
数据仓库项目跨功能需求开发不够完善,导致的各种问题,就我个人经验来说,主要体现在数据建模不够标准和 ETL 日志体系不够完善两个方面,本文会详细介绍一下,如何从跨功能需求的角度,构建标准的数据建模和完善的 ETL 日志体系。
对于一个软件来说,分为功能需求和跨功能需求(Cross-Functional Requirements, CFR)。功能需求,一般是我们可以看见的,就是实现了什么功能,提供了什么服务。而跨功能需求,是隐性的,容易被忽略,通常被称为非功能需求(Non-Functional Requirements, NFR)。以下是维基百科对非功能需求的定义(内容虽然多,删除哪句都舍不得):
In systems engineering and requirements engineering, a non-functional requirement (NFR) is a requirement that specifies criteria that can be used to judge the operation of a system, rather than specific behaviors. They are contrasted with functional requirements that define specific behavior or functions. The plan for implementing functional requirements is detailed in the system design. The plan for implementing non-functional requirements is detailed in the system architecture, because they are usually architecturally significant requirements.
Broadly, functional requirements define what a system is supposed to do and non-functional requirements define how a system is supposed to be. Functional requirements are usually in the form of “system shall do “, an individual action or part of the system, perhaps explicitly in the sense of a mathematical function, a black box description input, output, process and control functional model or IPO Model. In contrast, non-functional requirements are in the form of “system shall be “, an overall property of the system as a whole or of a particular aspect and not a specific function. The system’s overall properties commonly mark the difference between whether the development project has succeeded or failed.
Non-functional requirements are often called “quality attributes” of a system. Other terms for non-functional requirements are “qualities”, “quality goals”, “quality of service requirements”, “constraints”, “non-behavioral requirements”, or “technical requirements”. Informally these are sometimes called the “ilities”, from attributes like stability and portability. Qualities—that is non-functional requirements—can be divided into two main categories:
Execution qualities, such as safety, security and usability, which are observable during operation (at run time).
Evolution qualities, such as testability, maintainability, extensibility and scalability, which are embodied in the static structure of the system.
开发过程中,在跨功能需求上的成本,难度和工作量,是要远远大于功能需求的,需要让非技术人员意识到要实现这些跨功能需求所需要的额外的工作量。功能需求的实现,更多的是依赖于对业务的理解力,而跨功能需求的实现,是对技术人员的挑战。例如早几年的 12306 和淘宝的双十一,都是典型的功能需求实现完美,但是跨功能需求缺陷的经典案例。
在数据仓库项目上,跨功能需求主要体现在以下几点:
服务器发生异常,数据发生异常,如何保证 ETL 的真正幂等性
数据源的数据变更与数仓脱节,如何做到数据问题事前发现,避免数据污染
数据指标的处理过程复杂,口径问题频发,如何做到清晰的血缘关系,快速排查
业务需求变更频繁,如何快速接入新的数据源,实现数据真正打通
数据量大,计算逻辑复杂,如何在规定的时间窗口内实现数据落地
针对以上数仓项目跨功能需求开发不够完善,导致的各种问题,就我个人经验来说,主要体现在数据建模不够标准和 ETL 日志体系不够完善两个方面,下面详细的介绍一下,如何从跨功能需求的角度,构建标准的数据建模和完善的 ETL 日志体系。
数据建模
什么是数据建模
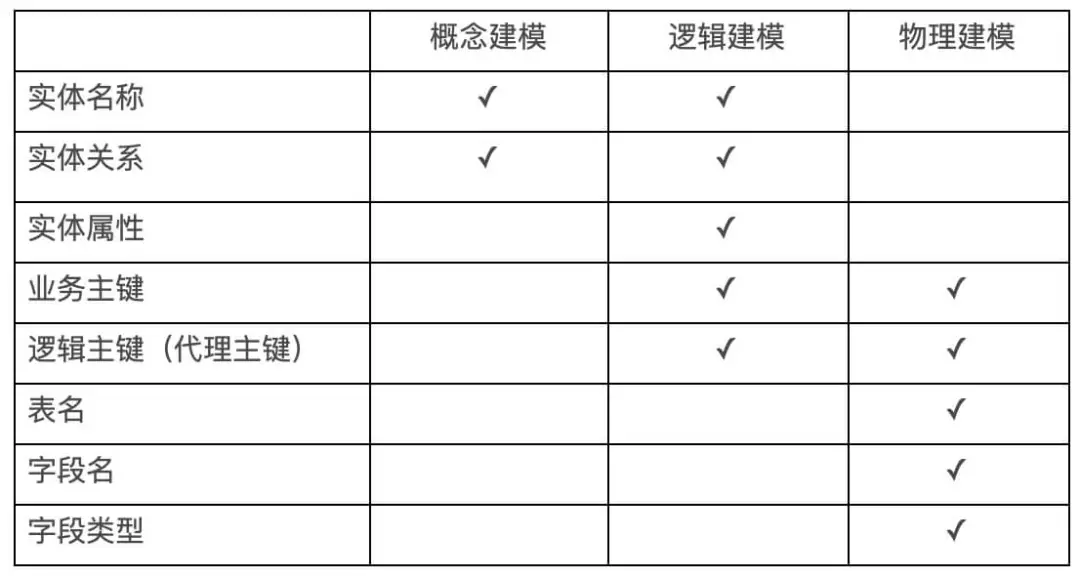
数据建模是探索数据结构的行为,建模的过程与应用开发中的类建模类似,创建实体,用属性填充实体,设置关联,最后实例化到数据存储,区别在于,类建模有数据和行为,而数据建模只有数据。数据建模关注的是需要什么样的数据以及应该如何组织它,而不是对数据执行什么操作。在数据项目中,数据建模一直处于核心地位,是整个数据仓库(包括传统数据仓库和现代数据仓库)的难点和基石。数据建模不是我们的最终目的,我们需要的是一个健壮,性能优越,易扩展,易使用的平台。ANSI(美国国家标准学会)指出数据建模主要包括以下三个阶段:
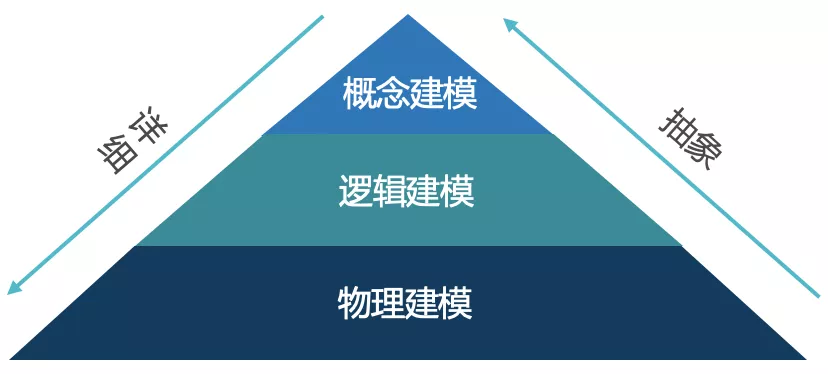
1、概念建模:自上而下创建数据模型,精确的描述业务组织,构建业务的总体结构,并给出主题领域的信息。由实体类型和关系组成。在这个过程中,未声明主键,未指定实体属性。这一阶段的产出虽然相对简单,但是过程至关重要,是决定数据建模好坏的关键。我们需要与业务用户深入交流,从业务的角度出发,尽量全的构建数据全景图。我们可以不去考虑现有数据,只考虑在特定业务场景下,应该有什么数据。根据数据全景图,定义所需的实体,以及实体和实体之间的关系。需要注意的是,在定义实体的边界时,没有一个正确的标准的方法,但是必须遵循统一的划分维度。
2、逻辑建模:逻辑模型定义实体的数据结构和实体之间的关系,在此过程需要定义业务主键和逻辑主键,规范化实体属性,以及细化实体之间的关联关系,同时定义数据源。在这一阶段,需要确认数据的管理者,数据的生产者以及数据的规范,需要确认数据的更新频率,粒度,保存时长以及维度口径定义。
3、物理建模:通过数据库规则,将逻辑模型实例化为物理数据模型。物理数据模型可能与逻辑数据模型不同,不同数据库的物理数据模型也可能不同。这一阶段是数据建模中最复杂的阶段,我们重点需要考虑的是数据的分层。数据分层的价值主要体现在以下几点:
有助于降低数据处理各阶段的耦合程度,清晰的定义数据处理各阶段的界线,有助于提高用户追踪异常的效率,降低运维成本
有助于评估、分析及追踪数据在不同处理阶段所消耗的系统资源,不同层次可以使用不同的计算引擎或者存储,调整优化硬件配置
有助于数据复用,模型复用,降低开发成本,提高开发效率
注意:在数据仓库项目中,物理表可以存在逻辑主键,但是不要存在物理主键和物理外键,数据完整性和一致性需要通过 ETL 保证。
三个阶段的工作内容以图表方式,展示如下:
数据建模的价值
面对不断增长的数据量和越来越丰富的数据源,我们面临的挑战是如何理解这些数据,并提供对业务有价值的信息。数据建模是一个语义层,是连接业务和物理存储的通道。需要我们充分理解业务术语,同时提供正确的信息,供业务人员灵活的查询。
如果我们在数据库设计中满足了业务需求,从企业所持有的大量数据中释放相关信息,就可以做到从最详细的信息到高层次的概述,提供组织各级绩效的准确报告,同时,根据历史数据可以对未来事件做出准确预测,使业务用户能够对公司战略做出明智的选择。
通过数据建模,我们可以应对许多数据挑战。可以将正确的业务信息传递给业务用户。主要价值体现在:
对业务进行全方位的梳理,构建数据的全方位视角
通过对源系统的透彻理解,缩短重复开发时间
提高数据结果的准确性
提高透明度,使业务用户和开发人员能够了解他们可以获得的信息
有助于降低业务复杂度,降低数据处理各阶段的耦合度
有助于评估、分析及追踪数据在不同处理阶段所消耗的系统资源,并依此进行调整,优化硬件资源配置
数据建模的方法
在数据仓库领域,业界常用的数据建模方法有以下两个:范式建模、维度建模。
范式建模
范式建模法是我们构建数据模型常用的一个方法,该方法主要由 Inmon 所提倡,我们在应用类关系型数据库中,大部分采用的是三范式建模法。由于范式建模与应用类的三范式建模区别不大,在这里就不做过多介绍了。
维度建模
维度建模是在数据仓库领域,最常使用的建模方法。由 Kimball 提出这一概念,按照事实表,维度表来构建数据仓库。最常用的就是星型模式(Star-schema)和雪花型模式(Snowflake Schema)。星型模式牺牲了性能,减少了维护成本。雪花型模式提高了性能,增加了维护成本。总体来说,维度建模通过增加数据冗余,提高了查询的便捷,但是同时,为了保证数据的一致性,也增加了 ETL 的复杂度。
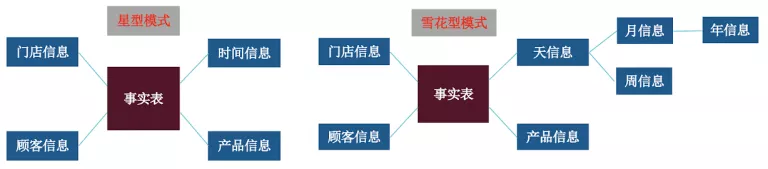
下面介绍一下维度建模的常用术语:
维度:一类描述信息。例如,时间维度。
属性:维度中的级别。例如,月是时间维度中的一个属性。
层次结构:表示维度中不同属性之间关系的级别规范。例如,时间维度中一个可能的层次结构是年→季度→月→日。
事实表:事实表是包含度量值的表。例如,销售额是一个度量值。此度量值以维度设计的粒度存储在事实表中。例如,它可以是按商店每天的销售额。在这种情况下,事实表将包含三列:日期 ID 列、商店 ID 列和销售额列。注意:事实表的汇总粒度,取决于事实表中包含的维度信息。
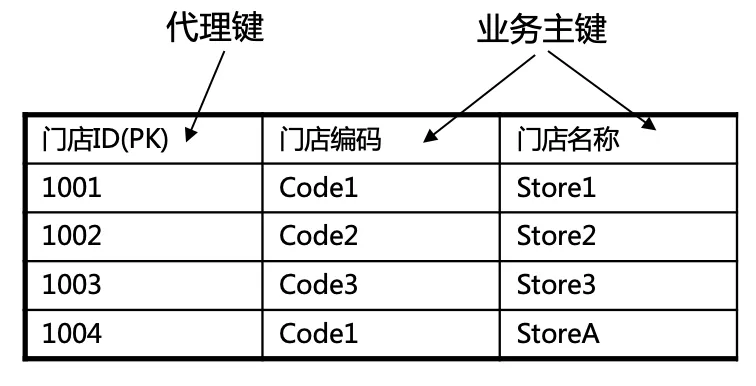
代理键:在维度建模中,一般使用一个系统分配的虚拟主键,来表示一个维度的唯一性,该虚拟主键存在于事实表中。例如如下例子,业务主键为复合主键,需要生成一个虚拟主键为代理键。
维度渐变:这是数据仓库常见的问题之一,表示维度数据随着时间的变化而变化,但是数据仓库要保留历史痕迹。例如如下的例子,门店的业务主键为门店名称,当门店类型发生变更时,门店 ID 跟着改变,这样可以保留门店信息变更的历史。
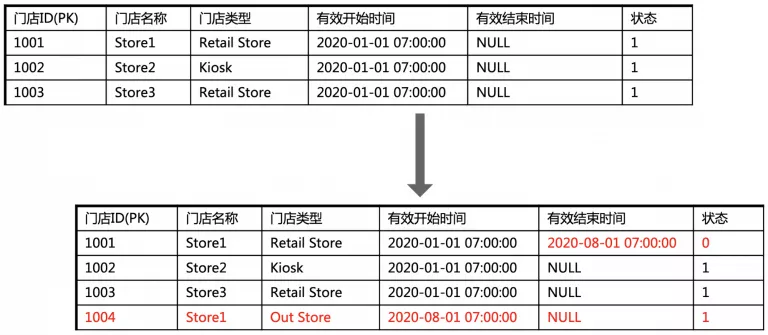
数据建模的例子
下面我们以一个例子,说明数据建模的过程。背景是某面向 C 端的零售企业,需要对购买其产品的客户,按照指定时间段内,在不同购买渠道的购买频率进行分组。
概念建模阶段:
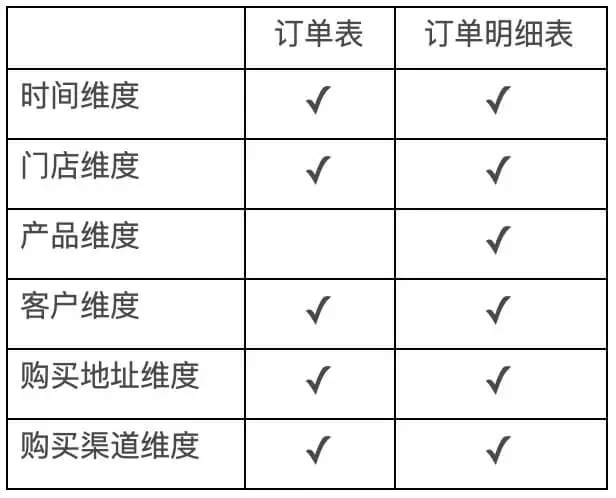
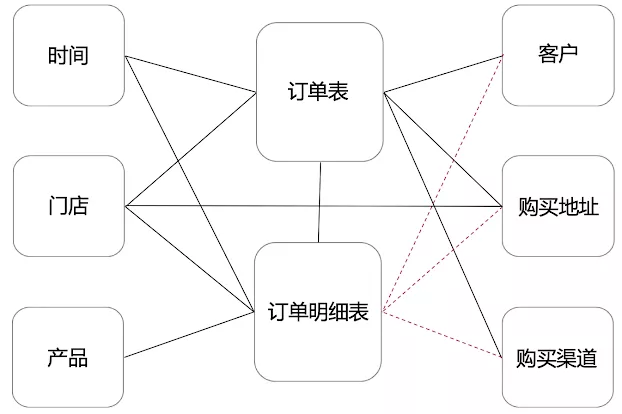
假设通过与用户的交流,涉及以下维度:时间、门店、产品,客户,购买地址,购买渠道等。事实表有订单表和订单明细表,订单表以每条订单为最小粒度,订单明细表以每条订单每个产品为最小粒度,相同订单相同产品为一条数据,用数量做标识。
该阶段产生的模型图如下,实线代表数据强关联,虚线代表数据弱相关,如果有特殊分析需求,数据可冗余:
逻辑建模阶段:
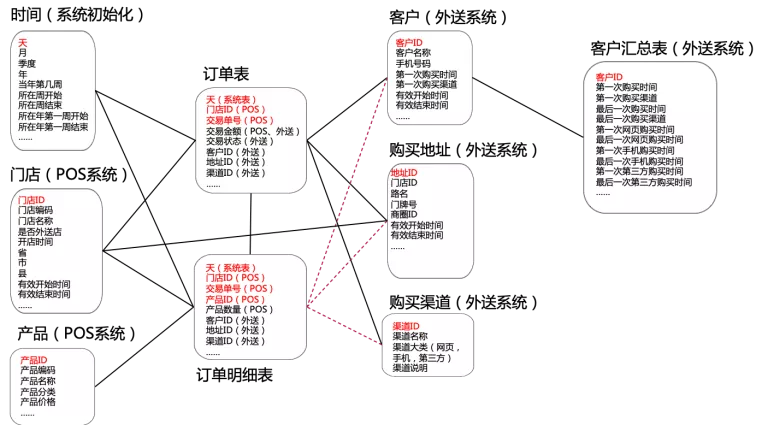
在这个例子中,门店和客户信息的属性是可变更的,地址库由于门店所属商圈变更,也会有变化,因此门店、地址和客户维度,需要做维度渐变。产生的模型图如下:
物理建模阶段:
在这个阶段,需要把逻辑建模的结果,实例化到数据存储中。一般对于关系数据库的物理建模和逻辑建模会大部分相同,只是根据数据类型或者其他数据库调优策略进行微调,但是对于非关系数据库,例如 MongoDB 或者 Keyvalue 的 HBase,这个要根据实际情况,物理建模会有比较大的调整。在本例中,数据结构改变不大,模型图在此不再赘述。需要注意的点有以下几个:
需要重点考虑数据分层,使数据结构更清晰,便于维护。在本例中只是简单的举例了一个客户汇总需要 ETL 进行预计算
充分利用各数据库对不同数据类型的处理,事实表尽量使用整型
尽量少的使用可空,如果有空值,尽量提前处理。例如可在维度表中,创建一个 ID 为-1 的记录,代表空值,事实表中如果查找不到维度,打上-1 的标签
尽量考虑扩展,布尔型可以使用 smallint 代替,比如是否,男女类型的字段,未来有可能出现增加一个未知的记录
考虑到性能问题,在关系数据库中,不要使用物理的主键和外键,而是使用 ETL 保证数据的完整性和一致性
数据建模本身没有难度,但是,数据建模的好坏,是数据仓库项目成败的关键因素之一。如何做好数据建模,是个真正的技术活,这个世界上没有一个魔法盒子能解决所有的问题。因此,个人建议在数据仓库建模的不同阶段,不同类型的数据仓库,采用不同的方法,因地制宜,从而保证整个数据仓库建模的质量。
ETL 日志体系
说到日志,相信大家都不陌生。不管是应用类项目,还是数据类项目,都需要有日志平台为各种业务保驾护航。我们在这里仅讨论数据仓库离线 ETL 的日志体系,其他的组件和资源监控日志或者采集日志由其他成熟平台处理,例如 ELK(Elasticsearch,Logstash 和 Kibana 的缩写)。
ETL 日志的分级
在数据项目中,ETL 日志分为三个级别,分别是:
调度级别,主要是 ETL 调度器所产生的日志,这部分日志主要依赖 ETL 调度器,大多数情况下,不会发生错误,例如现在比较流行的 Azkaban
ETL 级别,ETL 运行日志,需要记录 ETL 内部的每个模块和 ETL 整体的运行情况,运行时间,维度表的错误处理,事实表运行了多少条数据,多少条成功,多少条失败,失败的原因等等,以流水账的形式记录,供运维人员查看,方便日后排查错误和性能调优。从这部分日志可以清晰的看到数据仓库的数据情况和源系统数据质量的变化
数据级别,这是数据仓库面向运维最重要的一部分日志,需要记录每个批次运行的数据范围,每个批次运行后的数据结果,实现了日志驱动数据仓库层与层之间的数据流动
其中 ETL 级别和数据级别的日志,需要结构化或者半结构化处理。数据仓库平台需要利用这些日志进行自动化或者半自动化的处理,做到错误事前发现,打造无人值守的运维平台。
ETL 日志的处理
该部分属于 ETL 级别日志,由 ETL 中的代码,根据需要生成。我们需要为数据仓库的运维人员提供一个统一的视图管理工具,运维人员可以查看所有的 ETL 的执行情况。简单的日志表结构如下:
错误汇总表:

错误明细表(ETL 执行错误后会写入该表,错误级别分为警告和错误,警告数据进入数据仓库,错误数据不进入数据仓库):

日志驱动数据
该部分属于数据级别日志,日志驱动数据主要有两个方面的含义:
数据的完整性和一致性,在数据仓库的 ETL 处理过程中,数据库是没有事务的,为了满足 ETL 的幂等性,我们必须在 ETL 中手动处理事务,以解决服务器断电,网络闪崩等特殊情况下数据的完整性和一致性的问题
数据仓库的数据是分层存储的,我们需要日志表清晰的记录层与层之间的数据流动痕迹。例如:历史数据如果重新加载,上层预计算 ETL 如何重新运行,执行预计算的 ETL 决定是否重新加载历史数据
在数据仓库的每一层,需要加入数据级的日志表来解决以上问题。事实表的粒度决定需要控制事务的最小粒度,例如事务粒度如果为每个门店每天的数据,那么就表示同一店天的数据要么全部成功,要么全部失败,与其他店天互不影响。假设我们有如下架构:
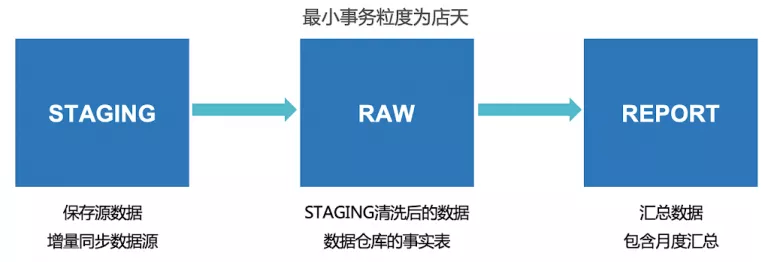
每一层需要一个 QUEUE 表和一个 LOG 表,QUEUE 表负责生成 ETL 需要运行的数据,LOG 表负责记录 ETL 的执行结果,日志表相同店天可有多条数据,标识同一店天运行历史痕迹。QUEUE 的表结构如下:

LOG 的表结构如下:

RAW 层的 ETL 执行的步骤如下:
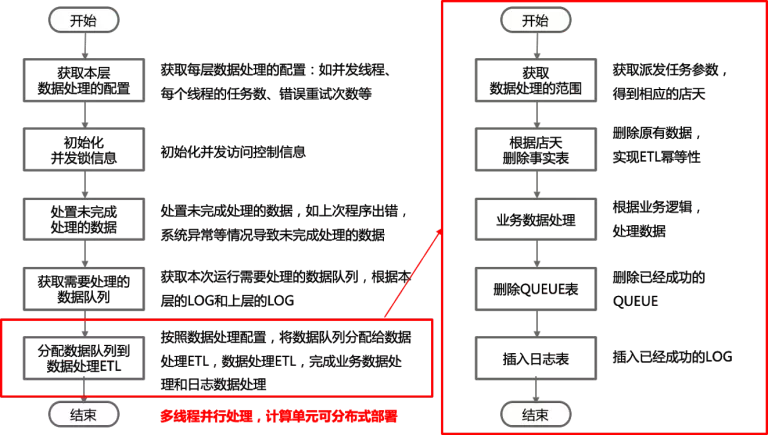
如果 RAW 的 ETL 执行到一半出错,那么已经成功的店天数据,则在下次运行的时候不用重新处理。如果数据有重新加载,REPORT 层的数据是否需要重新计算,取决于 REPORT 的获取本层需要运行数据的逻辑,与 RAW 是否加载数据无关,这样就避免了不同数据层之间的耦合,数据可以分层管理。
结束语
以上分享是我对如何实施一个好的数仓项目的部分理解。我在这里只是抛砖引玉,数仓类的跨功能需求不仅仅是数据建模和 ETL 日志体系,还有其他跨功能需求没有在本文中体现。例如,性能、安全、可用性等等,也都同样重要。在不同的业务场景下,任何一个跨功能需求都可能决定数仓项目的成败。欢迎大家一起探讨。
文章转载自:ThoughtWorks 洞见(ID:TW-Insights)
原文链接:数据仓库项目中的数据建模和ETL日志体系




