
学过人类照片和鱼类照片的 AI,第一次见到美人鱼的照片会作何反应?人脸和鱼身它都很熟悉,但它无法想象一个从没见过的事物。近期,阿里巴巴达摩院将因果推理方法引入计算机视觉领域,尝试克服机器学习方法的缺陷,让 AI 想象从未见过的事物,相关论文已被计算机视觉顶会 CVPR 2021 收录。
计算机视觉(CV,Computer Vision)是研究如何让机器“看”的科学,通过将非结构化的图像和视频数据进行结构化的特征表达,让 AI 理解视觉信息。深度学习出现后,AI 在 CV 领域的很多任务取得了超越人类的进展,不过,比起人类的视觉理解能力,AI 仍是非常“低维”的存在。
通过人和鱼的形象来想象美人鱼,对人来说轻而易举,AI 却极有可能把美人鱼胡乱归入“人”或“鱼”中的一类。因为它们缺乏“想象”这一高级别认知能力。现阶段的机器学习技术本质是通过观测数据进行拟合,这导致 AI 只认得学过的事物,遇到超越训练数据的对象,往往容易陷入“人工智障”。
图灵奖得主、因果关系演算法创立者朱迪·珀尔认为,人类的想象能力源于我们自带因果推理技能的大脑,人类善问“为什么”,也就是寻求事物的因果关系。借助这套认知系统,我们用“小数据”就能处理现实世界无限的“大任务”。而 AI 却只能用“大数据”来处理“小任务”,如果 AI 能够学会因果推理,就有望破除“智商天花板”,甚至通向强人工智能。
因果推理理论极大启发了研究者,其与机器学习的结合日益受到关注。在工业界,达摩院城市大脑实验室最早将因果推理方法引入 CV 领域,用因果推理模型赋能机器学习模型,让视觉 AI 更智能。今年,该团队与南洋理工大学合作了《反事实的零次和开集识别》等三篇采用因果推理方法的论文,均被 CVPR 2021 收录。

(左为现有方法的 AI“想象”结果,中为达摩院论文提出的算法核心,右为基于达摩院框架完成的想象结果。在左右二图中,* 红色代表训练集里面的样本,蓝色是 AI 未见过类别的样本,绿色 AI 对未见过类别的想象。)
零次学习是指让机器分类没见过的对象类别,开集识别要求让机器把没见过的对象类别标成“不认识”,两个任务都依赖想象能力。《反事实的零次和开集识别》提出了一种基于反事实的算法框架,通过解耦样本特征(比如对象的姿势)和类别特征(比如是否有羽毛),再基于样本特征进行反事实生成。在常用数据集上,该算法的准确率超出现有顶尖方法 2.2% 到 4.3%。论文作者岳中琪指出,AI 认知智能的进化刚刚开始,业界的探索仍处在早期阶段,今后他们将不断提升和优化相关算法。
城市大脑实验室介绍,数据驱动的机器学习模型普遍面临数据不均衡问题,“以城市为例,它的信息呈长尾分布,相比海量的正常信息,交通事故、车辆违规、突发灾害等异常信息的发生概率很小,样本稀少,尽管可以通过大量增加少见样本的办法来部分解决问题,但这么做成本高、效率低。”
基于自研算法,只需使用正常信息样本,就能让 AI 获得无偏见的异常检测结果。一旦出现紧急情况,比如某辆车和某个行人发生异常交互,城市大脑不必不懂装懂或视而不见,而是可以实时识别和反馈信息。未来,这一技术有望应用于城市基础视觉算法体系优化、极少样本城市异常事件感知能力优化乃至多模态语义搜索、智能图文生成等领域。
下面是岳中琪对 CVPR 2021 论文《反事实的零次和开集识别》(Counterfactual Zero-Shot and Open-Set Visual Recognition)的解析,论文代码请见 https://github.com/yue-zhongqi/gcm-cf。
现有的零次学习和开集识别中,见过和未见过类别间识别率存在严重失衡,我们发现这种失衡是由于对未见过类别样本失真的想象。由此,我们提出了一种反事实框架,通过基于样本特征的反事实生成保真,在各个评估数据集下取得了稳定的提升。这项工作的主要优势在于:
我们提出的 GCM-CF 是一个见过 / 未见过类别的二元分类器,二元分类后可以适用任何监督学习(在见过类别上)和零次学习算法(在未见过类别上);
我们提出的反事实生成框架适用于各种生成模型,例如基于 VAE、GAN 或是 Flow 的;
我们提供了一种易于实现的两组概念间解耦的算法
接下来我会具体的来介绍我们针对的任务,提出的框架,和对应的算法。文章导视:
第一节:零次学习和开集识别
第二节:反事实生成框架
第三节:提出的 GCM-CF 算法
第四节:实验结果
第一节:零次学习和开集识别

很多人都认识羚羊和貘这两种动物(如上图所示),那么一个鼻子像貘的羚羊长得什么样呢?可能大家能想象出来一个类似于图右的动物(它叫高鼻羚羊)。在上面的过程中,我们就是在做 零次学习 (Zero-Shot Learning, ZSL):虽然我们没见过高鼻羚羊,但是通过现有的关于羚羊和貘的知识,我们就能想象出来这个未见类别的样子,相当于认识了这个动物。事实上,这种将已有知识泛化到未见事物上的能力,正是人能够快速学习的一个重要原因。

我们再来看一个路牌的例子,我们很容易就认出左边的两个路牌是熟悉的、见过的,而右边的则是一个很奇怪的没见过的路牌。人类很容易就能完成这样的 开集识别 (Open-Set Recognition, OSR),因为我们不仅熟悉见过的样本,也有对未知世界的认知能力,使得我们知道见过和未见之间的边界。
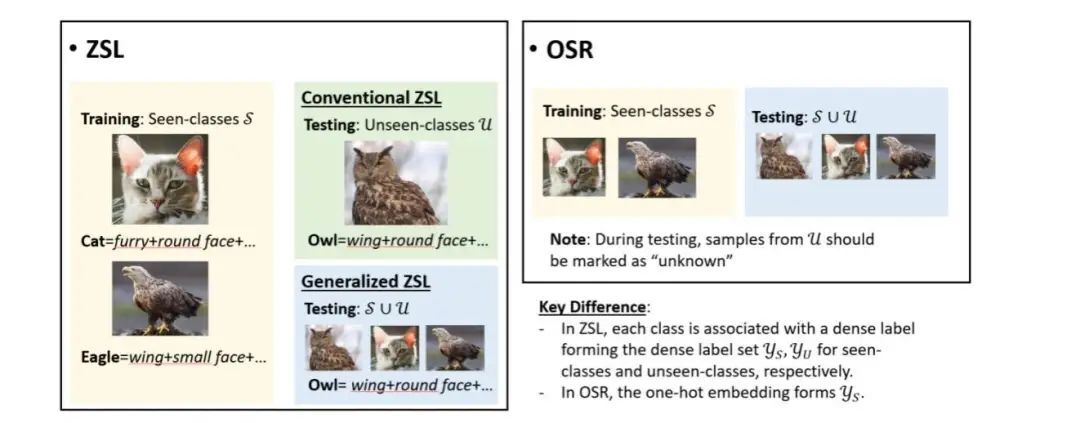
在机器学习当中,这两个任务的定义如上图所示。零次学习训练集提供类别集合。上面的图片,除了每张图片的类别标签,每个类别还额外有一个属性特征 (attribute) 来描述这个类的特点(比如有翅膀,圆脸等等),测试的时候有两种设定:在 Conventional ZSL 下全部是未见类别中的图片(),并且测试的时候也会给定类别的 dense label,而在 Generalized ZSL 中测试集会有和中的图片。开集识别的训练集则和普通的监督学习没有差别,只是在测试的时候会有训练未见过类别的样本,分类器除了正确识别见过的类,还要将未见过的类标成“未知”。
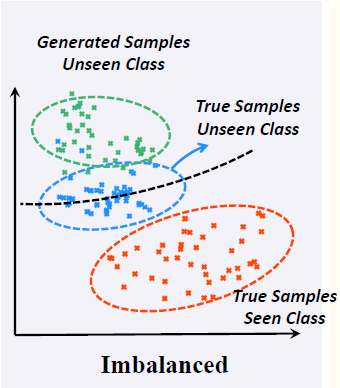
现有的 ZSL 和 OSR 的主要方法是基于生成的,比如 ZSL 中用未见类别的属性特征生成图片,然后在 image space 进行比较。然而生成模型会自然的偏向见过的训练集,使得对于未见类别的想象失真了(这其实是因为属性特征的 entanglement,这里我不详细展开,大家可以参考一下论文)。比如训练的时候见过大象的长鼻子,而去想象没见过的貘的长鼻子的时候,就会想象成大象的鼻子。左边的图展现了这种失真:红色是训练集里面的样本,蓝色是 ground-truth 的未见过类别的样本,绿色是现有方法对未见过类别的想象,这些想象已经脱离了样本空间,既不像见过的类,也不像没见过的类(绿色的点偏离了蓝色和红色的点)。这就解释了为什么见过和未见过类别的识别率会失衡了:用绿色和红色样本学习的分类器(黑色虚线)牺牲了未见过类的 recall 来提高见过类的 recall。
第二节 反事实生成框架
那么如何在想象的时候保真?我们来思考一下人是怎么想象的:在想象一个古代生物的样子时候,我们会基于它的化石骨架(图左);在想象动画世界的一个场景的时候,我们会参考现实世界(图右)。这些 想象其实本质是一种反事实推理(counterfactual inference),给定这样的化石(fact),如果它还活着(counterfact),会是什么样子呢?给定现实世界的某个场景,如果这个场景到了动画世界,它是什么样子呢?我们的想象,通过建立在 fact 的基石上,就变得合情合理而非天马行空。

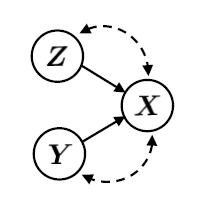
那么可否在 ZSL 和 OSR 当中利用反事实产生合理的想象呢?我们首先为这两个任务构建了一个 基于因果的生成模型 Generative Causal Model (GCM),我们假设观测到的图片是由样本特征(和类别无关,比如物体的 pose 等)和类别特征(比如有羽毛,圆脸等)生成的。现有的基于生成的方法其实在学习,然后把的值设为某个类的特征(比如 ZSL 中的 dense label),把设成高斯噪声,就可以生成很多这个类的样本了。
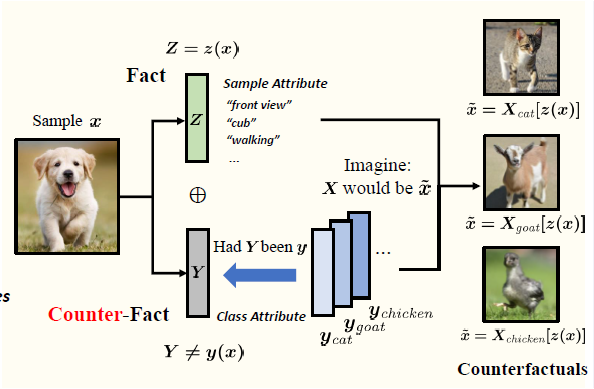
反事实生成和现有生成模型的最大区别就是基于了特定的样本特征(fact)来进行生成,而非高斯噪声。具体过程如上图所示,对于一个图片,我们通过 encoder 拿到这个图片的样本特征(比如 front-view,walking 等),基于这个样本特征(fact)和不同的类别特征(counterfact),我们可以生成不同类别的反事实图片(front-view,walking 的猫,羊和鸡等等)。直觉上,我们知道,因为反事实生成的猫、羊和鸡的图片很不像,肯定不属于这三个类别。这种直觉其实是有理论支持的 — 叫做 反事实一致性(Counterfactual Consistency Rule),通俗的解释就是 counterfact 和 fact 重合时,得到的结果就是 factual 的结果,比如 fact 是昨天吃冰淇凌拉肚子,那么反事实问题“如果我昨天吃冰淇淋会怎么样呢?”的答案就是拉肚子。那么如何通过 consistency rule 解决 ZSL 和 OSR 呢?
第三节 GCM-CF 算法
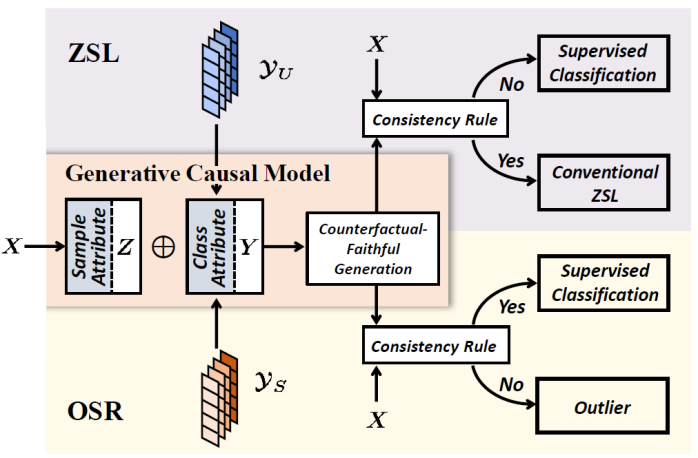
我们的 GCM-CF 算法流程由上图概括,它本质上是一个基于 consistency rule 的二元分类器,去判断某个样本是属于见过还是没见过的类。
训练的时候我们学习一个 GCM(训练过程等下会具体讲)。测试的时候,对于每个样本,我们用上一节介绍的步骤进行反事实生成:用这个样本自己的,拼上不同的类别特征,然后用生成。这样生成的样本可以证明是“保真”(Counterfactual Faithful)的,也就是在样本空间里面,那么我们就能够用样本空间当中的量度去比较和生成的,从而用 consistency rule 判断是属于见过的还是没见过的类。
具体到任务中,在 ZSL 里面,我们用未见过类别的 attribute(图中)生成反事实样本,然后用训练集的样本(见过的类)和生成的样本(未见过的类)训练一个线性分类器,对输入样本进行分类后,我们取见过类和未见过类概率的 top-K 的平均值。如果未见过类上的平均值较小,我们就认为样本不像未见过的类(not consistent),把这个样本标注成属于见过的类,并使用在见过类的样本上面监督学习的分类器来分类(这其实是基于 consistency rule 的换质位推理,具体见论文);反之如果 consistent,就标注为为见过的类,然后用任何 Conventional ZSL 的算法对其分类。在 OSR 里面,因为没有未见类别的信息,我们用见过类的 one-hot label(图中)作为生成反事实样本 *,如果和生成的样本在欧式距离下都很远(not consistent),就认为属于未见过的类,并标为“未知”,反之则用监督学习的分类器即可。
可以看到算法的核心要求是生成保真的样本,这样才能用 consistency rule 做推理。这个性质可以由 Counterfactual Faithfulness Theorem 来保证,简单来说就是:保真生成的充要条件是样本特征和类别特征之间解耦(disentangle)。我们通过三个 loss 实现:
-VAE loss:这个 loss 要求 encode 得到的,和样本自己的,可以重构样本,并且 encode 出来的要非常符合 isotropic Gaussian 分布。这样通过使的分布和无关实现解耦;
Contrastive loss:反事实生成的样本中,只和自己类别特征生成的样本像,和其他类别特征生成的样本都远。这个避免了生成模型只用 Z 里面的信息进行生成而忽略了,从而进一步的把的信息从里解耦;
GAN loss:这个 loss 直接要求反事实生成的样本被 discriminator 认为是真实的,通过充要条件,用保真来进一步解耦。
第四节 实验
在介绍实验前,值得注意的是 ZSL 常用的 Proposed Split 官方给的数据集之前有一个数据泄露的 bug,这使得一些方法在见过类别(S)的表现特别高。去年的时候官方网站上放出了 Proposed Split V2,解决了这个 bug。我们下面的实验都是在改过的数据集上跑的。
减轻见过和未见过类别识别率的失衡:下面的 tsne 显示了反事实生成的结果,可以看到通过 condition 样本特征(蓝星是未见类的样本,红星是见过的),生成的未见类别的样本确实保真了(在蓝点中间),得到的 decision boundary(黑线)也 balanced 了。这在 ZSL 的 4 个常用数据集上也体现了出来,我们的方法大幅提高了未见类别 (U) 的准确率,从而使得整体的准确率 H(harmonic mean) 提高了,达到了 SOTA 的表现。现有的方法其实也有一个简单的解决失衡的办法,就是直接调整见过类别的 logits,通过改变调整的幅度,我们可以得到一个见过类别和未见过类别的曲线,可以看到我们的方法(红线)在各个调整幅度下都更高,说明它能从根本上减轻失衡,这是简单的调整所不能完成的。
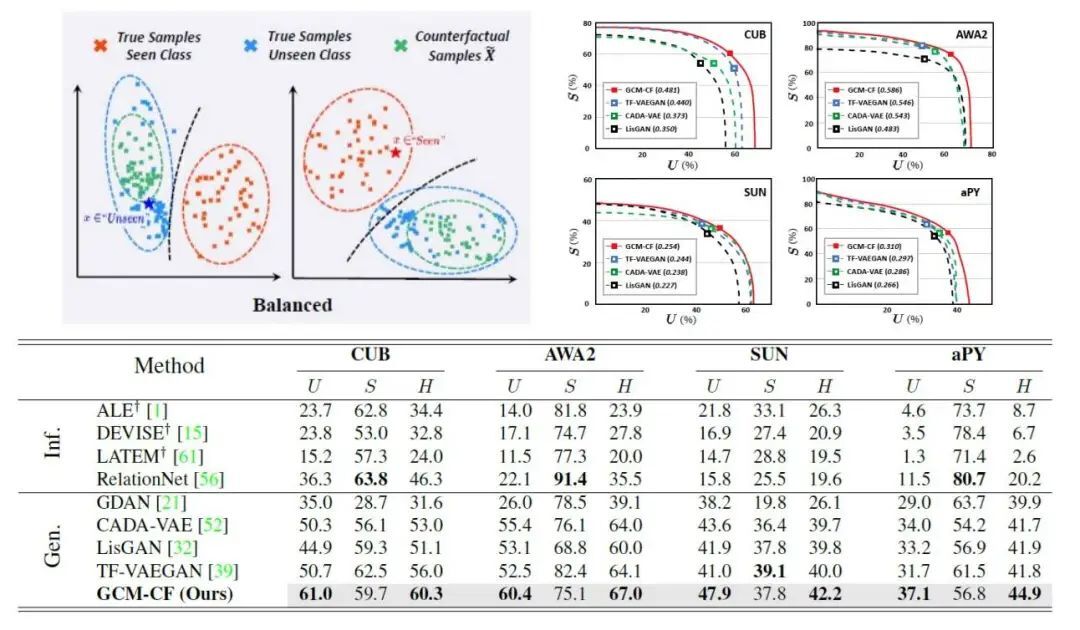
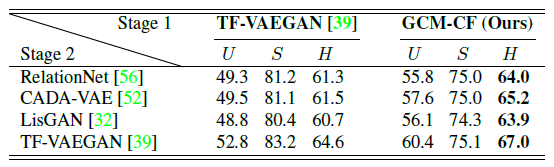
强大的见过 / 未见过类别的分类器:我们的方法能够适用任何的 conventional ZSL 算法,我们测试了 inference-based 的 RelationNet,和三个基于不同生成网络的 generation-based 的方法,发现加上我们的方法都获得了提高,并且超过了用现在 SOTA 的 TF-VAEGAN 作为见过 / 未见过的分类器的表现。
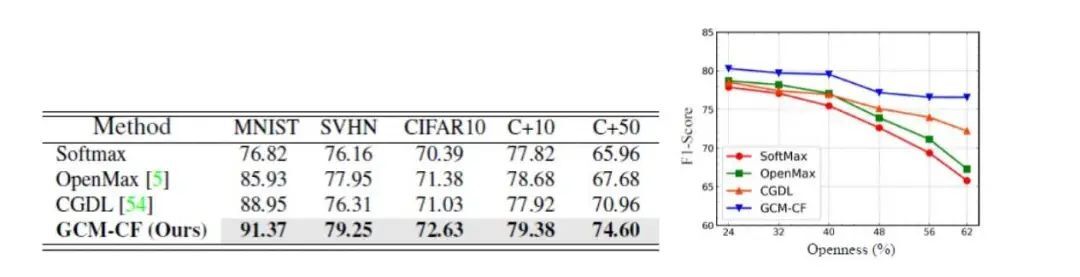
强大的开集分类器:我们在常用的几个数据集上做了开集识别的实验(用的 F1 指标),并取得了 SOTA 的表现。因为开集识别中未见过类别的数量是未知的,所以好的分类器必须在数量少和多的情况下都好,在右图中我们画了 F1 分数和未见过类别的数量(从少到多)的曲线,我们的方法(蓝色)在每个情况下都是最好,并且在未见类别很多的时候(蓝色曲线末尾)F1 基本没有下降,体现了较强的鲁棒性。
结语
这篇工作是我们对于解耦表示(disentangled representation)的一点点探究和摸索,把难以实现的所有 factor full disentangle,放宽成为两组概念(样本特征和类别特征)之间的 disentangle,并借着 disentangle 带来的 faithfulness 性质,使我们提出的反事实生成框架变为可能。这也从一个侧面反映了解耦是因果推理的一个重要的前提,当不同的概念被区分开(比如解耦的表示)时,我们就可以基于它们之间的因果关系进行推理,得到鲁棒、稳定、可泛化的结论。
我也看到一些对于解耦的悲观或是质疑,确实,目前就连解耦的定义都没有定论,更不要说方法、evaluation 等等了。但这些困难也是可预见的:解耦在帮助机器跨越一个层级,从学习观测到的数据中的规律,到探究这些数据产生的原因 — 就像人知道太阳每天会升起的规律是容易的,但明白为什么太阳会升起却花了几千年。这里也鼓励大家多多关注、探索解耦这个领域,说不定带来下一个突破的就是你啊。
最后附上论文的引用:
@inproceedings{yue2021counterfactual,
title={Counterfactual Zero-Shot and Open-Set Visual Recognition},
author={Yue, Zhongqi and Wang, Tan and Zhang, Hanwang and Sun, Qianru and Hua, Xian-Sheng},
booktitle= {CVPR},
year={2021}
}




