
在信息系统中,事情可以变得非常复杂,至少可以说是这样。像 Web 服务这样的典型信息系统,在其最基础的层次上,仅仅是一个巨大的、集成的数据管道中的一个过程。其主要工作是处理数据处理:获取数据,转换数据,并将数据传送给其他系统。但当其他系统都集中在上面时,复杂性就迅速增长。处理并减轻这种复杂性是开发团队面临的一大挑战。
通常,信息系统都是用软件编程的范式来实现的,例如,面向对象编程就是一种基于“对象”概念的方法,可以包括数据和代码。面向对象程序设计遵循无约束信息系统往往是复杂的,在这种情况下,很难对其进行理解和维护。
由于增加了系统复杂性,通常会导致开发团队的工作效率下降,因为这需要更多时间来增加系统的新功能。在生产中,难以诊断的问题经常发生。这些问题会使用户在系统表现不佳时感到沮丧,甚至更糟的是,导致系统停止工作。
面向对象编程的三个方面是复杂性的来源:
对象中的数据封装
类中非灵活的数据布局
状态突变
在很多情况下,对象内部的数据封装是有用的。但是,在现代信息系统中,数据封装常常会产生复杂的类层次结构,而类层次结构涉及到许多与其他对象的关系。
经过多年的发展,先进设计模式和软件框架的出现减轻了这种复杂性。但基于面向对象编程的信息系统仍然趋于复杂。
如果每个数据块都用一个类来表示,就有助于工具的使用(如编辑器中的自动完成),并且在编译时会检测到诸如访问不存在的字段之类的错误。但是,类布局的僵化使得数据无法灵活访问。这对于信息系统来说是非常痛苦的。每个数据的更改都有一个不同的类表示出来。举例来说,在一个处理客户的系统中,有一个代表数据库的类的客户,以及一个代表数据处理逻辑的类的客户。类似的数据有不同的字段名,但类的泛滥无法避免。这是因为数据“锁定”到了类中。
允许对象的状态发生突变这一事实是多线程信息系统中另一复杂因素。为避免数据被并发修改,并确保对象的状态保持有效,需要引入各种锁机制,使代码难以编写和维护。有时候,在向第三方库传递数据之前,我们会使用防御性复制策略来确保我们的数据没有被修改。添加锁机制或防御副本策略使得我们的代码更复杂,并且性能更差。
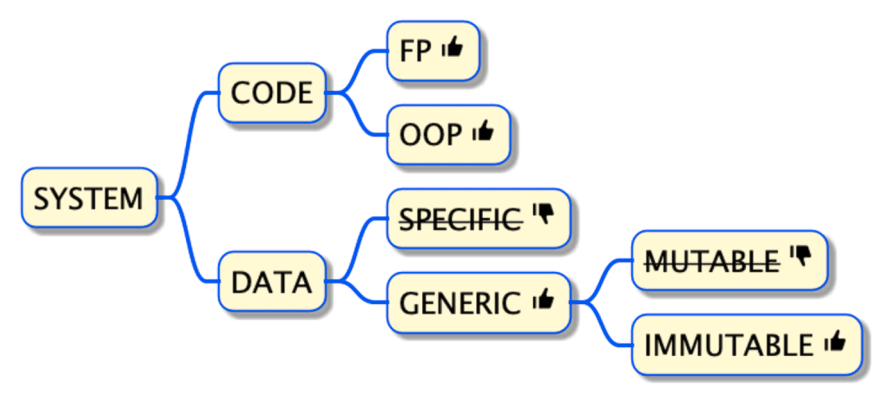
面向数据的编程(Data-Oriented Programming,DOP)是开发者为了降低信息系统复杂性而遵循的一组最佳实践。
DOP 背后的理念是,通过将数据作为“一等公民”来简化信息系统的设计和实施。DOP 引导我们把代码从数据中分离出来,以不可变的通用数据结构来表示数据,而非围绕数据和代码相结合的对象来设计信息系统。所以,在 DOP 中,开发者可以像在任何程序中一样灵活、稳定地操作数据,而不需要操作数字或字符串。
DOP 通过遵循三个核心原则,降低了系统的复杂性:
将代码与数据分离
用通用数据结构表示数据
保持数据不可变
在面向对象的编程语言中遵循 DOP 的一个可能的方法是,在静态类方法中编写接收其操作数据作为解释参数的代码。
把代码从数据中分离出来,从而实现关注点分离,常常会使类的层次结构变得不那么复杂:与其用一个由涉及许多关系的实体组成的类图来设计一个系统,不如由两个不相连的更简单的子系统组成:一个代码子系统和一个数据子系统。
在使用诸如哈希图和列表这样的通用数据结构来表示数据时,数据访问是灵活的,这样可以减少系统中类的数量。
如果开发者需要在多线程环境中编写代码,那么保持数据的不变将使他们更加顺利。不需要使用锁机制或防御性复制来保护代码,数据的有效性就有了保障。
DOP 原则既适用于面向对象的编程语言和函数式编程语言。但是,向 DOP 过渡对面向对象的开发者来说可能需要比函数式编程开发者更多的思维转变,因为 DOP 将让我们摆脱封装有状态类中数据的习惯。
作者介绍:
Yehonathan Sharvit,自 2000 年以来一直担任软件工程师,使用 C++、Java、Ruby、JavaScript、Clojure 和 ClojureScript 编程。他目前在 CyCognito 担任软件架构师,为大规模的数据管道建立软件基础设施。
原文链接:
https://dev.to/viebel/a-simple-way-to-reducing-complexity-of-information-systems-2d22




