
本文首发于 InfoQ,由声网 Agora 开发者社区 与 InfoQ 联合策划,并由 InfoQ 审校。
疫情爆发至今一年多的时间里,很多行业在疫情期间都备受打击,然而也有一些行业“因祸得福”,快速增长,包括在线教育、在线诊疗、在家办公、在线买菜、在线直播等。这些在线业务行业,均要大量应用音视频直播技术,在音视频直播技术的背后有两项关键技术在支撑:实时通信技术(Real-time Communication)与实时渲染技术(Real-time Rendering)。目前二者正在与实时生成技术相结合,为我们带来更好的实时沟通体验。
RTC 技术与实时渲染技术
RTC(Real-time Communications),实时通信,是一个正在兴起的风口行业,其强调“实时”即 Real-time,延迟在毫秒级别,支持强互动,最典型的应用就是直播连麦和实时音视频通信。
提到直播,还有一个重要的技术叫做 CDN:内容分发网络,简单地说就是将网站/应用的图片、音频、视频等素材提前传输到距离用户更近的 CDN 节点上(在物理层面就是电信机房里的服务器),当用户访问时就可以就近快速下载、减少等待。现在有一些平台通过 CDN 来实现直播,然而 CDN 的技术机制理论上会有 5-10 秒的延迟,在浏览图片、短视频等素材来说用户感知不明显,对于不需要实时强互动的直播,比如体育赛事网络直播、演唱会网络直播、新闻现场直播,延迟在 5-10 秒之间则是可以接受的。
而像前文提到的办公、教育、社交、医疗、娱乐这些直播应该对互动有非常高的要求,5-10 秒的延迟是无法忍受的,一方面画面会存在延时、卡顿、模糊、杂音、回声等常见问题;另一方面,实时互动根本没法用,游戏或直播中的连麦,远程医疗医患对话,直播小班课老师学生间的答疑,需要讨论的视频会议……理论上都要做到跟移动电话一样低延时、高接通和强互动,否则不只是体验不行,而是没法用。正是因为此,视频会议、社交直播、小班课、游戏开黑等互动要求高的场景,RTC 技术基本上已成为唯一选择。国内的 RTC 服务供应商包括声网、腾讯云、阿里云等。
RTC 技术比较复杂,不只是需要专门的网络节点,同时对网络架构、通信协议、软件算法和应用机构都有特殊要求。一个完整的实时音视频系统包括一下几个部分:
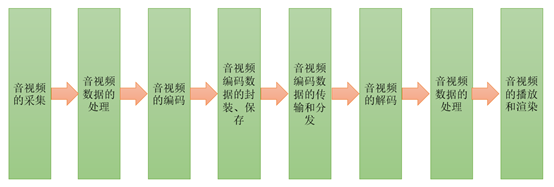
此外 RTC 对数据传输的及时性的要求通常要高于可靠性的要求。如发送端采集的一帧编码数据丢失了,对于接收播放端可能并没有太大的影响,接收播放端可以利用收到的前面和后面的帧,通过补帧等技术,实现同样好的用户体验,再如一帧音频数据丢失了,接收端可以用 NetEQ 等技术,根据收到的前面和后面的数据,用算法填上这一帧的数据,而不会降低用户体验。
实时渲染(Real-time Rendering)主要用于实时图像生成与分析处理,负责渲染直播画面、直播特效等等,如美颜、动画表情互动、礼物特效,提供更加个性化、人性化的使用体验。实时渲染关注的是交互性和实时性,一般制作的场景需要进行优化以提高画面计算速度并减少延时。
实时渲染技术随着计算机图形学的发展在持续进步。2000 年之后,3D 图像渲染 GPU 已经成为台式机标配,CGI 开始无处不在,预渲染的图形在科学上几乎是真实照片级的。这时期的工作主要集中在集成更复杂的多阶段的图像生成。纹理映射也已经发展为一个复杂的多阶段过程,使用着色器(shader)将纹理渲染、反射技术等多种算法集成到一个渲染引擎中的操作并不少见。2009 年电影《阿凡达》运用动作捕捉技术为角色生成动画,能够将动画直接叠加到实时拍摄的图像上,真正实现了高质量的实时渲染。软件方面 OpenGL 也开始成熟。不久前英伟达发布的 DLSS 2.0(Deep learning super sampling),根据官方宣传,可以保证渲染程序在较低分辨率下对游戏画面进行实时光线追踪,而 DLSS 2.0 则会将渲染后的画面进行 4 倍超采样,从而保证细节与帧率的兼顾,标志着实时渲染技术有了新的突破。
实时生成技术进展
近年来,随着互联网的迅猛发展和智能移动设备快速普及每时每刻都有大量的图像被生产、编辑和传播,越来多任务需要算法具备成图像生成能力,现有的直播渲染技术已经不能满足观众需求,实时生成画面+实时传输通信是未来趋势。与此同时,深度学习在语音识别、自然语言处理计算机视觉等许多领域都取得了巨大的成功,由层叠神经元组计算模型——深度神经网络,拥有比传统算法更加强大的特征提取及表示能力。因此人们开始研究其在生成模型上的应用。深度模型通过训练样本去估计数据集的概率分布,接着便可以利用这个生成新的数据或者操纵原有的数据。
基于生成对抗网络 GAN(Generative Adversarial Networks, GANs)图像生成研究目前收到了广泛关注。GAN 是由 Goodfellow 等人在 2014 年提出。这个深度生成模型背后的思想是博弈论,训练的过程可以被视作二元零和博弈。 GAN 包含两个组成部分,生成器(generator)和判别器(discriminator),两者均由多层感知机组成。在训练过程中,生成器 G 旨在生成尽可能逼真的图像数据去骗过判别器 D,而判别器则努力去分辨真实的样本和生成器输出的假样本。可以证明,该对抗训练过程最终将收敛到理论上的唯一解,在这种情况下,生成器生成的数据和真实数据将无法区分。训练完成后,生成器便可以从噪声中随机采样,生成训练数据集中不存在的新本。相比于传统模型例如玻尔兹曼机,GAN 不再需要复杂的马尔科夫链,只使用反向传播即可。同时大量实验 表明,GAN 可以生成更加锐利、逼真的图像,因此其在图像生成领域得到了广泛的应用。
近期一些 GAN 领域的工作实现了实时的图像生成功能,如实时的人脸驱动。Siarohin 等人提出了一阶运动模型,包含关键点检测器、密集运动场估计网络和运动迁移网络。关键点检测器通过无监督的训练,对源图像和目标图像分别提取关键点,接着密集运动场估计网络利用两幅图像的关键点信息估计出稀疏间运动信息,接着根据局部仿射变换去估计出密集的运动场,最后迁移网络接受目标图像作为输入,将编码器的特征基于此前得到的运动场进行扭曲,再送入解码器,获最后重现图像。这种方法实现的实时人脸驱动效果如下。

还有一些插件借助相似的方法,可以在 ZOOM 视频会议中实现实时换脸。下图 ZOOM 会议中的马斯克并非马斯克本人,而是换脸得到的。
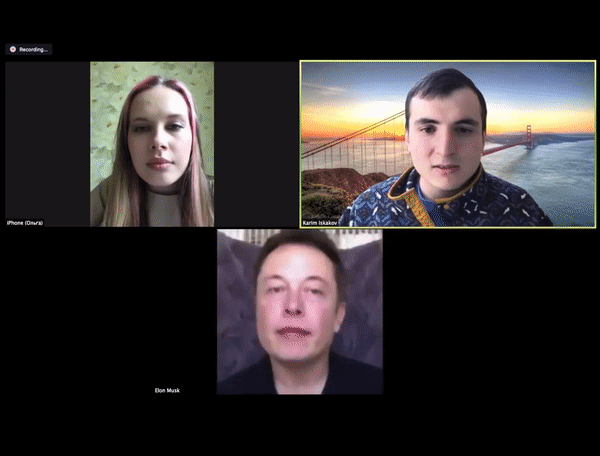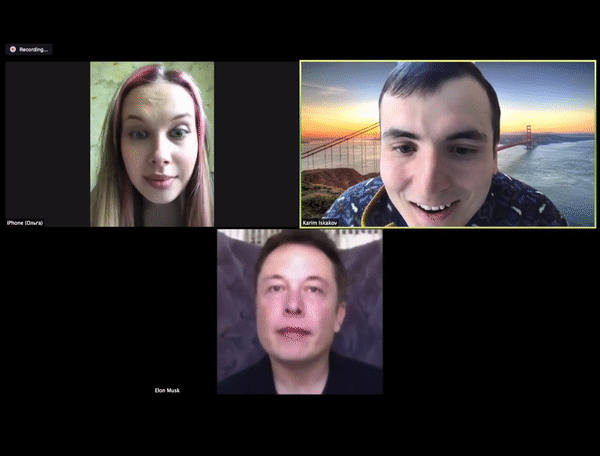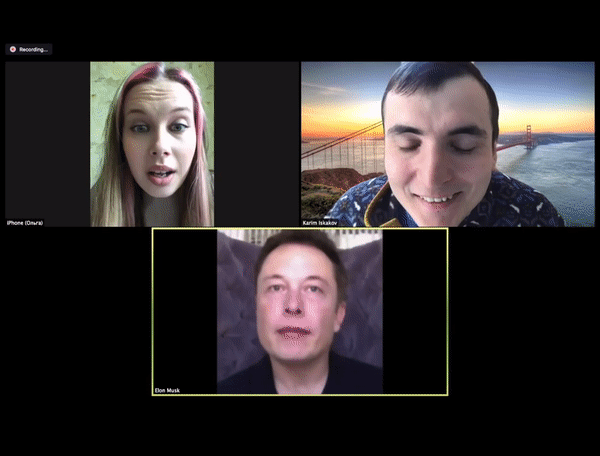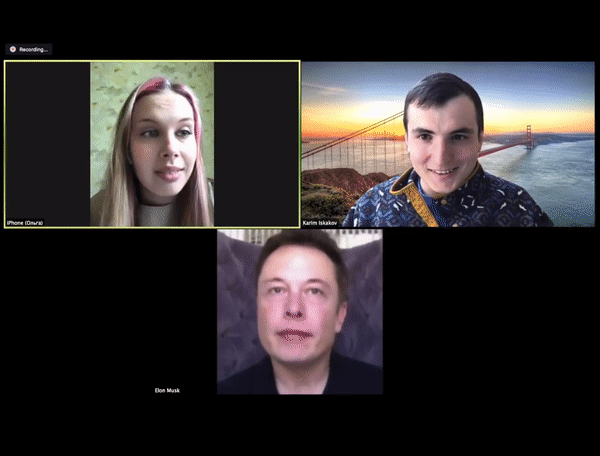
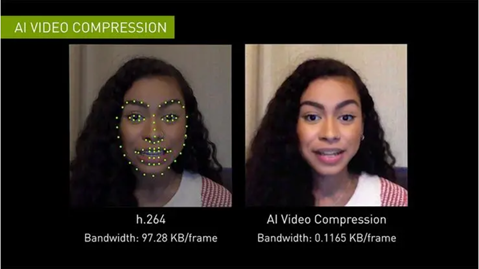
近期,NVIDIA 推出一款 Cloud-AI 视频流平台——Maxine,它可以在视频通话中,提供高清画质、噪音消除、目光校正,以及实时转录、翻译等功能,并且支持电脑、平板、手机等多种类型的设备,用于解决当前视频通话存在的各种问题。Maxine 增加了消除伪影的功能,可以使得画面更清晰,能过滤掉常见的背景噪音,如敲击键盘、主机运行的嗡嗡声、家里吸尘器的声音,还提供了实时翻译、转录字幕的功能。最重要的是借助视频压缩技术,可以有效减少数据传输的带宽。Maxine 通过把带宽问题变成计算问题,可以将传输所需带宽减少到 H.264 视频压缩标准所需带宽的十分之一,极大地增加视频的流畅度。Maxine 采用的 AI 视频压缩技术的核心在于它不是对整个屏幕的像素进行流式处理,而是分析通话中每个人的面部关键点,然后在另一端的视频中重新设置人脸的动画,如此一来便可以大幅降低的数据的传输量,同时还可以保证视频传输的质量。在面对面互动体验方面,Maxine 还增加了动画头像交互和虚拟助手功能。动画头像交互允许视频通话者根据喜好选择动画虚拟头像 ,这些头像虽不是真实的,但可以通过交互者的声音和情绪基调自动驱动。

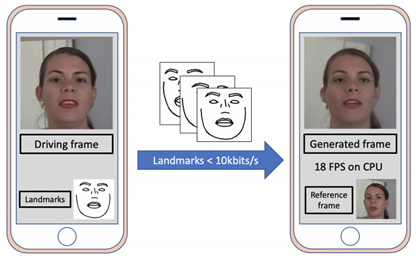
FaceBook 也使用深度生成模型以极小的带宽(小于 10kbits/s)提取并传输人脸特征点,然后在用户接收端设备上自动重建人脸,进而实现视频通话。他们设计的网络大小仅仅为 3MB,可以在 iPhone8 上运行。
RT2C
实时通信未来的发展趋势是与实时生成相结合,实现实时创作与连接(RT2C,Real-time Creation and Connection),其中创作部分包括生成和渲染,连接部分包括传输通信与社交网络。这将极大拓展媒体传播场景,提供更高品质的内容,让媒体制作更加便捷和多样化,提供更新颖、更人性化的观看效果和使用体验,更加吸引观众,拓展市场。一个典型应用是虚实结合的自由视角直播技术。
自由视角直播是指用户应该能够自由地选择观看直播的视角。传统的直播只为观众提供固定的一个视角,用户只能随着导播镜头被动地去观看。现有的一些多链路直播也只是事先在场景周围固定几个摄像机,然后提供这几个摄像机的观看视角,不是真正的“自由视角”。自由视角直播是让用户可以平滑无缝、自由地选择观看角度,通过遥控器或者手势滑动视窗,充分避免遮挡影响,实现 720°的无缝观看,不错过每一个精彩细节。同时提供一些上帝视角俯视全场,便于观众随时了解全场整体态势,也提供一些运动员或演员的跟踪视角、放大视角,让观众能随时跟踪自己喜欢的运动员或演员的表现。让观众仿佛在现场自由穿梭,随意欣赏表演或比赛,关注自己最在意的细节。使得人对真实世界的视觉感知同时具备了沉浸感、立体感、空间感,还解决了一般的立体视频内容不丰富、交互不自然的问题。与此同时还可以进行 AR 场景增强,在直播的视频流中渲染入一些现场并不存在的特效景象,让电视前的观众有亦真亦幻的视觉感受。比如在大型表演直播中添加虚拟的人物、景象或动态效果,与真实的演员进行互动;在比赛现场的场间休息中渲染一些大型的吉祥物投影或者啦啦队表演。
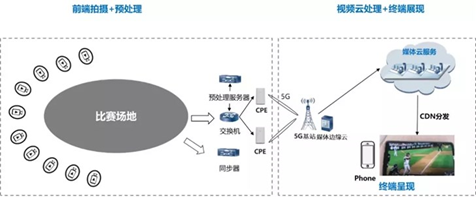
自由视角生成首先需要做摄像机自动定标,这方面已经有很多研究。视角生成领域相关技术大致可以分为三种:基于模型的绘制、基于图像的绘制和基于景深图像的绘制。基于模型的绘制主要指通过对场景进行三维建模,在获取场景纹理信息后,使用计算机图形学方法做旋转平移得到新视角图像。基于图像的绘制主要指直接利用参考图像来生成新视角,离散采样然后通过插值合成新视角的图像。基于景深的绘制在图像上加入了场景深度,用于辅助绘制新视角的图像。其中基于景深的绘制是比较流行的方法。通过这些方法可以实现自由视角和上帝视角的生成。而跟踪视角的生成需要借助视频检测与追踪技术,从不同摄像机中识别和检测人物,并且保证任何时刻都至少有一台摄像机能跟踪到观众选择跟踪的人物。视频追踪方面目前已经有很多成熟的方法可以用,包括一些搭建 RNN 网络来进行的追踪的研究,通过学习新的距离度量方法来进行滤波的限制玻尔兹曼机进行的追踪研究等等。下图展示了一种自由视角生成的解决方案。
神经渲染也是获取新视角的重要方法。有些神经渲染方法会在图像融合阶段用一个神经网络来学习输入参考视角之间的一个混合权重,好处是可以更充分学习对每一个输入视角。有些神经渲染方法不仅学习输入参考视角的混合权重,还要学习场景本身的几何结构、表面材质等属性,并且在一个可微的图形学渲染器中生成出新的视角。还有些神经渲染方法学习一个体素网格模型,用一个固定分辨率的体素网格来记录和更新从输入学到的特征,后续再通过一个渲染网络生成新视角。近年提出的神经渲染方法 NeRF,直接从空间位置和视角(5 维输入)映射到颜色和不透明度(4 维输出)来进行体渲染,首先构建一个场景的稀疏模型,然后对系数模型中的采样点进行积分,用神经网络学习采样点与虚拟视角之间的关系,在静态场景上取得了很好的效果,如下图所示:

然而 NeRF 只能处理静态场景,并且需要大量时间和数据去训练模型。NeRF 的改进方法 Deformable NeRF 可以处理动态场景的神经渲染方法,而且可以在手机端运行,效果如下图所示:

AR 场景增强的相关技术已经在大型晚会中得到了较多的应用。一般来讲,需要事先在线下构建好虚拟模型及其动态效果,对场地构建 3D 模型和坐标,进行三维注册,在直播时将模型和动态效果渲染入视频流,嵌入场地的特定位置,然后呈现出来。现在对于大型场景的建模可以借助激光雷达完成。由于计算量巨大,需要借助边缘计算的方法,提高响应速度,降低延迟。
在传输部分,自由视角技术除了可以采用更大带宽、更低延迟的网络进行传输外,还可以采用硬件编解码、CDN 网络优化等方法进一步提高实时性。随着 5G 网络带来的增强带宽、海量连接、低延时高可靠特性,以及 VR/AR 技术的快速发展,上述技术路线正在逐渐落实。湖南电视台与华为联合制作的节目《舞蹈风暴》借助时空凝结设备,360 度立体呈现了舞者表演中的每一个旋转翻腾,用“风暴时刻”定格每一个精彩瞬间,让舞蹈之美在节目中得以具象呈现,带来了赏心悦目的视觉体验。

Intel True View 也为我们带来了良好的自由视体验。在橄榄球比赛这样激动人心的直播中,Intel True View 同样可以让电视机前的观众随意地选择自己想要的观看视角,紧盯自己最关注的细节,打破了传统直播视角固定的缺陷,增强了互动性。

总结,本文对 RTC 技术做了介绍,并简述了实时渲染技术的发展历史,然后介绍了实时图像与视频生成领域的相关研究工作与最新进展,最后提出 RTC 技术将朝着实时生成与传输 RT2C 方向发展。
参考资料:
1.CSDN. 实时通信 RTC 技术栈之:视频编解码[EB/OL].https://blog.csdn.net/netease_im/article/details/83513473. 2018.10.29
2.知乎. LiveMe FE 李承均:RTC 技术的入门和实践[EB/OL].https://zhuanlan.zhihu.com/p/168118142. 2020.08.05
3.知乎. 走过半个多世纪,计算机图形学的发展历程告诉你 5 毛钱的电影特效究竟多难[EB/OL].https://zhuanlan.zhihu.com/p/121620580. 2020.03.31
4.Siarohin A, Lathuilière S, Tulyakov S, et al. First order motion model for image animation [C]// Conference on Neural Information Processing Systems (NeurIPS), 2019.12
5.Wang T C, Mallya A, Liu M Y. One-Shot Free-View Neural Talking-Head Synthesis for Video Conferencing[J]. arXiv preprint arXiv:2011.15126, 2020.
6.Oquab M, Stock P, Gafni O, et al. Low Bandwidth Video-Chat Compression using Deep Generative Models[J]. arXiv preprint arXiv:2012.00328, 2020.
7.Mildenhall B, Srinivasan P P, Tancik M, et al. Nerf: Representing scenes as neural radiance fields for view synthesis[J]. arXiv preprint arXiv:2003.08934, 2020.
8.Park K, Sinha U, Barron J T, et al. Deformable Neural Radiance Fields[J]. arXiv preprint arXiv:2011.12948, 2020.
9.网易号. 惊艳之举!湖南广电联手华为再掀“舞蹈风暴”[EB/OL].http://mp.163.com/article/FR186L0G0517BTJ6.html. 2020.11.09
10.Youtube. It’s called True View | Intel[EB/OL].https://www.youtube.com/watch?v=Q6dY01q5j7M. 2020.09.03
作者介绍:
宋利,上海交通大学教授,博士生导师,IEEE 高级会员,图像通信与网络工程研究所副所长、人工智能研究院、未来媒体网络协同创新中心骨干成员。研究方向是多媒体信号处理、计算机视觉与人工智能。主持国家级科研项目 10 余项,发表学术论文 150 余篇,获授权发明专利 35 项,软件著作权 5 项。获国家科技进步二等奖、上海市科技进步一等奖、上海市技术发明一等奖、日本大川基金研究奖、IEEE ICME-Twitch 竞赛奖、国际会议最佳论文奖两次(IEEE VCIP 及 WCSP)。任 IEEE Transaction on Broadcasting 特邀编委、Multidimensional Systems and Signal Processing 编委,是 IEEE 电路与系统协会视觉信号处理与通信组技术委员、视频体验联盟技术组组长、中国智慧家庭产业联盟 4K 极客工作组技术委员、上海市信息家电行业协会技术委员。




