
eBPF(extended Berkeley Packet Filter) 是一种可以在 Linux 内核中运行用户编写的程序,而不需要修改内核代码或加载内核模块的技术。简单说,eBPF 让 Linux 内核变得可编程化了。本文整理自龙蜥大讲堂第 57 期,浪潮信息 SE 王传国从原理上分析了 eBPF 的加载工作过程,解释了它如何保证系统运行稳定以及它能加速网络的原因。
1. eBPF 加载过程
我们知道,一般 eBPF 的加载过程,首先是写 C 代码,然后用 llvm lang 编译成 ELF 文件,接着用 libelf 对 ELF 文件进行解析,解析之后按照 libbpf 所需要的格式进行数据的整理、组织,再通过 BPF 的系统调用,可以将这些数据都加载到内核里面,包括程序翻译出来的 eBPF 指令集。
在内核里面有校验器负责对程序进行校验,有 JIT 对程序进行翻译解析。
1.1 重定位
BPF 基础设施提供了一组有限的“稳定接口”, 使用 convert_ctx_access 对各种 CTX 进行转换,在内核版本升级时保证稳定。
CO-RE 核心思想就是采用(BTF)非硬编码的形式对成员在结构中的偏移位置进行描述,解决不同版本之间的差异。
需要重定位的元素:Map、函数调用、Helper 函数调用、字段、Extern 内核符号和 kconfig。
1.2 安全性检查:数据、指令、循环
数学计算除数不能为 0,指令调用范围[0, prog->len)深度优先遍历排除环。
1.3 eBPF 指令集

1.4 指针安全性检查

确定指针类型、范围纠正,识别不了的指针类型不允许引用。
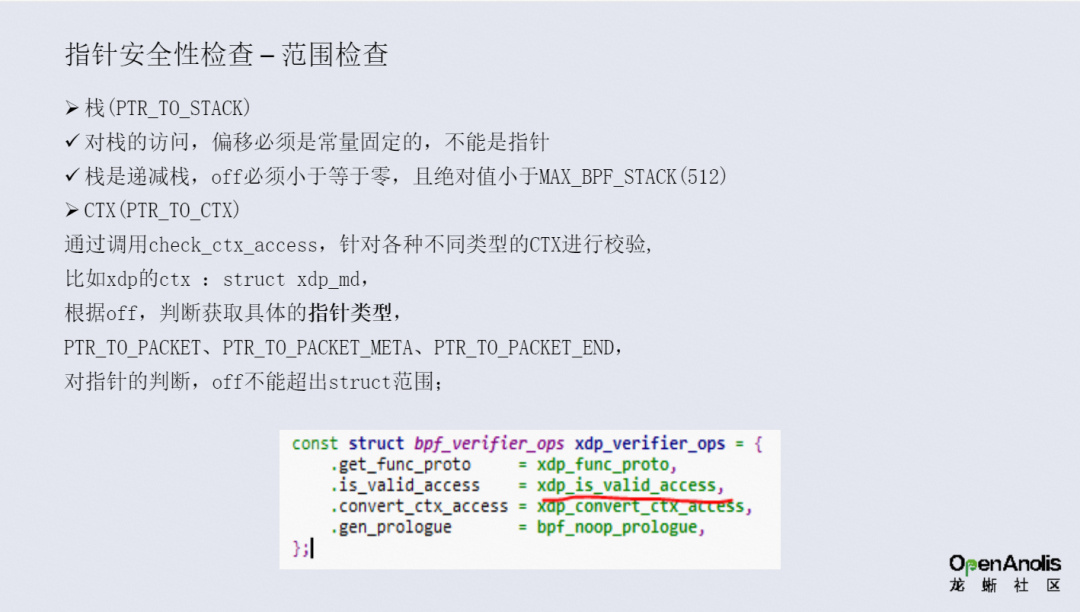
范围检查,不同的指针类型有不同的检查方法和范围。
2. eBPF 加速容器网络
主要涉及的 eBPF 程序类型:XDP、tc、sock_ops。
它们加速网络性能的基本原理都是把数据直接从一端(网口/socket)的发送队列传递到另一端的接收或发送队列,绕过不需要的网络协议栈。
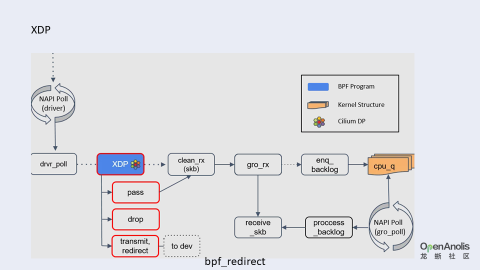
XDP 位于整个 Linux 内核网络软件栈的底部,还未生成 skb,能够非常早地识别并丢弃攻击报文,具有很高的性能;但是在虚拟机中有时候可能无法支持 XDP 程序的加载,例如虚拟机网卡的接收队列太少。
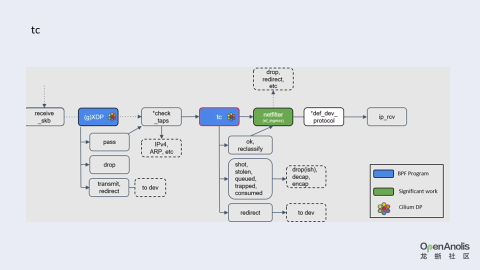
在 tc 功能的 sch_handle_ingress、sch_handle_egress 添加 hook 点,分别是 tc ingress 和 tc egress,没有 XDP 那么多要求,基本上所有的 OS 中都能使用,绕过 netfilter 等非必要的内核网络协议栈路径,能极大地提升网络性能,降低延迟。
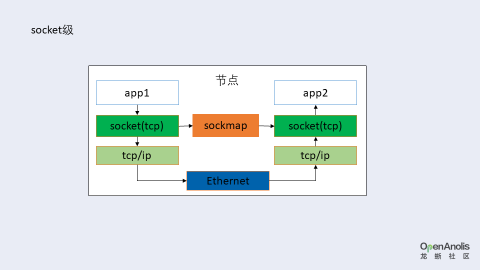
技术概述:把数据从一端 socket 发送队列直接发送到对端 socket 的接收队列或发送队列。
sockops:挂载到 cgroup,监控整个 cgroup 中所有 socket 的握手和挥手(主动|被动),记录 tcp 连接。
sockmap:存储数据特征与 socket 句柄的关系。写数据时执行 bpf_map_update,修改对应 socket 的 sendmsg 函数指针。
sk_msg:使用 sockmap 对数据进行 redirect 判定。

经过我们的测试,如果用 Cilium 替换 calico,用 TCP Throughput 模式测,那么 pod 间的通讯性能 tcp 吞吐量提升 58%、sockops 提升 153%、跨节点也能提升 24%。
如果用 TCP-RR 模式来测,那么相比 calico 同节点能提升 28%、sockops 提升 200.82%、跨节点提升 43%。
如果用 TCP_CRR 模式去测的话, calico 同节点能提升 40%、sockops 提升 35% 、跨节点提升 55%。
Cilium 在提升性能的时候,它对于 CPU 的占用降低了 10% 以上,因此我们测试的结果是 Cilium 的性能要明显优于使用 iptables 的 calico。所以说目前我们打算使用 Cilium 优化我们的容器网络。




