
当前直播行业愈发火热,用户通常处于不同的环境中,身边的键盘声,敲击声,空调声,喧哗声等噪声有时会对实时互动产生严重的干扰。然而传统的降噪算法针对平稳噪声有比较好的降噪效果,针对上述这一类非平稳噪声,比较难处理,收效甚微,降噪效果很差。
随着近年深度学习的广泛应用,使用神经网络的降噪算法喷涌而出,而且这类算法不管是在降噪力度上,还是鲁棒性上,都要优于传统降噪,是当前处理各种不同场景噪音的首选方案。
但是,在实时互动环境下,对于音频实时处理和性能要求比较高,这对于 AI 模型的设计和效果的平衡带来了的巨大的挑战。
基于上述挑战,荔枝集团音频团队提出了一种轻量的降噪方案--LizhiAiDenoiser,该方案不仅能处理日常生活中常见的平稳和非平稳噪声,而且能很好的保留语音的音质,同时该 AI 降噪模型在运行时占用的内存和 cpu 消耗都极低,满足了全量 iPhone 机型以及大部分 Android 中低端机型。
一、基本原理
LizhiAiDenoiser 采用传统算法和深度学习结合的混合结构。为了可实际在移动端部署,LizhiAiDenoiser 采用了比较精细的模型结构,主要使用低性能消耗的 CNN-RNN 结构。
1. 数据和增强
训练深度学习降噪模型的数据集是通过混合纯净语音和噪音音频的方式。纯净语音主要使用的是开源数据集,包括英文数据集和中文数据集,英文数据集 300 小时,中文数据集 200 小时。噪音音频由两部分构成,一部分是开源噪音集 audioset,大约 120 小时,一部分是自己录制的噪音集,大约 60 小时。数据增强的方法被应用于语音和噪声样本,目的是进一步扩展模型在训练的过程中看到的数据分布。当前,LizhiAiDenoiser 支持以下随机增强的方法:
○ 重采样速度和改变 pitch
○ 添加混响,在纯净语音中添加少量混响
○ 使用[-5,25]的信噪比来混合纯净语音和噪音
2. 模型目标
语音降噪通常采用有噪声语音的短时傅里叶变换(STFT),只增强幅度谱,而保持相位谱不变。这样做是因为人们相信,相位谱对语音增强并不重要。然而,最近的研究表明,相位对感知质量很重要。我们的方法使用深度神经网络来估计在复数域中的理想比值 Mask 的实部分量和虚部分量,这种方法更好的保留了语音的质量
同时以更小的模型参数达到了大模型同样的降噪效果。原始的 AI 降噪模型,模型大小大概 3M,固定测试集 mos 分为 3.1。对模型做一些剪枝同时调整模型结构,再针对模型输出目标进行调整,在保持 3.1 的 mos 的情况下,最终模型大小降为 900k。
复数理想比值 Mask 的推导过程如下:
S(t,f) = M(t,f) * Y(t,f) .........(1)
公式(1)中 S(t,f)代表纯净语音,Y(t,f)代表带噪语音,M(t,f)代表模型估计出来的复数域中的理想比值 Mask。
为了方便起见,上式没有体现出时间和频率的下标,但给出了每个 T-F 单元的定义。公式(1)可以扩展为:
S(r)+iS(i)= (M(r) +iM(i)*(Y(r)+iY(i))=(M(r)Y(r)-M(i)Y(i)+i(M(r)Y(i)+M(i)Y(r)) .........(2)
纯净语音的实部分量和虚部分量为:
S(r) = M(r)Y(r) - M(i)Y(i) .........(3)
S(i) = M(r)Y(i) + M(i)Y(t) .........(4)
根据公式(3)和公式(4)可以得到 M 的实部和虚部分量:
M(r)=(Y(r)S(r)+Y(i)S(i))/(Y(r)2+Y(i)2).........(5)
M(i)=(Y(r)S(i)-Y(i)S(r))/(Y(r)2+Y(i)2).........(6)
从而得到复数域理想比值的 Mask:
M=(Y(r)S(r)+Y(i)S(i))/(Y(r)2+Y(i)2)+i((Y(r)S(i)-Y(i)S(r))/(Y(r)2+Y(i)2)).........(7)
3. 网络模型
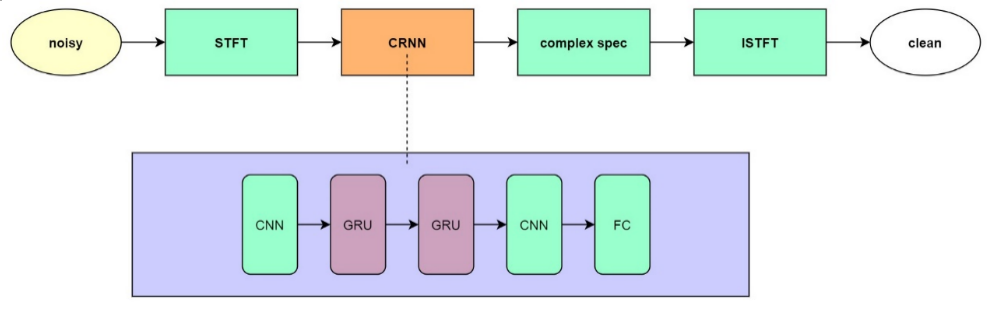
从上图可以看出,我们使用的模型结构极其简单,并且 CNN 能够很好的提取 local feature,GRU 能够学习时序上的特征,这对于模型的泛化和推理实时性都起到了很好的正向作用。
二、效果和性能
效果
在效果验证上,我们采用日常常见的八种噪音不同的信噪比与传统降噪进行对比测试,使用 POLQA 测试降噪后的音频 mos 分,对比结果如下:
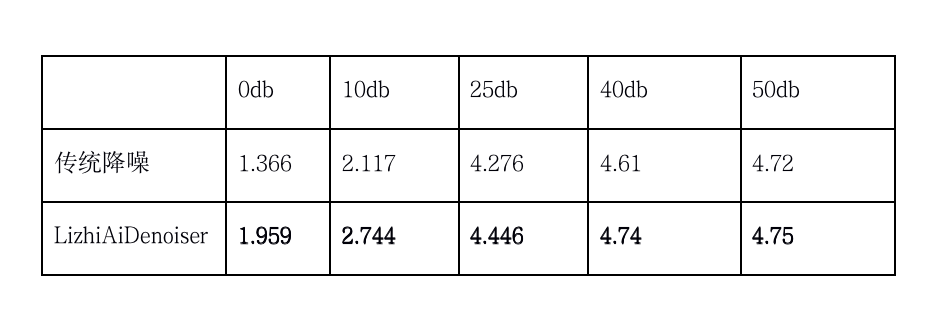
如上效果所示,LizhiAiDenoiser 在不同信噪比和场景下,取得了不错的效果。这里测试 40db 和 50db 的音频,主要是为了测试 LizhiAiDenoiser 对近乎纯净语音有没有损伤,从最终结果能够看出,LizhiAiDenoiser 对于纯净语音几乎不产生损伤情况。
音质保护示例
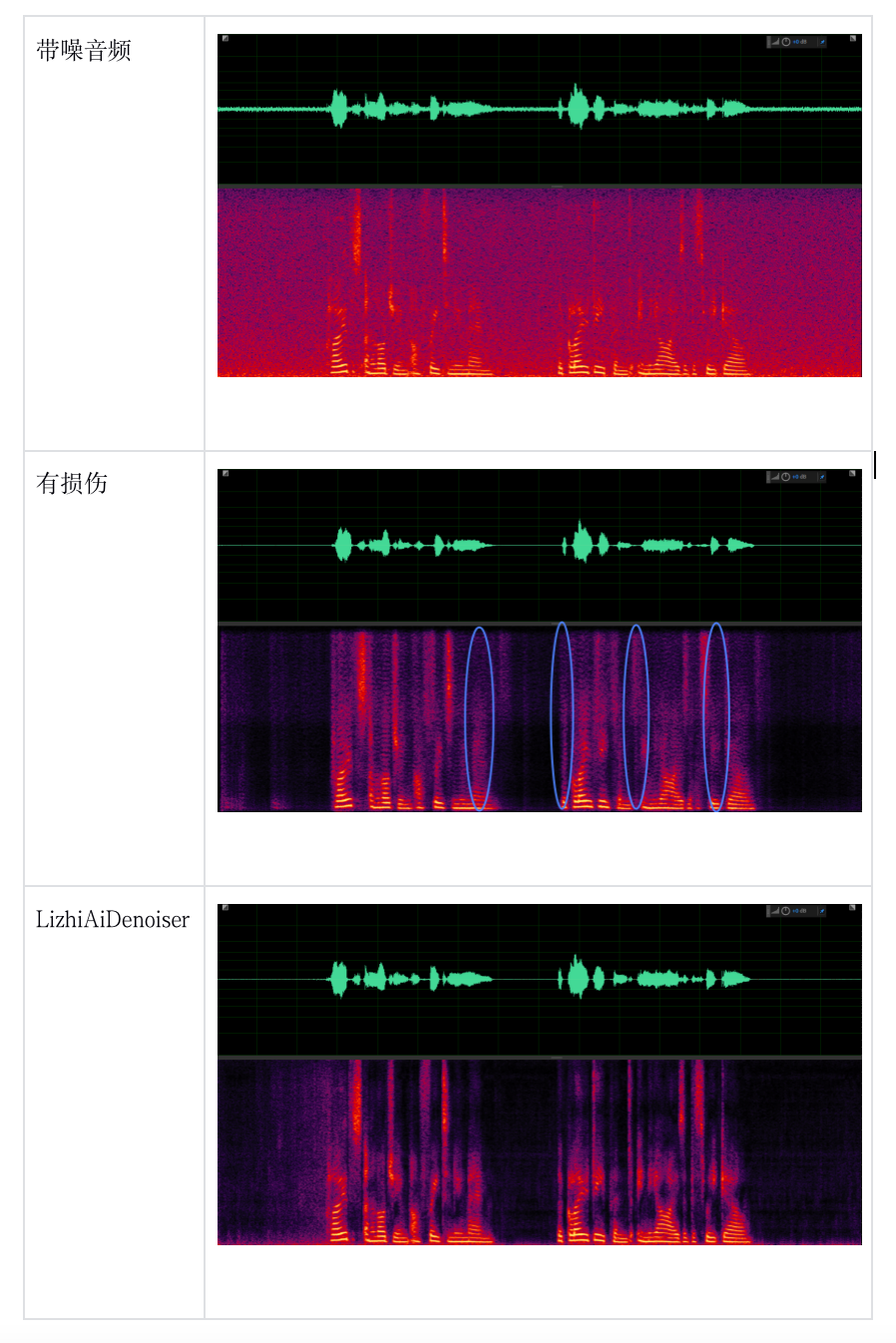
结论:在语音的中频部分能看到 LizhiAiDenoiser 降噪后对语音保留的更好。
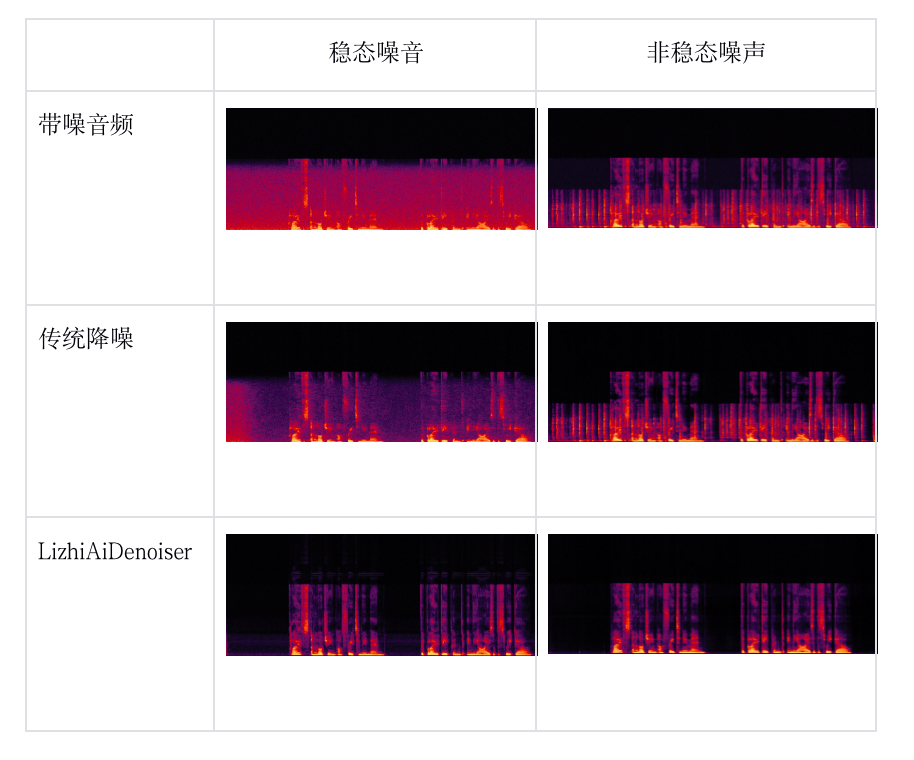
降噪示例
性能
在 LizhiDenoiser 的模型前向推理过程中,我们没有使用开源的推理框架,而是使用自研的推理框架,不使用开源推理框架原因有:
• 不依赖第三方推理框架,使得前向推理更加灵活多变;
• 减少 LizhiDenoiser 模块占包大小;
• 更加自由灵活的针对模型结构做极致的推理速度优化
分别测试了 iPhone 和 Android 较低机型的性能,这里主要采用 cpu 消耗和实时率来度量 LizhiAiDenoiser 的性能。
cpu 消耗
因为模型设计比较精细,参数占用比较小,cpu 占用不超过 3%。
实时率
实时率是指处理每帧音频所要花费的时间,通常是处理整个音频来统计总的耗时,再除以音频的总帧数,得到平均每帧耗时,这种方式在实时率要求比较高的任务中是很难有说服力的,因为此时任务比较单一,CPU 利用率比较高,所以总的耗时统计大大减少。
我们在统计实时率时采用最真实的统计方法,即在 RTC 应用中统计每帧音频的真实耗时情况。统计情况如下:
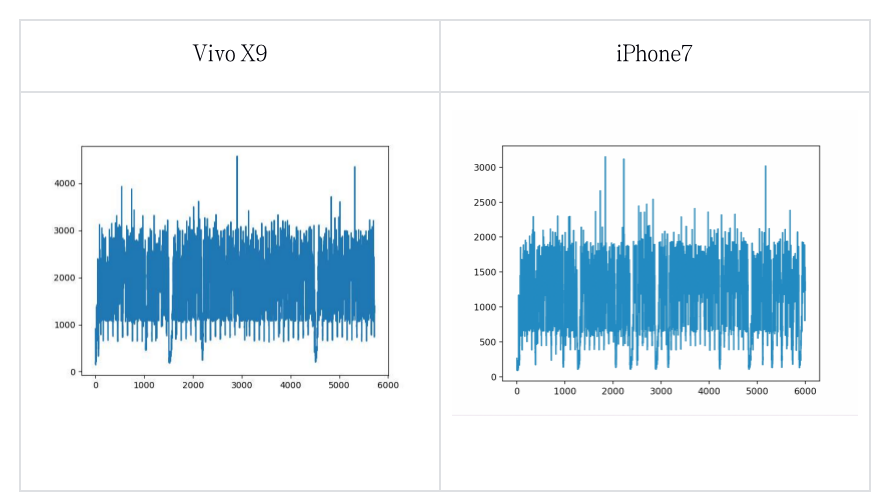
说明:上图中横坐标是音频帧数,每一帧 10 毫秒,纵坐标是每一帧经过 LizhiAiDenoiser 降噪耗时,单位是微秒
从图中可以看出,android 较低机型实时率不超过 0.3,iPhone 较低机型实时率不超过 0.2。
三、规划
AI 降噪在 RTC 任务中还有很多优化的空间:
1. 实时率的优化
进一步对模型进行剪枝和使用更低计算消耗的网络,同时进一步优化我们的 AI 推理框架,以及对模型进行量化,通过这几个维度的优化来进一步提升我们 AI 降噪的实时率。
2. 全频带 AI 降噪
因为全频带 AI 降噪不管是在特征输入上还是网络结构设计上都比较大,很难在 RTC 这种对实时率要求比较高的任务达到好的效果,所以我们接下来准备将音频转换到比较小的特征维度上,通过设计比较小的网络来拟合该任务。
3. 模型的压缩
在算法落地上,对于模型大小有时也有一定的要求,同时也是模型轻量的一个体现,更少的占用设备资源。所以在模型落地时,一般会对模型大小进行压缩,接下来我们会使用占用内存更小的数据类型来存储数据,优化模型存储的格式以进一步减少模型存储的大小。
作者:
邱威:荔枝音视频研发中心高级音频算法工程师,主要从事音频相关 AI 算法研究和 AI 模型在移动端部署的工作。




