
Uber 为服务外部供应商及自托管的大语言模型而创建的统一平台,为便于内部的采用而选择了镜像 OpenAI 的 API。GenAI 网关提供了一致且高效的接口,可为多个领域内的 60 多个不同的 LLM 用例提供服务。
Uber 是大语言模型(LLM)最早的一批采用者之一, 公司内有多个团队专注于将以 AI 驱动的功能融入到流程自动化、客户支持和内容生成等各个领域之中。然而,不同的集成类型也导致了工作的重复和方法的不统一。为应对这些挑战,Uber 决定将大模型相关的服务集中都在 GenAI 网关这一项服务中。
Uber 高级软件工程师 Tse-Chi Wang 和 Roopansh Bansal 解释了创建网关的原因:
GenAI 网关是为简化团队在项目中集成大模型的工作流程,简易的载入流程减少了团队的工作量,为利用大语言模型强大的功能提供了清晰且直接的途径。此外,工程安全团队所提供的标准化审核流程也会根据 Uber 的数据标准审查用例,审核通过才会允许用例访问网关。
出于 LangChain 和 LlamaIndex 等开源库的广泛采用和高可用性,Uber 团队选择在网关中使用 OpenAI API,通过镜像这一知名的应用程序接口可以简化载入的流程,扩大网关的负载范围。
GenIAI 网关是一项用 Go 语言编写的、位于服务层中的服务,结合了外部(OpenAI、Vertex AI)、内部的大语言模型和许多通用的能力(如验证和账户管理、缓存、可观测性和监控)。
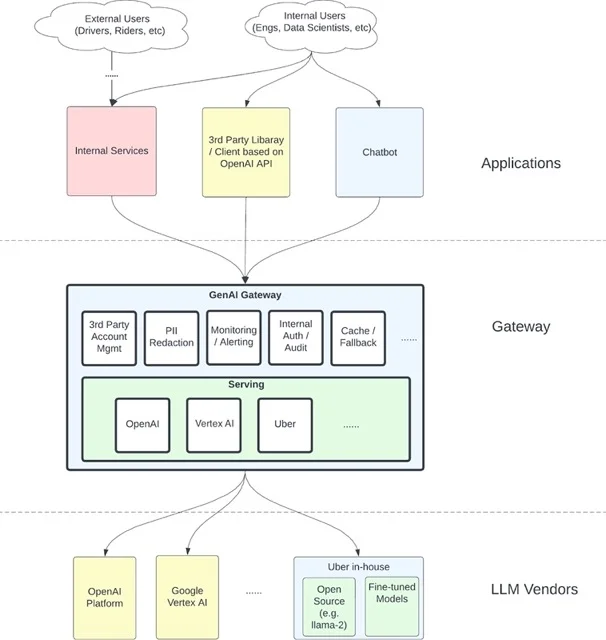
GenAI 网关的架构图(来源:Uber Engineering Blog)
GenAI 网关可减少个人身份信息(PII),这对大语言模型来说不仅重要也是一项挑战。Uber 要在将请求转发至第三方供应商之前确保其中的 PII 数据是经过匿名处理的,从而避免敏感数据的暴露风险。但从另一方面来说,PII 的减少可能会导致请求中丢失重要上下文信息,从而让大语言模型无法提供有用的回复。此外,数据的减少对大语言模型的缓存和检索增强生成(RAG)来说也是个问题。为应对这些挑战,Uber 团队鼓励使用 Uber 托管的大语言模型或是考虑依赖第三方供应商提供的安全保障。
作者在这里提供了一个案例研究,通过为客服提供聊天内容总结,减少处理用户查询的时间,从而提高客服的运营效率。在这一案例中,大语言模型所生成的总结有 97% 被客服认为有用,用户查询时间缩短了 6 秒。目前该方案每周生成约 2,000 万份总结,Uber 团队计划将其扩展到更多的地区和使用类型中。
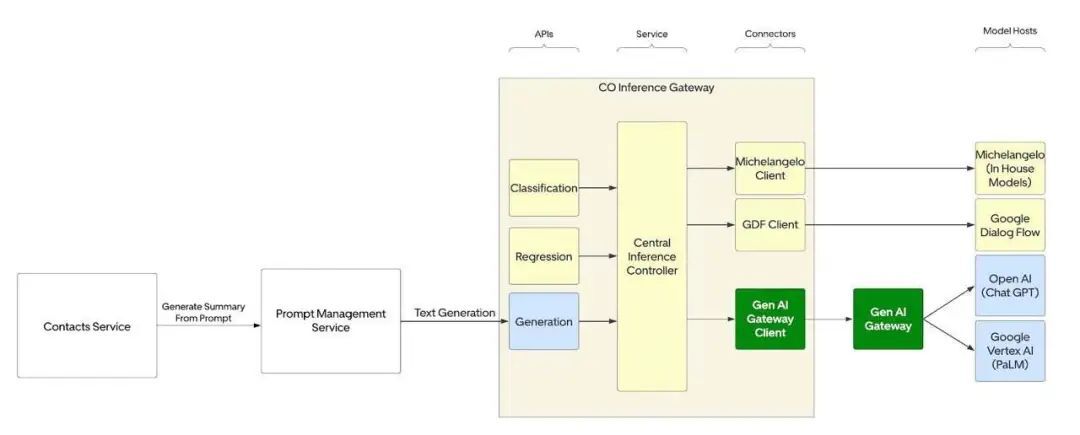
集成 GenAI 网关以支持特定用例(来源:Uber Engineering Blog)
Uber 团队从 GenAI 网关的开发和运行中学到了很多,并计划通过智能大模型缓存机制和更优秀的回滚逻辑、模型幻觉检测和安全策略维护进行改进。
查看英文原文:
https://www.infoq.com/news/2024/09/uber-genai-gateway-llm-openai/




