昨晚,OpenAI 推出了名为 GPT-4.1 的新模型,该系列优先提升了编码能力和指令跟随能力,同时将上下文窗口扩展到了 100 万个 tokens,大约相当于 75 万个单词。所有这些模型的知识截止日期为 2024 年 6 月,相比之前的版本,能提供更贴合当下的上下文理解。
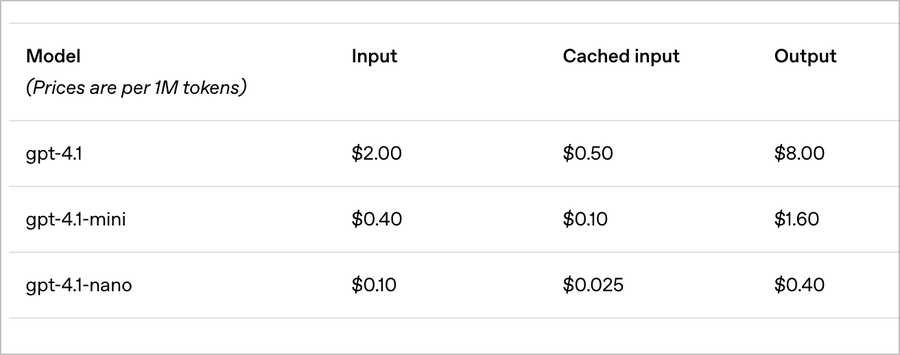
该系列包括标准的 GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano,所有版本都可以通过 API 使用,但无法在 ChatGPT 中使用。其定价采用分级结构:GPT-4.1 每百万个输入 tokens 收费 2 美元,每百万个输出 tokens 收费 8 美元;而 GPT-4.1 nano 作为 OpenAI“有史以来最便宜、最快的的模型”,每百万个输入 tokens 仅收费 0.1 美元。
目前,已经有不少用户在体验 GPT-4.1 的效果了。一位网友在试用后表示,“GPT-4.1 可以处理所有其他 OpenAI 模型无法应对的大篇幅上下文。”还有网友用 GPT-4.1 模型绘制一只鹈鹕,并将其与 Grok 3、LLama 4 和 Gemini 2.5 Pro 的生成结果进行比较,被众人评 Gemini 做得更好。 Box AI 则分享了用 GPT-4.1 模型来研读一份冗长的收益报告文档、从中提取出数据字段的例子,并表示其“能够大规模地对任何数据类型进行查询、整合、分析和总结”。
此外,GPT 4.1 现已接入 ChatLLM。在代码处理方面,它似乎不如 Gemini 2.5 Pro 和 Claude 3.7 Sonnet。
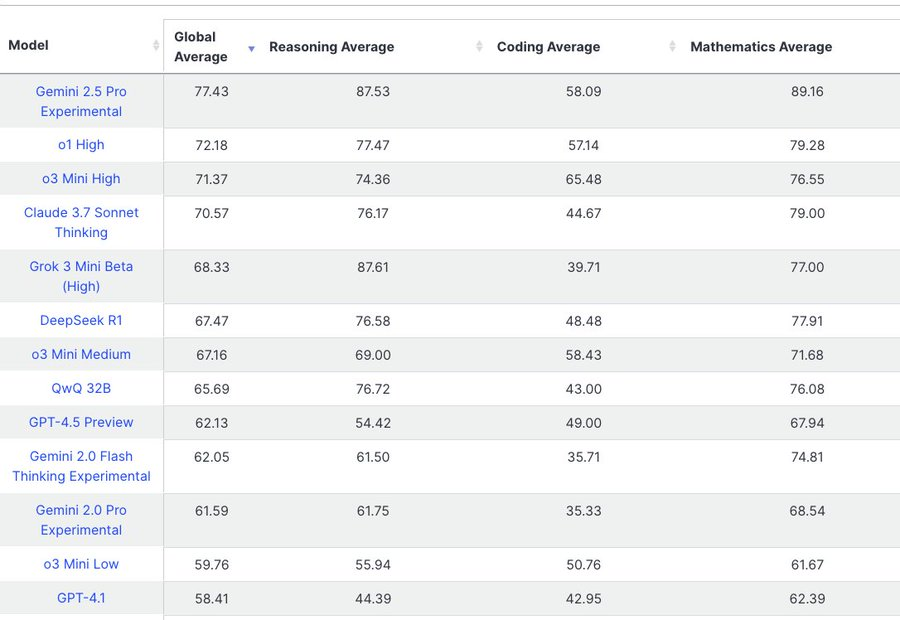
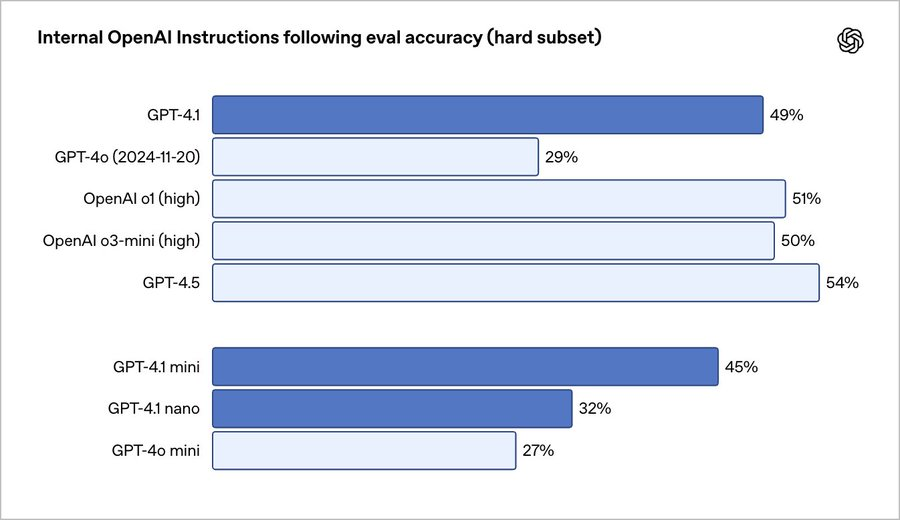
OpenAI 声称,在包括 SWE-bench 在内的编码基准测试中,完整的 GPT-4.1 模型的表现优于其 GPT-4o 和 GPT-4o mini 模型。其中,GPT-4.1 在格式遵守、遵守否定指令和排序等任务上的排名优于 GPT-4o,GPT-4.1 mini 和 nano 更高效、更快速,但也牺牲了一定准确性。
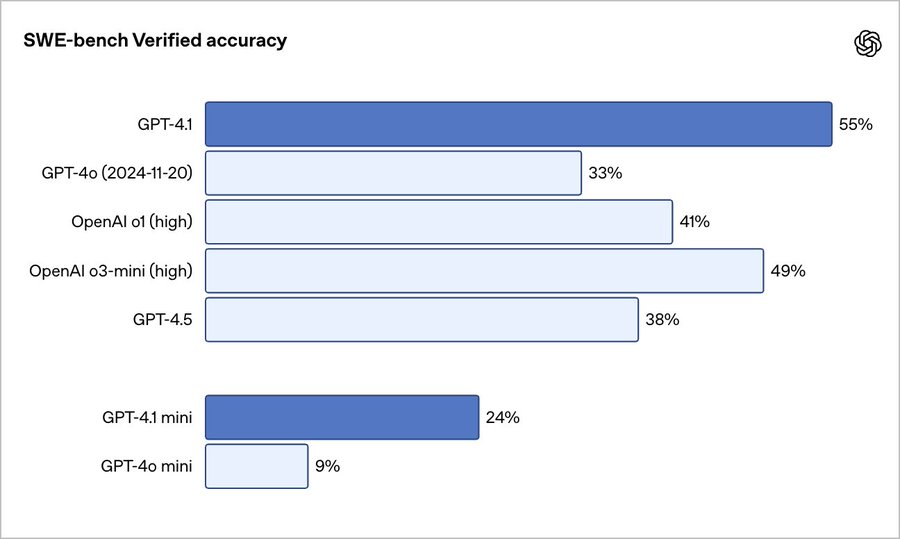
根据 OpenAI 的内部测试,GPT-4.1 一次可生成的 token 数量(32,768 对 16,384)多于 GPT-4o,其在 SWE-bench Verified(SWE-bench 的人工验证子集)上的得分介于 52%和 54.6%之间。不过,这些数字略低于谷歌和 Anthropic 在同一基准测试中报告的、分别为 Gemini 2.5 Pro(63.8%)和 Claude 3.7 Sonnet(62.3%)的分数。
但 GPT-4.1 在 Video-MME 的长视频理解测试中达到了 72%的准确率,相比 GPT-4o 的 65.3%有了显著提升。
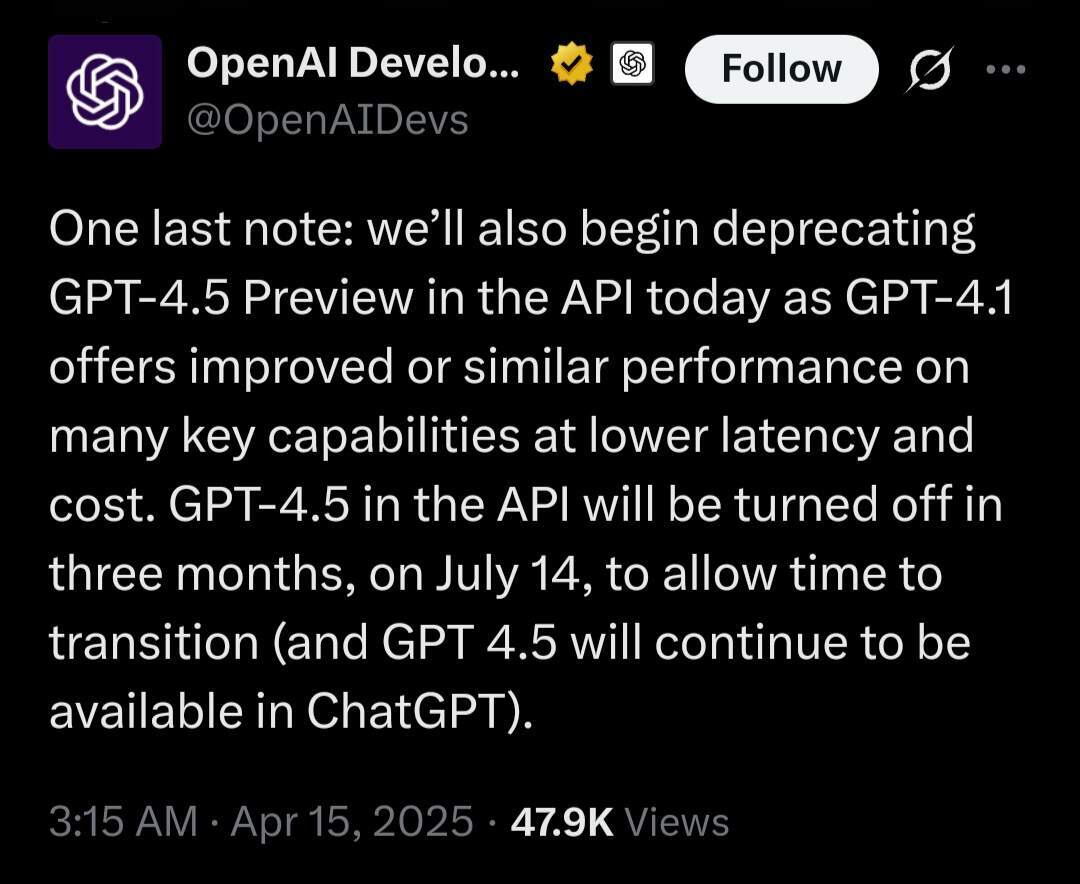
OpenAI 同时宣布,计划在 7 月 14 日之前从 API 访问中淘汰 GPT-4.5。该公司称,GPT-4.1 能够以大幅降低的成本提供“相当或更优的性能”。有网友表示,在 SimpleQA 基准测试中,GPT-4.5 仍然比 GPT-4.1 好得多。
但有不少网友都在调侃 OpenAI 命名模型的方式,“你们是怎么想出这些命名的呢?难道是掷骰子之类的方式吗?4.1 版本怎么能算是 4.5 版本的升级版?”“为什么不直接用 4.1 更新 4.5?对即将推出的版本 5 来说,这会比倒回去更新更合理。”