
导读
当前,虽然大语言模型(Large Language Models, LLMs)在处理和生成自然语言方面取得了一定的进步,但这些模型处理文本的长度有限,在理解和生成长文本方面的能力也受到影响。近日,北京通用人工智能研究院(简称通研院)研究团队联合北京大学人工智能研究院团队提出了一个用于测试和评估大语言模型(LLMs)长上下文理解能力的基准数据集——LooGLE。该数据集既能够评估 LLMs 对长文本的处理和检索能力,又可以评估其对文本长程依赖的建模和理解能力。
通过 LooGLE 对当前最为流行 9 种长文本 LLMs 进行评估可以发现,这些模型在复杂的长依赖任务中的多信息检索、时间重排序、计算、理解推理能力表现均不乐观。商业模型(Claude3-200k,GPT4-32k、GPT4-8k、GPT3.5-turbo-6k、LlamaIndex)平均只有 40%的准确率,开源模型(ChatGLM2-6B、LongLLaMa-3B、RWKV-4-14B-pile、LLaMA-7B-32K)只有 10%的准确率。
该成果论文《LooGLE: Can Long-Context Language Models Understand Long Contexts?》已被 ACL2024 接收,论文共同一作为通研院的李佳琪、王萌萌,通讯作者为通研院研究员郑子隆和北京大学人工智能研究院助理教授张牧涵。
论文地址:
https://arxiv.org/abs/2311.04939
数据地址:
https://huggingface.co/datasets/bigainlco/LooGLE
代码地址:

01 研究背景

近年来,基于 Transformer 架构的大语言模型 LLMs 在自然语言理解(NLU)和生成(NLG)任务方面取得了一定的进步,但在需要处理和理解长文档时,它们仍然存在非常大的局限。在评估 LLMs 的超长文本和上下文理解能力方面,传统的基准数据集往往在文本长度上不足(平均数以千词计),并且自动收集可能过时的文档(文档来自几年前发布的现有数据集,可能导致预训练 LLMs 中的数据泄漏,使评估结果不准确)。此外,现有基准中的任务主要是短依赖性任务,即只需要 LLMs 从一个特定句子或段落中检索答案(例如大海捞针),而不真正测试 LLMs 从整个文档的段落中收集信息并将其总结为答案的能力,我们称之为长依赖性任务。为了解决以上问题,我们提出了 LooGLE 基准数据集, 用于测试和评估大语言模型 LLMs 的长上下文理解能力。
02 研究创新
LooGLE 基准测试具有以下优势:
1)包含近 800 个最新收集的超长文档,平均近 2 万字(是现有相似数据集长度的 2 倍),并从这些文档中重新生成了 6 千个不同领域和类别的任务/问题用于构建 LooGLE;
2)目前没有既评估 LLMs 对长文本的处理和记忆,又评估其对文本长程依赖的建模和理解能力的数据集。LooGLE 的数据集由 7 个主要的任务类别组成,旨在评估 LLMs 理解短程和长程依赖内容的能力。作者精心设计了 5 种类型的长期依赖任务,包括理解与推理、计算、时间线重新排序、多重信息检索和摘要。通过人工标注精心生成了超过 1100 对高质量的长依赖问答对,以满足长依赖性要求。这些问答对经过了严格的交叉验证,从而得到了对大型语言模型(LLMs)长依赖能力的精确评估;
3)LooGLE 基准数据集仅包含 2022 年之后发布的文本,尽可能地避免了预训练阶段的数据泄露,考验大模型利用其上下文学习能力来完成任务,而不是依靠记忆事实和知识储备;
4) 该基准的文本源自广泛认可的开源文档,包括了 arxiv 论文、维基百科文章以及电影和电视剧本,涉及学术、历史、体育、政治、艺术、赛事、娱乐等领域。
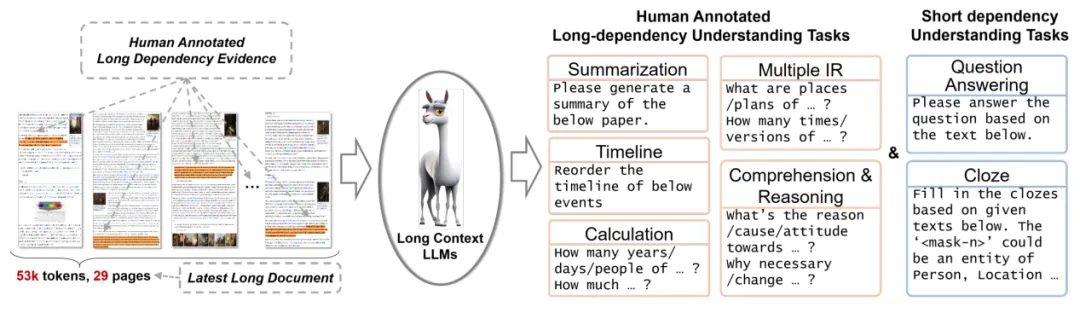

03 长文理解中长程问答任务生成

长程依赖任务介绍
在本研究中,作者组织了近百名标注者手工编制了约 1100 个真实的长依赖问答对,分为 4 类长依赖任务:多信息检索、时间重排序、计算、理解推理。这些任务非常具有挑战性,需要更高级的长文本理解能力,它们对于了解语言模型的局限性非常有价值。
多信息检索:与传统的短期检索任务显著不同,该任务下回答一个特定答案通常需要在整个文本中搜集多个线索或证据。任务要求从长文本中广泛分布的相关证据或线索中进行检索和提取,然后对这些证据进行汇总,才能得出最终答案。
计算:与前一个任务类似,首先需要从广泛的文本中进行多次信息检索提取相关数字,例如关于数量、频率、持续时间、特定年份等。要得出准确的答案,还需要对这些数字进行计算。这个过程既依赖于强大的长上下文信息提取能力,并且涉及一定程度的数学推理能力。
时间重排序:这个任务给大模型输入指令“请重新排列以下事件的时间轴”,以及一组按顺序排列的事件描述。任务目标是根据这些事件在长文本中出现的时间先后顺序将这些事件排列起来。成功完成这个任务需要对文档的主要故事情节进行抽取和理解,且要求模型具有时间意识。
理解推理:这个任务要求模型利用散落在长上下文中的证据,深入理解问题并推理出答案。最常见的问题模式涉及到因果关系、影响、贡献、态度以及与各种事件相关的基本属性。此外,当问题围绕着证据的重要程度、显著程度、最高或最关键方面时,则需要进行更广泛的比较和评估。此任务的答案通常在源文本中不明显。它们通常需要多步推理来模拟内在的联系和依赖关系,通过复杂的分析过程获取答案。
04 现有 LLM 测评和实验分析
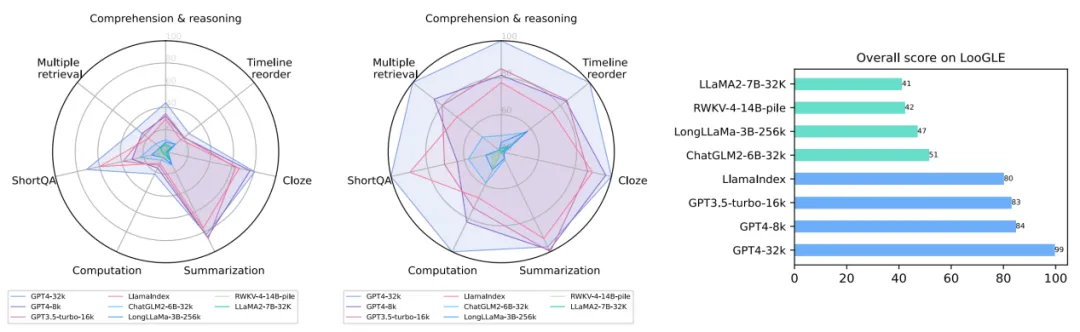
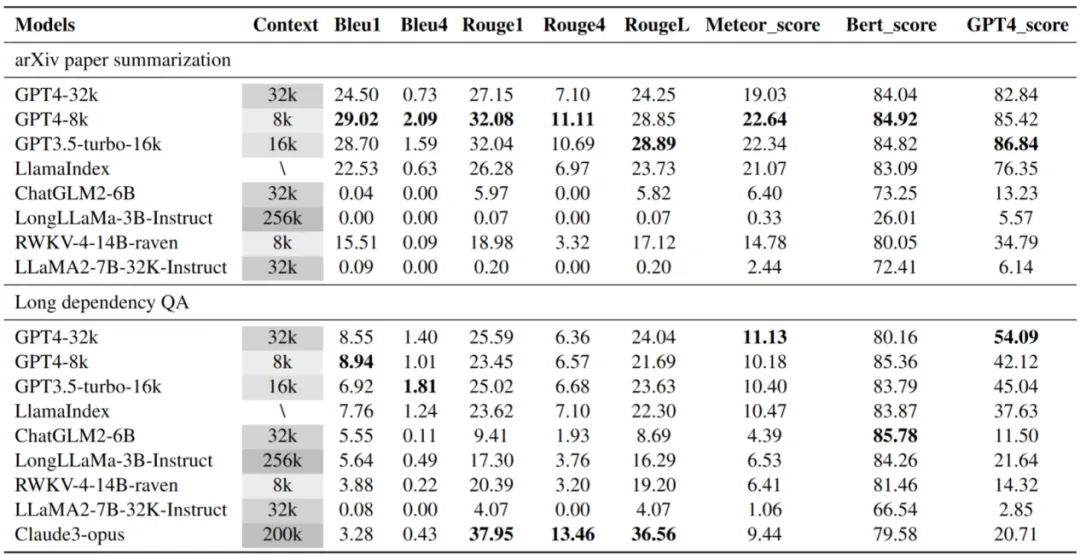
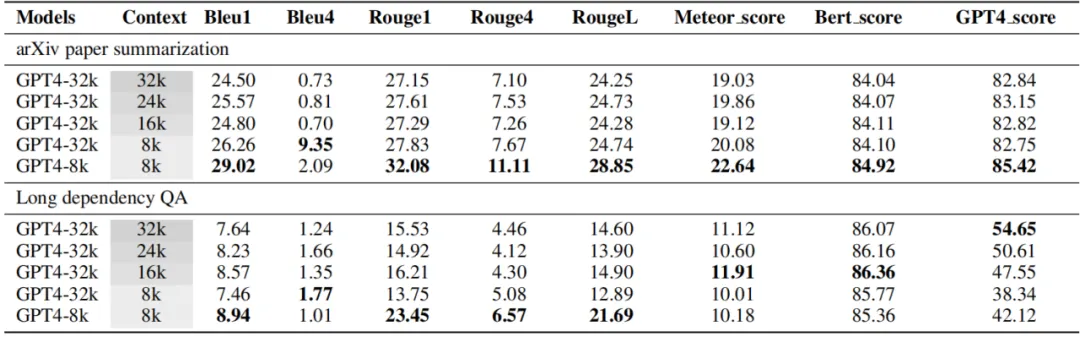
为了提供更全面和通用的性能评估,LooGLE 使用基于语义相似性的度量、GPT4 作为判断的度量,以及人类评估作为度量。在 LooGLE 上对 9 种最先进的长文本 LLMs 进行评估(其中包括 OpenAI 和 Anthropic 的商用模型,以及几个主流开源基座模型微调得到的长文本模型[1][2],和带有外部记忆模块的检索增强模型[3]),得出了以下关键发现:
(1)商业模型显著优于开源模型;
(2)LLMs 在短依赖任务(如短问答和填空任务)方面表现出色,但在更复杂的长依赖任务中均表现不佳;
(3) CoT(思维链)只在长上下文理解方面带来了微小的改进;
(4) 基于检索的技术在短问答方面表现出明显的优势,而通过优化的 Transformer 架构或位置编码来扩展上下文窗口长度的策略对长上下文理解的提升有限。
因此,LooGLE 不仅提供了关于长上下文 LLMs 的系统和全面的评估方案,而且为未来开发增强型模型以实现“真正的长上下文理解”提供了启示。


05 与现有数据集的对比
1)传统长文本数据集的文档长度通常不足,大部分平均长度只有数千个词;
2)数据集中的长文本普遍是通过过滤、扩展或修改现有的 NLP 数据集形成的,这不仅意味着内容的过时,而且这些文本可能已经被 LLMs 训练过,或通过其他方式被 LLM 获取到了;
3)长文本内容来源通常与特定领域相关,例如科研论文、专利、政府报告,且包含复杂的术语,这使得评估 LLMs 通用能力变得困难;
4)这些数据集中的任务主要依赖短期记忆,从长输入的特定位置检索答案。目前没有任务能评估 LLMs 建模和理解在全文中广泛分布的证据间的长程依赖性关系。
现有类似的数据集:
[4] ZeroSCROLLS: A Zero-Shot Benchmark for Long Text Understanding
[5] LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
[6] L-Eval: Instituting Standardized Evaluation for Long Context Language Models

除此之外,有部分长文本模型能力测试采用“Needle In A Haystack”[7]的捞针任务体现其长文本理解能力。但是这类任务只需要在长文本输入下进行局部定位和关键信息抽取,主要依赖模型的检索能力,缺乏对模型处理长依赖关系能力的考察,LooGLE 基准测试可以很好的解决现有长文本测评的问题。
06 结论
通过提出 LooGLE 长文本基准数据集,揭示了现有 LLMs 在理解和推理长文本中的局限性。LooGLE 通过提供超长文本、使用相对较新的文档以及精心设计和标注的真正长依赖性任务等优势解决了先前数据集存在的不足。LooGLE 基准数据集的推出不仅为评估和改进长文本 LLMs 提供了新的工具,也为人工智能语言处理技术的发展提供了新的方向。
References
[1] Wenhan Xiong, Jingyu Liu, Igor Molybog, Hejia Zhang, Prajjwal Bhargava, Rui Hou, Louis Martin, Rashi Rungta, Karthik Abinav Sankararaman, Barlas Oguz, Madian Khabsa, Han Fang, Yashar Mehdad, Sharan Narang, Kshitiz Malik, Angela Fan, Shruti Bhosale, Sergey Edunov, Mike Lewis, Sinong Wang, and Hao Ma. 2023. Effective long-context scaling of foundation models.
[2] Yunpeng Huang, Jingwei Xu, Zixu Jiang, Junyu Lai, Zenan Li, Yuan Yao, Taolue Chen, Lijuan Yang, Zhou Xin, and Xiaoxing Ma. 2023. Advancing transformer architecture in long-context large language models: A comprehensive survey.
[3] Peng Xu, Wei Ping, Xianchao Wu, Lawrence McAfee, Chen Zhu, Zihan Liu, Sandeep Subramanian, Evelina Bakhturina, Mohammad Shoeybi, and Bryan Catanzaro. 2024. Retrieval meets long context large language models.
[4] Uri Shaham, Maor Ivgi, Avia Efrat, Jonathan Berant, and Omer Levy. Zeroscrolls: A zero-shot benchmark for long text understanding, 2023. 2, 3
[5] Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du,
Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. Longbench: A bilingual,
multitask benchmark for long context understanding, 2023. 2, 3
[6] Chenxin An, Shansan Gong, Ming Zhong, Mukai Li, Jun Zhang, Lingpeng Kong, and Xipeng Qiu. L-eval: Instituting standardized evaluation for long context language models, 2023. 2, 3
[7] https://github.com/gkamradt/LLMTest_NeedleInAHaystack

— 往期发布 —
学术前沿 | 北京大学人工智能研究院多篇论文入选CICC 2024会议
点击图片查看原文
点击图片查看原文
点击图片查看原文

— 版权声明 —
本微信公众号所有内容,由北京大学人工智能研究院微信自身创作、收集的文字、图片和音视频资料,版权属北京大学人工智能研究院微信所有;从公开渠道收集、整理及授权转载的文字、图片和音视频资料,版权属原作者。本公众号内容原作者如不愿在本号刊登内容,请及时通知本号,予以删除。




