
DeepMind 的新项目是什么?
开发机器人技术的一大挑战,就在于必须投入大量精力来为每台机器人、每项任务和每种环境训练机器学习模型。近日,谷歌 DeepMind 团队及其他 33 个研究机构正共同发起新项目,旨在创建一套通用 AI 系统来应对这个挑战。据称该系统能够与不同类型的物理机器人协同运作,成功执行多种任务。
谷歌机器人部门高级软件工程师 Pannag Sanketi 在采访中表示,“我们观察到,机器人在专项领域表现极佳,但在通用领域却缺乏灵性。一般来讲,大家需要为每项任务、每台机器人和每种环境分别训练一套模型,从零开始调整每一个变量。”
为了克服这个问题,让机器人的训练和部署变得更加轻松、快捷,谷歌 DeepMind 在名为 Open X-Embodiment 的大型共享数据库项目中引入了两大关键组件:一套包含了 22 种机器人类型数据的数据集,外加一系列能够跨多种任务进行技能迁移的模型 RT-1-X(这是一个源自 RT-1 的机器人变压器模型)。为了开发 Open X-Embodiment 数据集,研发人员在超过 100 万个场景中展示了 500 多种技能和 150,000 项任务,因此,该数据集也是同类中最全面的机器人数据集。
此外,研究人员还在机器人实验室和不同类型的物理装置之上对模型进行了测试,并发现与传统机器人训练方法相比,新方案确实能取得更好的成绩。

来自 Open X-Embodiment 数据集的样本展示了 500 多种技能和 150,000 项任务。
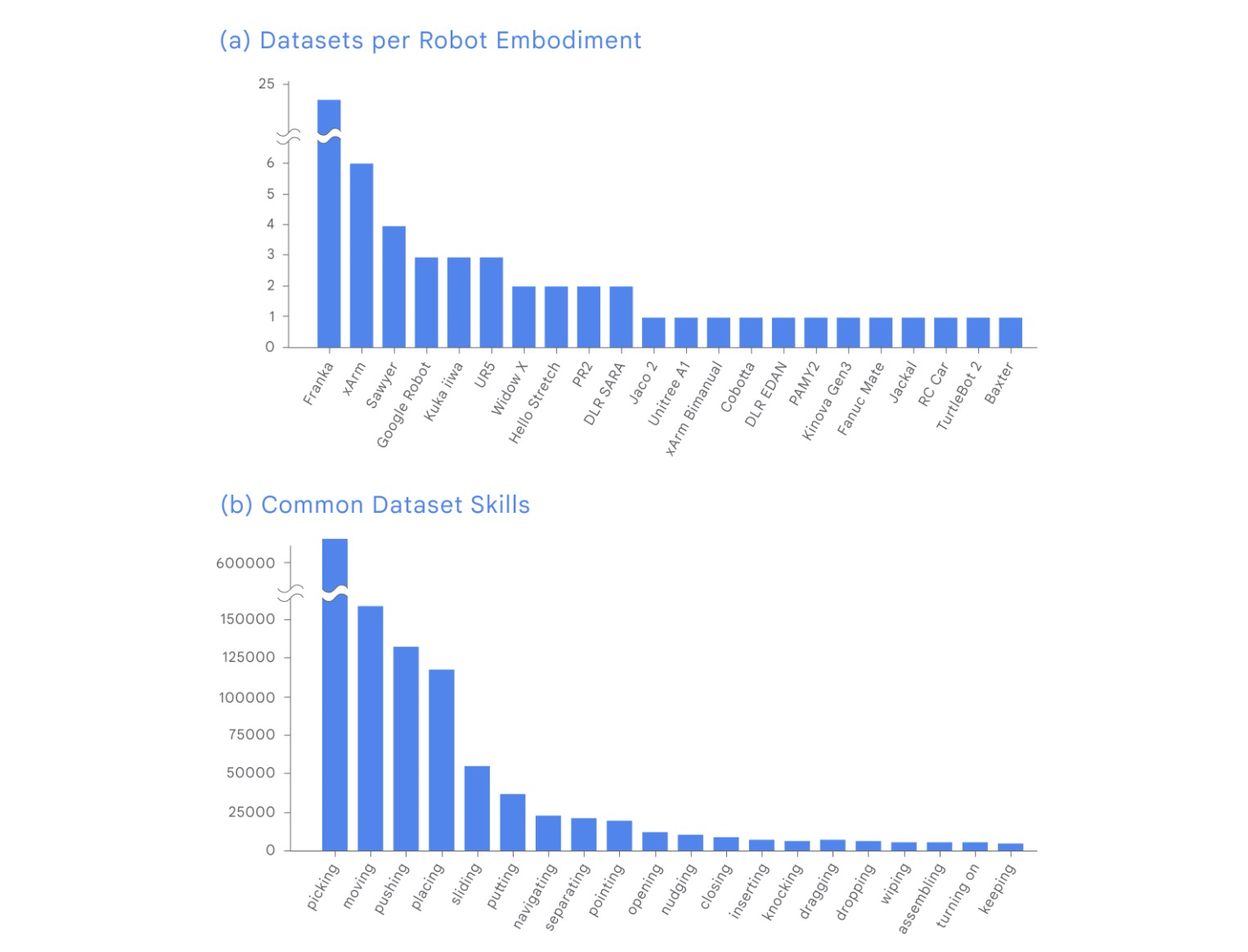
Open X-Embodiment 数据集结合了跨实施例、数据集和技能的数据。
结合机器人数据
通常来讲,不同类型的机器人往往拥有独特的传感器和执行器,所以需要配合专门的软件模型。这就类似于不同生物体的大脑和神经系统需要专门进化,从而适应该生物的身体结构与所处环境。
但 Open X-Embodiment 的诞生却出于这样一条先验性的假设:将来自不同机器人和任务的数据结合起来,就能创建一套优于专用模型的通用模型,足以驱动所有类型的机器人。这个概念在一定程度上受到大语言模型(LLM)的启发,即在使用大型通用数据集进行训练时,模型成果的匹配度甚至可以优于在特定数据集上训练的小型针对性模型。而研究人员惊喜地发现,此项原理果然也适用于机器人领域。
为了创建 Open X-Embodiment 数据集,研究团队收集了来自不同国家 20 个机构的 22 台机器人具身的真实数据。该数据集包含超 100 万种情节(所谓情节,是指机器人每次尝试执行任务时所采取的一系列动作),其中具体涉及 500 多种技能和 15 万个任务示例。
随附的各模型均基于 Transformer,一套在大语言模型中也得以应用的深度学习架构。RT-1-X 建立在 Robotics Transformer 1(简称 RT-1)之上,是一套适用于在真实环境下实现机器人技术规模化的多任务模型。RT-2-X 则建立在 RT-1 后继者 RT-2 的基础之上——RT-2 是一种视觉语言动作(VLA)模型,能够从机器人和网络数据中学习,并具备响应自然语言命令的能力。
研究人员在五所不同研究实验室的五台常用机器人上测试了 RT-1-X 对各类任务的执行能力。与针对这些机器人开发的专用模型相比,RT-1-X 在拾取和移动物体、以及开门等任务上的成功率高出 50%。该模型还能将技能迁移至多种不同环境,这也是在特定视觉场景下训练出的专用模型所做不到的。由此可见,由不同示例集训练而成的模型在大多数任务中都优于专用模型。论文还提到,此模型适用于从机械手臂到四足动物在内的多种机器人。
加州大学伯克利分校副教授、论文联合作者 Sergey Levine 写道,“对于任何曾有机器人研究经验的朋友来说,都能意识到这是多么了不起:这类模型「从来」就没能第一次就尝试成功,但这个模型却做到了。”
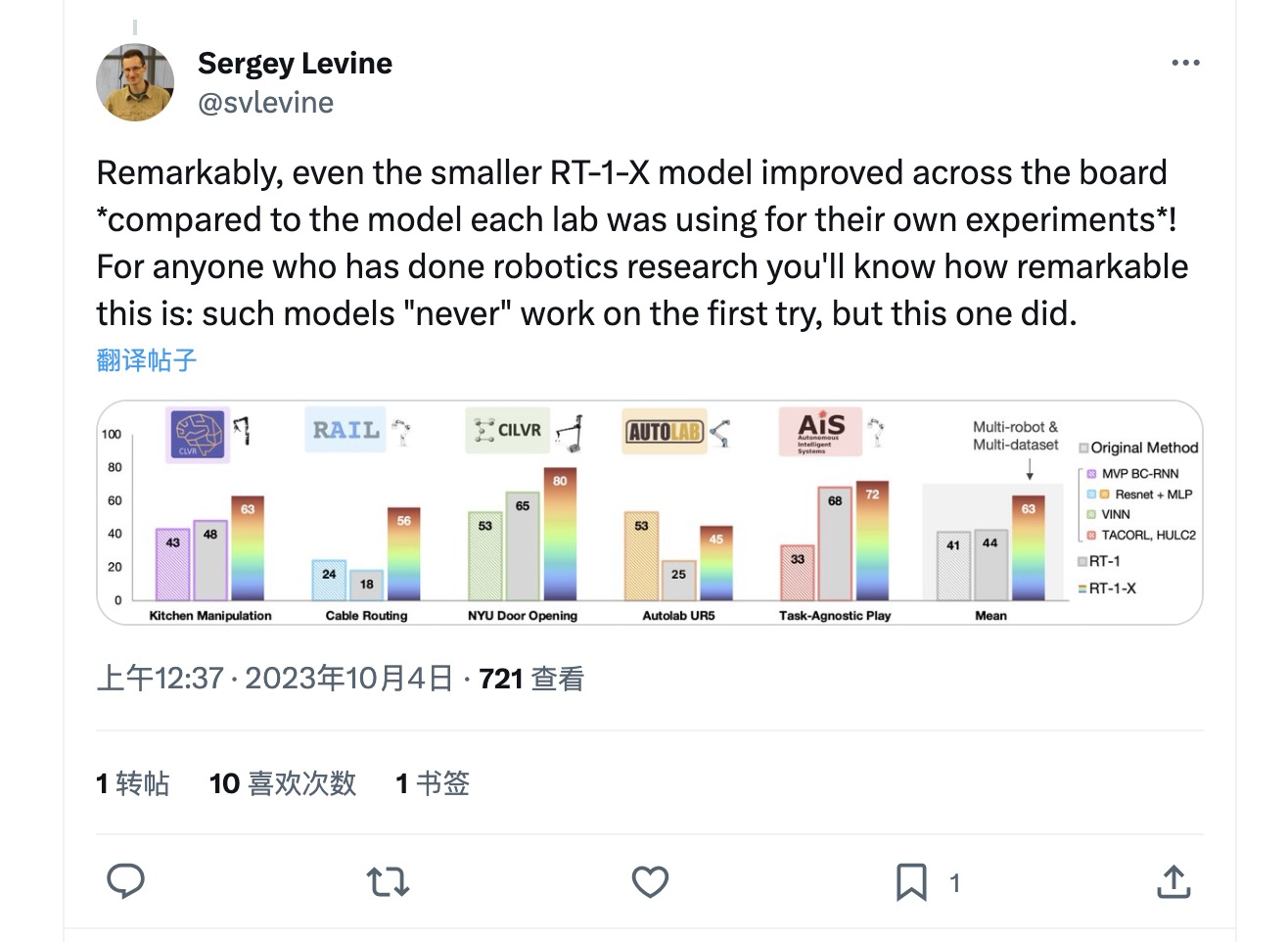
值得注意的是,即使是规模较小的 RT-1-X 模型,也实现了对各实验室内部专用模型的超越!对于任何曾有机器人研究经验的朋友来说,都能意识到这是多么了不起:这类模型“从来”就没能第一次就尝试成功,但这个模型却做到了。
在应急技能和处理训练数据集中未涉及的新任务方面,RT-2-X 的成功率可达 RT-2 的 3 倍。具体来讲,RT-2-X 在需要空间认知的任务上表现出更好的性能,例如理解“将苹果放到布旁边”和“将苹果放到布上”两种要求间的区别。
研究人员在 Open X 和 RT-X 的发布博文中写道,“我们的结果表明,与其他平台的数据进行联合训练之后,RT-2-X 获得了原始数据集中并不具备的额外技能,使其能够执行前所未见的新任务。”
步步迈向机器人研究的新未来
展望未来,科学家们正在考虑将这些进展与 DeepMind 开发的自我改进模型 RoboCat 的见解相结合,希望探索出新的研究方向。RoboCat 能够学会在不同机械臂上执行各种任务,然后自动设计出新的训练数据以提高自身性能。
Sanketi 认为,另一个潜在的研究方向,也可能是进一步研究不同数据集间的混合会如何影响跨机器人具身的能力泛化与改进效果。
该团队目前已经开源了 Open X-Embodiment 数据集和小型 RT-1-X 模型,但并未公开 RT-2-X 模型。
Sanketi 总结道,“我们相信,这些工具将改变机器人的训练方式,并加速该领域的研究进展。我们希望开源相关数据,并提供安全但受限的模型以减少障碍、加速研究。机器人技术的未来离不开机器人之间的相互学习,而这一切的前提,首先要求研究人员之间能够相互学习。”
参考链接:
https://venturebeat.com/ai/deepminds-remarkable-new-ai-controls-robots-of-all-kinds/
https://www.deepmind.com/blog/scaling-up-learning-across-many-different-robot-types




