
本文最初发布于 The Startup 博客,经原作者授权由 InfoQ 中文站翻译并分享。
注意:这是该系列文章的第 4 部分。你可以点击这里阅读上一部分。
虽然我们在前两篇文章中讨论的人员、流程、架构和设计问题都是云原生解决方案的关键推动因素,但云原生解决方案最终要落在技术和基础设施上,这也是我们在本文中要讨论的内容。
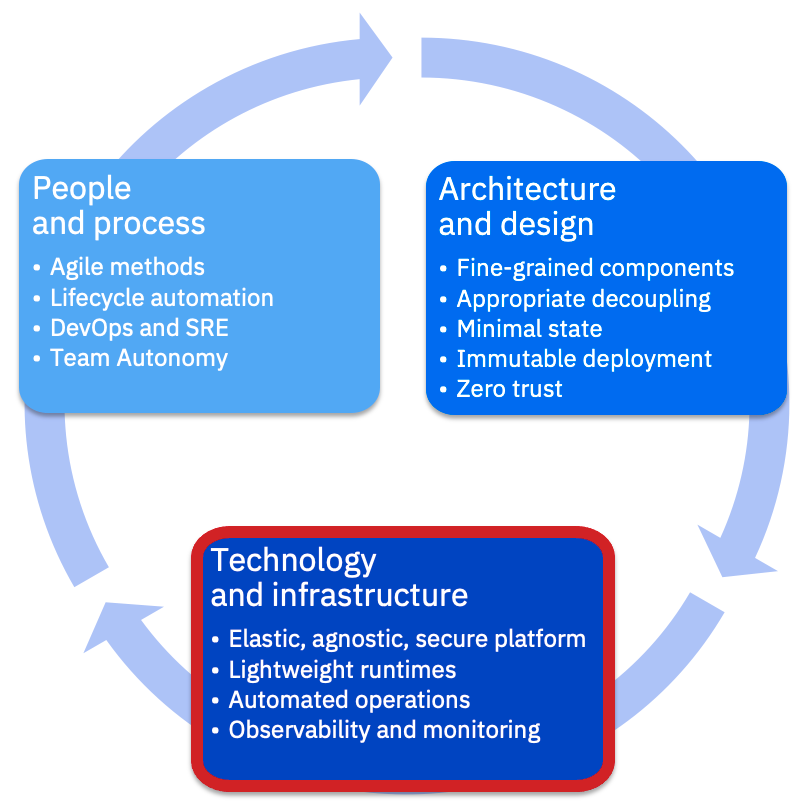
云原生要素:技术和基础设施
云基础设施就是将底层硬件抽象出来,使解决方案能够快速地自助配置和扩展。它应该能够使用相同的操作技能管理不同的语言和产品运行时。此外,它应该促进操作自动化,并提供一个可观测性框架。让我们仔细看下,在云原生方法中使用的基础设施有什么关键特征。

云原生的技术和基础设施
弹性、不可知且安全的平台
为了实现云原生,我们必须向部署组件的平台提很多要求。平台应该提供一种通用的机制,不管我们部署什么,它都能提供帮助,让我们不用考虑非功能性问题,同样,还应该“内置”安全性。因此,我们对平台的主要要求有:
弹性资源能力
不可知部署和操作
默认安全设置
如果开发人员要提高他们的生产力,就需要能够专注于编写创造业务价值的代码。这意味着平台应该解决负载平衡、高可用性、可伸缩性、弹性,甚至灾难恢复等问题。在部署时,我们应该能够指定高级的非功能性需求,而由平台完成剩下的工作。在这方面,我们将使用 Kubernetes 容器编排作为一个强大(实际上无处不在)的例子,但是云原生绝对不限于 Kubernetes 平台。
Kubernetes 集群可根据所部署的组件的需求,提供 CPU、内存、存储、网络等资源的自动化、弹性配置。资源池可以分布在许多物理机上,也可以分布在许多独立地区的多个可用区域上。它负责找到你所需要的资源,并将组件部署到这些资源中。你只需要指定需求——需要什么资源,它们应该或不应该扩展,以及它们应该如何扩展和升级。对于基于虚拟机的平台,我们也可以这样说,但正如我们将要看到的,容器带来了更多的东西。
假设我们遵循了上一节的架构原则,在容器中交付应用程序组件,让 Kubernetes 以标准化的方式执行部署和后续操作,而不考虑任何特定容器的内容。如果组件基本上是无状态的、可抛弃的、细粒度的、良好解耦的,那么平台就很容易以通用的方式部署、扩展、监控和升级它们,而不需要了解它们的内部结构。对于每一种软件,现在都有一种逐步抛弃专有安装和拓扑配置的趋势,像 Kubernetes 这样的标准就是其中的一部分。现在,它们都以相同的方式工作,我们可以受益于操作的一致性、学习曲线的降低以及附加功能(如监视和性能管理)更广泛的适用性。
最后,我们希望平台内置了安全,这样,我们从第一天起就可以相信它是安全的应用程序运行环境。我们不应该每次设计一个新组件时都需要重新设计安全内核;相反,我们应该能够从平台继承一个模型。在理想情况下,这应该包括身份管理、基于角色的访问管理、保护外部访问和内部通信。我们注意到,在这个例子中,Kubernetes 本身只是部分解决方案;对于一个完整的安全解决方案,还需要添加一些元素,比如用于内部通信的服务网格,以及用于入站流量的入站控制器。
轻量级运行时
要想实现操作敏捷性,就要保证组件尽可能简单和轻量级。这可以归结为三个主要特性。
快速启动/关闭
基于文件系统的安装和配置
基于文件系统的代码部署
为了实现可用性和可伸缩性,组件必须能够快速创建和销毁。也就是说,容器内的运行时必须可以优雅地启动和关闭。它们还必须能够处理不优雅地关闭。这意味着有许多优化可能可以做:从删除依赖项,减少初始化过程中的内存占用,到在镜像构建中启用编译“左移”。至少,运行时应该能够在几秒内启动,这个期望值会不断降低(如Quarkus)。
如果采用持续集成,我们还希望构建尽可能简单、快速。大多数现代运行时已经不再需要单独安装软件,而只需将文件放到文件系统上。类似地,根据定义,不可变镜像不应该在运行时更改,它们通常从属性文件读取配置,而不是通过自定义运行时命令接收配置。
同样,实际的应用程序代码也可以放在文件系统中,而不是在运行时部署。这些特性组合在一起,使得构建能够通过简单的文件复制快速完成,非常适合容器镜像的分层文件系统。
操作自动化
如果我们能够作为发布的一部分,交付在运行时配置解决方案的整个行动方案(包括基础设施和拓扑结构的所有方面),会怎么样呢?如果我们可以将行动方案存储在代码存储库中,并可以像处理应用程序代码那样触发更新,情况会怎样?如果我们让操作人员这个角色聚焦于实现环境自治和自愈,会怎样?这些问题引出了一些关键的方法,我们应该以不同的方式处理基础设施:
基础设施即代码
存储库触发的操作(GitOps)
站点可靠性工程
正如前面所讨论的,基于镜像的部署已经使部署的一致性提高了很多。然而,这只交付了代码及其运行时。我们还需要考虑如何部署、扩展和维护解决方案。在理想情况下,我们希望能够将所有这些都作为“代码”和组件的源代码一起提供,以确保在不同环境中构建时的一致性。
术语“基础设施即代码”最初关注的是编写底层基础设施(比如虚拟机、网络、存储等)的脚本。编写基础设施脚本并不是什么新鲜事,但有越来越多的专用工具,如 Chef、Puppet、Ansible 和 Terraform,大大推动了这方面的发展。这些工具首先假定有可用的硬件,然后在硬件上准备并配置虚拟机。有趣的是,当我们迁移到容器平台时,这个过程会有什么变化。
在理想情况下,我们的应用程序应该可以假设,已经有一个 Kubernetes 集群可用。集群本身可能是使用 Terraform 构建的,但这与我们的应用程序无关;我们只要假设集群是可用的。那么,现在我们需要提供什么样的基础设施即代码元素,来完整地描述我们的应用程序呢?可以认为,就是那些打包在 helm charts 或 Kubernetes Operator 中的各种 Kubernetes 部署定义文件以及相关的客户资源定义(CRD)文件。结果是一样的——将一组文件与我们的不可变镜像一起交付,它们完整地描述了应该如何部署、运行、扩展和维护。
因此,如果我们的基础设施现在成了代码,那么为什么不用与应用程序相同的方式构建和维护基础设施呢?每次我们提交一个基础设施的重大更改时,都可以触发一次“构建”,它会自动地部署到环境中。这种日益流行的方法被称为 GitOps。值得注意的是,这种方法特别偏爱采用“声明式”而非“命令式”方法的基础设施工具。你提供了一个描述“将来”目标状态的属性文件,然后该工具将解决如何让你达到目标状态的问题。上面提到的许多工具都可以在这种方式下工作,这是 Kubernetes 的基本操作方式。
真正的系统是复杂的、不断变化的,所以认为它们永远不会崩溃是不合理的。不管像 Kubernetes 这样的平台在自动化动态扩展和可用性方面有多好,问题还是会出现,至少最初还是需要人工干预来诊断和解决。然而,在实现了细粒度、弹性伸缩组件自动化部署的世界中,反复的人工干预将变得越来越不可能,只要可能,就要实现自动化。为了做到这一点,操作人员需要重新接受培训,成为“站点可靠性工程师”(SRE),编写代码执行必要的操作工作。事实上,一些组织已在明确地招聘,或将开发人员移到运营团队中,以确保工程文化。人们越来越多地保证解决方案是可自愈的,这意味着当系统扩展时,我们不再需要增加相应的操作人员。
可观测性和监控
随着组织向更细粒度的容器化工作负载发展,将监控作为事后加上去的东西是不可持续的。为了在云原生环境中取得成功,这又是一个我们需要“左移”的例子。解决这个问题取决于我们是否能够回答下面三个关于组件的问题:
它是健康的吗?你的应用程序有可以轻松访问的状态吗?
它里面发生了什么?你的应用是否有效地使用了平台无关的日志记录和跟踪?
它是如何与其他组件交互的?你利用了跨组件相关性吗?
可观测性并不是一个新术语,尽管它在 IT 领域,尤其是在云原生解决方案方面得到了新的应用。它的定义来自于非常古老的控制理论。它是一种度量,是指基于从外部看到的内容,可以在多大程度上理解系统内部的状态。如果你希望响应性地控制某个东西,你就需要能够准确地观测它。
有些定义还做了区分,监控是针对已知的未知因素(如组件状态),而可观测性是针对未知的未知因素——为之前没有想过的问题寻找答案。在一个高度分布式的系统中,你两者都需要。
平台必须能够轻松、迅速地评估已部署组件的运行状况,以便快速做出生命周期决策。例如,Kubernetes 要求组件实现简单的探测,以报告容器是否已启动、是否已准备好工作以及是否运行良好。
此外,组件应该基于其活动,以标准的形式提供易于访问的日志记录和跟踪结果,用于监控和诊断。通常,在容器中,我们只简单地记录到标准输出。然后,平台可以分类整理和聚合这些日志,并提供查看和分析服务。
对于细粒度组件,涉及多个组件的交互可能会增加。为了能够理解这些交互并诊断问题,我们需要能够可视化跨组件请求。OpenTracing是一个非常适合容器世界的、越来越流行的现代化分布式跟踪框架。
回顾
下图是前面提到的让云原生采用取得成功的所有关键要素:
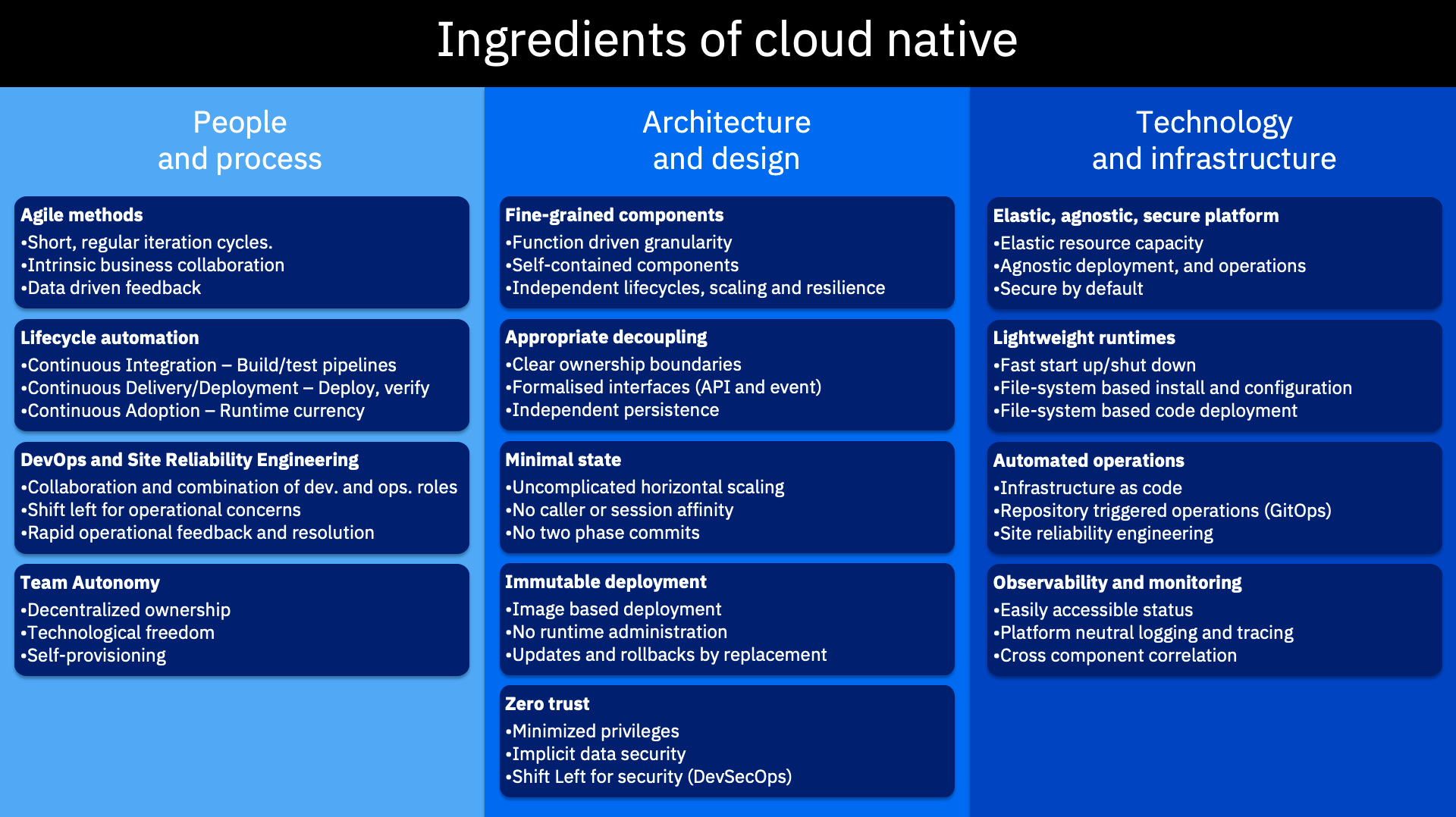
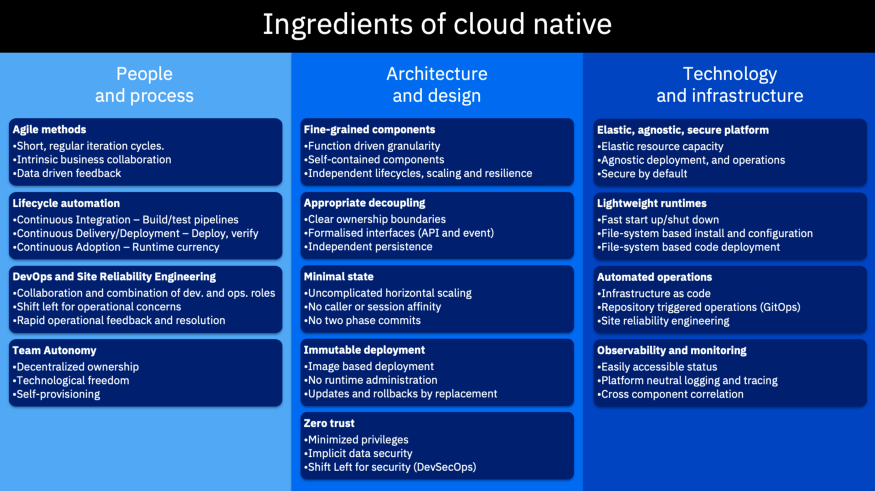
云原生的要素
通常,它们是相互联系,而且相互加强的。你需要全部都做吗?这样的问题表述方式可能是错误的,就好像是说上面的任何一项都是简单的二元问题,“是的,你需要”或“不,你不需要”。问题应该是你要做的多深入。无疑,你需要考虑每一个方面的现状,并评估是否需要更进一步。在下一篇文章中,我们将回到“为什么”人们被云原生所吸引,并看看这是否可以帮我们理清,我们如何、何时以及在多大程度上采纳上述要素。
查看英文原文:
The “How” of Cloud-Native: Technology and Infrastructure Perspective
延伸阅读:




