
前言
压缩技术对于图像、视频应用十分重要。在保证同样主观质量的前提下,如何将图像压缩到更小体积便于互联网信息传输,火山引擎视频云团队不断突破压缩技术“天花板”。
字节跳动在公司成立之初就建设了图像处理平台,起初主要服务于今日头条 APP 的图文资源。随着业务扩展,后逐步服务于抖音图集、短视频封面、图虫等几乎用户能看到的所有图片展示场景。火山引擎视频云团队将字节跳动图像处理的实践,整理为《veImageX演进之路》系列,将从产品应用、后端技术、前端技术、算法、客户端 SDK 详细解读字节跳动背后的图像技术。
veImageX 是火山引擎基于字节跳动内部服务实践,推出的图像一站式解决方案 ,覆盖上传、存储、处理、分发、展示、质量监控全链路应用。
背景
互联网内容的展示离不开图片,通过 CDN 展示分发图片可以提升图片访问速度,但是也需要为带宽付费。HEIF 图片格式有着卓越的压缩性能,相比 WebP 可以节省 30% 的图片码率,由此可以为业务节省相当规模的带宽成本。
但 HEIF 格式是一把双刃剑,相比其他格式,在提升压缩率的同时,也需要消耗更多 CPU 计算资源。为了降低 HEIF 格式的编码计算成本,veImageX 采用了 FPGA 异构架构,逐步将 HEIF 编码的流量从 CPU 计算集群迁移到 FPGA 计算集群。
在流量迁移过程中,最初整体流量较小,FPGA 编码服务看起来很稳定。但随着迁移过程递进,当 FPGA 的单卡 QPS 上涨到一定阈值后,FPGA 卡所在宿主机的性能瓶颈逐渐暴露出来,影响了整体的迁移工作。
本文会对迁移过程中遇到的性能瓶颈做分析,并给出优化解决方案。经过这一系列优化措施,veImageX 整体 CPU 负载从 80% 降低为 30%,相应的服务延时从 140ms 降低为 4ms。
架构
首先,我们看一下 FPGA HEIF 静图分发链路的整体架构。
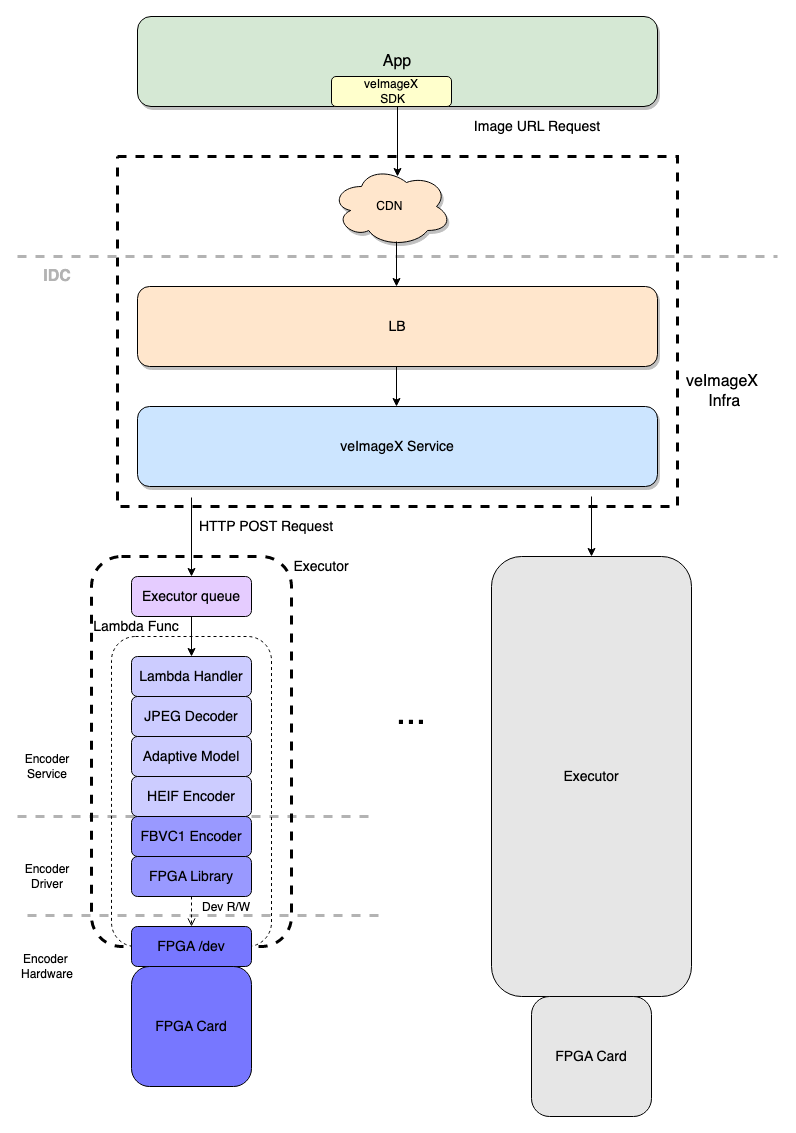
链路分为三块:
● 业务 App:一般会集成 veImageX 的图片 SDK。既可以兼容各类图片格式(自然也包括 HEIF),提供了图片的下载、解码、展示功能。也支持将访问图片过程中产生的指标数据上报,这样可以方便在控制台查看这些性能指标,比如解码耗时、图片加载成功率等。
● veImageX 分发基础链路:主要解决了图片分发问题,提供了基础的图片实时处理能力。其中 CDN 缓存了图片请求,提供了加速访问的能力;veImageX 源站服务主要负责访问权限的校验、流量控制、图片资源下载以及静态图片的主体处理流程。对于 HEIF 静图编码场景,veImageX 源站服务则需要和 FPGA HEIF 编码服务互动,协作完成。
● FPGA HEIF 编码服务:自上而下可以分为编码服务层、编码驱动层、编码硬件层。
为了解决计算资源异构引入的耦合问题,FPGA HEIF 的编码能力通过 HTTP 服务化的方式提供出来。所有的 FPGA 卡部署于字节跳动自研的 Lambda 计算平台。通过 Lambda 函数+资源虚拟化的方式,将 HEIF 编码功能抽象为上游可直接调用的服务,并能确保将编码请求均衡地调度到各个 FPGA 卡上。物理机上的每一张 FPGA 卡和对应的主机 CPU 和内存资源都被打包,经由 Executor 管理。此外,为了防止 FPGA 卡被突发流量打挂,Executor 内置了一个执行队列,用于控制 FPGA 卡的并发吞吐。
编码服务层主要负责解析 HTTP 请求,获取待编码的图片数据。待编码的图片数据一般通过 JPEG 格式传入,因此其中内嵌了一个 JPEG 解码器。此外,veImageX HEIF 支持自适应编码选项,通过服务层内的自适应模型预测编码所用到的质量参数。服务层中的 HEIF 编码器是一个适配层,屏蔽了底层计算架构的差异,对于 CPU 和 FPGA 都可以提供相同的编码接口,将传入的 RGBA 像素矩阵编码为 HEIF 码流。
编码驱动层中的 FBVC1 编码器可以将图片像素序列编码为二进制码流,上层的 HEIF 编码器拿到这个码流后,按照 HEIF 标准格式封装即可。FBVC1 编码过程中,依赖了 FPGA 驱动库和编码硬件层打交道,发送指令,读写 FPGA 设备。
优化方向
降低线程数
在迁移测试 FPGA 编码服务过程中,我们也遇到了一些性能瓶颈的问题。首当其冲的是,当单机 QPS 达到 2K 时,CPU 负载高达到 60%。通过分析热点,我们可以看到问题出现在 onnxruntime 这个库上。
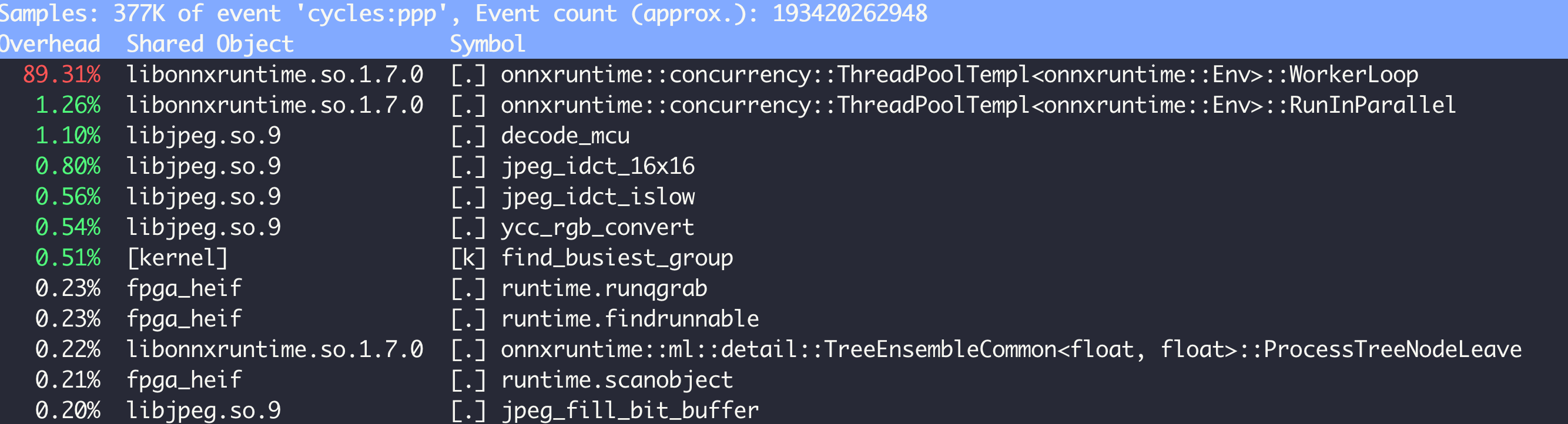
从调用的 API 很容易联想到,这是一个线程相关问题。我们都知道,如果没有手动设置线程数的话,默认会使用物理机核数作为线程数,导致整体的调度开销比较严重。
因此,需要根据宿主机的 CPU 配置情况,手动配置线程数,不要使用默认配置,最终将 CPU 负载从 57% 降低到 7%。
调优 GOMAXPROCS
HEIF 的编码服务层是使用 Golang 实现的。而 Golang 中使用了 GOMAXPROCS 这个环境编码来控制底层并发度。默认情况下,GOMAXPROCS 是和物理机核数相关。所以这里也遇到了和上一个问题相同的根因,需要限制整体的并发度。
针对 GOMAXPROCS 做了调优,在单机 QPS 达到 8K 时,CPU 负载下降了 6% 。
限制磁盘 IO
首先通过 statio 查看磁盘情况,

再结合下面的火焰图(黑框内有明显的磁盘 IO 操作)
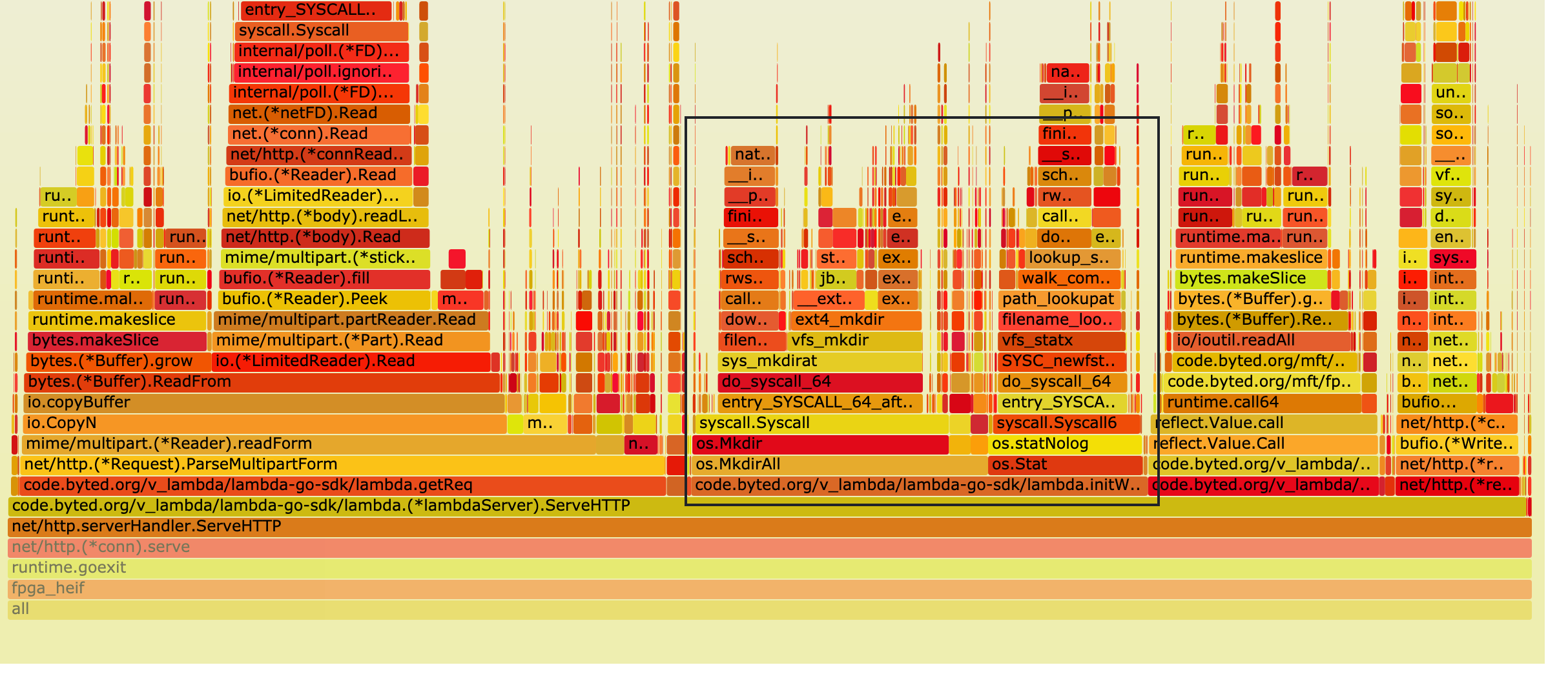
这里很容易能想到这些磁盘 IO 操作导致了整体延迟的升高。但从结果来看,平均 8ms 还在预期范围内。但 HEIF 编码服务对处理的延迟要求较严格,请求处理过慢会导致请求堆积,此时 FPGA 的计算潜力无法做到完全释放。
针对这块定向优化,相关延时下降至 0.5ms,CPU 负载下降 3%。
另外,我们观察到磁盘和 cached memory 较高,这显然不太正常。
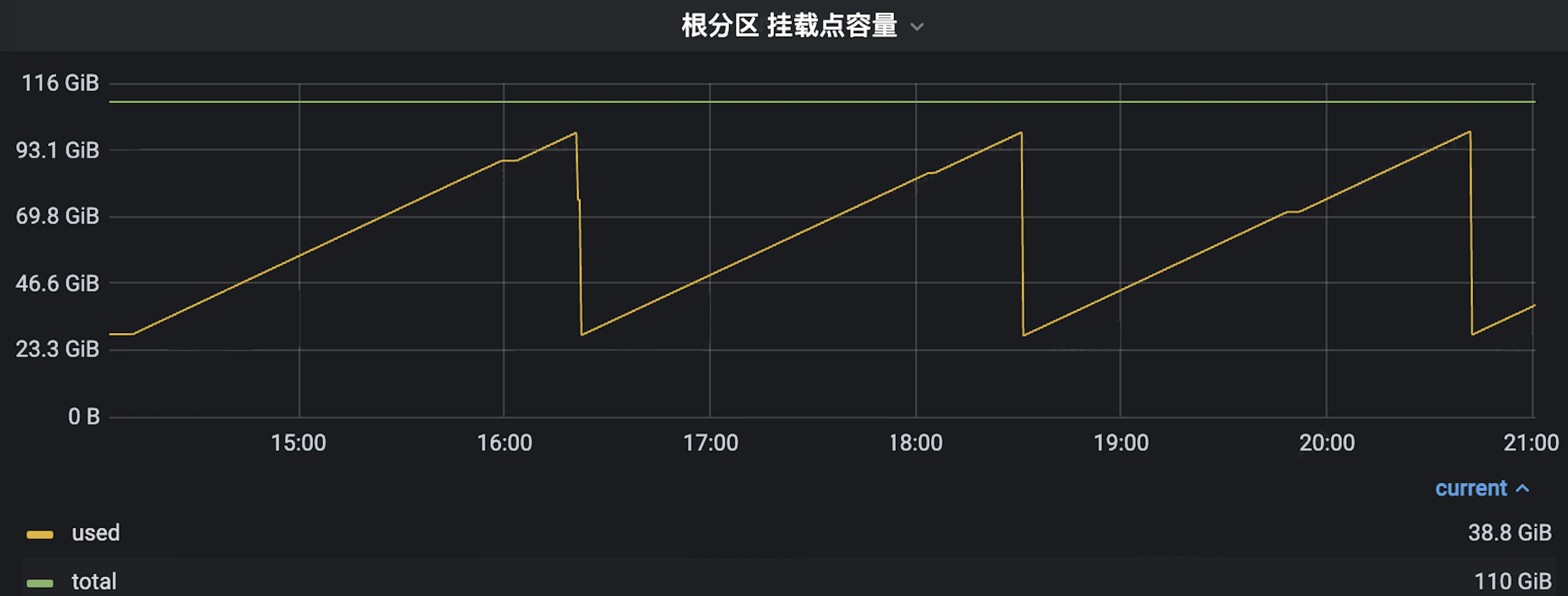
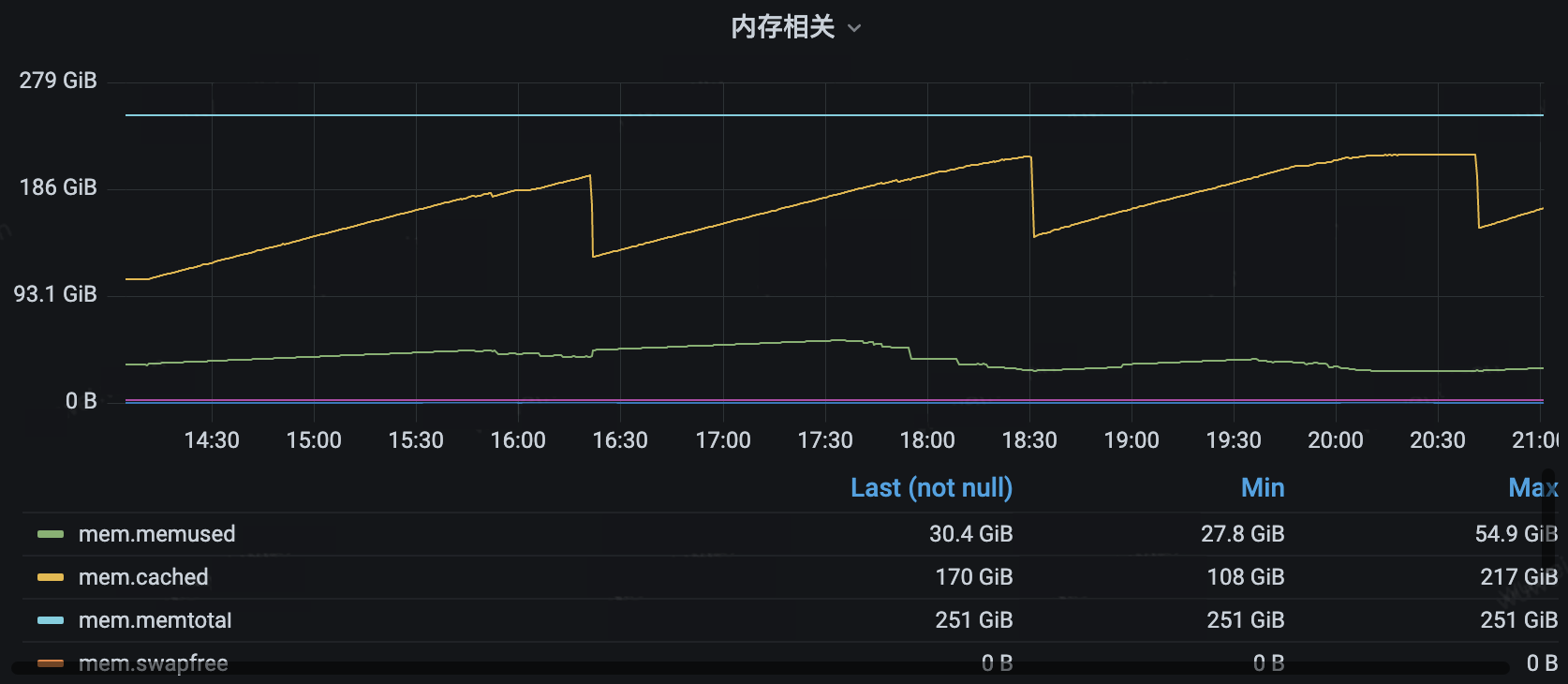
进一步定位后,确定是编码服务造成的。详细排查后发现,编码驱动层中的 FPGA 驱动程序的部分调试日志未关闭,导致大量的日志写磁盘。当关闭驱动的调试日志后,CPU 负载下降 5% 。
合并 CGO 调用
编码服务包括两部分的 CGO 调用:
● 自适应编码模型预测:每个请求会有最多 5 次的推理,合并为 Batch,减少为 1 次调用
● FPGA 编码:直接调用 SDK 需要 6 次 CGO 调用,对这部分实现 C 的封装,减少为 2 次调用
这部分优化影响较小,在延迟数据层面不是很明显,模型预测部分可能有几百 us 的优化。
减少 GC
编码服务每次处理请求都需要获取图像 raw data,因此服务会多次创建 []byte 的图像数据对象,容易导致频繁 GC。
一个解决问题的思路是在服务启动前预分配一个固定的对象池,每次请求需要的 []byte 对象直接从对象池里拿。此外,也曾尝试过使用 Golang 标准库中的 sync.Pool,但效果不好,可能的原因是 sync.Pool 里依然有一些 GC 相关的策略,不符合我们这个场景。
这部分优化后,CPU 负载下降了 6% 。
均衡中断
从系统的监控中,我们观察到各 CPU 负载不是很均匀。

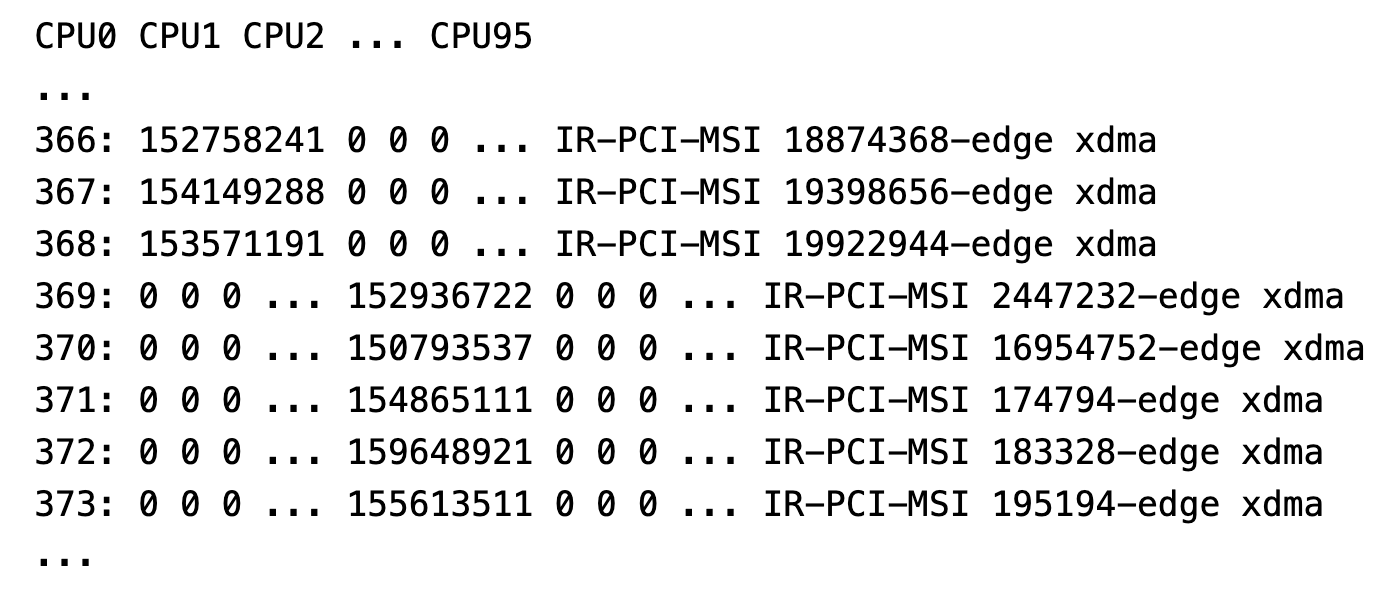
编码过程中发生的中断情况
我们可以得出结论,FPGA 的相关中断被只绑定到了特定的 CPU 上,没有分布均匀。这个在当时并没有成为瓶颈,所以优化后没有明显提升。
加速图片解码
我们从火焰图可以看到解码时间占服务延时的较大部分。
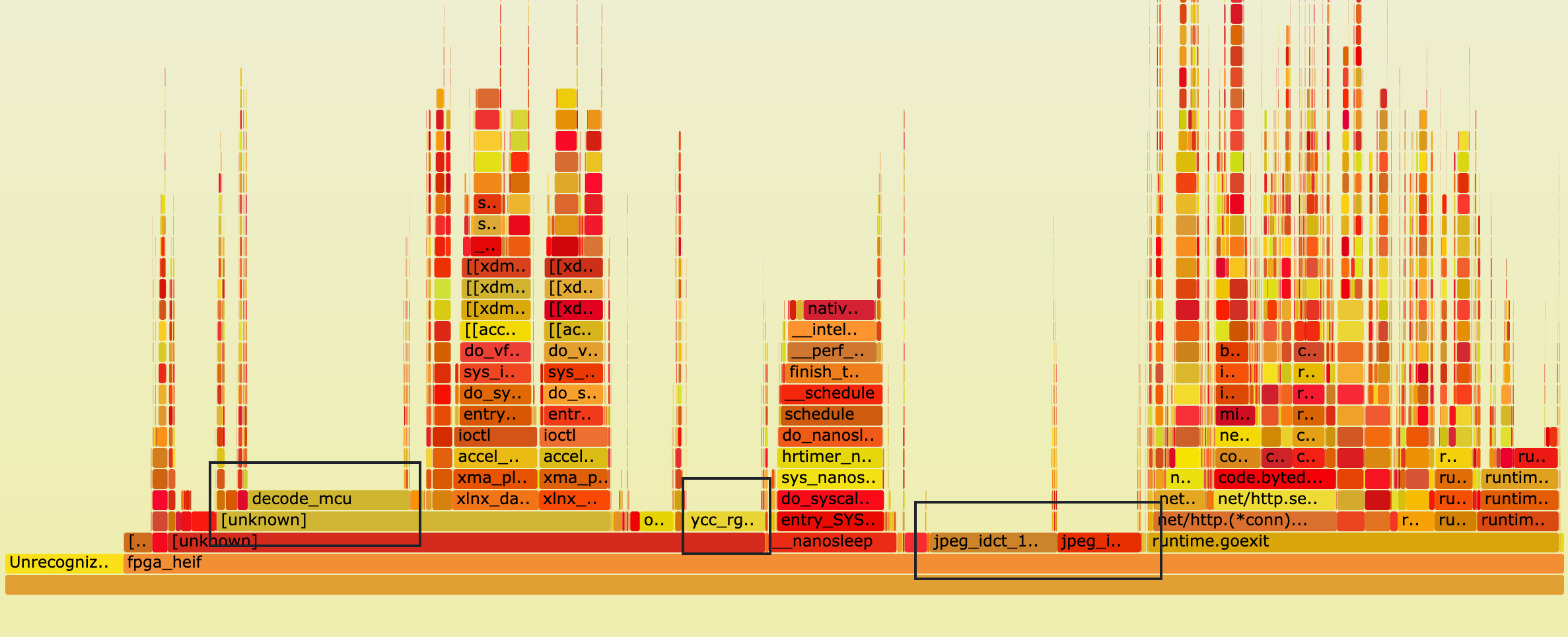
对火焰图中黑框内调用栈分析后,观察到有相当部分时间消耗在了 JPEG 解码上。调查后,发现底层 SDK 解码使用了 libjpeg,整体性能不佳。这里我们替换为使用 SIMD 实现的 libjpeg-turbo 解码库后,CPU 负载降低了 10%,耗时减少 2ms。
优化总结
基于优化后的版本再次做性能压测,使用 300x400 分辨率的测试图片,当单机 QPS 达到 10K 时,编码服务整体性能指标变化如下:
● CPU 负载从 80% 降低为 30%
● 服务延时从 140ms 降低为 4ms
可以看到,经过我们一套“组合拳”优化后,整体编码服务的性能有了明显提升。
写在最后
目前火山引擎 veImageX 已经上述实践形成端到端的解决方案对外输出,帮助每一个互联网企业用更低的成本达到更好的图片加载效果。除了商务降本之外,也可以用更“绿色”的算法降本,为行业降本增效提供了一种创新可能性。
了解更多 veImageX,点击阅读原文:https://www.volcengine.com/products/imagex




