
DolphinScheduler是由易观开源的一个分布式可伸缩的可视化工作流任务调度平台。
在我所工作的领域,DolphinScheduler 可以快速解决企业数据开发的十大痛点:
多源数据连接和访问:可以访问常见的数据源,不需要进行太多的修改就可以添加新数据源;
多样化、专业化、海量数据任务管理:围绕大数据(Hadoop 家族、Flink 等)任务调度问题展开,与传统调度器有明显的区别;
图形化的任务安排:提供了便捷的用户体验,可与商业产品竞争,尤其是针对大多数国外开源产品无法通过拖放直接生成数据任务的情况;
任务详情:丰富的任务查看、日志、时间运行轴显示,满足开发人员对数据任务精细化管理的需求,可帮助快速定位慢 SQL 和性能瓶颈;
支持各种分布式文件系统:丰富了用户可选择的非结构化数据选项;
原生多租户管理:满足大型组织的数据任务管理和隔离需求;
全自动分布式调度算法,均衡所有调度任务;
原生集群监控:可监控 CPU、内存、连接数、ZooKeeper 状态,适合中小型企业的一站式运维;
原生任务告警功能:最大限度降低任务操作风险;
强大的社区运营:倾听用户真实的声音,不断添加新功能,持续优化用户体验。
DolphinScheduler 以早期微服务技术为基础,采用了服务注册表的概念,使用 ZooKeeper 对集群进行分布式管理(很多大数据技术都使用 ZooKeeper 进行去中心化集群管理)。Worker 主节点可以任意添加,也可以单独部署 API 管理和告警管理。作为企业级技术模块,它实现了微服务隔离、独立部署、模块化管理等技术特点。然而,在容器化云原生应用快速发展的时代,这种技术模式存在一些不足:
需要从头部署,无论是安装在物理机器还是虚拟机器上。一个 DolphinScheduler 节点需要数百个 shell 操作,一个包含多个节点的集群可能需要数千个 shell 操作;
标准的企业级 DolphinScheduler 涉及大量的基础设施环境管理,通常需要 8 个以上的节点、主机和 IP 地址。这些基础设施信息给管理带来了一定的困难;
添加节点需要执行一系列操作,如安装 Java、配置主机、设置 DS Linux 用户、设置无密码登录、修改安装节点配置文件,而且需要停止并重启整个集群;
大型企业通常有多个集群用于支持不同的业务,这会造成大量的重复性工作;
调度器具有一定的可观测性功能,但不能与主流工具集成;
总的说来,调度器仍然需要进行日常的检查,例如诊断 Java 核心进程异常退出问题;
对于不同需求和场景下的调度器配置,没有有效的管理机制或工具。
解决这些技术缺陷的核心想法是:
如何将 DolphinScheduler 集成到当今主流的云原生技术中;
如何以较少的人力资源部署 DolphinScheduler,能否实现全自动集群安装部署模式;
如何拥有一个完全无服务器的 DolphinScheduler,并大大降低配置管理成本;
如何标准化技术组件实现规范;
是否能在无人监督的情况下运行,系统是否能自我修复;
如何将其集成到现有的可观测平台中。
利用 Kubernetes 技术
作为云原生技术的事实上的标准,Kubernetes 给整个 IT 应用技术体系带来了革命性的改变。Kubernetes 主要以服务注册和发现、负载均衡、自动发布和回滚、容器隔离、软件自我修复和分布式配置管理等核心技术为基础。
不仅仅是 Kubernetes,我们的团队还集成了来自 CNCF(云原生计算基金会)的许多优秀项目,开展了以下工作:
对 DolphinScheduler 的部署技术进行了改进。我们使用 Helm 和 Argo CD 来极大简化一键式部署。
使用 Argo CD 实现了 GitOps 配置内容管理机制,使 DevOps 具备了完整的审计能力。
Kubernetes 的 Pod 水平自动伸缩技术大大降低了伸缩应用程序的操作难度。
Kubernetes 标准化的健康探测技术让调度器的所有技术组件具有强大的自我修复能力。
Kubernetes 和 Argo CD 的滚动发布技术让 DolphinScheduler 工具实现了优雅而简单的升级。
Kube-Prometheus 技术的使用为 DolphinScheduler 带来了标准化的可观测性。
强大的 UI 技术简化了 CMDB 可视化管理、基于 Kubernetes 的组件配置管理、应用程序日志管理等。
我们还向 DolphinScheduler 引入了更强大的工具,以获得更丰富的云原生功能:
通过 Kubernetes 服务注册发现和摄入技术实现了更容易的服务访问;
引入的 Linkerd 为 DolphinScheduler 带来了服务网格功能,提高了所有 API 的管理和监控能力;
将 DolphinScheduler 与 Argo 工作流或标准 Kubernetes 作业相结合;
引入了对象存储技术 MinIO,统一了非结构化数据存储技术。
我们所做的工作都是为了使 DolphinScheduler 更强大、运行更稳定、要求更少的运营时间、具备更好的可观测性、更丰富更完整的生态。
向云原生平台的初步过渡
为了完全拥抱云原生技术,DolphinScheduler 首先需要快速实现云原生部署和操作,即将大多数企业应用程序迁移到 Kubernetes 环境中。
感谢开源社区的贡献,我们快速构建了 DolphinScheduler 的 JAR 包 Docker 镜像,并使用 Helm 工具包实现了基于 Kubernetes 的声明式部署脚本。成为 Kubernetes 托管对象是集成到云原生最重要的一步。这些不仅让云原生用户和组织更方便、更快地使用工具,而且大大提高了 DolphinScheduler 用户的工作效率。
要在 Kubernetes 上部署 DolphinScheduler,你可以这么做:
从 GitHub 下载dolphinscheduler-1.3.9.tar.gz,在./dolphinscheduler-1.3.9/docker/kubernetes/dolphinscheduler 文件夹中找到 Helm 包。
使用下面的命令部署 DolphinScheduler 实例:
kubectl create ns ds139helm install dolphinscheduler . -n ds139
有时候,为了进行 ETL 和连接数据库,DolphinScheduler 用户需要集成 DataX、MySQL JDBC 驱动程序或 Oracle JDBC 驱动程序。我们可以下载必要的组件,构建新的 Docker 镜像,并升级 DolphinScheduler 实例:
#Download the additional componentshttps://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.49/mysql-connector-java-5.1.49.jarhttps://repo1.maven.org/maven2/com/oracle/database/jdbc/ojdbc8/https://github.com/alibaba/DataX/blob/master/userGuid.md#Create a new docker image with new tag by this DockerfileFROM apache/dolphinscheduler:1.3.9COPY *.jar /opt/dolphinscheduler/lib/RUN mkdir -p /opt/soft/dataxCOPY datax /opt/soft/datax#Edit image tag of helm value.yaml file, and execute helm upgrade.helm upgrade dolphinscheduler -n ds139
一般来说,我们建议在生产环境中使用独立部署的外部 PostgreSQL 作为管理数据库。我们发现,在切换到外部数据库后,即使完全删除并重新部署 Kubernetes 中的 DolphinScheduler,也不需要重新创建 DolphinScheduler 的应用程序数据(例如,用户定义的数据处理任务)。这再次证明了系统具备高可用性和数据完整性。此外,我们建议为 DolphinScheduler 组件配置 PersistentVolume,因为如果 Pod 重启或升级,DolphinScheduler 的历史应用程序日志将会丢失。
与传统模型中使用上百个 shell 命令的操作相比,我们只需要修改一个配置文件,再加上一行安装命令,就可以自动安装 DolphinScheduler 的 8 个组件,节省了大量的人工成本,减少了大量的操作错误。如果有多个 DolphinScheduler 集群,这将大大降低人力成本,业务部门的等待时间将从几天减少到不到一小时,甚至可能是十分钟。
加入 GitOps(Argo CD)
Argo CD 是一种声明式的GitOps持续交付工具,它基于 Kubernetes 和 CNCF 的孵化项目,是 GitOps 的最佳实践工具。
GitOps 可以为 DolphinScheduler 带来以下的好处。
图形化和一键式安装集群软件;
Git 可以记录完整的发布过程,并支持一键回滚;
方便的 DolphinScheduler 工具日志查看。
然后,我们可以看到由 Argo CD 自动部署的 Pod、configmap、secret、service、ingress 和其他资源,它还会显示提交信息和用户名,完全记录了所有的发布事件信息。与此同时,你还可以一键回退到历史版本。
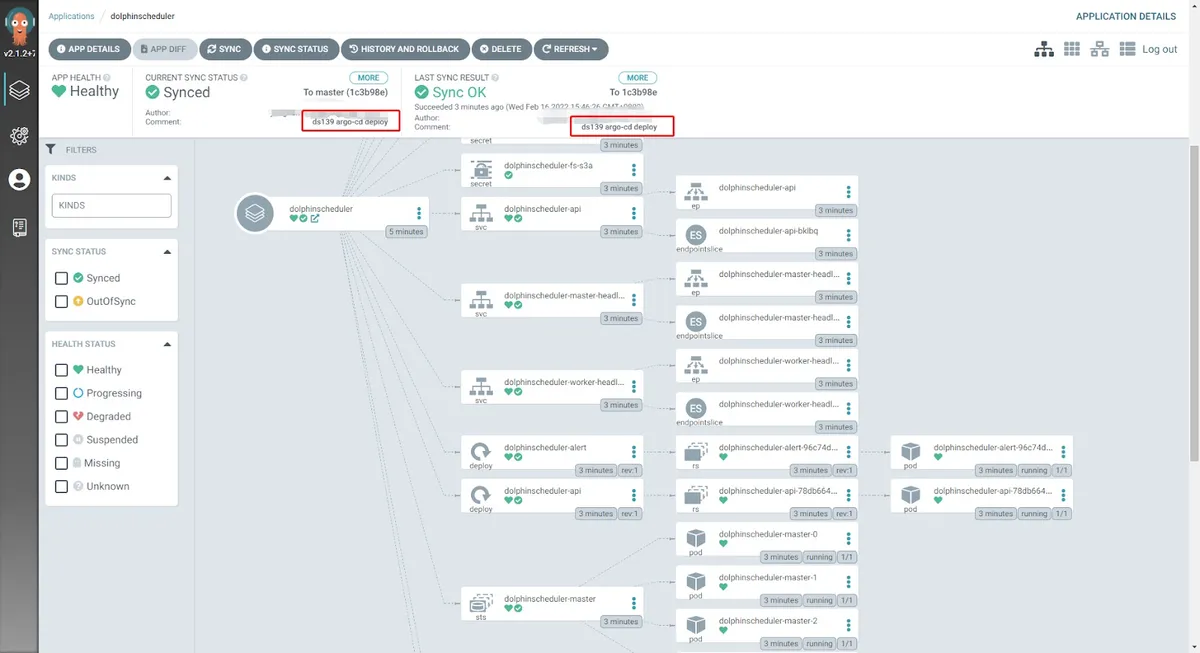
通过 kubectl 命令可以查看相关的资源信息:
[root@tpk8s-master01 ~]# kubectl get po -n ds139 NAME READY STATUS RESTARTS AGEDolphinscheduler-alert-96c74dc84-72cc9 1/1 Running 0 22mDolphinscheduler-api-78db664b7b-gsltq 1/1 Running 0 22mDolphinscheduler-master-0 1/1 Running 0 22mDolphinscheduler-master-1 1/1 Running 0 22mDolphinscheduler-master-2 1/1 Running 0 22mDolphinscheduler-worker-0 1/1 Running 0 22mDolphinscheduler-worker-1 1/1 Running 0 22mDolphinscheduler-worker-2 1/1 Running 0 22m[root@tpk8s-master01 ~]# kubectl get statefulset -n ds139 NAME READY AGEDolphinscheduler-master 3/3 22mDolphinscheduler-worker 3/3 22m[root@tpk8s-master01 ~]# kubectl get cm -n ds139 NAME DATA AGEDolphinscheduler-alert 15 23mDolphinscheduler-api 1 23mDolphinscheduler-common 29 23mDolphinscheduler-master 10 23mDolphinscheduler-worker 7 23m[root@tpk8s-master01 ~]# kubectl get service -n ds139NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEDolphinscheduler-api ClusterIP 10.43.238.5 <none> 12345/TCP 23mDolphinscheduler-master-headless ClusterIP None <none> 5678/TCP 23mDolphinscheduler-worker-headless ClusterIP None <none> 1234/TCP,50051/TCP 23m[root@tpk8s-master01 ~]# kubectl get ingress -n ds139 NAME CLASS HOSTS ADDRESSDolphinscheduler <none> ds139.abc.com
你还可以看到,所有的 Pod 部署在 Kubernetes 集群的不同主机上,例如,worker 1 和 worker 2 位于不同的节点上。

在配置好了 ingress 后,我们就可以使用域名来访问公司内网中的 DolphinScheduler Web UI。我们以 DNS 子域名 abc.com 为例:http://ds139.abc.com/dolphinscheduler/ui/#/home。我们可以在 Argo CD 上查看 DolphinScheduler 每个组件的内部日志:
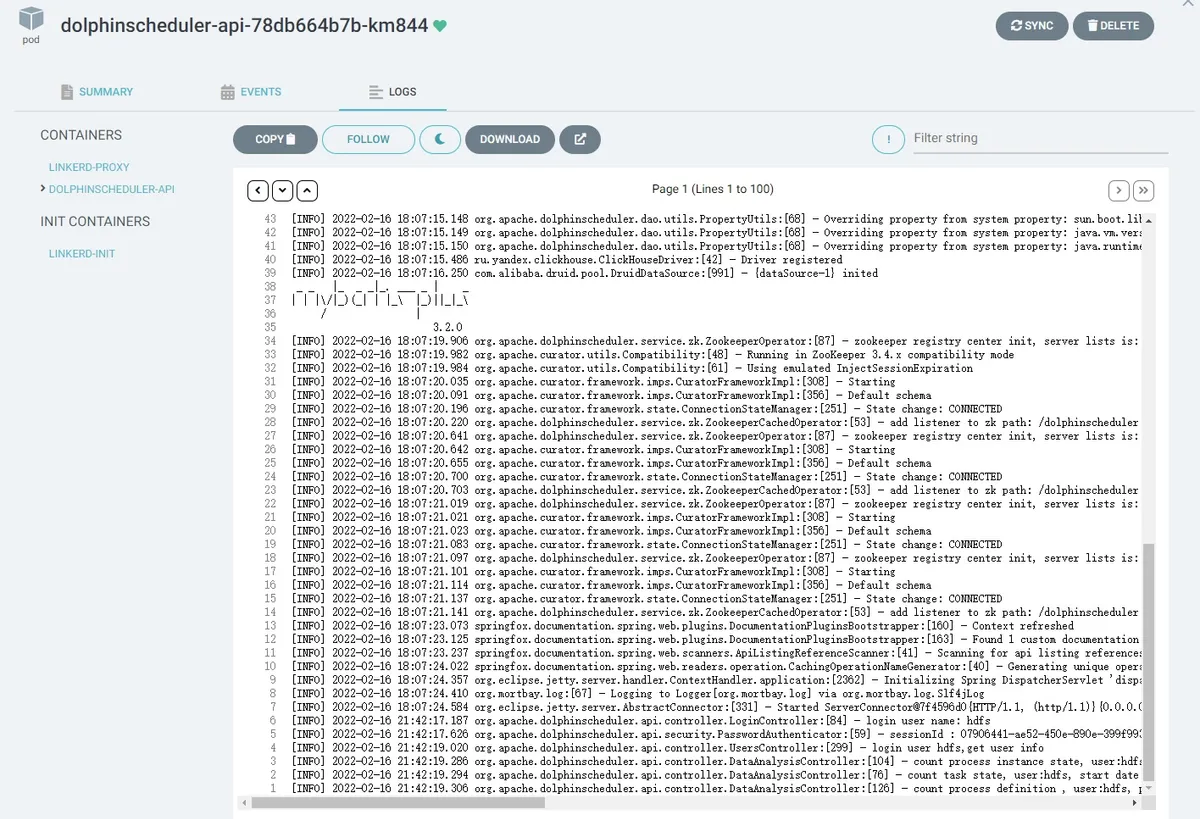
有了 Argo CD,我们就可以非常方便地修改组件(如 master、worker、API 或 alert)的副本数量。DolphinScheduler 的 Helm 配置还保留了 CPU 和内存的设置信息。我们修改了 value.yaml 文件中的副本设置。修改好之后,我们将其推送到公司内部的源代码系统:
master: podManagementPolicy: "Parallel" replicas: "5"worker: podManagementPolicy: "Parallel" replicas: "5"alert: replicas: "3"api: replicas: "3"
只需在 Argo CD 上点击“同步”即可开始同步,并根据需要添加相应的 Pod。
[root@tpk8s-master01 ~]# kubectl get po -n ds139 NAME READY STATUS RESTARTS AGEDolphinscheduler-alert-96c74dc84-72cc9 1/1 Running 0 43mDolphinscheduler-alert-96c74dc84-j6zdh 1/1 Running 0 2m27sDolphinscheduler-alert-96c74dc84-rn9wb 1/1 Running 0 2m27sDolphinscheduler-api-78db664b7b-6j8rj 1/1 Running 0 2m27sDolphinscheduler-api-78db664b7b-bsdgv 1/1 Running 0 2m27sDolphinscheduler-api-78db664b7b-gsltq 1/1 Running 0 43mDolphinscheduler-master-0 1/1 Running 0 43mDolphinscheduler-master-1 1/1 Running 0 43mDolphinscheduler-master-2 1/1 Running 0 43mDolphinscheduler-master-3 1/1 Running 0 2m27sDolphinscheduler-master-4 1/1 Running 0 2m27sDolphinscheduler-worker-0 1/1 Running 0 43mDolphinscheduler-worker-1 1/1 Running 0 43mDolphinscheduler-worker-2 1/1 Running 0 43mDolphinscheduler-worker-3 1/1 Running 0 2m27sDolphinscheduler-worker-4 1/1 Running 0 2m27s
不仅是 Helm,基于 Argo CD 的 GitOps 技术也为整个 DolphinScheduler 工具提供了图形化、自动化、可跟踪、可审计的强大 DevOps、回滚和监控功能,而无需对 DolphinScheduler 进行任何代码修改。
为 DolphinScheduler 添加自我修复能力
众所周知,当今的 IT 环境总是处于一个不稳定的状态。换句话说,我们的技术系统将服务器、操作系统和网络的各种故障视为发生在集群中的常规事件。当用户无法通过浏览器正常访问 DolphinScheduler 的任务管理页面,或者当 DolphinScheduler 无法正常运行大数据任务时,为时已晚。
在 DolphinScheduler 迁移成云原生之前,它只能依靠日常监控来检查 master/worker/API 和其他组件是否正常运行,比如使用 DolphinScheduler 的管理 UI,或通过 jps 检查 Java 进程是否存在。当一家企业有数百个调度环境时,不仅成本会很高,更重要的是,系统的可用性也会面临巨大的风险。
值得注意的是,Kubernetes 本身可以为部署类型标准化的有状态应用程序进行自动重启和恢复,甚至 CRD(定制资源定义)本身也可以自动重启和恢复。当应用程序出现故障时,一个异常事件会被记录下来,然后重新拉取应用程序并重启,Kubernetes 会记录 Pod 重启的次数,帮助技术人员快速定位故障。
除了标准化的自我修复能力外,还有主动健康监测方法,即构建一个服务接口,通过 livenessProbe 主动探测正在运行 DolphinScheduler 的 Pod,当检测到的故障超过重试次数后将自动重启 Pod。此外,通过使用 readinessProbe,Kubernetes 集群可以在探针捕获到异常时自动切断到异常 Pod 的流量,并在异常事件消失后自动恢复到异常 Pod 的流量。
livenessProbe: enabled: true initialDelaySeconds: "30" periodSeconds: "30" timeoutSeconds: "5" failureThreshold: "3" successThreshold: "1"readinessProbe: enabled: true initialDelaySeconds: "30" periodSeconds: "30" timeoutSeconds: "5" failureThreshold: "3" successThreshold: "1"增强 DolphinScheduler 的可观测性
我们知道,Prometheus 已经是云原生系统中监控工具的事实上的标准,将 DolphinScheduler 的标准监控纳入 Prometheus 系统对我们来说意义重大。Kube-Prometheus 技术可以监控 Kubernetes 集群中的所有资源。有状态集合、命名空间和 Pod 是 DolphinScheduler 的三个主要资源特性。借助 Kube-Prometheus 技术可以自动实现对 CPU、内存、网络、IO、复制等资源的日常监控,无需任何额外的开发和配置。
我们利用 Kubernetes 中的 Kube-Prometheus 操作技术,在部署后自动监控 DolphinScheduler 各个组件的资源。但需要注意的是,Kube-Prometheus的版本需要与 Kubernetes 的主版本相对应。
服务网格集成
作为数据服务提供者,DolphinScheduler 将服务网格技术集成到内部服务治理系统中,实现了服务链接的可观察性管理。
DolphinScheduler 不仅需要一般的资源监控,还需要对服务调用链进行监控的技术。借助服务网格技术,实现了 DolphinScheduler 内部服务调用和 DolphinScheduler API 外部调用的可观测性分析,优化了 DolphinScheduler 产品的服务。
此外,作为数据工具的服务组件,DolphinScheduler 可以通过服务网格工具无缝集成到企业内部的服务模式中。它可以在不修改 DolphinScheduler 代码的情况下启用 TLS 服务通信、客户端服务通信重试和跨集群服务注册发现等功能。
我们集成了 Linkerd,将其作为我们的服务网格,它也是 CNCF 的一个优秀的项目。通过修改 value.yaml 文件中的 annotations,并重新部署,就可以为 master、worker、API、警报和 DolphinScheduler 的其他组件快速注入网格代理边车。
annotations: linkerd.io/inject: enabled
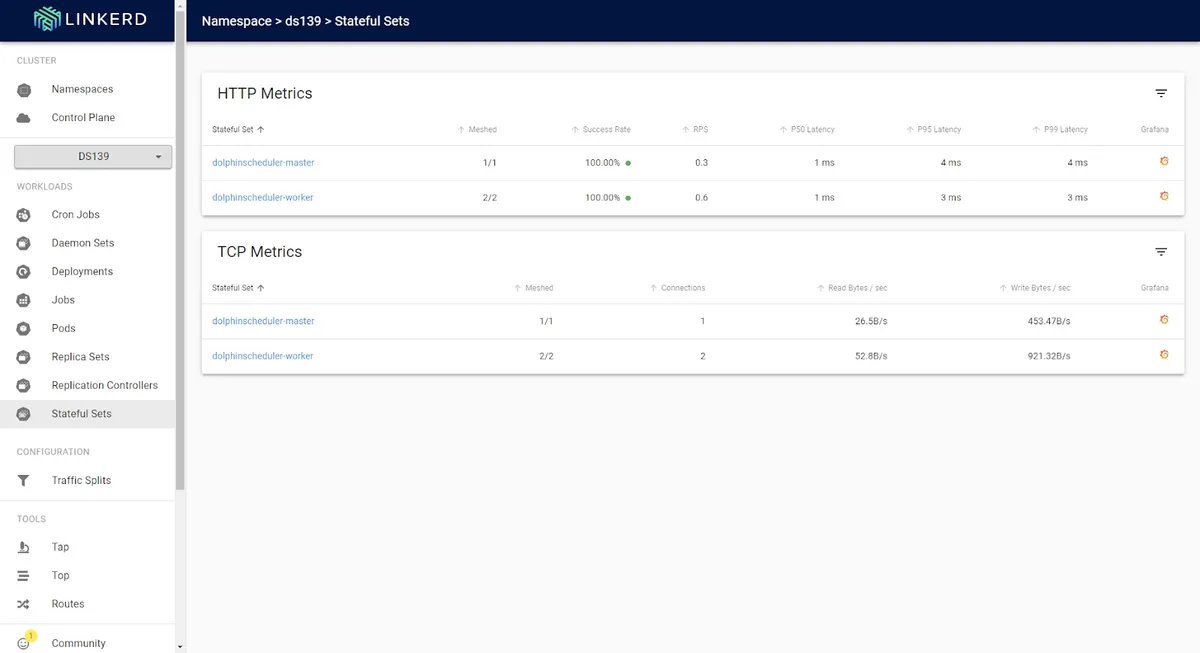
你还可以观察组件之间的服务通信质量,包括每秒请求数。
加入云原生工作流调度能力
要成为真正的云原生调度工具,DolphinScheduler 需要能够调度云原生作业流。
由 DolphinScheduler 调度的任务都是在固定的 Pod 中执行的。在这样的模式下,对任务开发技术的隔离性具有较高的要求。
特别是在 Python 语言环境中,一个团队中会有不同版本的 Python 基本包和依赖包,版本之间的差异甚至可能出现数百种组合。一个细小的依赖包差异将导致 Python 程序运行错误。这也是阻止 DolphinScheduler 运行大量 Python 应用程序的障碍。我们推荐下面的方法,快速将 DolphinScheduler 与 Kubernetes 作业系统集成,具有强大的任务隔离性和并发能力:
使用标准的 Kubernetes API 提交作业。你可以直接通过 kubectl 命令或 REST API 提交任务。
将 kubectl 命令文件上传到 DolphinScheduler,并通过 DolphinScheduler 的 shell 任务来提交。
使用 Argo Workflows 的 Argo CLI 命令或 Rest API 命令提交作业。
无论是 Kubernetes 还是 Argo Workflows,都需要添加 watch 功能,因为 Kubernetes 是异步的,需要等待任务完成。
这里我们使用了 Argo Workflows,我们可以在 DolphinScheduler 创建一个新的 shell 任务或步骤,并粘贴下面的命令。我们可以将普通的数据作业(如数据库 SQL 作业、Spark 作业或 Flink 作业)和云原生作业组合在一起,执行一个更加全面的作业流。例如,这是一个 Hive SQL 任务,用于导出 Web 应用程序的用户点击数据:
beeline -u "jdbc:hive2://192.168.1.1:10006" --outputformat=csv2 -e "select * from database.user-click" > user-click.csv
这个示例作业是一个 Python Tensorflow 任务,通过训练数据来构建机器学习模型。这个作业通过 HTTP 来运行。首先,我们运行作业:
#通过HTTP执行Python Tensorflow作业curl --request POST -H "Authorization: ${ARGO_TOKEN}" -k \ --url https://argo.abc.com/api/v1/workflows/argo \ --header 'content-type: application/json' \ --data '{ "namespace": "argo", "serverDryRun": false, "workflow": { "metadata": { "name": "python-tensorflow-job", "namespace": "argo" }, "spec": { "templates": [ { "name": "python-tensorflow", "container": { "image": "tensorflow/tensorflow:2.9.1", "command": [ "python" ], "args": [ "training.py" ], "resources": {} } } ], "entrypoint": "python-tensorflow", "serviceAccountName": "argo", "arguments": {} } } }'
然后我们可以查看作业的信息和状态:
#通过HTTP查看Python Tensorflow作业的和状态curl --request GET -H "Authorization: ${ARGO_TOKEN}" -k \ --url https:/argo.abc.com/api/v1/workflows/argo/python-tensorflow-job将文件系统从 HDFS 升级到 S3
分布式算法是云原生赋能的一个领域,例如谷歌的 Kubeflow 技术,它完美地结合了 TensorFlow 和 Kubernetes。分布式算法通常会使用文件,而 S3 是存储易于访问的大数据文件的事实上的标准。当然,DolphinScheduler 还集成了 MinIO 技术,通过简单的配置即可实现 S3 文件管理。
首先修改 value.yaml 文件的 configmap 部分,指定 MinIO 服务器。
configmap: DOLPHINSCHEDULER_OPTS: "" DATA_BASEDIR_PATH: "/tmp/dolphinscheduler" RESOURCE_STORAGE_TYPE: "S3" RESOURCE_UPLOAD_PATH: "/dolphinscheduler" FS_DEFAULT_FS: "s3a://dfs" FS_S3A_ENDPOINT: "http://192.168.1.100:9000" FS_S3A_ACCESS_KEY: "admin" FS_S3A_SECRET_KEY: "password"
MinIO 中保存文件的桶的名字叫“dolphinscheduler”。用户通过 DolphinScheduler UI 上传的共享文件都保存在这个文件夹中。
结论
作为新一代云原生大数据工具,DolphinScheduler 有望在未来集成 Kubernetes 生态系统中更多优秀的工具和功能,以满足更多多样化用户群体和场景的需求。我们目前路线图中的一些项目包括:
利用边车定期删除 worker 作业日志,实现轻松的操作和维护;
与 Argo Workflows 进行更多的集成,用户可以通过 API、CLI 等方式在 DolphinScheduler 中调用 Argo Workflows 进行单个作业、DAG 作业和周期性作业;
使用 HPA(水平 Pod 自动伸缩)自动伸缩 DolphinScheduler 组件,以实现更有弹性的运行环境和处理不确定的工作负载;
集成 Spark 和 Flink Operator,实现全面的基于云原生的分布式计算;
实现多云、多集群的分布式作业调度,强化无服务器和 FAAS 的架构属性。
想要了解更多关于 DolphinScheduler 的信息,或者想要加入开发者社区,请通过我们的Slack频道联系我们。
作者简介:
Yang Dian 是深圳城市交通规划中心的副总工程师。他目前的技术专长主要是关于数据算法平台实现和云原生转型。他曾参与中国顶级物流企业的 IT 架构咨询项目。
原文链接:
Embracing Cloud-Native for Apache DolphinScheduler with Kubernetes: a Case Study




