
ByConity 是字节跳动开源的云原生数据仓库,在满足数仓用户对资源弹性扩缩容,读写分离,资源隔离,数据强一致性等多种需求的同时,提供优异的查询,写入性能。
GitHub |https://github.com/ByConity/ByConity
烽火星空(文中简称“烽火”)在搭建其 HSAP 数据库 FMDB 的过程中遇到了高并发场景下查询性能不理想,并且某些查询 SQL 有长尾现象等问题。通过接入 ByConity,利用其存算分离、读写分离、便于扩缩容、复杂查询优化等特性对 FMDB 的单表查询场景进行了相关优化,最终实现其业务场景下的平均响应速度平均提升至 3 倍,P99 响应时间缩短为 1/8。产品性能和流畅性均大幅提升。
本文主要介绍烽火在 HSAP 领域的工程化实践,以及如何使用 ByConity 加速其应用场景。
HSAP 在大数据领域优势及挑战
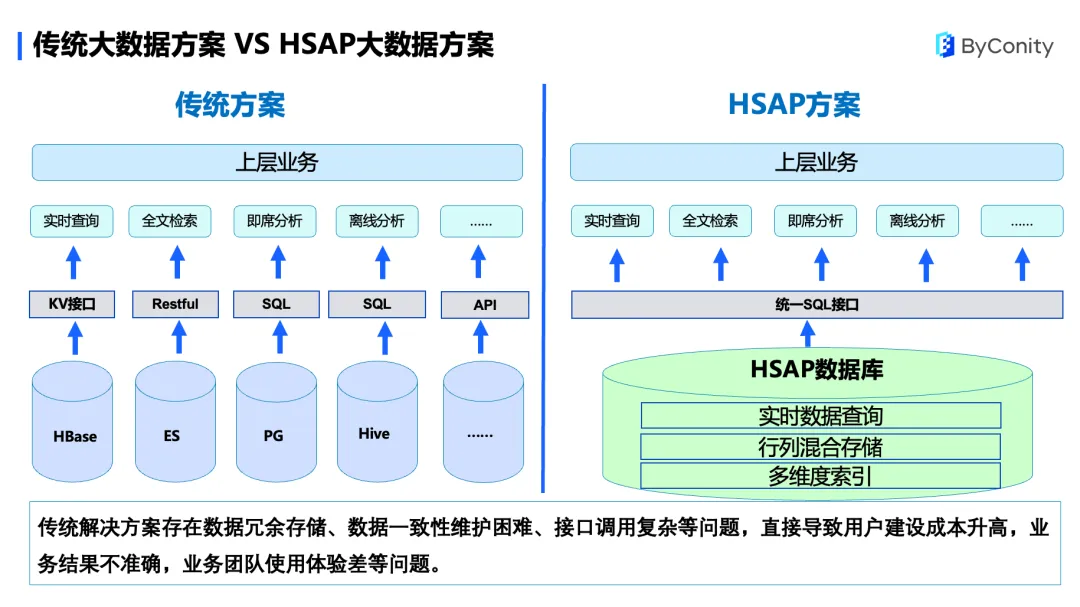
传统大数据方案 VS HSAP 大数据方案
传统大数据解决方案存在以下问题:
数据冗余存储。比如,同一份数据有可能会存到不同的数据库中,来提供查询和分析的业务场景。
数据一致性维护困难。在数据冗余存储的背景下,一份数据有可能会存储在不同的数据库中,导致数据一致性问题。最后,接口调用复杂。
接口调用复杂。每个数据库提供不同的接口,比如 HBase 提供一个 KV 接口,ES 提供一个 Restful 接口,PG 和 Hive 等提供了 SQL 接口,需要分别调用,使用时复杂度高。这些会直接导致用户建设成本升高,业务结果不准确,业务团队使用体验差等问题。
Hybrid Serving/Analytical Processing(HSAP)是面向 Serving 和 AP 场景混合设计的系统,能够简化用户系统架构,统一技术栈,具有较大的成本优势。
HSAP 的方案在底层存储使用了行列混合存储以及多维索引的方式,将数据进行统一存储,存储成一份,解决了数据冗余存储的问题;由于数据只存储一份,保持了数据一致性。另外,它对外提供统一的 SQL 接口。这种方式用户使用简便,便于业务调用。
但此方案在技术上存在一些挑战,对实时入库、高并发点查和数据分析都有较高的要求,比如实时数据快速接入、行列混合存储、多维度二级索引、混合负载高效查询、系统高可用、统一 SQL 访问接口、集群方便扩展等。
烽火 HSAP 数据库方案和设计
针对以上挑战,烽火基于 HSAP 提出了数据库整体方案 FMDB,它具有行列混合,一份数据、多份索引以及查询分析一体等特点。
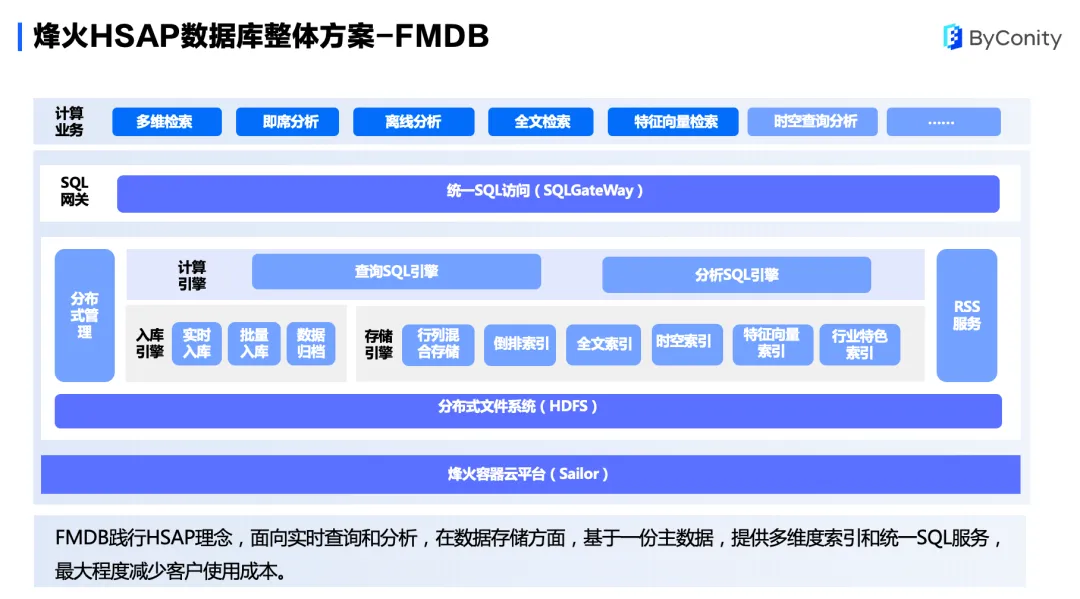
FMDB 整体分为烽火容器云平台、数据库核心、SQL 网关三大部分。烽火容器云平台是基于 K8s 提供的一个资源管理和调度的系统,是整个系统的底座,负责对 FMDB 计算资源的管理及运维。数据库核心分为计算引擎、入库引擎和存储引擎。SQL 网关层通过统一的 SQL 进行对外访问,使用了一个 SQL 路由规则,通过这种路由规则,将查询的 SQL 分为查询 SQL 和分析 SQL 两类。
架构设计
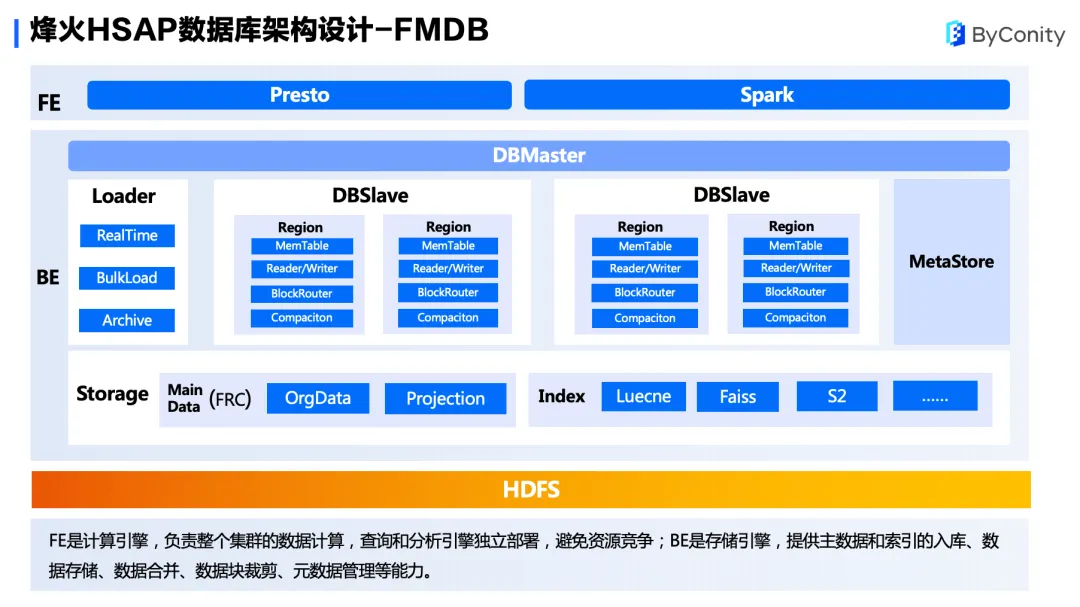
数据库的架构设计分为两大部分。
FE 是计算引擎,负责整个集群的数据计算,目前使用 Presto 和 Spark 来进行计算。
BE 是存储引擎,主要采用 Master/Slave 架构,数据以 Region 方式在每个 Slave 节点进行存储。数据写入先构造成一个 Region 格式,并写到一个 MemTable 中,当 MemTable 写满时会刷到 HDFS 中,当 HDFS 数据达到一定阈值时将进行数据合并。另外块路由(BlockRouter)机制可以对查询进行数据裁剪,降低了查询的复杂度。
在存储方面,我们主要使用 FRC 数据格式进行存储,包括主数据和 Projection 数据。在索引方面,我们使用 Luecne、Faiss 和 S2 的组件,提供全文索引、特征向量检索、空间位图等业务分析。
ByConity 在烽火的选型历程
2020 年 3 月,公司启动 FMDB 项目,对 Presto、Doris 等 MPP 计算框架进行调研,最终确定 Presto+Spark+FRC 的技术栈作为 HSAP 数据库技术底座。2022 年 12 月,团队开始关注 ByConity,在次年 1 月开源后引入并替换 Presto 作为查询计算引擎方案。2023 年 12 月,我们将 ByConity 融入到 FMDB 产品中,并在客户现场测试,取得了不错的性能效果。
在 FMDB 调研中 ClickHouse 也是我们的考虑之一。它的优点包括高效的 Pipeline 数据处理方式;高效的 MergeTree 数据存储引擎;向量化执行加速;MMP 架构,任务调度轻量级。
但它也存在一些痛点,比如:第一,分布式部署困难。如果要部署分布式表,首先要在每个 shard 上创建一个 MergeTree 表,然后再在 MergeTree 基础上创建一个分布式表,这样部署相对比较困难。其次,Join 场景性能不理想。当数据量比较大时 Join 性能很耗计算资源,且耗时较长。第三,扩缩容困难,需要迁移大量数据,成本较高。第四,副本维护不便。因为使用 zk 来进行副本维护,这给 zk 的压力也比较大。
ByConity 开源之后我们团队进行了一些研究,它有以下几个特点:首先,存算分离。将存储和计算进行分离,数据打包到存储系统中。其次,读写分离。将查询和入库进行分离,读节点和写节点之间的资源也不再互相影响。第三,DiskCache 加速。它采用将远端数据下载到本地的技术,可加快查询。第四,扩缩容方便。它计算和存储分离,扩容无需做到数据均衡,可以快速弹性扩缩容。第五,分布式表。相比于 ClickHouse 来说,不再有本地表和分布式表的区分,使用一个 CNCHMergeTree,可以直接创立分布式表。最后,复杂查询优化。对于复杂查询来说,当开启优化器后,可以对查询进行加快。
ClickHouse 和 ByConity 使用差异可参考:从使用的角度看 ByConity 和 ClickHouse 的差异
FMDB 基于 ByConity 的加速实践
在 FMDB 搭建中我们遇到了一些痛点,单表排序和分组查询在高并发场景下面临 SQL 耗时较长的问题,业务体验也不太好。
分析主要原因有以下三点:第一,HDFS 负载高时对查询有较大影响;第二,Presto 执行框架对于高并发有明显的长尾现象;第三,对 JVM 内存使用比较容易出现 OOM 现象。
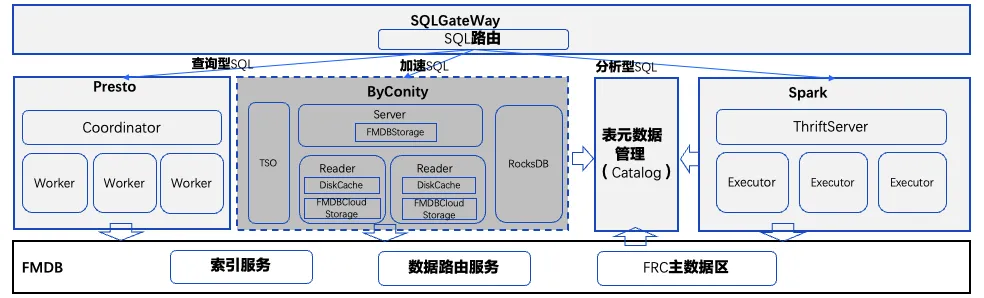
在 FMDB 集群中引入少量 ByConity 计算节点后,利用 ByConity 高并发访问和 DiskCache 机制,解决了 FMDB 上述存在的痛点问题,降低了 SQL 的延时现象和长尾现象,提升了系统的流畅性。近期我们准备使用 ByConity 替换 Presto 作为查询 SQL 引擎。
特定场景下的加速效果
下图为某特定业务场景下,对原生 FMDB 和使用 ByConity 的 FMDB 进行对比测试。从结果数据来看,不同并发下,平均响应时间分别缩短为原来的 38% 和 25% 左右,提升效果比较显著。P99 响应时间最高缩短为原来的 1/8。TPS 平均也提升为近 3 倍。

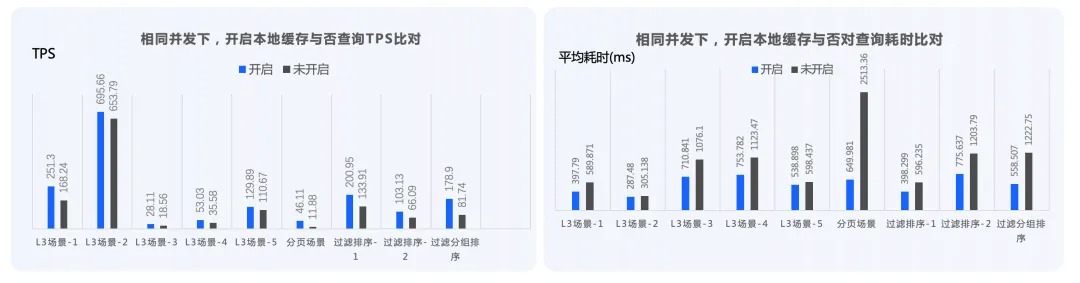
下图为对 ByConity 开启 DiskCache 和没有开启 DiskCache 进行的对比,在某些场景,如分组过滤和排序场景下,性能有很好的提升。
ByConity 在 FMDB 中的适配
将 ByConity 应用到 FMDB 的过程中根据业务需求进行了一些适配,主要包括以下四点:
元数据存储扩展。ByConity 内部使用 FoundationDB 作为元数据持久化,考虑 FoundationDB 组件相对较重,且需要运维经验,因此对 ByConity 源码进行了修改,使用 RocksDB 服务提供元数据持久化。
查询优化。在数据查询的场景下,将 ByConity 查询条件推至 FMDB 底层存储引擎,减少进入 Pipeline 的数据量,提高查询效率。同时使用 ReplacingMerge 算子优化 Upsert 场景,提高合并读效率。
存储引擎扩展。这也是最重要的一点,通过对 ByConity 数据源进行扩展,将 FMDB 的主数据、索引和元数据对接到 ByConity,并支持 DiskCache,提高 FMDB 特定场景的查询性能。
倒排索引支持。我们团队在去年尝试将 ClickHouse 社区中的倒排索引迁移到 ByConity。
由于 ClickHouse 原生的倒排索引是一种行式的方式,我们基于数据粒度将其进行优化,提升了倒排索引的并发能力。内部测试结果显示,其倒排索引能力和主键索引能力,性能基本上差不多。目前该功能还在实验中。
未来规划
未来我们团队将升级最新版本,并探索将更多的功能引入 ByConity,进一步提升产品能力。
将内部使用的版本从 ByConity 0.2 升级到 ByConity 0.4 版本(官方已经更新 0.3 和 0.4),并尝试将复杂计算迁移至 ByConity;
探索将特征向量存储和索引迁入 ByConity。考虑我们目前对外使用的还是 ClickHouse,可能未来我们会把特征存储迁到 ByConity 上;
将 ByConity 和列计算引擎引入到 Spark,形成 Native 计算,加速离线计算;
探索将图计算引擎底层存储迁入 ByConity。
- END -

点击ByConity Meetup 西安站_哔哩哔哩_bilibili可直达视频回放




