
中国历史悠久,文化底蕴深厚,文物数目众多,文物作为前人智慧的结晶,其文献价值不言而喻。古籍是记录中华文明的重要载体,也是流传至今的宝贵文化遗产,文物保护也是一项长期重要的基础工作。全国 2800 多家图书馆收藏有超过 5000 万册的古籍,其中 1/3 存在不同程度的破损。按现有的文物修复人员数量,需要数百年的时间才能把馆藏文物全部修复好。
《古籍寻游记》是字节跳动联合中国第一历史档案馆、敦煌研究院、甘肃简牍博物馆、国家图书馆(国家典籍博物馆),共同打造的古籍活化项目,还原古文献四大发现 — 殷墟甲骨、居延汉简、敦煌遗书、明清档案,让古籍以数字化的形式“活”起来。
该项目以 VR 互动纪录片为核心,依托火山引擎多媒体实验室最新的三维重建技术,复刻线下文物到 PICO 虚拟场景中,并应用自研光场视频技术,采集并惟妙惟肖的还原动态人物的光场信息,在 VR 场景中提供高自由度的观看和交互体验。在这些纪录片中,观众可以通过 PICO、抖音裸眼 VR 等方式,足不出户穿越时空,亲自参与历史事件,零距离接触与欣赏古籍。
本文重点介绍火山引擎多媒体实验室的三维重建技术以及光场视频技术的原理、先进性及应用领域,帮助大家能更好的了解和认识三维重建技术,助力相关技术在实际产品和应用中落地。
一、技术挑战与难点
文物的数字化需要对文物做三维重建和数字复原,同时也对三维重建技术提出了很大挑战:
文物采集需要使用对于文物无侵害的设备,传统的高精度激光等设备就无法使用。文物通常保护在陈列柜内,难以拿出,也对重建的采集提出了更高的要求;
文物往往形状复杂,且具有一定的材质,尤其是古籍类文物,往往很薄,如何重建这种很薄的文物,是物品重建的一个难点。如何高真实感复现文物并表现其真实感纹理,包括漫反射、镜面反射、半透明,等复杂材质的恢复与微细表面的重建,也对技术提出了挑战;
对于石窟等文物,需要采集并重建一定的空间,如何采用纯视觉的方式,在石窟内进行漫游采集,并进行完整重建,是项目的一个难点;
为了更好地实现博物馆的文化推广,实现历史情景的在线还原,需要对动态人物和场景进行高真实度重建,然而,当前动态人物和场景的高真实度重建缺乏完整的有效解决方案。
二、三维重建技术介绍
三维重建是计算机辅助几何设计(CAGD)、计算机图形学(CG)、计算机动画、计算机视觉、医学图像处理、科学计算和虚拟现实、数字媒体创作等领域的共性科学问题和核心技术。三维重建技术,一般包括数据采集、预处理、点云拼接、特征分析、网格及纹理生成等步骤。传统的三维重建采用基于视觉或者基于多模态(深度数据,e.g.,激光)重建图像三维信息的过程,能够对静态物体和场景进行建模,但缺乏有效的对于动态物体和场景建模的整体解决方案。火山引擎多媒体实验室具备自研的物品重建技术、场景重建技术,及光场视频技术,能够对静态物体构建高保真的形态,并恢复其复杂材质;能够对大场景,包括城市,园区,房屋空间等进行有效的建模,是数字孪生的重要基础;且能够对动态物体和动态场景,采用先进光场视频技术进行重建和复现,实现点播和直播,具备整套的技术解决方案。
2.1 物品重建技术:既要保护文物又要精确扫描
在“古籍寻游记”项目中,火山引擎多媒体实验室做了四十多样文物的数字复原。在做文物数字复原的过程中,遇到的第一个难点就是,文物是需要重点保护的,对于采集设备有一定的限制,比如,常用的高精度激光设备是不能够用来扫描文物的,这就驱使火山引擎多媒体实验室团队采用基于视觉的方式对文物进行三维重建。然而传统基于视觉的重建方法无法处理弱纹理物体,而且对于形状比较复杂的物品也难以重建(例如狭长的简牍、扁平的甲骨)。为此,采用符号距离场(Signed Distance Fields,简称 SDF)的技术方案来表示三维物体,结合深度学习的方法克服了以上重建难点。SDF 表示了空间中每个点到物体的有向距离,是一种隐式表示,二维 SDF 的示意图如下。
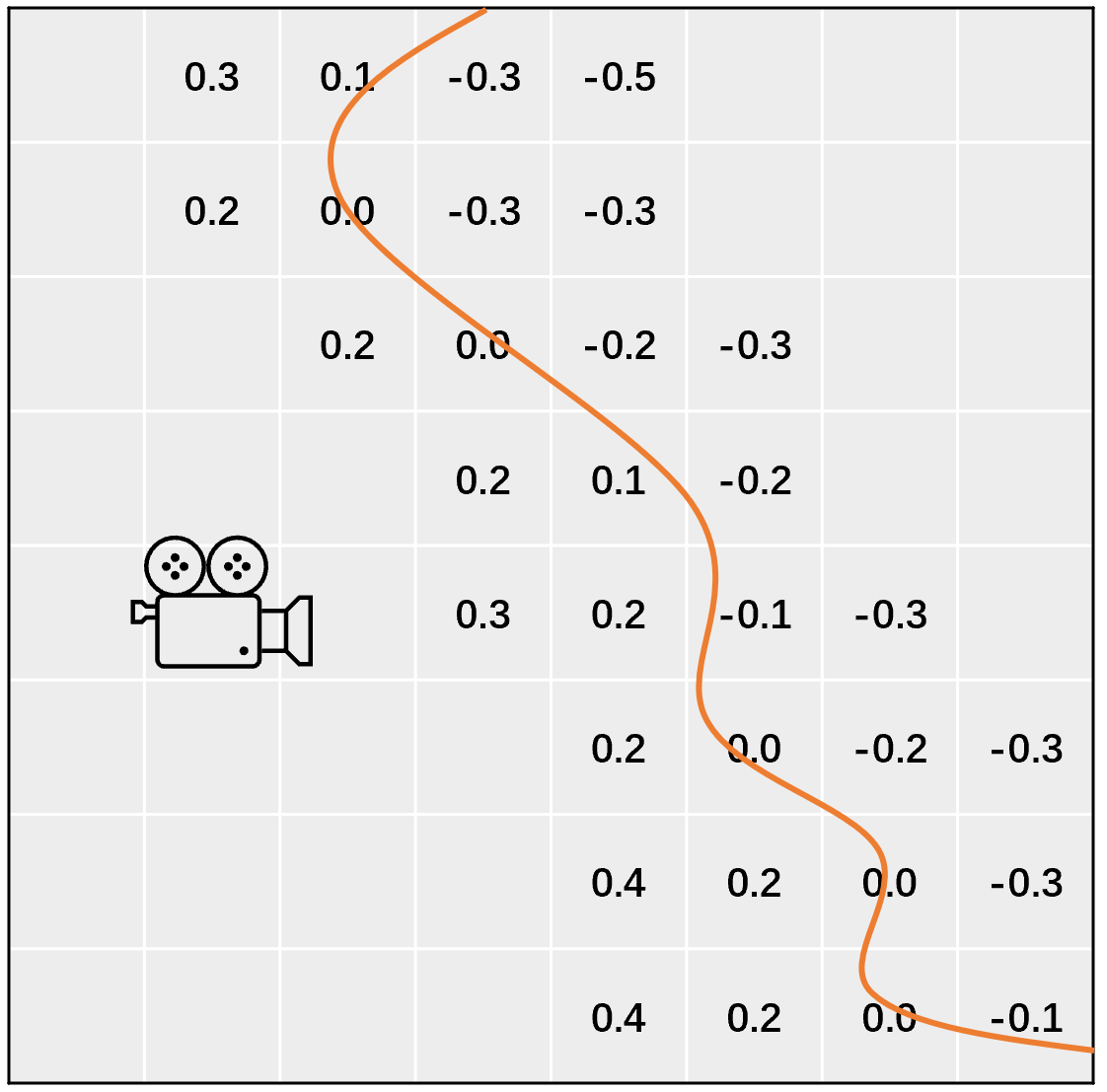
图:SDF 示意图
如何监督神经网络使其准确地拟合该 SDF 是需要研究的问题。先用运动恢复结构(Structure from Motion,简称 SfM)算法,精确计算拍摄图像的相机姿态。有了相机姿态,利用可微渲染的方法将 SDF 所表示的空间信息渲染到图像上,把渲染得到的图像和该视角下采集的图像做比较,不断优化神经网络,使 SDF 在各个采集视角下的渲染结果尽可能与实际采集的图像一致。为了进一步提高重建精细度,在优化 SDF 的时候加入稀疏重建得到的三维点做约束,能更好的还原物体的细节特征。
为了达到完整重建的目的, 火山引擎多媒体实验室还将分割算法和重建算法相结合,能够有效的重建出物体的底部区域。由于物体在扫描过程中是要固定在某个位置,物体的底面采集不到图片的。物体的完整重建就是要解决物体底部重建的问题,通常的做法是悬线法或多段重建加后处理拼接。悬线法对文物来说不够安全,拼接后处理流程较长,不能自动化。为此,火山引擎多媒体实验室在重建算法中加入了自动化图像分割,能够将正反两次拍摄的数据统一起来一起重建,直接得到完整的重建结果,完整重建的结果对比如下图所示。

图:未使用完整重建技术建模结果

图:使用完整重建技术建模结果
高光是物体重建的一大挑战,一方面高光影响特征点匹配,导致恢复的相机位姿不准确,再一个高光也会破坏不同视角间观测结果的一致性,对重建造成干扰。为此, 火山引擎多媒体实验室总结出一套利用偏振光消除高光的方法,能有效去除大量高光,高光消除的结果对比如下图所示。

图:消除高光前

图:消除高光后
火山引擎多媒体实验室的方法还可以模拟不同物体的反射/折射性质,实现对特殊材质物体的建模,文物重建的结果展示如下图所示。

图:文物原图

图:文物重建
甲骨文重建结果四大博物馆的文物,有一些是纸质、竹简类的珍贵文物,这些文物也难以从陈列柜中取出并采集。针对这种情况,火山引擎多媒体实验室自研了加入光学偏振片的采集设备,可以消除玻璃陈列柜带来的杂光、高光和反射问题,使得我们在有一层玻璃保护壳的状态下,仍对文物进行高保真的扫描和重建。

图:玻璃陈列柜中文物

图:文物重建结果
此外,火山引擎多媒体实验室的物品重建技术还包含精确位姿估计、真实感纹理(漫反射、镜面反射、半透明)等复杂材质的恢复与微细表面的重建,也均在“古籍寻游记”项目中得以运用,将宝贵的文物实现高真实度的 1:1 还原,并转换为数字化资源,让观众“沉浸式”逛馆,让藏品更加深入人心。火山引擎多媒体实验室的物体重建技术具备很强的普适性,不仅适用于文物,一般物体也同样适用,而且对一些传统重建难以处理的物体,比如,刀刃等非常薄的物体等,也能有不错的重建结果。

2.2 自建场景重建算法:更高效率、更高精度
场景重建是计算机视觉和摄影测量中的重要研究课题,也在智慧城市、虚拟现实、数字导航与数字遗产保护等方面有着重要的应用。通过视觉进行三维重建具有采集效率高、采集成本低、精度上限高、适应场景广等优点,同时可以避免其他扫描设备对场景带来不必要的损害,但在算法层面面临诸多挑战。对此,火山引擎多媒体实验室结合 AI 技术与多视角几何基本原理,搭建了一套先进的鲁棒、精确完整视觉重建算法框架。重建过程包括三个关键步骤:图像处理、点云优化和网格重建。
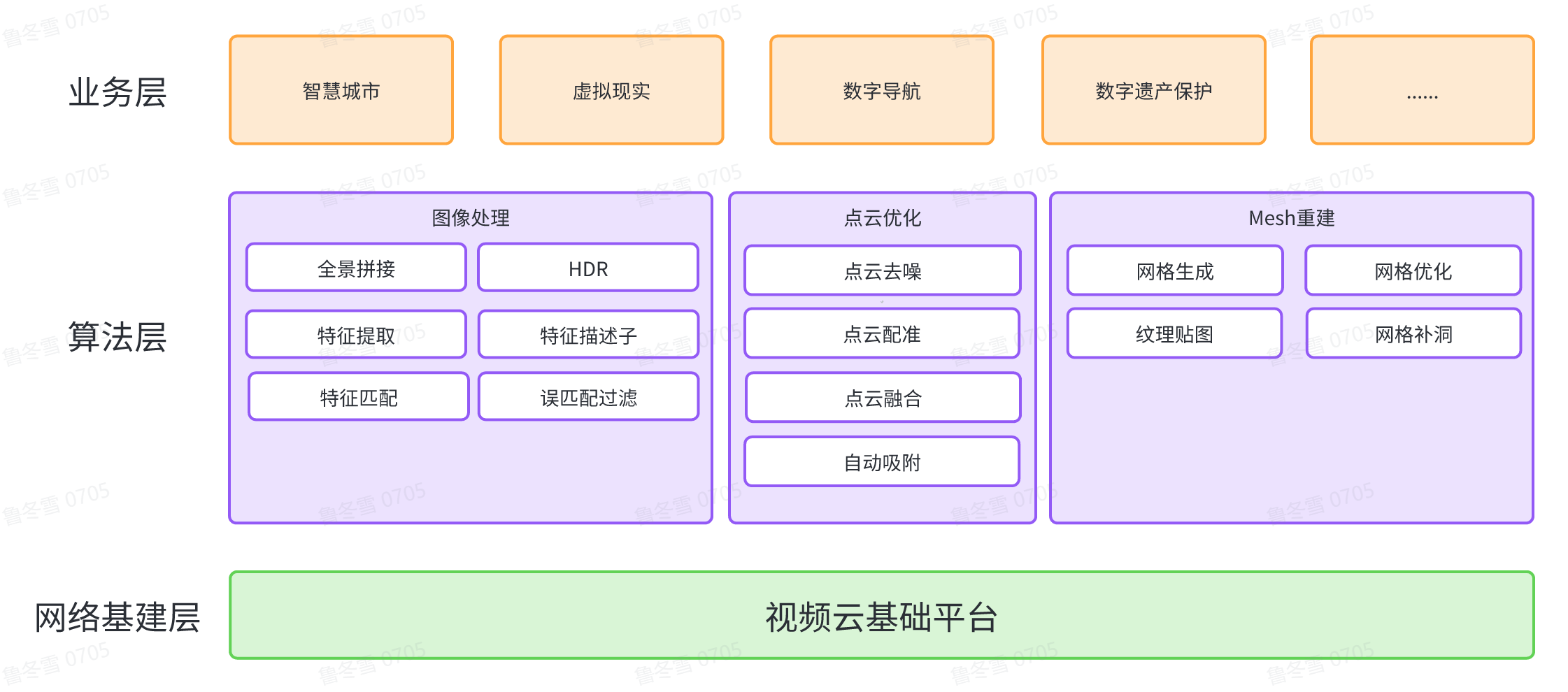
火山引擎多媒体实验室利用先进的人工智能技术,对图像进行去噪、超分、特征提取与匹配等处理,从而克服了诸多传统方法限制。然后利用 SfM 算法以及捆集约束(Bundle Adjustment,简称 BA)从图像中提取稀疏几何结构和相机参数。同时团队开发了支持全景相机、多相机组、RGBD 相机、激光雷达、 GPS/IMU 等多传感器数据输入的位姿估计算法,实现高精度、多模态、自适应的稀疏重建。为了处理大规模数据,团队开发分块重建和地图合并策略,实现分布式集群并行重建,显著提高了重建效率。
在完成场景稀疏重建后,通过立体视觉 (Multiple View Stereo,简称 MVS)技术将二维图像信息转化为三维点云信息。团队自研基于单目相机、双目相机和多目立体视觉的深度估计算法,通过神经网络进行稠密深度估计,在任意视差、各种纹理环境获得稳定优秀的表现。获得点云信息后,进行点云去噪和补全,并通过点云配准实现场景几何一致性。最后,通过基于 VoxelHash 和图像语义信息的点云融合策略,进一步滤除噪声,生成更加平滑一致的完整场景点云。
获得场景点云后,进行 Mesh 重建。火山引擎多媒体实验室自研多种网格优化算法,实现网格平滑、去噪、简化和补洞,获得更加精细、完整的高质量网格模型。得益于图像处理期间高精度的相机位姿估计以及图像超分等画质优化,结合自研贴图算法,获得更高清、拼缝更少的高质量纹理贴图。同时通过纹理重打包算法优化,实现更高的纹理利用率,降低存储资源浪费,提升纹理有效分辨率。


火山引擎多媒体实验室的物品重建技术和场景重建技术可以等比例、高精度的复原不同大小、不同形状的文物。上述的技术可以将线下文物转换到线上,在 PICO、抖音里实现文物的虚拟呈现,用户可以把甲骨文把玩在手里,清晰的看到上面的文字,实现传统参观没有的文物观赏体验,同时也可以跨越空间限制,置身并漫游在敦煌石窟里。另外,该项技术可以将线下珍贵文物转换为线上的永久数字资源,实现文物的数字化保护,可以让后世的人们身临其境体验到文物的全貌。
2.3 自研光场视频技术:平衡成本与精确度之间的难题
为了能够在虚拟敦煌石窟内,身临其境地观看一场盛世舞蹈,感受超越现实的体验,火山引擎多媒体实验室自研的光场视频技术,能够对动态人物和场景进行高真实度重建,达到行业先进水平。
动态三维网格数据(Dynamic Mesh),可以表示动态人物和场景,但是如何重建出高质量的动态三维网格,并使得新渲染出的图像能够如照片般逼真是一个难题。 若通过三维场景设计师对场景进行手工重建,将获得较好的重建质量,但将付出较大的人力成本; 若通过 SFM/MVS 等算法自动重建三维场景,则需要重建场景纹理有一定要求,且重建结果可能包含不精确的几何细节和纹理失真。
神经辐射场技术,采用神经网络对隐式重建,利用可微渲染模型,从已有视图中学习如何渲染新视角下的图像,从而实现照片级逼真的图像渲染, 即神经辐射场(NeRF)技术。可微渲染模型建模了从三维空间模型及纹理到图像的渲染过程,其可微特性使得在已有视角图像的监督下,通过神经网络对三维空间几何及纹理进行学习。在未知新视角下,可以对学习到的三维空间几何进行重新渲染,从而获得新视角下的图像。
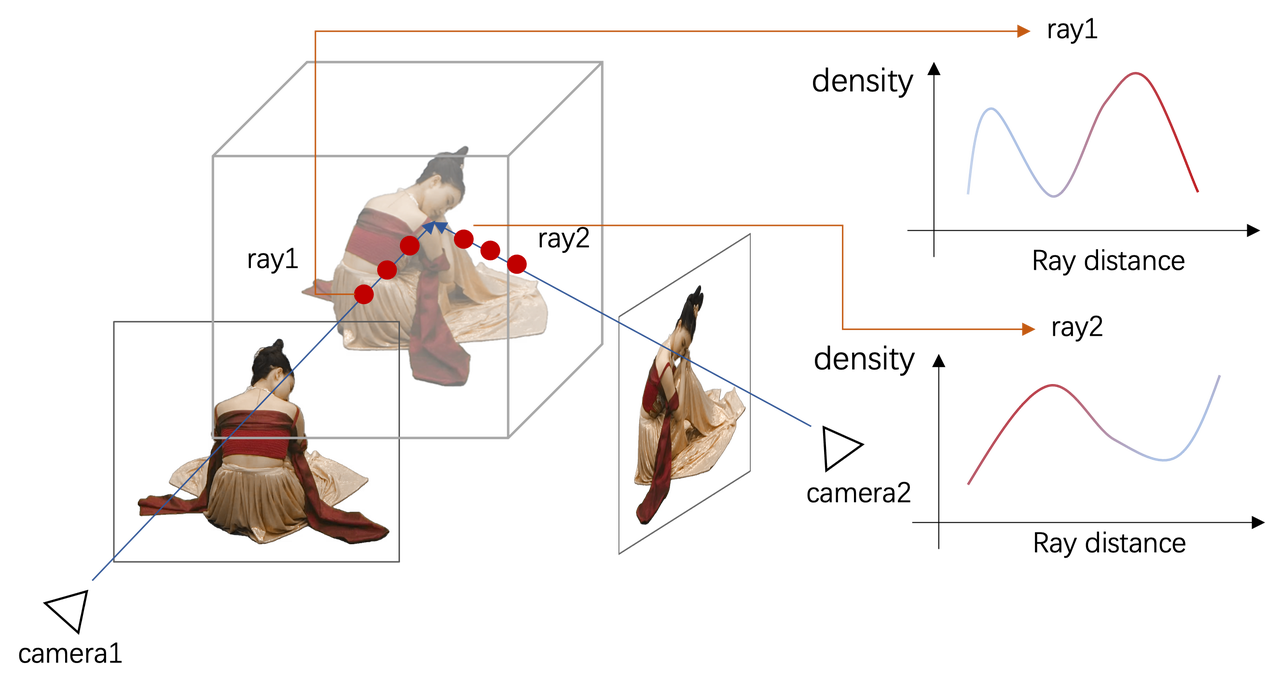
图:可微渲染模型
火山引擎多媒体实验室融合神经辐射场技术与传统的网格建模技术。在具体实践中,首先重建出人物的大致几何轮廓,并改进 NeRF 技术,融入几何轮廓作为先验加入训练指导,隐式学习三维空间几何,并重新渲染出稠密新视角下的图像。在神经辐射场训练过程中,针对动态人物场景,团队通过一些优化策略以提升该场景下的新视角生成效果,如借助基于哈希编码的层次化表达提升模型训练速度,借助流式训练提升动态场景的帧间一致性等。最后采用视频融合技术, 能够自动学习背景信息,实现前景的重光照,使得前景演员与背景场景能够无缝融合。
光场视频重建结果
同时,火山引擎多媒体实验室的光场视频技术,可以实现 NeRF 的编辑,重建并复现复杂的动态大场景。

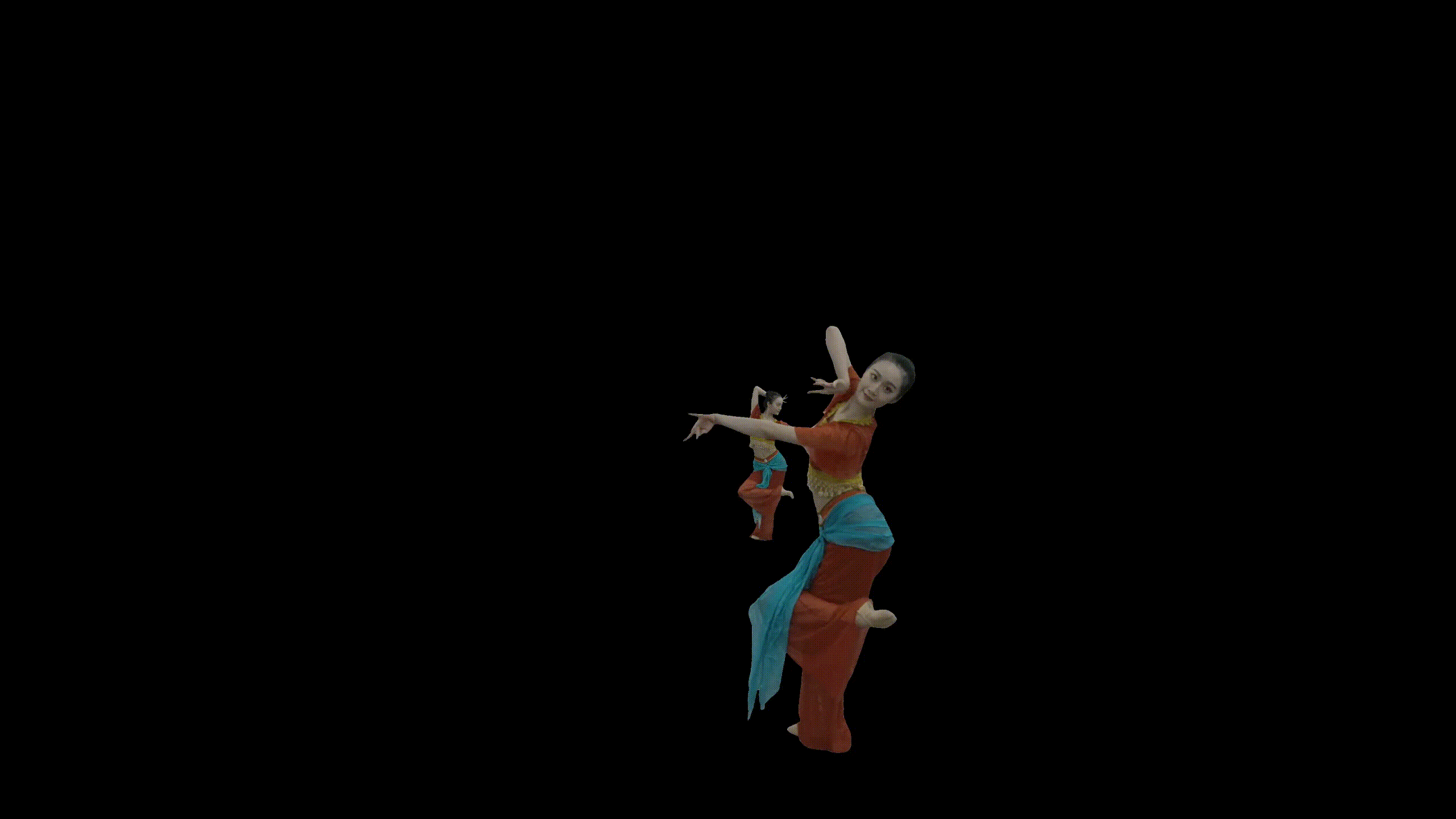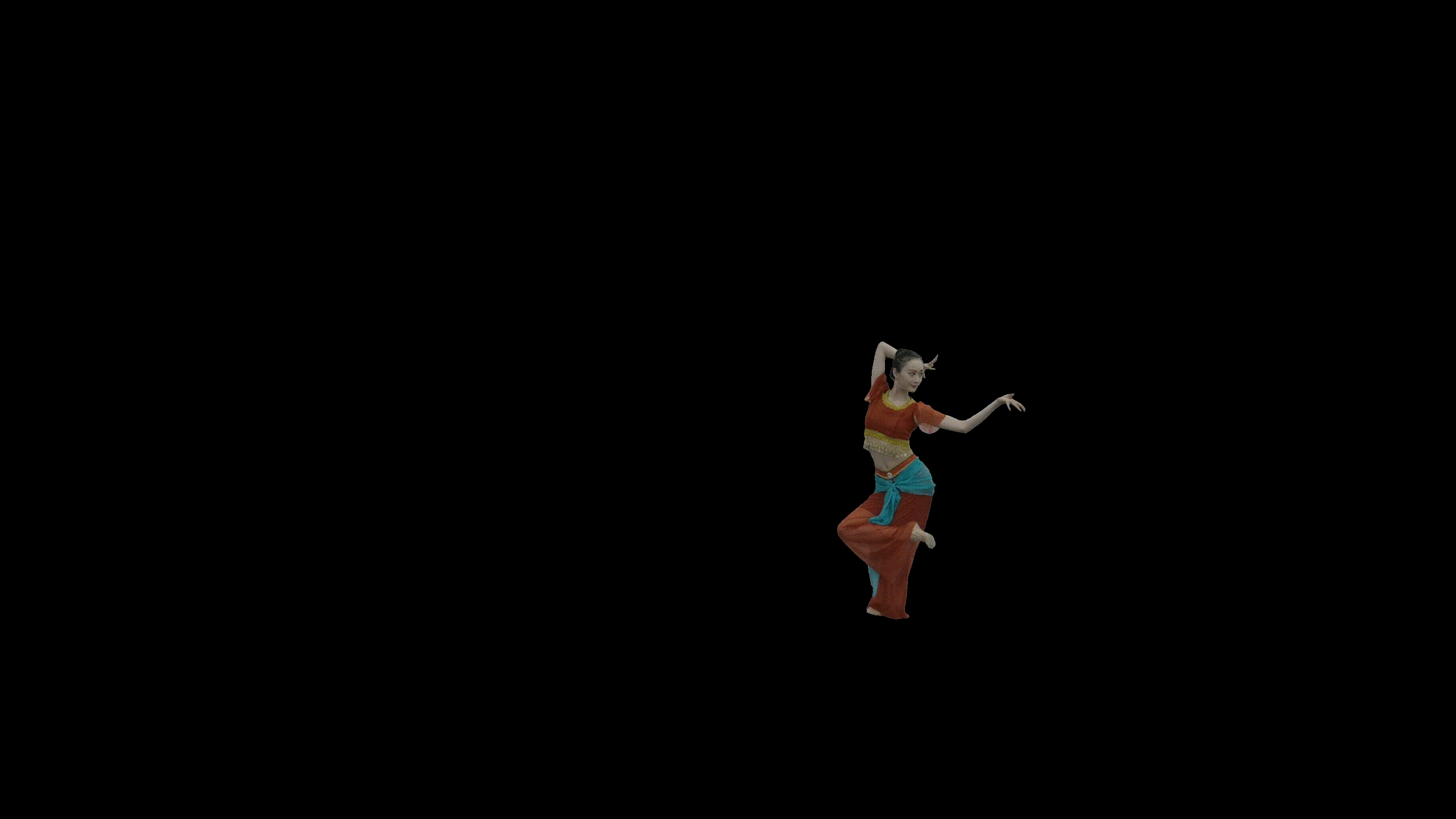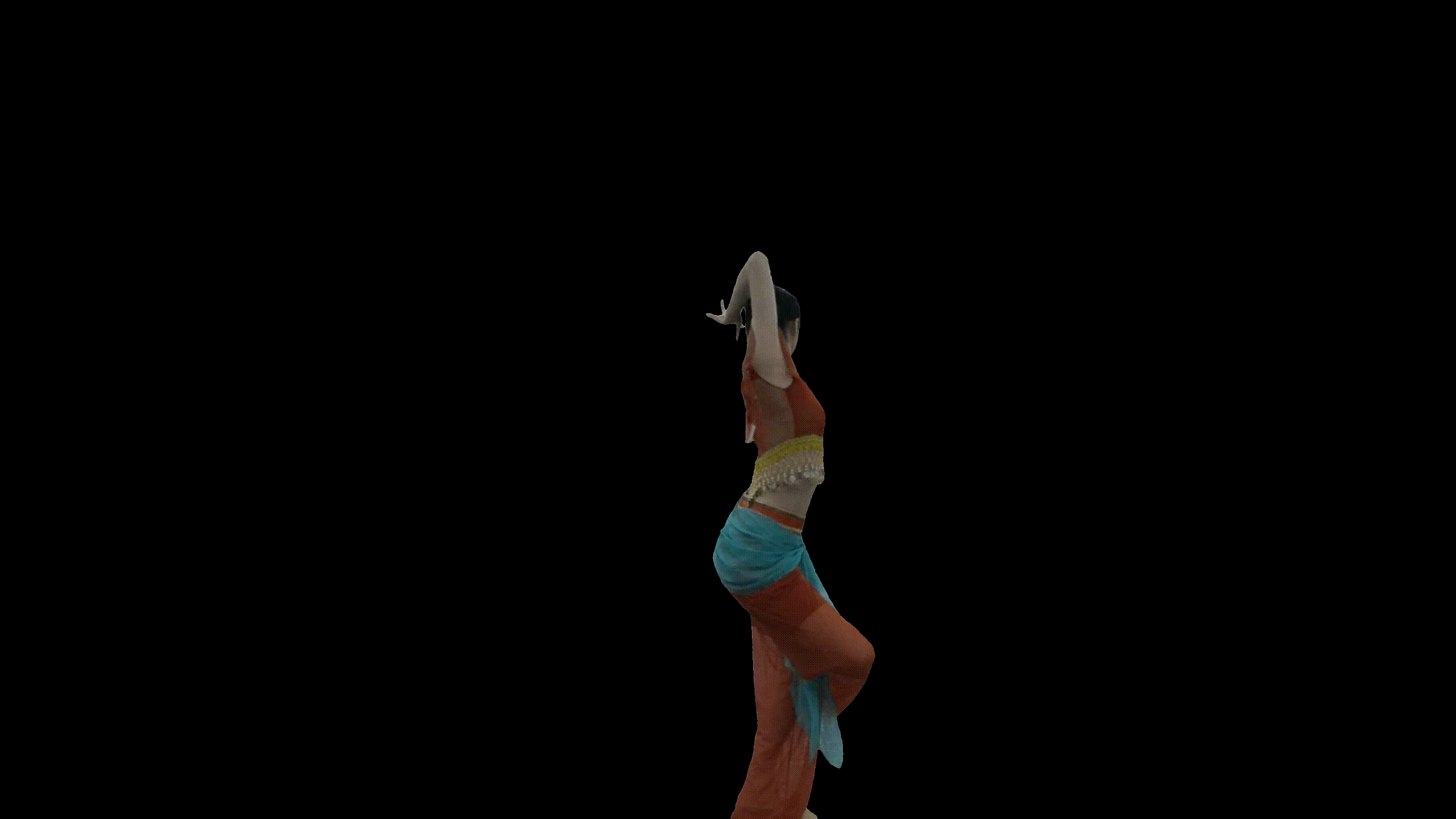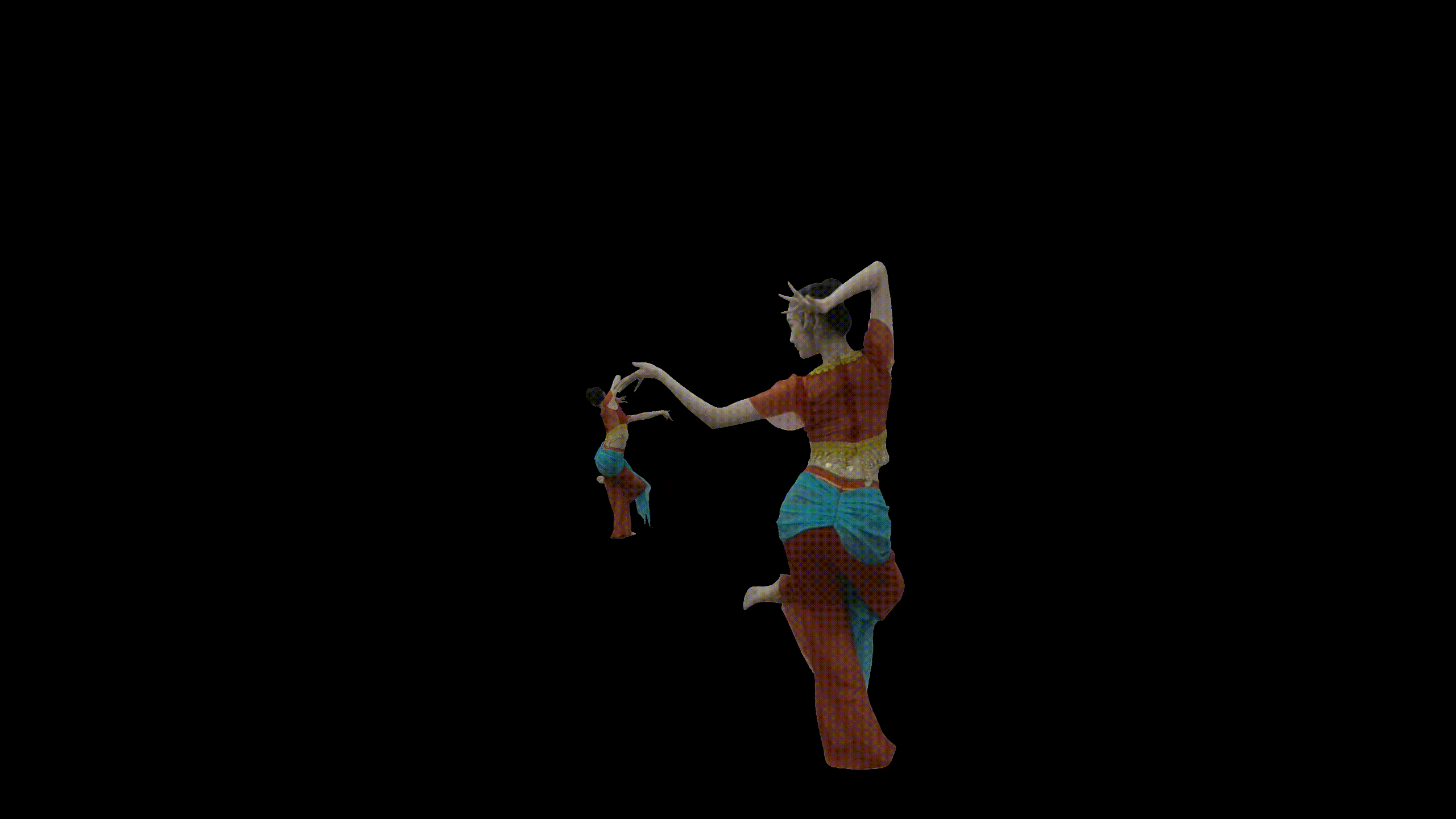
图:光场视频后编辑结果
火山引擎多媒体实验室的光场视频技术,仅仅需要稀疏的多相机输入,就能够生成稠密的光场数据,这主要是采用基于深度学习的新视角生成技术。光场视频数据相对传统视频数据,具有数据量大的特点,团队采用多视角聚合编码技术压缩光场数据,降低传输和存储的压力。结合大规模直播技术以及 RTC 传输技术,能够实现光场视频的点播和直播。
光场视频高自由度观看结果(PICO 内录制)
三、总结与展望
随着 3D 技术的不断成熟,火山引擎多媒体实验室的 3D 技术不仅在 VR 领域、自动驾驶、视频直播、游戏等场景落地具体的应用,而且将会在在工业、医疗、建筑家居、航空航天等领域持续探索。火山引擎希望能够将物品重建技术、场景重建技术及光场视频技术广泛应用到各行各业的产品和项目中去,服务于企业客户,为用户带来更高清、更互动、更沉浸的创新体验。




