本文最初发布于 Yelp 工程部门博客,原作者:Umesh Dangat。经授权由 InfoQ 中文站翻译并分享。阅读英文原文: Moving Yelp’s Core Business Search to Elasticsearch 。
虽然 Yelp 较新的搜索引擎通常使用 Elasticsearch 作为后端,但核心的商家搜索功能依然在使用基于 Lucene 自行开发的后端。这已经是 Yelp 生产环境中最古老的系统之一。这个自定义搜索引擎的部分功能包括:
- 分布式 Lucene 实例
- 主 - 从架构
- 为多种语言提供自定义的文本分析支持
- 大部分商家搜索功能依然在用的自定义商家评级功能(例如点评、名称、hours_open、service_areas 等业务特性)
- 通过派生出的 Yelp 分析数据改善搜索结果的质量,如某商家最常用的查询
遗留系统存在的问题
对实时索引支持欠佳
我们原本的系统使用了一种主 - 从架构,主系统负责处理写入(索引查询),从系统负责实时流量。一个主实例负责为 Lucene 索引创建快照并将其上传至 S3,这样从实例就可以定期下载进而刷新数据。因此更新后的索引需要延迟一段时间才能被用于搜索查询。一些搜索功能,例如预订和交易无法承受这样的延迟(几分钟之久),需要索引数据能够立刻使用(最多等待几秒钟)。为解决这一问题,我们只能使用另一种实时存储:Elasticsearch,并将其与商家信息(遗留的搜索存储)并行查询,但这意味着应用程序服务必须根据两个结果额外计算才能获得最终结果。随着业务增长,这种方法无法很好地扩展,我们开始在应用程序层对结果进行合并和排序时面临性能问题。
代码推送缓慢
我们有一个规模庞大的开发者团队在不断努力改善搜索结果的排名算法。工作完成后编写好的代码会推送至底层的搜索排名算法。在遗留系统中,这样的推送每天进行多次,每次需要花费数小时的时间。现在,Yelp 几乎所有微服务都使用 PaaSTA 部署,同时遗留系统可能是 Yelp 内部使用 PaaSTA 的最大“微服务”。我们的数据已经大到需要进行分片(Shard),为此使用了一种两层的分片方法。
- Geosharding:根据地理位置将商家拆分为不同逻辑索引。例如旧金山和芝加哥的商家位于不同索引中,因为分片操作有可能会在同一个国家内部进行。
- Microsharding:我们会进一步将每个地区索引拆分为多个“微索引”或“微分片”,为此使用了一种基于简单模块的方法,例如:
business_id % n, where “n” is the number of microshards desired
所以我们最终使用的 Lucene 索引看起来是这样的:
<<geographical_shard>>_<<micro_shard>>
每个 Lucene 索引支撑的进程都有自己的服务实例,为确保可用性,还需要考虑复制问题。例如,每个
- 从 S3 下载数十 GB 的数据
- 让 Lucene 索引预热,预加载 Lucene 缓存
- 计算不同数据集并将其载入内存
- 强制进行垃圾回收,因为启动过程会创建大量暂存对象
每次代码推送意味着必须对工作进程进行循环操作,每次都要重复上述过程。
无法执行某些功能性工作
对所有数据重建索引需要耗费大量时间,这意味着增加新的功能需要付出更高成本。因此我们无法执行很多操作,例如:
- 对分片算法进行快速迭代。
- 对分析程序进行迭代。我们使用针对不同语言自行开发的分析程序实现文字的令牌化(Tokenize),Lucene 这样的搜索引擎会在索引时使用特定的分析程序(执行令牌生成、剔除字 [Stopword] 筛选等工作),同时在查询时一般也会选择使用同一个分析程序,这样就可以在反转后的索引中找到令牌化的查询字符串。更改分析器意味着要对整个语料库重建索引,因此我们通常会尽可能避免对分析代码库进行优化。
- 通过索引更多字段改善排名。商家特征是对搜索结果进行排名的主要因素之一。随着商家数据日渐丰富,我们可以使用这些数据来改善搜索排名。然而此时必须使用另一个实时存储来查询这些商家特征,因为对遗留系统进行改动实在是一个让人望而生怯的过程。
- 随着辅助数据结构中存储的数据量越来越多,我们逐渐开始面临 JVM 堆的上限。我们的自定义数据不能存储在 Lucene 索引中,但这些数据也是商家排名所必须的(例如为每个商家存储最常用的查询)。随着数据量继续增长,扩展工作也愈加困难,因为 JVM 堆的大小本身也存在局限。
因此我们确信遗留系统必须大幅翻新。可新系统又该如何设计?首先一起来看看现有系统,借此了解新系统到底需要解决哪些问题,同时不会产生任何回退。
遗留系统
遗留的商家搜索栈
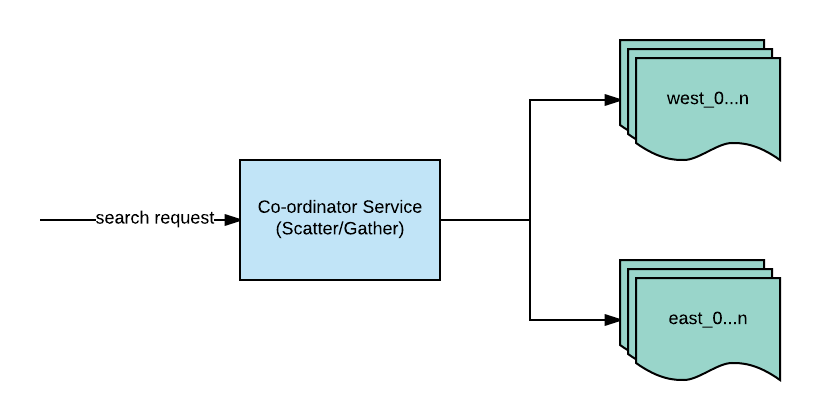
遗留的商家搜索栈
一切从传入协调器(Coordinator)服务的搜索查询开始。该服务负责确定要使用的地域分片(基于商家地理位置),随后会将查询转发至相应分片,例如上图简化后的用例中,查询会被发送至西区或东区。查询会被广播至该地域分片内的所有微分片(为了进行横向扩展而进行的第二层分片)。在从 1 到 N 个微分片获得结果后,协调器会对结果进行汇总。
微分片(单一遗留搜索节点)
深入看看具体的一个节点,了解如何通过查询得到结果。
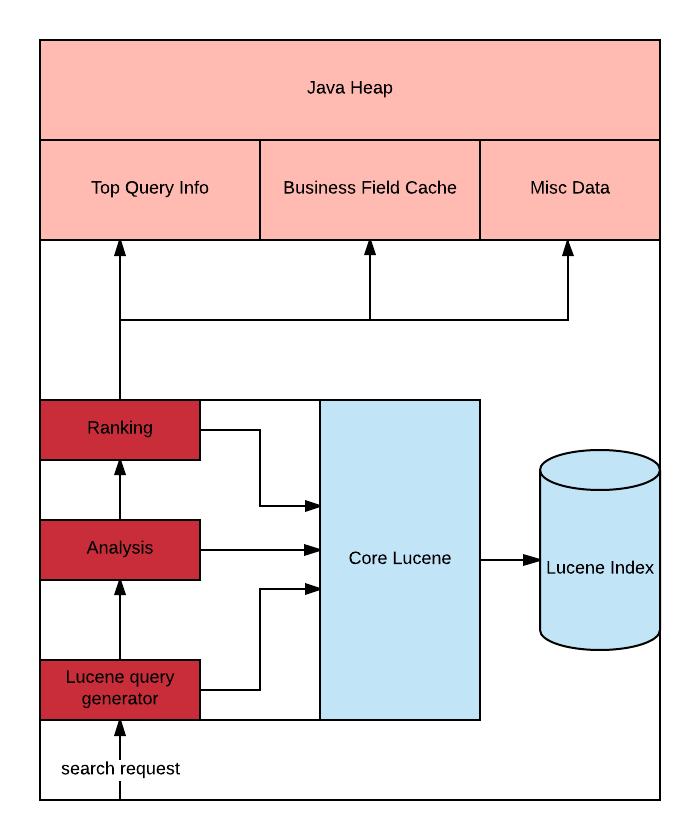
微分片
搜索查询会被转换为 Lucene 查询,随后发送至 Lucene 索引。Lucene 按照 Collector 的指令返回结果流。Collector 也可以看作是负责排名的机制(Ranker),决定了结果的显示顺序。这一过程中还将应用排名逻辑。Yelp 的排名逻辑会使用一系列启发式方法来确定最终结果排名。这些启发式方法还需要参考与商家有关的某些数据:
- 商家字段缓存:商家的前序索引(Forward index),例如商家特征
- Top 查询信息:从用户活动中派生出的数据
- 杂项数据:包括与 Yelp 业务有关的数据,例如 Yelp categories
借此我们已经可以定义新系统的设计目标。
下一代商家搜索系统的目标
根据上文内容,我们可以将一些高层次的目标总结如下:
- 将应用程序逻辑与所用后端解耦
- 更快速的代码推送
- 简化自定义数据的存储和驱动搜索结果排名的索引转发(例如特定上下文数据)
- 实时索引
- 应对未来数据增长的线性性能扩展
我们评估了 Elasticsearch 并发现该技术可以满足我们的一些目标。
挑战
应用程序逻辑与所用后端的解耦
评级代码本身不需要知道后端运行在哪里,因此可将这些代码与底层搜索后端的存储进行解耦。在我们的用例中,这些都是 Java 代码,因此我们可以将其部署为 jar。具体来说,我们可以在分布式搜索环境中运行评级 jar,这是通过 Elasticsearch 对插件的支持做到的。我们将评级代码与 Elasticsearch 插件的实现细节进行了妥善的隔离。
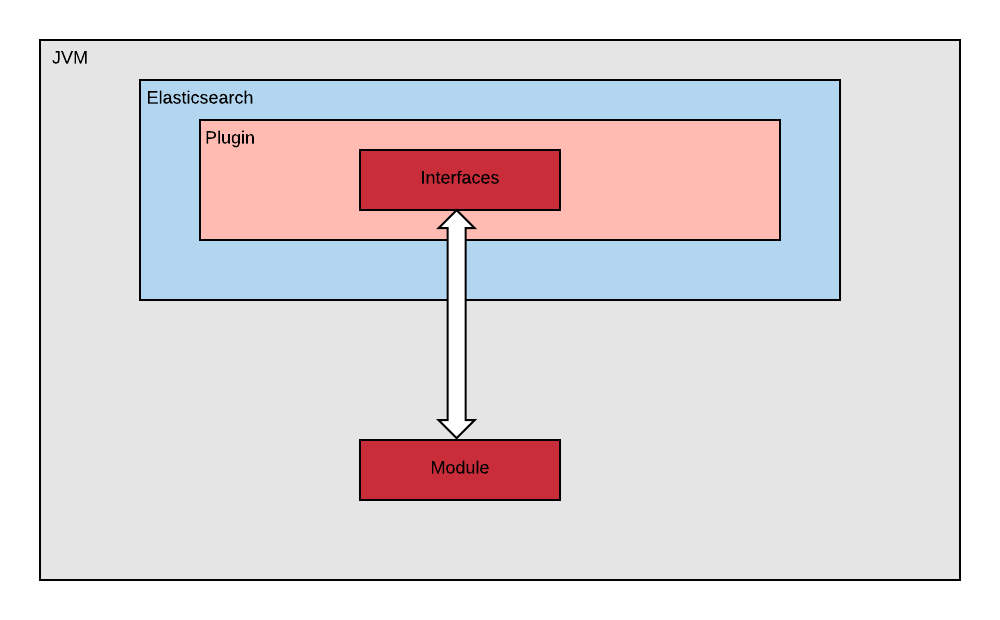
将插件从评级 jar 中解耦
接口
我们通过两个主要定义将评级代码与底层 Elasticsearch 库直接解耦,这样评级代码就不再硬性依赖 Elasticsearch(或 Lucene),借此可灵活地通过任何后端运行这些代码。
public interface ScorerFactory {
Scorer createScorer(Map<String, Object> params);
}
public interface Scorer {
double score(Document document);
}
public interface Document {
<T> T get(Class<T> clz, String field);
}
访问 GitHub 查看 interfaces.java
- Document 接口可供模块 / 评级代码查询商户特征。然而评级代码并不知道其具体实现。Document 的具体实现是由 Elasticsearch 插件注入的。
- Scorer 接口由模块实现,当然它也不依赖 Elasticsearch。该 Scorer 可由 Elasticsearch 插件内部的专用类加载器(Classloader)加载。
模块
模块也是评级代码,其中保存了与搜索有关的核心逻辑。正是这些代码需要每天多次推送到生产环境。这也是一种部署在 Elasticsearch 集群上的 jar,随后需要载入 Elasticsearch 插件。
插件
Elasticsearch 插件承载了评级代码。其中主要是与 Elasticsearch 有关的连接代码,可用于加载模块代码并委派用于提供评价所需的 Document。
更快速的推送
如上文所述,我们每天多次推送代码,但对我们来说,不能在每次推送后重启 Elasticsearch。由于开发的相关模块已与 Elasticsearch 解耦,因此可在无需重启整个 Elasticsearch 集群的情况下重载这些模块。
首先将评级 jar 上传至 S3。随后增加了一个 Elasticsearch REST 端点,该端点会在每次部署过程中调用,借此让 Elasticsearch 插件重载指定的 jar。
public class YelpSearchRestAction extends BaseRestHandler {
@Override
protected RestChannelConsumer prepareRequest(RestRequest request, NodeClient client) {
moduleLoader.loadModule(); //a. invoke re-loading of module.jar
return channel -> channel.sendResponse(new BytesRestResponse(RestStatus.OK, content));
}
}
访问 GitHub 查看 deployModule.java
端点调用后将会触发 module.jar 的加载操作,这一过程会通过一个私有的类加载器进行,可从 module.jar 中加载入口点的顶级类。
public final class ModuleLoader {
public synchronized void loadModule(){
final Path modulePath = downloadModule(); //1. download the module.jar
createClassloaderAndLoadModule(modulePath); //2. create classloader and use that to load the jar
}
private void createClassloaderAndLoadModule(final Path modulePath){
final URLClassLoader yelpySearchClassloader = new YelpSearchPrivateClassLoader(
new URL[]{modulePath.toUri().toURL()},
this.getClass().getClassLoader() //3. Create URLClassloader
);
scorerFactory = Class.forName("com.yelp.search.module.YelpSearchScorerFactoryImpl",
true,
yelpySearchClassloader)
.asSubclass(ScorerFactory.class)
.getDeclaredConstructor(new Class[]{Environment.class})
.newInstance(environment); //4. Create instance of ScorerFactory that return the Scorer
}
public Scorer createScorer(Map<String, Object> params) {
return scorerFactory.createScorer(params); //5. Scorer factory returning scorer, called once per query
}
}
访问 GitHub 查看 createClassloaderAndLoadModule.java
- 将 module jar 下载至 Path
- 基于 Path 创建私有的类加载器
- 使用 module.jar 的 URL 创建 URLClassloader
- 创建实现 ScorerFactory 的实例。请注意 asSubclass 的使用以及 Environment 的参数传递。Environment 是另一个接口,提供了模块代码所需的更多资源
- ScorerFactory 通过一个 createScorer 方法返回 Scorer 实例
随后我们就有了可重载 Scorer 的 Elasticsearch 插件代码。
class YelpSearchNativeScriptFactory implements NativeScriptFactory {
public ExecutableScript newScript(@Nullable Map<String, Object> params) {
Scorer scorer = moduleLoader.createScorer(params));
return new ExecutableScriptImpl(scorer); //1. Create elasticsearch executable script
}
}
访问 GitHub 查看 ElasticsearchPlugin.java
1. 创建 Elasticsearch 可执行脚本,为它传递之前曾“热加载”的 Scorer 实例。
class ExecutableScriptImpl extends AbstractDoubleSearchScript implements Document {
public ExecutableScriptImpl(final Scorer scorer) {
this.scorer = scorer;
}
public double runAsDouble() {
return scorer.score(this); //1. score this document
}
访问 GitHub 查看ExecutableScriptImpl.java
oElasticsearch 可执行脚本最终使用 Scorer 计分并传递 Document。请注意“这里”传递来的内容。借此 Elasticsearch 中的 Document 特性查询,即 doc 值查询才可以真正在 Elasticsearch 插件内部进行,同时模块代码可直接使用相关接口。
加载自定义数据
遗留系统最初面临的问题之一在于,随着时间延长,单个搜索节点的内存占用会逐渐变大,造成这个问题的主要原因在于 JVM 堆中加载了大量辅助数据。通过使用 Elasticsearch,我们可以将大部分此类内存中数据结构“卸载”至 doc 值。我们必须确保宿主机有足够的内存,让 Elasticsearch 检索这些 doc 值时可以高效利用磁盘缓存。
ScriptDocValues 适合大部分类型的属性,例如 String、Long、Double,以及 Boolean,但我们还需要支持自定义数据格式。一些商家有上下文特定的数据存储,每次搜索时需要单独计算。这样才能通过搜索功能帮助商家在某些情况下获得更高评级,例如针对以往情况,“结合过去常用的查询,为商家关联某一搜索查询的概率”。我们是这样呈现这种结构的:
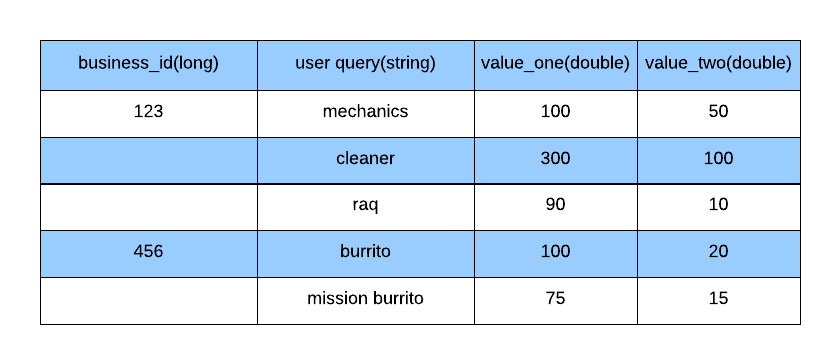
自定义数据格式
如果要将每个商家的此类数据存储为 doc 值,那么就必须进行序列化:
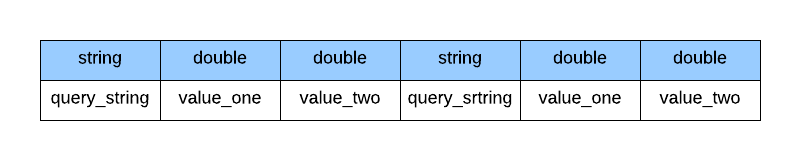
每个商家的自定义数据的序列化布局
由于查询字符串长度不固定,可能需要占用更多空间,因此我们决定使用正整数来代表。我们确定了一种长度值单调递增的字符串,借此可以使用 Long 取代 String 进而节约空间,并确保记录的长度为固定值。
假设有两个字符串“restaurants(餐厅)”和“mexican restaurants(墨西哥餐厅)”,我们的插件将“restaurants”视作 1,将“mexican restaurants”视作 2。字符串本身可以用查询对应的 Long 值取代,因此最终看到的将会是“1”和“2”。借此就可以使用固定长度的 Long.Bytes 代表字符串。这样可以更容易地对与查询有关的数据进行序列化或反序列化。这是个简化的例子,实践中需要根据不同语言存储字符串的分析后表单,例如英文中的“restaurants”可以令牌化为“restaur”。
因为字符串已经替换为相应的值,现在我们就可以更改数据结构只保存 Long 和 Double 数据了:

每个商家固定长度项的序列化布局
用户查询以及每个商家相关的值可呈现为对象列表。
Class QueryContextInfo {
private long queryId;
private double valueOne;
private double valueTwo;
}
访问 GitHub 查看 QueryContextInfo.java
借此可在 Elasticsearch 中使用自定义的序列化机制,对商家的所有记录以二进制数据类型的方式进行索引。
public static byte[] serialize(QueryContextInfo[] queryContextInfoRecords) {
byte[] bytes = new byte[Integer.BYTES + (queryContextInfoRecords.length * (Long.BYTES + 2 * (Double.BYTES)))];
ByteBuffer.wrap(bytes, 0, Integer.BYTES).putInt(queryContextInfoRecords.length);
int offset = Integer.BYTES;
for (QueryContextInfo queryContextInfo : queryContextInfoRecords) {
ByteBuffer.wrap(bytes, offset, Long.BYTES).putLong(queryContextInfo.getQueryId());
ByteBuffer.wrap(bytes, offset + Long.BYTES, Double.BYTES).putDouble(queryContextInfo.getValueOne());
ByteBuffer.wrap(bytes, offset + Long.BYTES + Double.BYTES, Double.BYTES).putDouble(queryContextInfo.getValueTwo());
offset += Long.BYTES + 2 * (Double.BYTES);
}
return bytes;
}
访问 GitHub 查看 QueryContextInfoSerialize.java
但这又造成了一个问题:使用 ScriptDocValues 查找二进制数据。为了支持这种功能,我们向 Elasticsearch 提交了一个补丁,通过这个补丁将能实现类似下面这样的操作:
List<ByteBuffer> queryContext = document.getList(ByteBuffer.class, "query_context");
访问 GitHub 查看 QueryLookUp.java
在从 Elasticsearch 中读取 ByteBuffer 后,即可针对所需 query_id 进行搜索,例如用户提供的,位于序列化后 QueryContextInfo[] 内部的 query_id。匹配的 query_id 可以帮助我们获取对应的数据值,例如商家的 QueryContextInfo。
性能方面的收获
在构建新系统的过程中,我们花了大量时间确保该系统能实现远超遗留搜索系统的表现。这一过程中学到了很多经验,例如:
找到瓶颈
Elasticsearch Profile API 可以帮助用户快速找到查询中存在的瓶颈。
通过分片让计分功能实现线性扩展
在我们的用例中,计分功能存在瓶颈,因为我们需要通过多种功能才可以对结果评级。我们意识到可以通过增加分片数量的方式进行水平扩展,这也意味着可以提高查询过程中 Elasticsearch 的并行度,而每个分片也可只对更少的商家进行计分。然而这样做也需要注意:具体数量并没有标准的最佳做法,这完全取决于检索规模及计分逻辑,当然还有其他因素需要考虑。增加分片数量对性能的改善幅度并非无上限的。此时只能通过不断增加分片数量并重建索引数据,不断尝试和评估找出最佳值。
使用 Java Profiling 工具
通过使用诸如 jstack 、 jmap ,以及 jprofiler 等 Java 工具,我们可以更全面地了解代码中的热区(计算密集型组件)。例如我们首次实现的二进制数据查找功能需要对整个字节数组进行反序列化,将其转变为 Java 对象列表(主要针对 List 进行),随后需要线性地搜索 query_id。我们发现这个过程很慢,并且造成了更多对短寿命对象的垃圾回收操作,因为每个查询中的每个被检索的商家都是这样做的。
我们调整了自己的算法,在不进行反序列化的情况下,针对序列化的数据结构进行二进制搜索。借此即可快速搜索商家 Blob 内的 query_id。同时这也意味着无需为了将整个 Blob 反序列化为 Java 对象而增加垃圾回收的成本。
结论
此次将 Yelp 的核心搜索功能迁移至 Elasticsearch,可能是 Yelp 搜索团队近年来从事的最具挑战性的项目之一。考虑到可行性,这个项目蕴含着大量技术挑战,而我们在项目中采用的“快速失败”迭代模式也就显得更加重要。在每次简短的迭代过程中,我们主要处理了那些高风险内容,例如热代码加载、Elasticsearch 对自定义数据的支持,以及 Elasticsearch 的性能问题,借此我们就可以更自信地继续推进整个项目了,不在其他次要问题上花费太多时间。最终这个项目取得了成功,现在我们已经可以定期重建数据索引,并轻松添加更多字段,进而可以用以往无法想象的方式改善评级算法。现在我们的代码推送可在数分钟完成,不再需要数小时。也许更重要的是,我们终于不再需要继续维护那套难以理解的遗留系统,开发者也可以更轻松地学习并掌握 Elasticsearch。
感谢冬雨对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




