本文翻译自: Data Pipeline: Salesforce Connector ,原作者为Ian F.,已获得原网站授权。
这是关于 Yelp 的实时流数据基础设施系列文章的第五篇。这个系列会深度讲解我们如何用“确保只有一次”的方式把 MySQL 数据库中的改动实时地以流的方式传输出去,我们如何自动跟踪表模式变化、如何处理和转换流,以及最终如何把这些数据存储到 Redshift 或 Salesforce 之类的数据仓库中去。
阅读本系列的第一篇:
中文:一天几十亿条消息:Yelp 的实时数据管道
英文: Billions of Messages a Day - Yelp’s Real-time Data Pipeline阅读本系列的第二篇:
中文: Yelp 的实时流技术之二:将 MySQL 表数据变更实时流到 Kafka 中
英文: Streaming MySQL tables in real-time to Kafka阅读本系列的第三篇:
中文: Yelp 的实时流技术之三:不止是模式存储服务的 Schematizer
英文: More Than Just a Schema Store阅读本系列的第四篇:
中文: Yelp 的实时流技术之四:流处理器 PaaStorm
英文: PaaStorm: A Streaming Processor
Yelp 用客户关系管理(customer relationship management,CRM)平台 Salesforce 来为超过 2000 人的销售团队提供支持。Salesforce 提供了许多现成的功能,让我们的销售团队可以轻松地定制他们的业务流程。
我们的销售团队主要做什么呢?他们卖广告包!他们卖给谁呢?Yelp 上的商家!那我们如何从 Yelp 的数据库中获取这些商家信息并提供给 Salesforce 呢?读过下文你就明白了。
以前的方法
我们现有的单向同步基础架构名为“Bulk Workers”,是早在 2010 年设计的了,目的是要显著地改进端到端发送数据的时间。这套设计方案成功地把同步时间从 3 星期缩短为 24 小时,这很棒!这套方案细节是怎样的呢?
这些“Bulk Workers”实际上就是一些 Gearman 定时任务,它们会检索业务表中的每一行数据,再按 Salesforce 的模式对这些数据进行转换。转换后的数据会用一个 Salesforce 客户端发送给 Salesforce,客户端是基于 Beatbox 开发的,主要的改进是增加了对 Salesforce 批量 API 的支持。
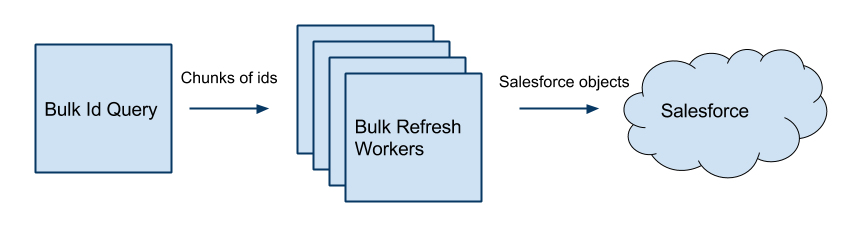
旧的集成方法
上面的方法一直工作得很好……直到它再也顶不住的时候。
在接下来的 5 年里,这套架构见证了数据的急速增长,从最初的 30 万亿行,到 2015 年超过了 100 万亿行。数据更新的操作影响尤其大。后来,同步时间开始越拖越长。我们就知道我们需要优化一下系统,来更好地支持更新操作了。
进入正题:数据管道
于是我们开始收集需求。我们认为新的解决方案需要下面这些:
- 实时处理
- 保证“至少一次提交”
- 自带监控和告警等功能
- 由配置驱动模式之间的转换
- 可以很容易地增加新字段和转换
差不多是在相同的时间点,我们已经在做依靠分布式发布 / 订阅消息系统 Kafka 的新数据管道了。这个数据管道可以直接满足我们的前三个需求。那我们剩下的工作就是构建一个转换框架来满足后面的两个需求,并且作为到Salesforce.com 的连接器。
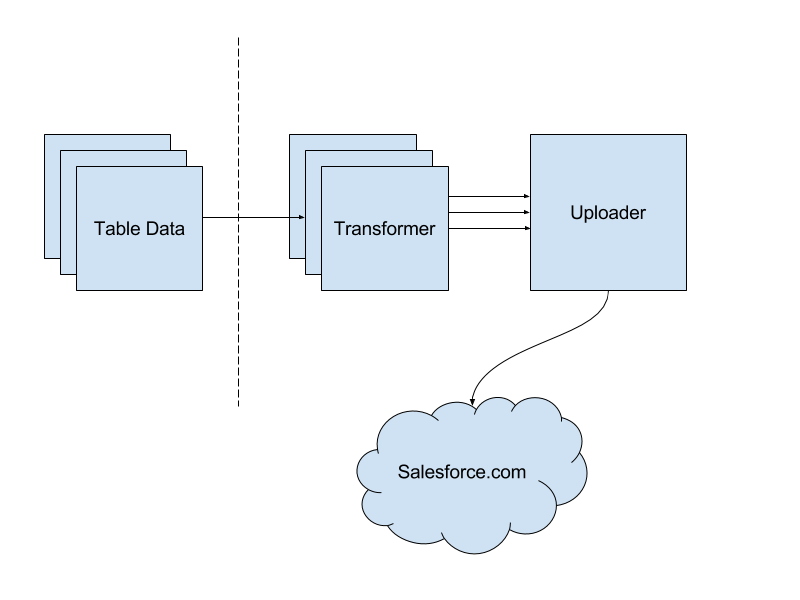
Salesforce 数据管道集成方法
转换器(Transformer)
我们采用了一个名为 PaaStorm 的、在 Yelp Hackathon 上产生的并且已经应用到生产环境的项目作为我们的 Kafka-to-Kafka 处理器,叫这个名字是因为它与 Storm 很相似,并且是用 Yelp PaaSTA 部署的。在保留了 Storm 的范式的前提下,我们构建了一个通用的转换器,可以生成许多实例,处理各个 Topic 中的要发往 Salesforce 的原始数据。在处理源 Topic 时,每个实例都会从一个 YAML 文件中得到转换步骤,然后再做拷贝、移动和(或)值映射操作。这很重要,因为 Salesforce 的模式存在的时间远远长于我们的新架构,是很难改动的。这个也意味着没有什么比较自动的方法去做字段映射。如果有一个由配置驱动的映射关系,那就让我们可以快速对转换做解析而不必真正地部署代码。这对项目的灵活性至关重要。
每个转换器都会向一个新的 Kafka Topic 中发布序列化后的 Salesforce 对象,供上传器消费并发往 Salesforce。
上传器(Uploader)
让上传器自己做为一个实例就可以让我们清楚地知道我们有多少个服务要与 Salesforce.com 通信。上传器会消费各个转换器转换后的消息,将它们批量发送到 Salesforce。因为发往 Salesforce 的请求是发向互联网的,所以这是我们的管道中最慢的部分之一。因而能不有效地进行批量处理就对性能影响非常大。使用合适的 API 也非常重要。因为 Salesforce 提供了好多种不同的 API,所以有时候选择用哪个也不容易。为了让我们可以很容易地不必做更多的工作就在 API 之间切换,我们写了个通用的客户端,用它包装了现有的 SOAP、REST 和批量 API 等 Python 客户端。我们也写了一个 ORM(Object-Relational Mapping)客户端,并为每张我们要写的目标表定义了模型。这让我们可以在发送到 Salesforce.com 之前就对数据进行验证,并且在写数据的时候确认该用哪个 Salesforce External ID 。
评估
我们用来评估的第一张表就是我们的广告商表。选它是因为它是我们 Yelp 整体业务中规模比较小的表之一,但对于我们的销售团队的运作又是非常重要的。在之前要把数据变更操作从 Yelp 同步到 Salesforce 需要 16 小时。在切换到新架构之后,可以看到同步时间变成了平均约 10 秒钟,偶尔会有一些波峰,但也就只是变为几分钟而已!这就足以表明出现在 Salesforce 上的数据是非常可靠的,销售团队在查看数据时,再也不必不断地来要更新的数据了。
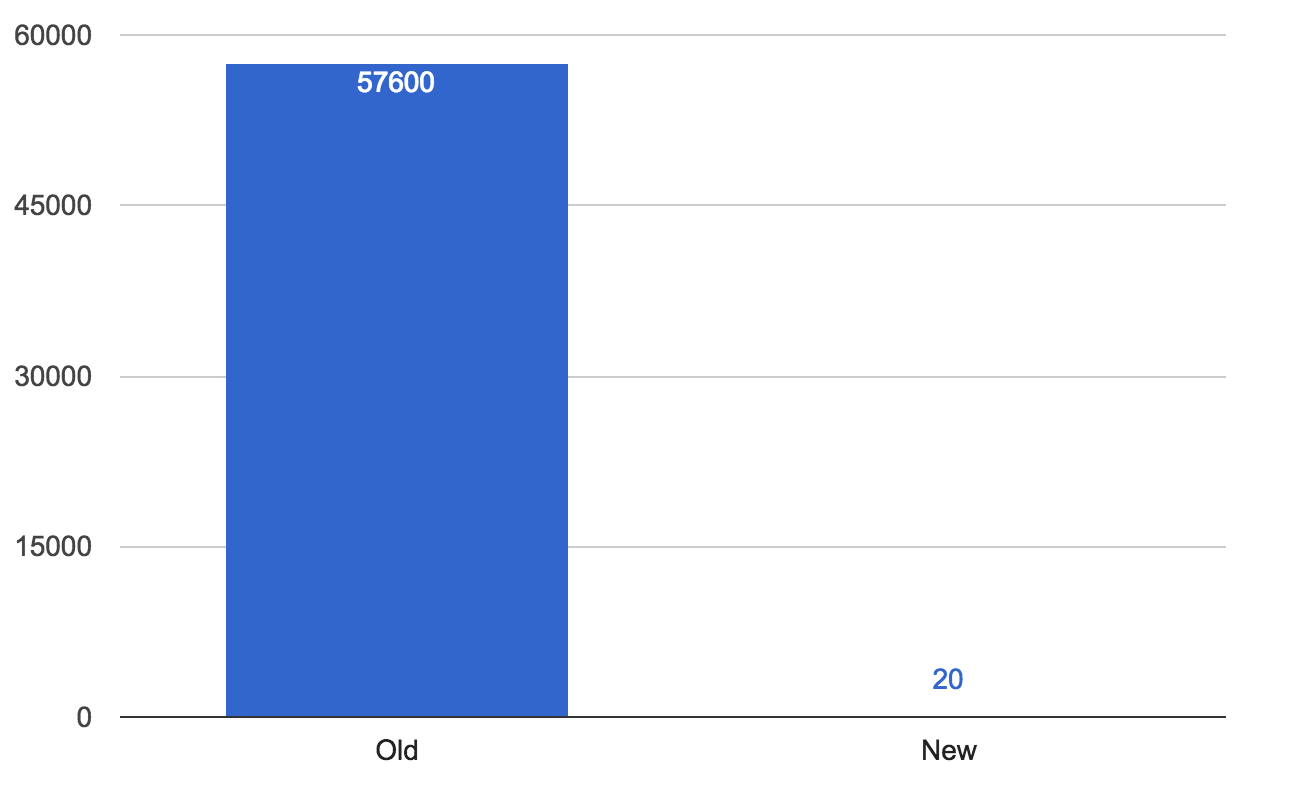
每秒钟平均同步延迟
挑战
听起来很容易?事实上并非如此。在设计和构建我们的连接器的过程中,我们要解决好几个问题:
我们注意到在处理失败的更新操作中有很大部分都是在 Salesforce 一侧超时了,或者是由于没能成功的为某行数据获取锁而被拒绝了。这两种问题的根本原因都在于我们在 Salesforce 的程序中使用了大量的触发器和回滚操作。差不多每张表上都有非常复杂的逻辑,而每一条写操作都要把这些逻辑全处理一遍,以保证不同数据之间的一致性,或者为了将某些业务流程自动化。这些功能本来都是很好的,但碰上问题时你就不那么想了。所以我们工作的重点就是要减少做写操作时的处理量。把这样的处理尽可能地挪到异步处理的过程中,就可以减少我们锁定单条记录的时间,也就减少了每条写操作的处理时间。
另一个要解决的问题是依赖关系。我们本来的数据源(MySQL)有限制依赖,而 Kafka 并没有。虽然写到每个 Kafka Topic 中的消息都是保证有序的,但是我们并不能保证这些 Topic 中的数据会以某个确定的速度被处理。在各张表都彼此依赖的情况下这个问题就很严重,因为一张表中的数据可能会比另一张表的数据更先被读取和更新,导致数据在一定时间内处于不一致的状态。一个常见的例子就是广告商的数据记录会比用户的数据稍早到一会。因为广告商的数据中包含一个指向 User 表的外键字段,写入就会失败。因此我们就要跟踪哪些数据是因为不符合依赖约束而写入失败的,然后再由上传器在确定依赖关系满足了之后再重试。把上传的操作按依赖顺序序列化并处理重试,这可以覆盖我们绝大多数的用例,尽管这意味着我们因此没办法达到一个很高的并行度。
还有一个问题,就是我们的数据没有全放在一个单一的数据库里面,所以对我们来说可用的就是单条的数据记录。为了解决这样的问题我们开发了新功能,读两个 Topic 中的数据并把它们关联起来,然后再把关联后的数据重新发布出去。
结论
使用基于 Kafka 的数据管道来为销售团队获取数据,我们已经在这方面取得了很大改进。接下来我们准备构建自己的基础架构,这样就可以实现其他的转换操作、简单的聚合、以及在写 Salesforce 的高可靠保障等等功能。




