
在过去的几个月里,Crossplane 支持的自定义资源数量突破了 Kubernetes 的限制。在这篇文章中,我们将探讨下由 Upbound 工程师发现的限制,以及我们如何帮助克服它们。
本文最初发布于 Upbound Newsletter。
在过去的几个月里,Crossplane 支持的自定义资源数量突破了 Kubernetes 的限制。在这篇文章中,我们将探讨下由 Upbound 工程师发现的限制,以及我们如何帮助克服它们。
背景
Upbound 创建了 Crossplane,帮助人们创建云控制平面。这些控制平面位于云提供程序之上,允许你自定义它们暴露的 API。平台团队使用 Crossplane 为开发人员提供更简单、更安全的自助服务云接口。
Crossplane 使用我们所谓的云提供程序来扩展控制平面,以支持新的云——例如,安装 AWS 提供程序使得控制平面可以按照自己的概念和策略来封装 AWS。Crossplane 提供程序扩展了 Crossplane,使其可以支持底层云提供程序支持的所有 API。我们称这些 API 为托管资源或 MR。
MR 是构建块,使用 Crossplane 定义的 API 就是由 MR 组成。要使用 Crossplane 构建控制平面,你需要:
定义你希望控制平面暴露的 API。
安装用于支撑那些 API 的提供程序。
告知 Crossplane,当有人调用你的 API 时要创建、更新或删除哪个 MR。图片:
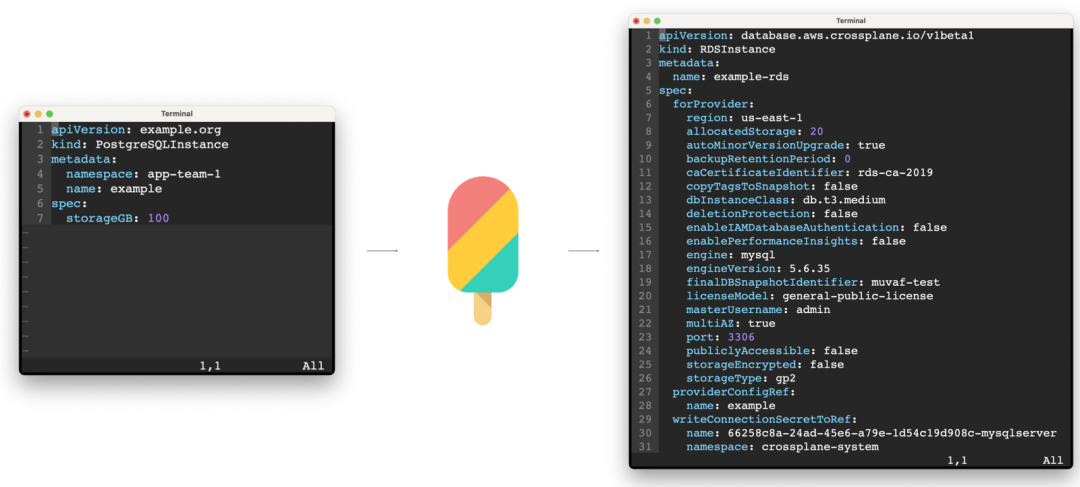
配置 Crossplane 暴露一个简单的 PostgreSQLInstance API,该 API 以托管资源 RDSInstance 为基础。
Crossplane 提供程序旨在成为相应云提供程序高保真、全覆盖的代理。在本文写作时,AWS 暴露了大约 1000 个 API 端点,也就说,安装 AWS 提供程序并实现 AWS API 全覆盖的话,扩展之后的 Crossplane 将支持大约 1000 种新的 MR。实现 AWS、Azure 和 GCP 提供程序全覆盖的多云控制平面将支持大约 2000 个 MR。在后台,每个 MR 都由一个 Kubernetes 自定义资源定义(CRD)来定义。
Kubernetes API 服务器是 Crossplane 控制平面的关键组件。Upbound 很早就发现了 Kubernetes 控制平面的优势,并选择以它为基础构建 Crossplane。该 API 提供了一个可扩展的 JSON REST API,并内置支持可靠的持久化(即 etcd)和一些有用的特性,如基于角色的访问控制(RBAC)、Webhooks(可以在 API 调用提交到存储之前更改或验证包含在该调用中的数据。)
API 服务器区分“内置”API 资源和“自定义(API)资源”,前者主要支持容器相关的概念,如 Pod、部署和服务,而后者可以代表任何东西。Crossplane MR 是一种 Kubernetes CR。API 服务器使用 CRD 来获知新类型的 CR。CRD 包含 API 服务器暴露一个新 CR 所需的所有信息——例如,它的类型和 OpenAPI 模式。这是一种相当新颖的方法;API 服务器暴露一个 API,你可以调用这个 API 告知服务器其他需要暴露的 API。
在 Crossplane 之前,即使是最高级的 Kubernetes 用户也只能用少量的 CR 来扩展他们的 API 服务器——或许创建数十个 CRD。随着 Crossplane 开始支持数以百计的 MR,我们发现了 Kubernetes 能够处理的 CRD 上限。
API 发现
我们观察到的问题可以归结为两部分:客户端和服务器端。客户端问题主要包含在一个称为发现(Discovery)的过程中。像 kubectl 这样的客户端使用这个过程来发现 API 服务器支持什么 API。其他的暂且不说,这使得客户端能够“自动补全”API 类型。例如,当有人输入 kubectl get po 时,它可以知道他们的意思是 kubectl get pods。
发现过程的主要问题是它需要客户端“浏览”API 服务器的许多端点。自定义资源由 API 服务器像下面这样在端点提供出来:https://example.org/apis////例如,一个名为 cool-db、类型为 Instance、属于 API 组 rds.aws.upbound.io/v1 的 MR 将像下面这样提供:
https://example.org/apis/rds.aws.upbound.io/v1/instances/cool-db为了发现这个端点,客户端需要查询:
https://example.org/apis 获取支持的 API 组清单,如 rds.aws.upbound.io。
https://example.org/apis/rds.aws.upbound.io 确定组内有什么版本,如 v1。
https://example.org/apis/rds.aws.upbound.io/v1 确定版本 v1 存在什么类型的 CR。
当 CR 的类型数以千计时,客户端需要查询许多 API 端点才能完成发现过程。例如,“三大”云提供商——AWS、Azure 和 GCP——提供了大约 2000 种 Crossplane MR,它们分布在大约 300 个 API 组和版本中,也就是说,客户端必须发起大约 300 个 HTTP 请求来执行发现。从根本上说,这没有那么糟糕——相对于现代的网速而言,这些请求的响应相当小,客户端可以利用 HTTP/2 来避免许多到 API 服务器的 TCP 连接开销。关于发现过程的可扩展性问题主要是由客户端速率限制器所做的假设和缓存造成的。
客户端速率限制
我们注意到的第一个客户端问题非常明显——每隔 10 分钟,kubectl 的发现结果缓存就会失效,它会发出如下所示的日志信息,然后最多要等 5 到 6 分钟才真正开始做你要求它做的事:
Waited for 1.033772408s due to client-side throttling, not priority and fairness, request: GET:https://api.example.org/apis/pkg.crossplane.io/v1?timeout=32s这个问题很容易解决。kubectl 中执行发现的部分使用了一个速率限制器,以确保它不会造成 API 服务器过载。当我们最初注意到这些日志时,速率限制器允许客户端平均每秒发起 5 次请求,而突发请求最多为 100 个。
解决这个问题的权宜之计是放宽速率限制。如今,发现仍然受限于每秒 5 次请求,但每秒突发请求最多可为 300 个。在 Cruise 和 Upbound 等公司的工程师的要求下,kubectl 在 v1.22 版本发布时及时提高了这一限值。发现缓存的过期时间也被配置为 6 小时,而不是 10 分钟。从 Kubernetes v1.25 开始,所有基于 client-go 库构建的客户端都将享受到提高后的限值。
客户端缓存写入
下一个客户端问题诊断起来有点难。我们的分析显示,即使完全禁用速率限制,执行 300 来个 API 组的发现也需要将近 20 秒。一开始,我们以为这是因为网络限制——通过现代互联网连接下载发现数据就需要大概 20 秒。幸运的是,我们注意到,在 macOS 上确实需要 20 秒,但在 Linux 上几乎是瞬间完成。

大量的时间消耗在 diskv.WriteStream 互斥量中。
幸运的是,kubectl 提供了一个便捷的 -profile 标识,让我们可以深入了解时间花在了哪里。在尝试了多种不同类型的分析器后,我们注意到,互斥量分析器显示,kubectl 94% 的时间消耗在了一条与发现数据缓存相关的代码路径上。
我们发现,kubectl 用来缓存发现数据的 diskv 库被配置成了 fsync 所有缓存文件——大约 300 个发现端点,每个一个。这个系统调用可以确保操作系统将写入特定文件的数据一路刷写到持久化存储。在 macOS 上,Go 使用 F_FULLSYNC fnctl 为将数据持久化到磁盘提供了强有力的保障。显然,这比其他操作系统要慢许多,苹果不建议这么做,除非是在数据持久化特别重要的地方。
F_FULLFSYNC 所做的事情和 fsync(2) 一样,然后它会要求磁盘驱动器将缓冲区的所有数据刷写到持久化存储设备上(参数被忽略)。目前,这已经在 HFS、MS-DOS(FAT) 和通用磁盘格式(UDF)文件系统上实现。完成这个操作可能需要相当一段时间。
到底是苹果的存储层从根本上就比其他系统的慢,还是说他们的硬件更真实的反馈了完全持久化数据所需的时间,人们有一些不同的看法。无论如何,对于一个很容易重建的缓存来说,这一调用所提供的保障等级并不是必须的。
从 Kubernetes v1.25 版本开始,Upbound 更新了 kubectl(及所有基于 client-go 的客户端),使用校验和来保证发现缓存的一致性,而不是 fsyncs。我们在读取时检测有错误的条目并使其失效,而不是费力在写入时持久化缓存。这种方法在 macOS 提供了类似的一致性,但速度比之前快大约 25 倍(在 Linux 上快大约 2 倍)。
修复前,写入并读取一个缓存值需要大约 22 毫秒:
$ go test -v -bench . -run '^Bench'goos: darwingoarch: arm64pkg: k8s.io/client-go/discovery/cached/diskBenchmarkDiskCacheBenchmarkDiskCache-10 60 22272642 ns/opPASSok k8s.io/client-go/discovery/cached/disk 2.582s修复后,写入并读取一个缓存值需要大约 0.7 毫秒:
$ go test -v -bench . -run '^Bench'goos: darwingoarch: arm64pkg: k8s.io/client-go/discovery/cached/diskBenchmarkDiskCacheBenchmarkDiskCache-10 1534 761469 ns/opPASSok k8s.io/client-go/discovery/cached/disk 1.483s```客户端改进前瞻
人们将发现速率限制与美国债务上限进行了比较——每次债务到达上限时就提高上限。对于 Crossplane 上请求最密集的用例,目前的限制仅仅是够用而已,但应该无法坚持多久。越来越多的人要求把它们完全删除。
客户端速率限制的本质是请求避免过多导致 API 服务器过载。这直觉上是个好主意,但有两个问题:
速率限制器的状态不会存续到客户端生命周期之后。大多数 kubectl 命令 2 到 3 秒就可以完成,因此,可供速率限制器用来决策的上下文很少。如果每个 kubectl 命令需要一秒钟完成,那么一个紧凑的命令循环将被有效地限制在每秒 300 个请求。
客户端之间不会相互协调——如果许多客户端的请求同时爆发,每秒发出 300 个请求,那么 API 服务器仍然会过载。
API 优先级和公平性(AP&F)(在 v1.20 版本中成为 API 服务器的一个 Beta 特性)可以克服上述问题。它使用服务器端队列和流量削减来保护 API 服务器。有了 AP&F:
每个 API 服务器的优先级数量都可配置。
类似 RBAC 的规则根据资源类型、用户、命名空间等对请求进行优先级分类。
请求可能在多个队列之间随机分片(shuffle-sharded),以大幅减少噪音客户端对对等客户端的影响,即使优先级相同。
当 API 服务器过载时,请求会收到一个低开销的 HTTP 429 “请求太多”响应。
减少执行发现所需 HTTP 请求数量的工作也在进行当中,为的是可以去掉速率限制。有一份 Kubernetes 增强提案(KEP)已获批准,该提案建议添加一个聚合 HTTP 端点以供发现使用,并计划在 Kubernetes v1.26 中提供 Alpha 支持。有了这个端点,客户端就能够通过请求单个 HTTP 端点来执行发现。这个聚合发现端点还将支持基于 ETag 的缓存,允许客户端只在已知缓存过期的情况下下载发现数据。
OpenAPI 模式计算
与第一次看到有关客户端速率限制的报告同时,我们还注意到,Kubernetes API 服务器在 CRD 负载下会行为异常:
我看到了各种不可思议的错误,从 etcd leader 更换到 API 服务器报告没有 CustomResourceDefinition 这种类型,再到 HTTP 401 未授权,尽管我的证书在后续的请求中依然有效。
首先我们看到,请求过了很长时间才得到处理,如果确实得到了处理的话。在创建完数百个 CRD 之后,这种行为似乎会持续大约一个小时。
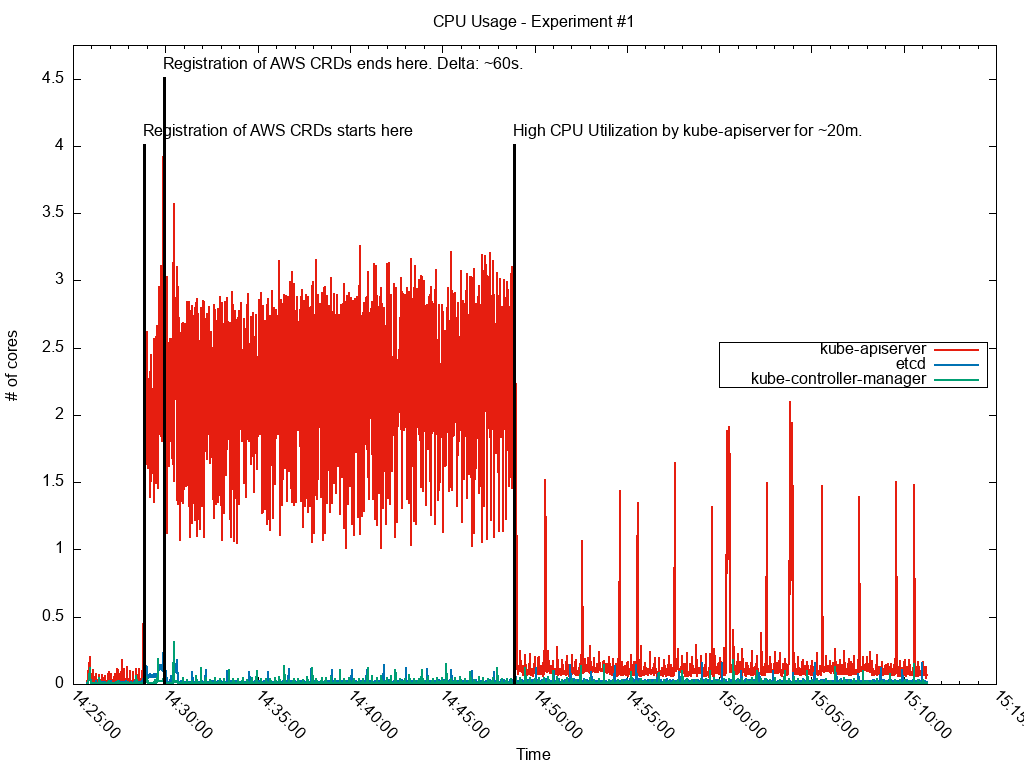
在创建了 765 个 AWS CRD 之后,紧接下来的一段时间 CPU 利用率非常高。
从监控仪表板上可以看出,在创建了许多 CRD 之后,紧接下来的一段时间 API 服务器 CPU 利用率非常高。有趣的是,我们注意到,当我们向一个已经有很多 CRD 的 API 服务器大批量添加 CRD 时,CPU 利用率居高不下的时间更长。
通过对 API 服务器 CPU 利用率的分析,我们发现,CPU 利用率升高的主要原因是计算 OpenAPI v2 聚合模式的逻辑。每次添加或更新一个 CRD 时,OpenAPI 控制器会:
为定义好的 CR 创建一个 swagger 规范。
将已知所有 CR 的 swagger 规范合并成一个大的规范。
将合并后的规范序列化成 JSON,以便可以由 /openapi/v2 端点提供出来。
就是这样,每次添加或更新一个 CRD,API 服务器就要完成序列化工作,而随着 CRD 数量的增加,这项工作的开销也会越来越大。一次性添加许多 CRD 会导致这种情况发生在一个紧凑的循环中,那很容易耗尽 API 服务器的 CPU 预算。
鉴于这种情况,我们算是很幸运了。在早期,有人报告了内存利用率在创建 CRD 之后会提升的情况后,API 服务器维护人员就识别了问题所在并着手修复,而且同步降低了我们观察到的 CPU 利用率。这个修复使得端点 /openapi/v2 的模式计算延迟——所有处理延迟到客户端实际向该 API 端点发起请求时。在 Upbound 的小小帮助下,Kubernetes v1.23.0 中加入了这个修复,并反向移植到了 v1.20.13、v1.21.7 和 v1.22.4 等补丁版本中。
etcd 客户端
在引入新的、更高效的 OpenAPI 模式计算方法后,我们迅速发现了 API 服务器的下一个瓶颈——持续提升的内存利用率。我们在试验过程中发现,在 API 服务器上,每个 CRD 要占用 4MiB 多一点的物理内存(驻留集大小或 RSS)。图片:
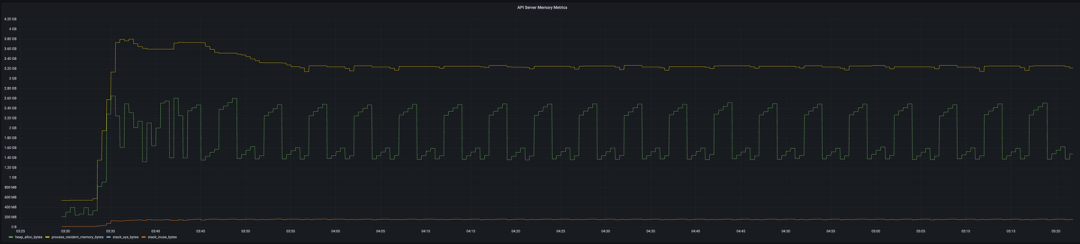
API 服务器安装 780 个 CRD 后的内存使用情况
对于像 Google Kubernetes Engine(GKE)这样的托管 Kubernetes 服务,这特别成问题,因为它们经常会限制 API 可以使用的 CPU 和内存。当预测到 API 服务器需要更多的资源时——比如创建了更多节点,这些服务能够优雅地对它进行纵向扩展。遗憾的是,在本文写作的时候,大多数 API 服务器都没有考虑到创建的 CRD 会越来越多,而且要到 API 服务器反复出现“OOM killed”(因超出内存预算而终止)时才开始扩展。
虽然 ProviderRevision 获取健康状况只需要大约 150 秒,但区域 GKE 集群之后至少会有 3 次进入修复模式。在区域集群的“RUNNING”和“RECONCILING”状态之间,每次运行 kubectl 命令,我们都观察到了与之对应的各种错误,最明显的是连接 API 服务器时的连接错误和 I/O 超时。集群要一个多小时才能稳定下来。不过,在此期间,控制平面会间歇性地短时可用。
我们测试过的所有 Kubernetes 服务(即 GKE、AKS 和 EKS)都或多或少地受这个问题所影响。它们都可以自愈,但在此之前,API 服务器会有 4-5 秒到 1 个小时不等的时间不可用。请注意,集群不会完全停止运作——Kubelets 和容器会继续运行——但它会停止所有的协调工作。
我们再次求助于 Go 的内置分析工具,并很快就有了一些发现。原来,一个名为 Zap 的日志库占用了 API 服务器超过 20% 的内存。颇具讽刺意味的是,Zap 显然是为低开销而设计的,但却不小心被滥用了。
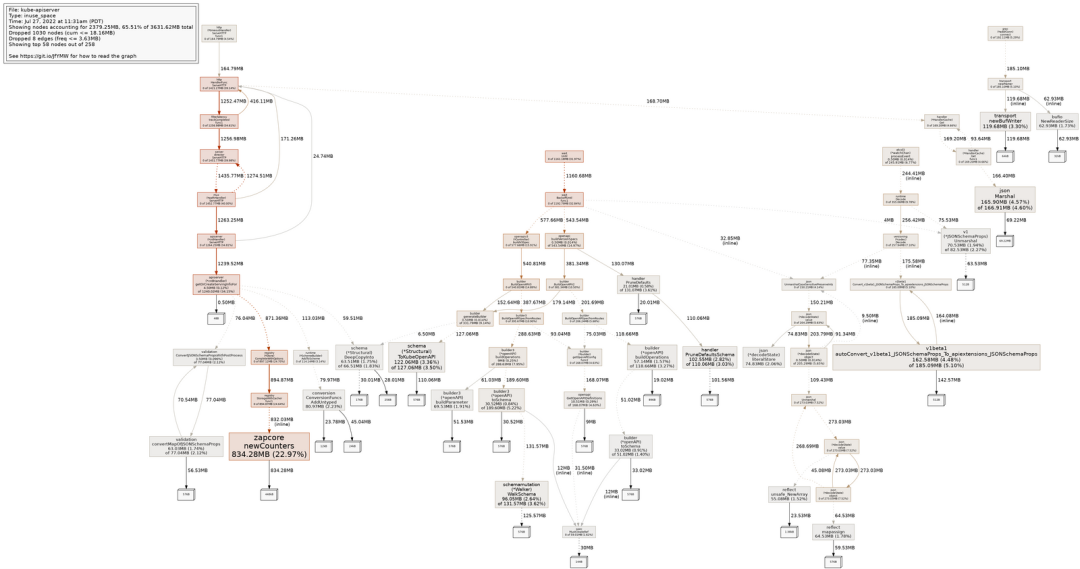
在一台有 1878 个 CRD 的空闲 API 服务器上,zapcore.newCounters 占了 23% 的内存。
实际上,API 服务器会为每个版本的 CR 创建一个 etcd 客户端(即每个 CRD 至少创建一个 etcd 客户端),并且每个 etcd 客户端都会实例化自己的 Zap 日志记录器。这会导致数百个冗余的日志记录器,对内存造成重大影响,同时,API 服务器和存储数据的 etcd 数据库之间也会产生数百个不必要的 TCP 连接。
大多数 Kubernetes API 系统维护人员似乎都认为,这个问题的正确修复方式是所有 CR 端点共享一个 etcd 客户端。不过,由于我们是在 Kubernetes API 发布周期后期提出的这个问题,所以我们选择做一个小的策略性修复,使所有 etcd 客户端共享一个日志记录器。即将于 8 月底发布的 Kubernetes 1.25 将包含这一修复,下一波补丁版本 Kubernetes 1.22、1.23 和 1.24 也会包含这一修复,也会在大致相同的时间发布。我们希望,内存利用率缩减大约 20% 可以缓解我们在托管 Kubernetes 服务中观察到的问题。
服务器端改进前瞻
长期来看,我们在服务器端的工作未来将集中在降低 CRD 的计算资源成本。近期,我们已经开始大幅减少 API 服务器使用的 etcd 客户端数量,从每个 CR 版本一个减少到每个传输一个(即每个 etcd 集群)。我们还与 GKE、EKS 和 AKS 的工程团队合作,以确保他们的服务能够处理 Crossplane 安装的 CRD 数量。
早期的调查还表明,API 服务器会受垃圾收集优化所影响。我们做了一个简单的实验,在一台安装了大约 2000 个 CRD 的空闲 API 服务器上,当堆增长 50% 时触发垃圾收集(默认是在堆增长 100% 时触发),其结果是,峰值 RSS 内存利用率减少了 25%。更频繁的垃圾收集对 CPU 的影响是否可以接受,还需要进一步的测试来确定。一旦 Go 1.19 发布,或许可以试下新的内存限制设置,它提供了 Go 运行时会尝试遵守的一个软内存限制。
小结
在过去的 12 个月里,Crossplane 社区已经确定了一个新的 Kubernetes 扩展维度——定义的自定义资源的数量——并推动其突破其限制。Upbound 工程师帮助诊断和消除了这些限制,包括:
限制性的客户端速率限制器。
缓慢的客户端缓存。
低效的 OpenAPI 模式计算。
冗余、高昂的成本、etcd 客户端。
在本文大部分问题的诊断中,Alper Rifat Uluçınar 都提供了很大的帮助——感谢 Alper!如果你觉得这篇文章有趣,那么你可能也会喜欢他最近在 KubeCon 大会上所做的关于这个话题的演讲。
原文链接:https://blog.upbound.io/scaling-kubernetes-to-thousands-of-crds/
今日好文推荐
历时三年替换掉二十年老系统,这个团队选择“一次性到位” | 卓越技术团队访谈录
奇葩事儿:删除用户云数据还无法恢复,只赔 3 万;微信键盘来了,体积 524MB;谷歌希望将效率提高 20%:暗示将裁员?| Q 资讯




