
从迭代 Facebook 的 News Feed 排名算法到向用户提供与他们最相关的广告,Facebook 一直在探索新的特征来帮助改进我们的机器学习(ML)模型。每次我们添加新特征时都会引入一个具有挑战性的数据工程问题,从而需要我们从战略层面思考我们所做出的选择。更复杂的特征和更精巧的技术都需要额外的存储空间。即使在 Facebook 这么大体量的公司中,容量也不是无限的。如果任其发展,不加选择地接受所有特征,我们很快就会不堪重负,模型迭代速度和运行效率都会被拖累。
为了更好地理解这些特征与支持它们所需的基础设施容量之间的关系,我们可以将系统抽象成一个线性规划问题。这种方法可以让我们尽可能提升模型的性能、探索其性能表现对各种基础设施约束条件的敏感性,并研究不同服务之间的关系。这项工作是由我们工程团队的数据科学家们完成的,它展示了分析和数据科学在 ML 中的价值所在。
支持特征开发
不断引入能充分利用新数据来维护高性能模型的特征是非常重要的。新特征负责提供大部分的模型增量改进。这些 ML 模型对我们的广告投放系统是很有用的。它们共同运作,用于预测用户对广告采取特定行动的可能性。我们在努力不断改进这些模型,目标是让系统只投放与用户相关的广告。
随着我们的技术变得越来越复杂,我们开发了许多更复杂的特征,这些特征又需要更多的基础设施能力。根据其目的,一个特征利用多种不同的服务。某些特征具有更高的内存成本,而另一些特征则需要额外的 CPU 算力或占用更多存储空间。合理利用我们的基础设施来尽可能提升模型性能是非常重要的。我们必须巧妙地分配资源,并量化不同场景的权衡条件。
为了解决这些问题,我们将系统抽象成了一个线性规划问题,其目标是最大化我们模型的种种指标。我们使用这个框架来更好地理解各种特征和服务之间的交互。有了这些知识,我们就可以自动选择最佳特征,确定要投资的基础设施服务,并维护模型和服务的健康水平。
为我们的问题建立框架
在探讨我们的框架之前,我们首先引入一个模型问题。假设我们有多个特征,它们都占用了一定的空间(矩形的高度)并为我们的模型(青色方块)贡献了一定的增益,但我们无法在有限的容量中容纳所有这些特征。
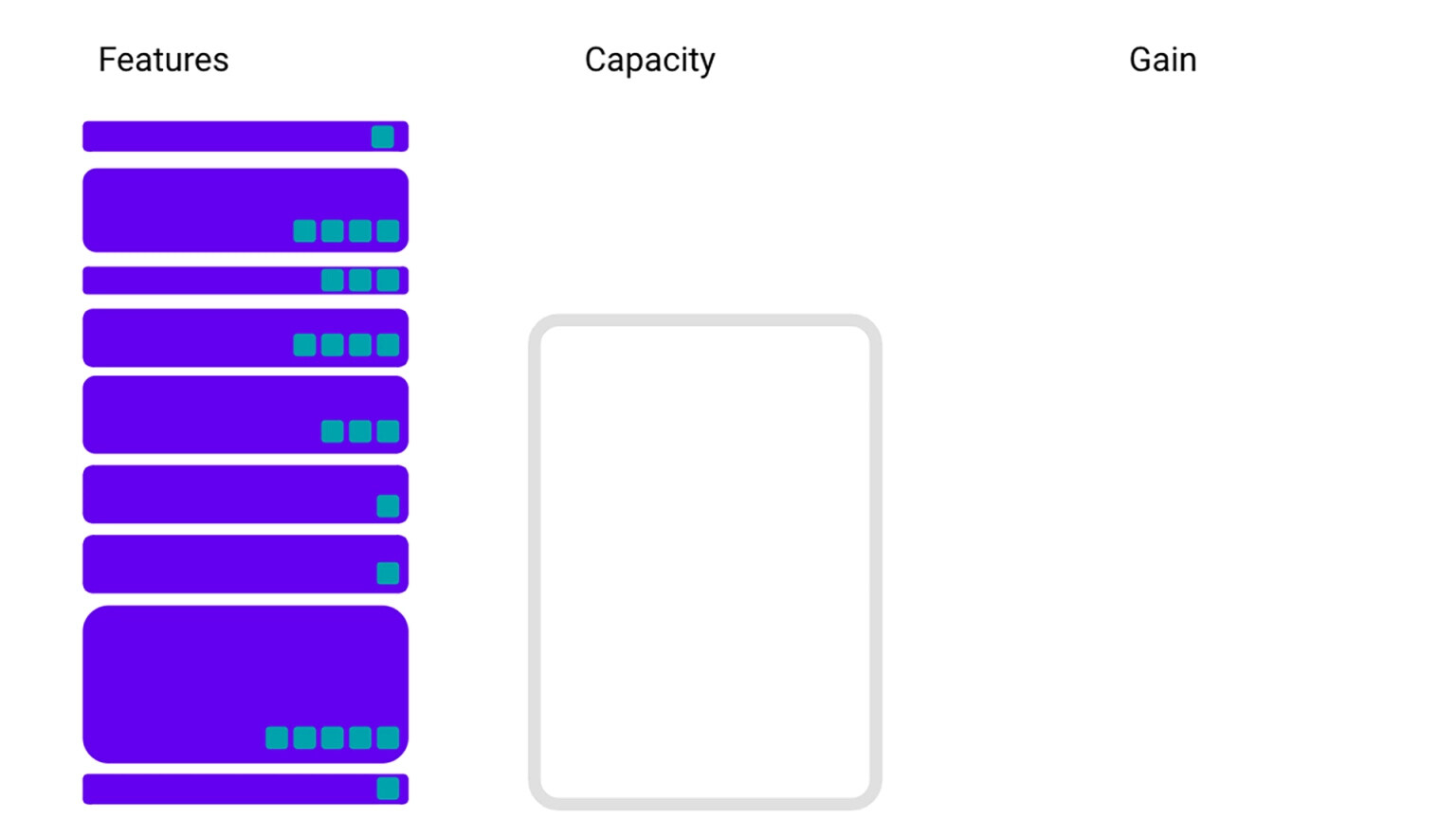
一个解决方案是简单地选择增益最大的特征(青色方块),直到容量不足为止。但如果你只是优先考虑增益,就可能无法充分利用你的资源。例如,选择了一个增益较大的大特征时,你可能会占用两个增益较小的小特征的空间。而这两个小特征加起来会比一个大特征更物有所值。
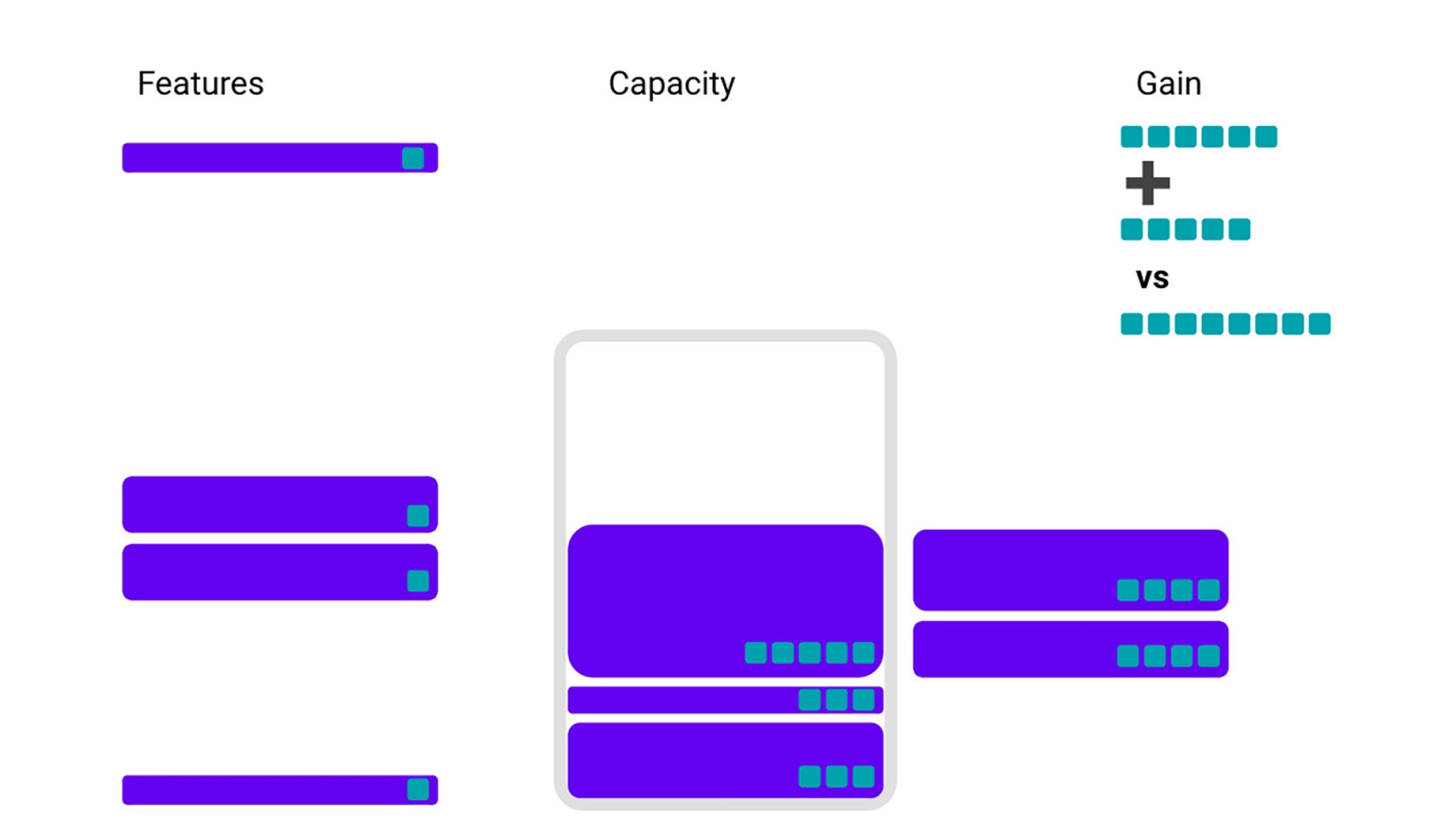
如果我们稍微多想一下,可以转而寻找能够为我们带来最大增益的特征——也就是每单位存储获得增益最大的特征。然而,如果我们只从这个角度来做出选择,我们最后可能会遗漏一些收益较低,但我们仍有空间容纳的特征。
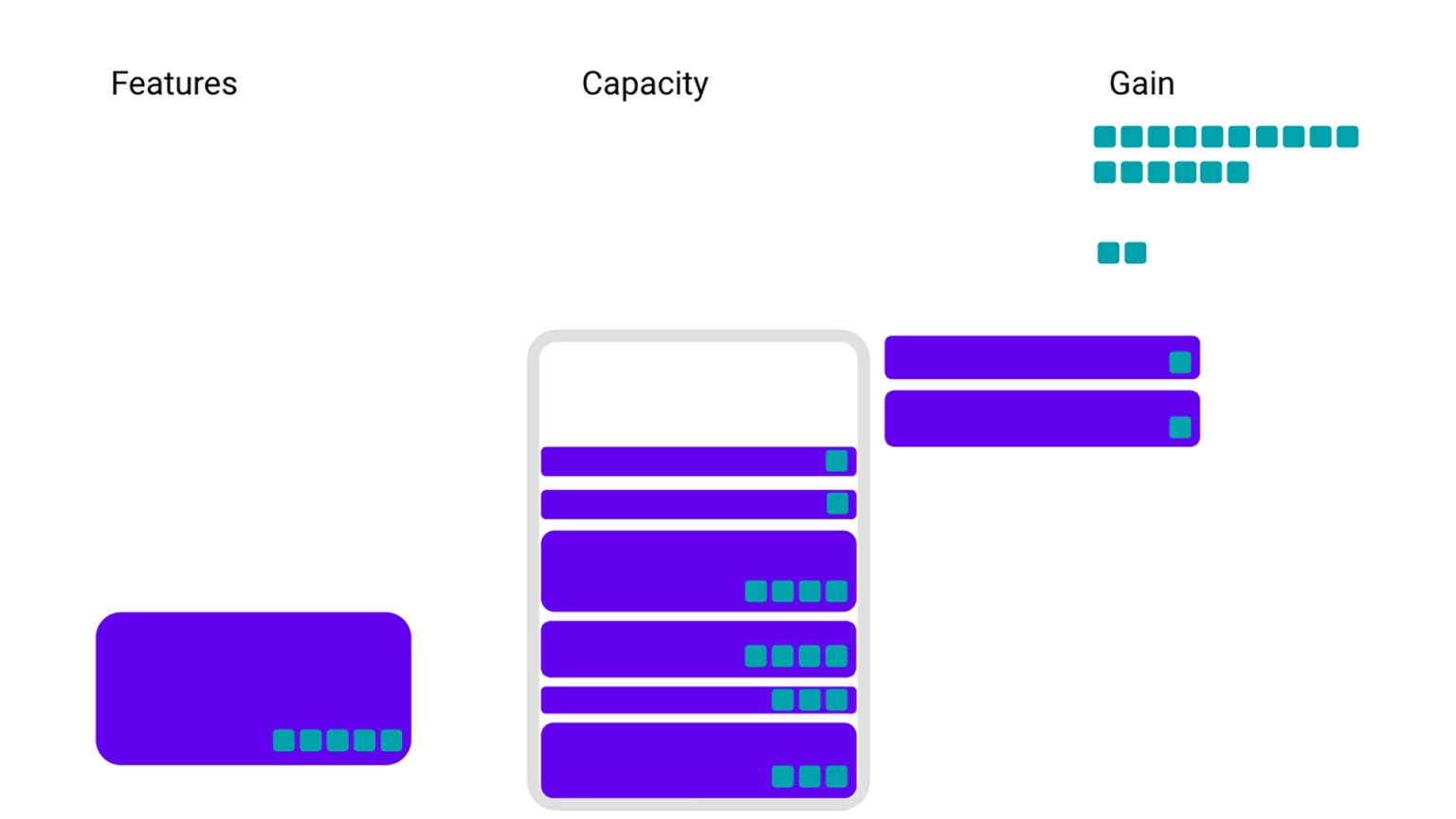
上面这些都是我们基础设施的非常简化的视图,但实际情况要复杂一些。例如,特征通常不会只占用一种资源,而是会需要很多资源——例如内存、CPU 或其他服务中的存储。我们可以添加一个服务 B,这样示例就变得稍复杂一些,其中橙色特征同时会占用服务 A 和服务 B 中的空间。
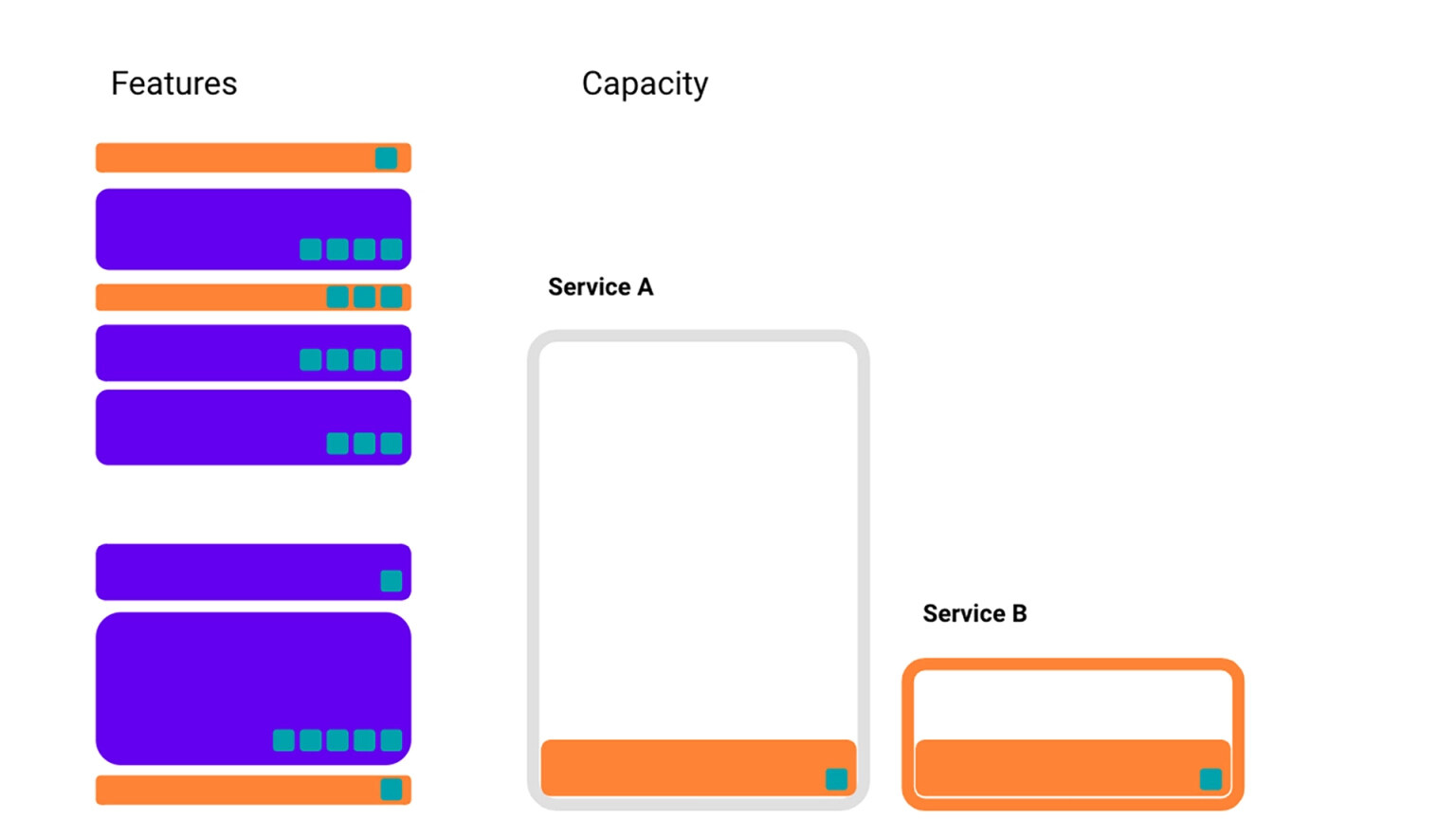
精挑细选要使用的特征并不是控制我们基础设施用量的唯一方法。我们还可以采用各种技术来提高特征存储的效率。这有时会带来成本,代价可能是特征自身或者是一个服务的容量。在这个示例中,假设我们可以将某些特征的存储成本(粉红色边框)减半,但代价是降低特征的增益,并使用服务 B 中的一些有限容量。
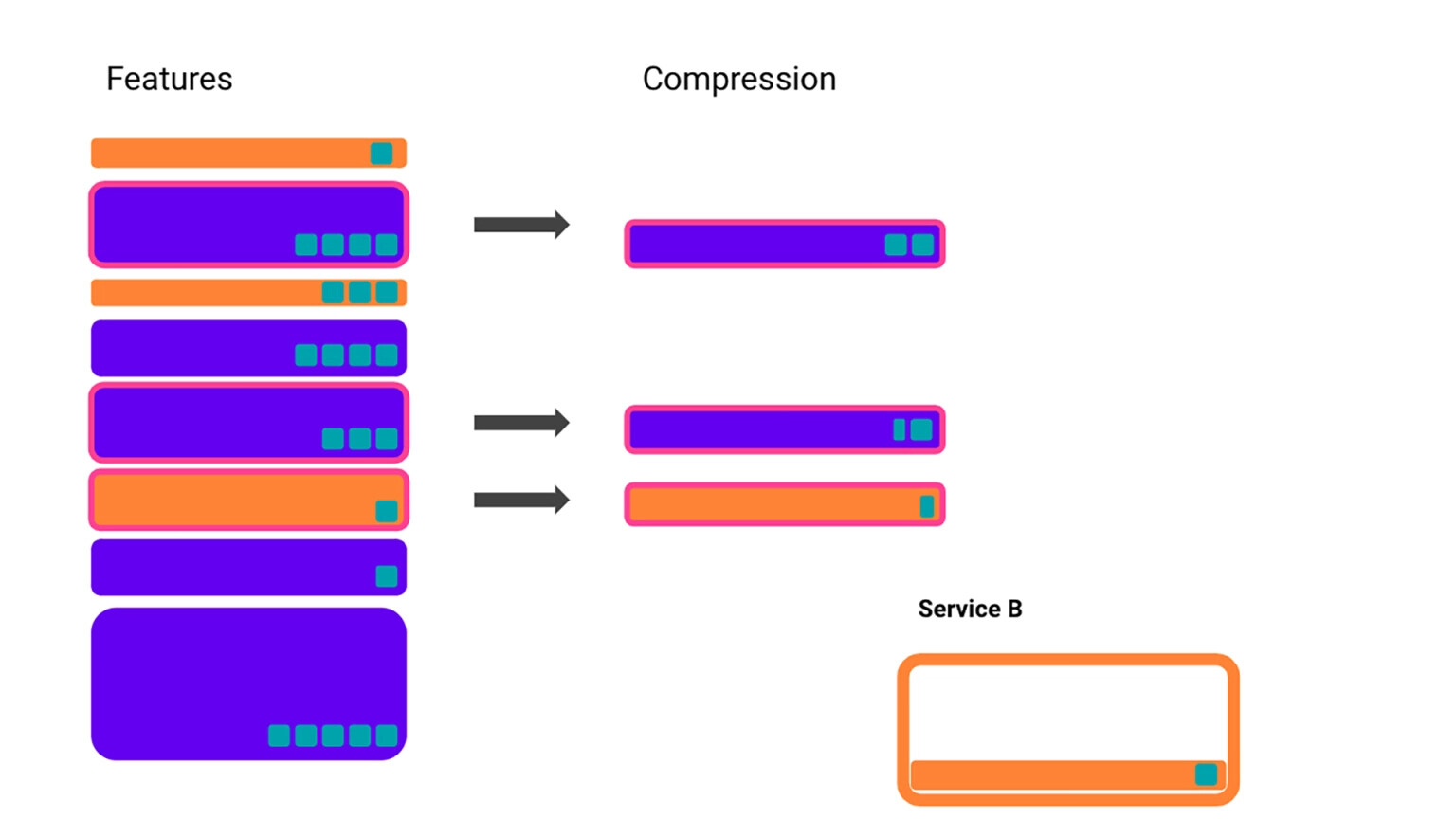
我们的示例就介绍到这里,但这足够讲清楚一般情况了——基础设施可以是一个复杂的、具有不同约束的互连系统。实际上,我们的能力并不是一成不变的。如果有必要,我们可以来回移动资源。特征也不是我们唯一在处理的事情。还有许多项目和工作流程也在争夺同样的资源。我们不仅需要选择让我们的收益最大化的特征,而且还要回答关于我们的系统如何响应变化的一些问题:
我们选择哪些特征来优化增益?
特征压缩是值得的吗?更重要的是,工程师花时间来实施它是否是值得的?
如果我们向服务 A 添加更多容量,增益会如何变化?
服务依赖项之间是如何交互的?如果我们增加服务 B 的容量,我们可以减少服务 A 的用量吗?
扩展问题
我们先退后一步,回顾一下模型问题的条件:
我们想要最大化我们的增益。
我们受限于服务 A 的容量。
我们还受限于服务 B 的容量,只有某些特征需要用到它。
某些特征可能会被压缩,但是:
它们会面临增益损失。
必须使用服务 B 的部分容量。
我们可以将所有这些约束表示为一个线性方程组。
令𝑥是一个 0 或 1 的向量,表示我们是否选择了特征;令𝑔是一个存储特征增益的向量。下标𝑓和𝑐表示我们是指定完整成本还是压缩特征。例如,𝑥𝑓表示我们选择包含完整的、未压缩的特征,而𝑔𝑐表示压缩特征的成本。
根据这些定义,我们的目标是最大化:
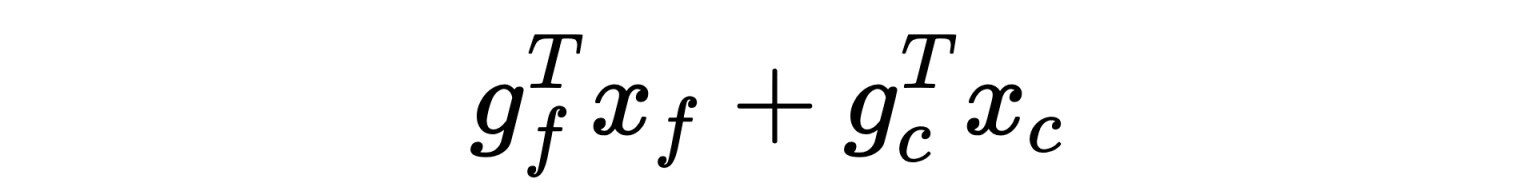
我们现在可以向方程添加约束来模拟我们的基础设施约束:
特征只能被选择并压缩、选择但不压缩或不被选择。我们不能选择相同特征的压缩版本和未压缩版本。
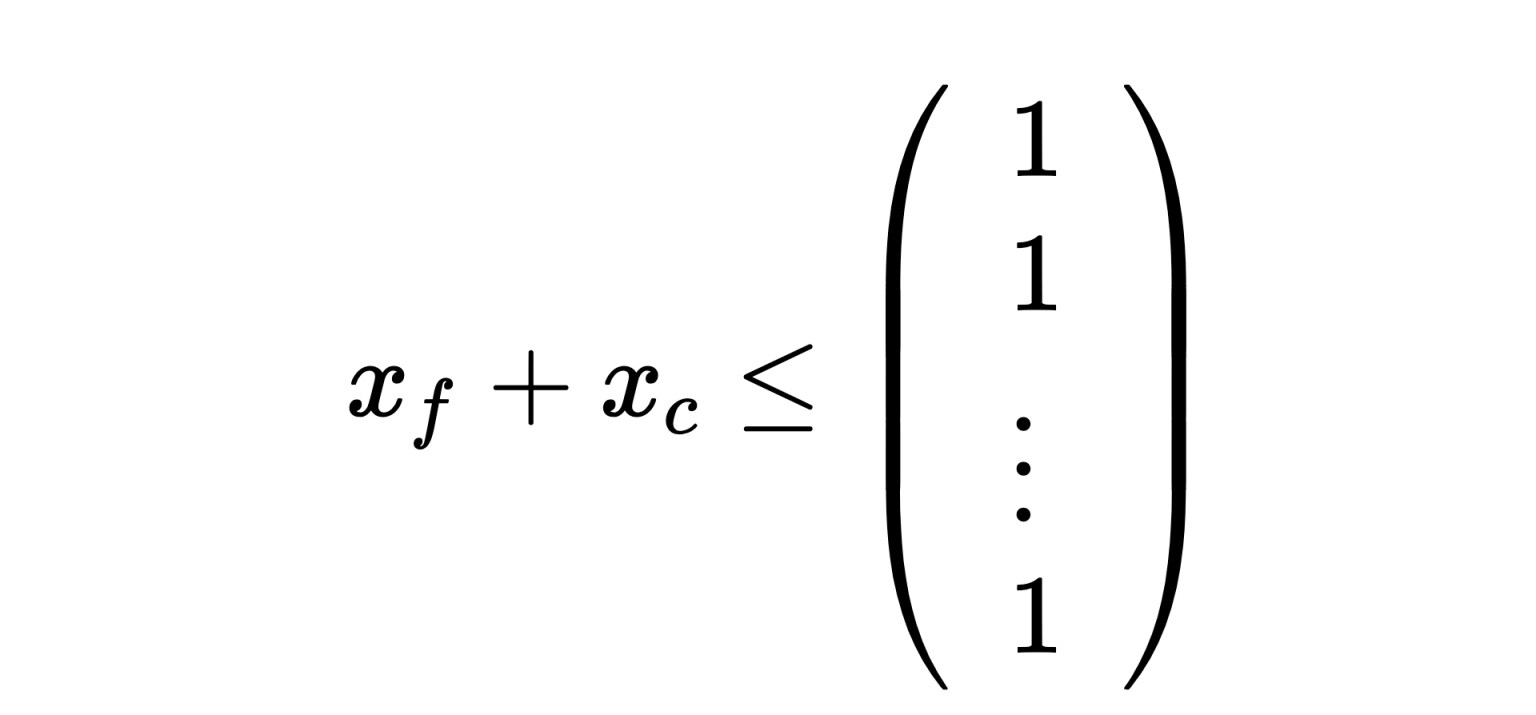
令𝑠是特征的存储成本,下标𝐴和𝐵分别代表服务 A 和 B。例如,𝑠𝐴𝑐表示服务 A 中压缩特征的存储成本。我们受到两个服务的容量约束。
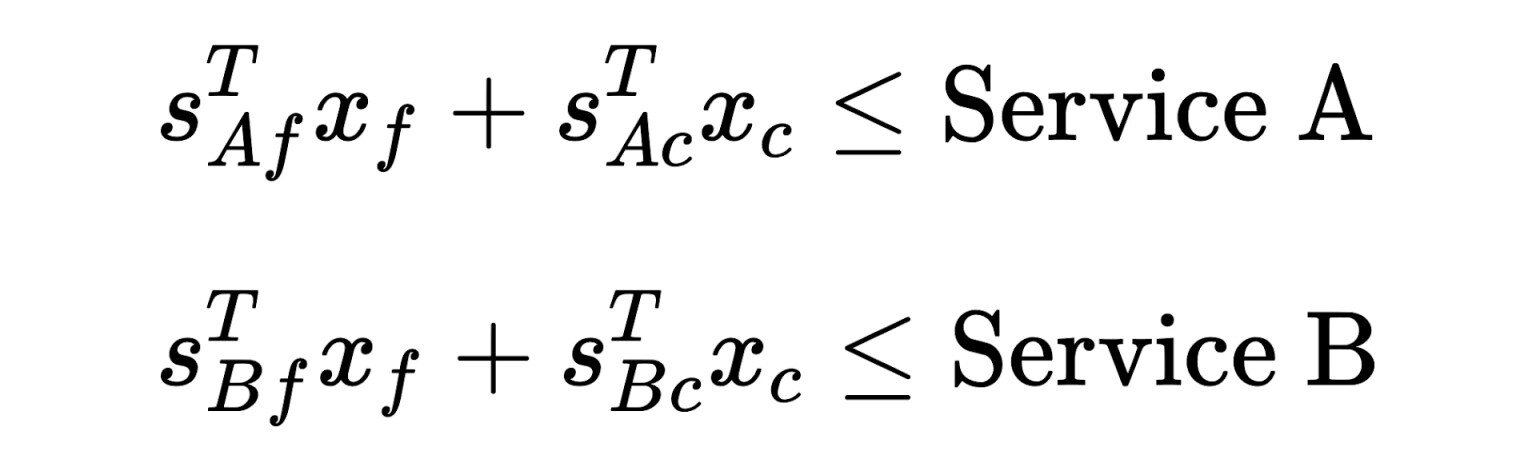
必须使用服务 B 的一些容量才能启用压缩。我们将其表示为必须选择的一些特征。
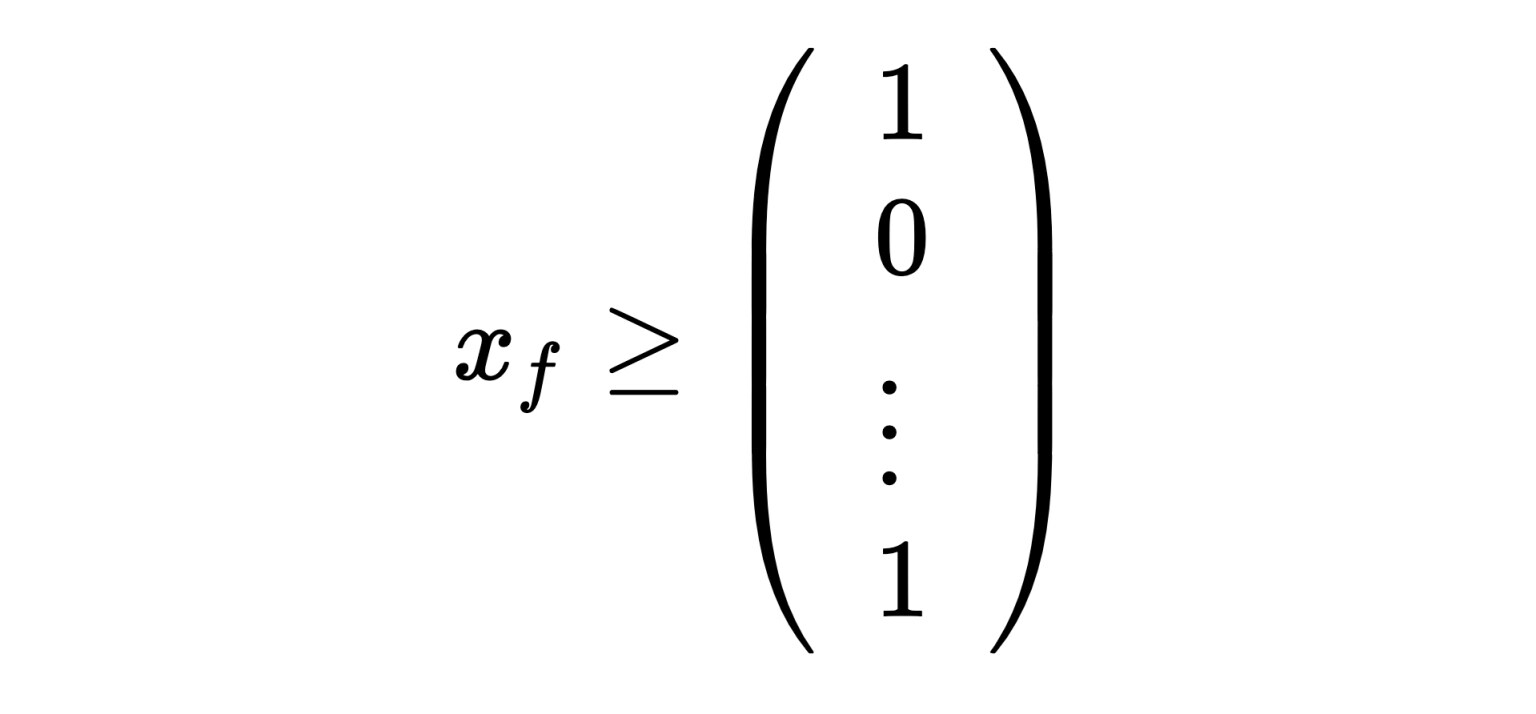
这样,我们现在已经在几个方程中完全定义了我们的问题,并且可以使用线性规划技术对它们求解。当然,由于我们希望可以自动化和提高生产力,因此方程组很容易转化为代码。对于本示例,我们使用优秀的 NumPy 和 CVXPY 包在 Python 中完成操作。
import cvxpy as cpimport numpy as npimport pandas as pd # Assuming data is a Pandas DataFrame that contains relevant feature datadata = pd.DataFrame(...)# These variables contain the maximum capacity of various servicesservice_a = ...service_b = ... selected_full_features = cp.Variable(data.shape[0], boolean=True)selected_compressed_features = cp.Variable(data.shape[0], boolean=True) # Maximize the feature gainfeature_gain = ( data.uncompressed_feature_gain.to_numpy() @ selected_full_features + data.compressed_feature_gain.to_numpy() @ selected_compressed_features) constraints = [ # 1. We should not select the compressed and uncompressed version # of the same feature selected_full_features + selected_compressed_features <= np.ones(data.shape[0]), # 2. Features are restricted by the maximum capacity of the services data.full_storage_cost.to_numpy() @ selected_full_features + data.compressed_storage_cost.to_numpy() @ selected_full_features <= service_a, data.full_memory_cost.to_numpy() @ selected_full_features + data.compressed_memory_cost.to_numpy() @ selected_compressed_features <= service_b, # 3. Some features must be selected to enable compression selected_full_features >= data.special_features.to_numpy(),]利用这个框架
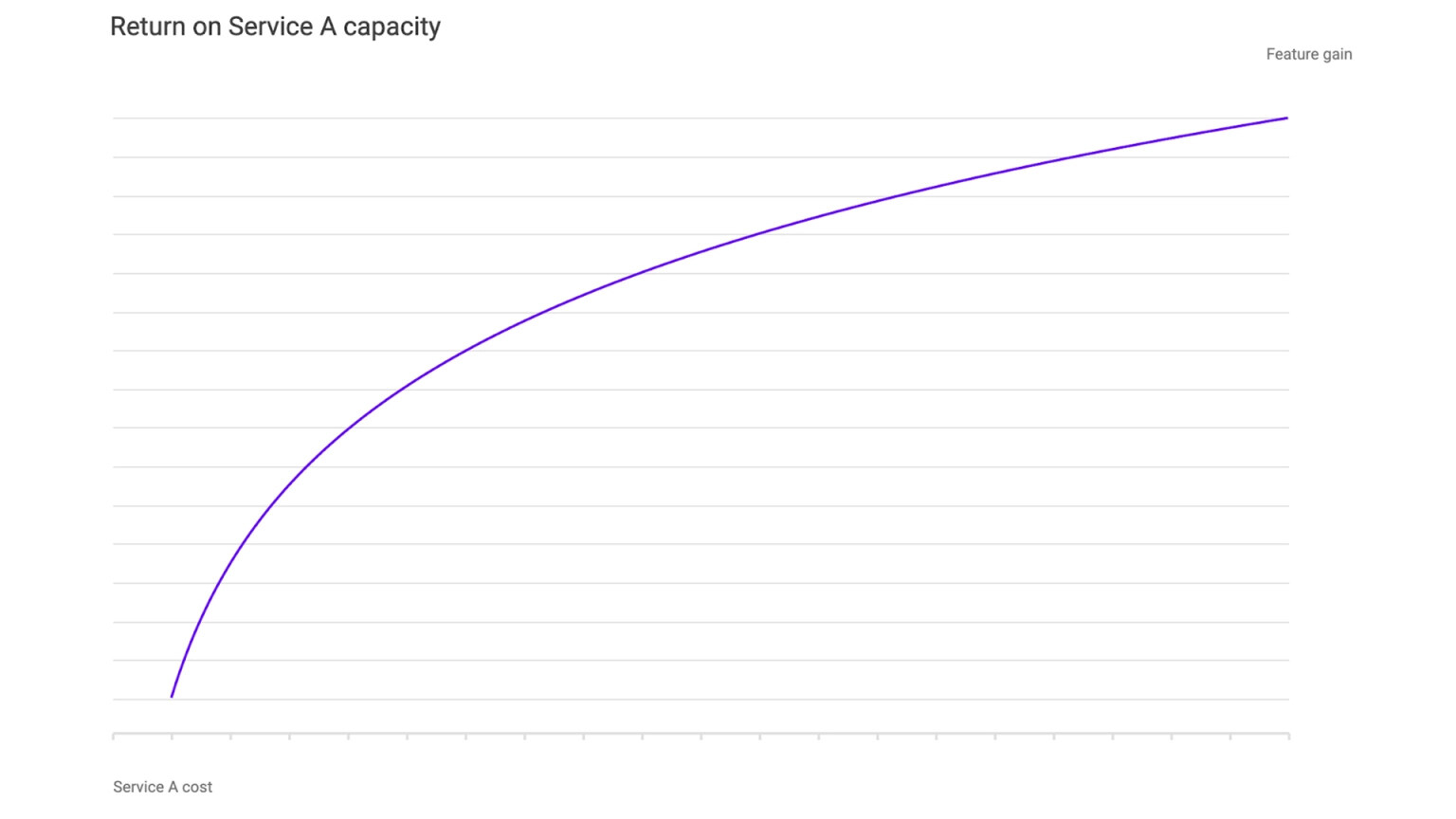
现在我们有了一个可以用来表达我们的问题和假设的框架。如果我们想了解服务 A 的容量增加如何转化为特征增益,我们可以在不同的服务 A 容量值下运行上面的优化问题并绘制增益图。这样我们就可以直接量化每次容量增加所能带来的回报。我们可以将其当作一种强信号,来指导我们未来应该投资哪些服务,并直接对比更多特征内存、计算或存储的投资回报。
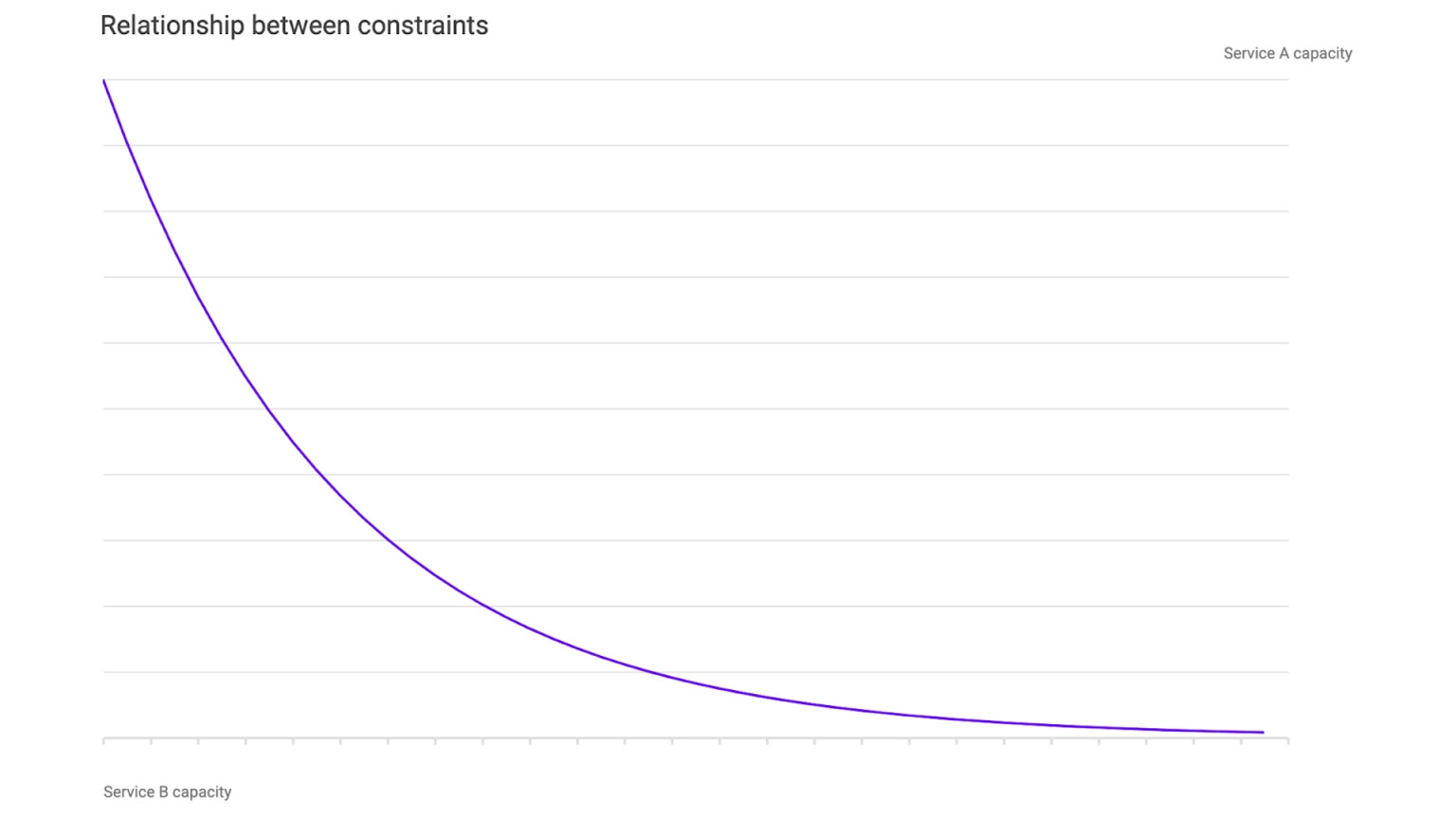
类似地,我们可以查看各个服务之间的关系。我们只需在保持增益不变的情况下改变服务 A 和 B 的容量。可以看到,随着服务 B 的容量增加,实现相同增益所需的服务 A 容量更少了。如果一项服务的压力比另一项服务大很多,则我们可以利用这一点见解。
使用线性规划作为自动化决策的框架
以前,特征批准是一个手动过程,团队需要花费宝贵的时间来计算我们可以支持多少特征,并分析增加服务容量能带来的投资回报。在像 Facebook 这样的公司中——我们有很多不断迭代的模型——这种方法是无法扩展的。将我们的服务构建为一个线性方程系统后,我们得以将一个复杂的互连系统简化为一种易于沟通的基本关系组合。由此以来,我们可以在部署特征和投资基础设施时做出更明智的决策。
原文链接:https://engineering.fb.com/2021/07/29/data-infrastructure/linear-programming/




