
一、背景
斗鱼是一家面向大众用户的在线直播平台,每天都有超大量的终端用户在使用斗鱼各客户端参与线上互动。伴随业务的迅猛发展,斗鱼需要对客户端采集到的性能数据进行统计和分析,开发出具有多维度分析图表和数据监控的 APM (Application Performance Monitoring,应用性能监控) 平台。
针对不同的客户端采集的不同数据,我们需要将各种维度之间相互组合并聚合,最终产出的数据变成指标在图表中展示。例如:对在时间、地域、网络环境、客户端以及 CDN 厂商等维度聚合下的各项指标情况进行多维度分析,包括客户端网络性能(包含完整请求耗时,请求耗时,响应耗时,DNS 耗时,TCP 耗时,TLS 耗时等等指标)各类错误时间段内的占比以及详细数量、状态码分布等等。图一和图二分别是两个示例:
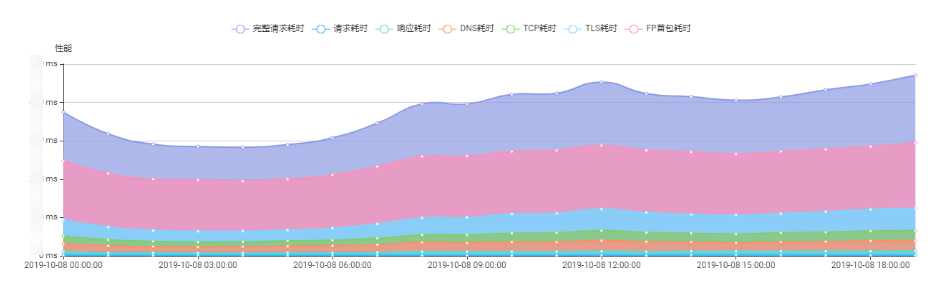
△ 图一
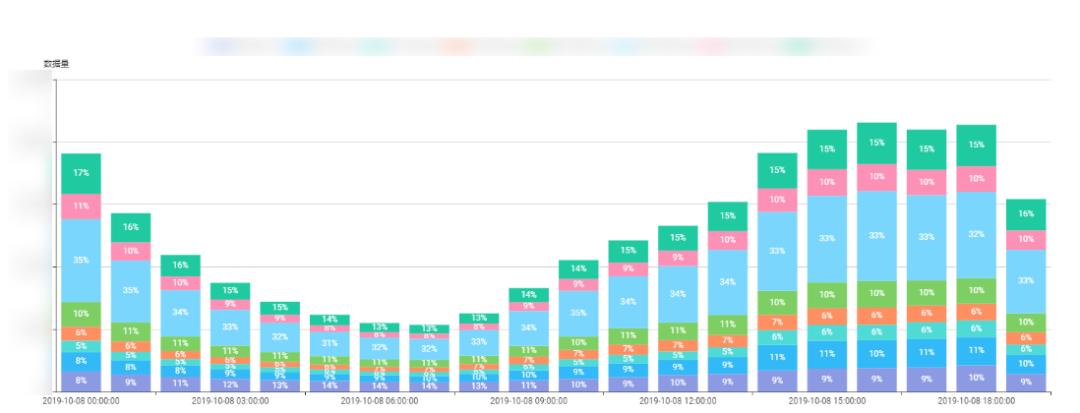
△ 图二
我们最初的 APM 平台采用了市面上非常流行的 Elasticsearch (简称 ES)实时聚合 实现。配合自研多数据源统一接口(EST 多数据源统一接口平台)框架,能够实现维度指标的自由组合查询。数据采用 storm 实时消费 kafka 写入 ES,做到了数据的实时展示。告警采用定时查询 ES 的方式。
不过运行一段时间后,我们发现基于 ES 的方案存在问题:采用 ES 实时聚合的方式,大多数时候对单个字段的聚合查询是非常快的,一旦遇到较为复杂的多维度组合查询并且聚合的数据量比较大(如数十亿),就可能会产生大量的分组,对 ES 的性能压力很大,查询时间很长(几十秒到数分钟)导致用户难以等待,还可能会遇到数据精度丢失的问题。因此为了支撑业务发展,考虑再三我们决定寻找替代方案,注意到 Apache Kylin 在大数据 OLAP 分析方面非常有优势,于是决定采用 Kylin 替换 Elasticsearch, 对斗鱼 APM 平台中存在的问题进行优化。不试不知道,一试吓一跳,效果还真的不错。
二、使用 Kylin 的挑战和解决方案
我们使用 Kylin 的过程也不是一帆风顺的,期间不断学习、摸索、踩坑,积累了一定的经验。这里分享一下我们遇到的一些挑战,以及找到的解决办法。
1. Kylin 集群的搭建
由于是第一次使用 Kylin,而 Kylin 依赖 Hadoop,其集群的搭建便是第一道难题。作为独立业务使用,为了保证业务的稳定性,不能依赖于公司的 Hadoop 主集群,所以需要单独搭建一整套供 Kylin 使用的运行环境。
Kylin 支持主流的 Hadoop 版本。图三是 Kylin 官网介绍的 Kylin 对各组件的版本依赖,可以看到还是比较容易满足的。

△ 图三
Hadoop 集群我们选择了主流的 Cloudera CDH 5.14.4,Kylin 2.4.1。采用 CM 的模式搭建,目前集群共 17 台机器,其中 CM 节点 3 台,角色包含 HDFS,YARN,Zookeeper,Hive,HBase,Kafka(主要是消费使用),Spark 2 等。其中 4 台机器上部署了 Kylin 服务,采用了 1 个 “all“ 节点,1 个 “job“ 节点,2 个 “query“ 节点的模式,确保了查询节点和任务节点都互有备份,满足服务的高可用。
2. 构建实时 Cube 中的问题
斗鱼客户端收集到的 APM 数据会先暂存于 Kafka 消息队列中,Kylin 支持直接从 Kafka topic 中摄入数据而不用先落 Hive,于是我们选择了这种直连 Kafka 的方式来构建实时 Cube。
1)Kafka 数据格式要求
Kylin 的实时 Cube 需要配置基于 Kafka topic 的 Streaming Table (将 Kafka topic 映射成一张普通表)。这一步不同于基于 Hive 的数据表(Kylin 可以直接从 Hive metastore 获取表的字段信息),需要管理员进行一定的手工配置,才能将 Kafka 中的 JSON 消息映射成表格中的行。这一步对 Kafka 中的数据格式和字段有一定的要求,起初因为不了解这些要求,我们配置的 Cube 在构建时经常失败,只有少数 Cube 构建成功。也有的 Cube 很多次都构建成功,但偶尔会有失败。针对这些问题我们进行了一系列的排查和改进。
a. 由于我们原始数据在 kafka 中的存放格式为数组格式(JSON 字符串),所以在创建 Streaming Table 的时候会遇到下面的问题:
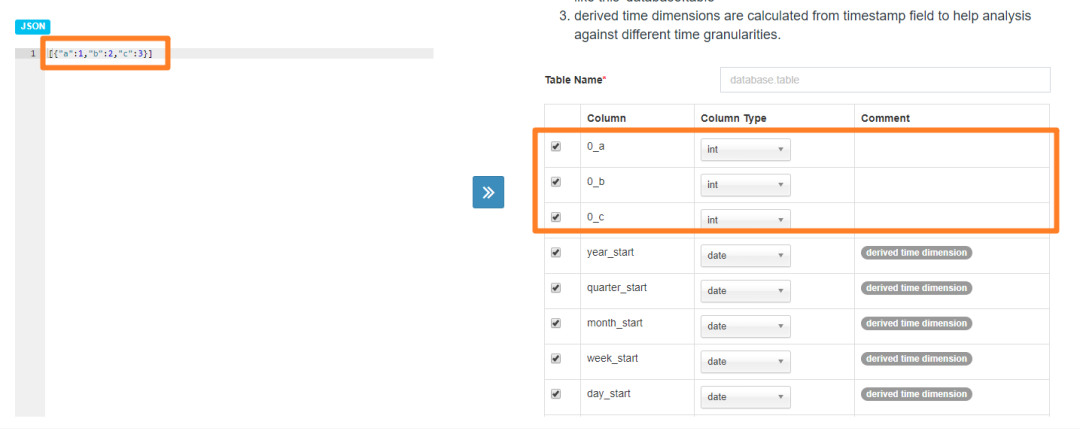
Kylin 会将数组中识别的字段默认加上数组下标,例如图中的 0a,0b 等,与我们的预期不符,所以需要对数组数据进行拆分。也就是说,Kylin 期望一条消息就是一个 JSON 对象(而非数组)。
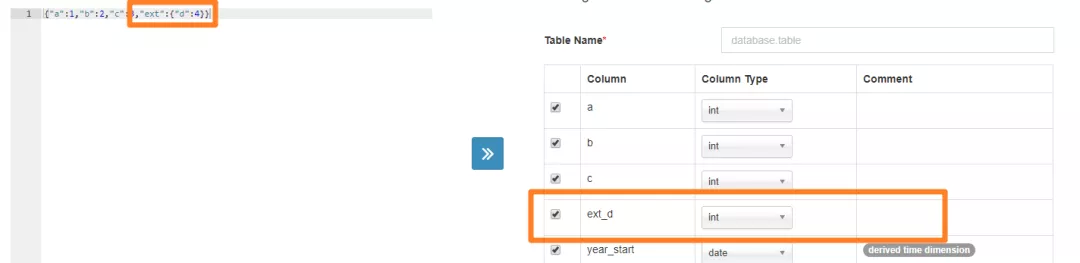
b. 我们原始数据中还有嵌套的对象类型的字段,这种类型在 Kylin Streaming Table 识别的时候也可能会有问题,同样需要规整。如 Kylin 会把嵌套格式如 "{A: {B: value}}" 识别为 A_B 的字段,如下图,所以使用起来同样也可以,这个根据业务的不同可以自由选择,我们采用了将嵌套字段铺平来规避后面可能出现的问题。
c. 这个是比较难发现的一个问题,就是在设计好 Cube 之后,有时会有 Cube 构建失败的情况,经过排查之后发现,是由于公司业务数据来源的特殊性(来自于客户端上报),所以可能会出现 Kafka 中字段不一致的情况。一旦出现极少数字段不一样的数据混在 Kafka 中,便极有可能让这一次的 Cube 构建失败。
基于以上几点,我们总结,Kylin 在接入 Kafka 实时数据构建之前,一定要做好数据清洗和规整,这也是我们前期耗费大量时间踩坑的代价。数据的清洗和规整我们采用的是流处理(Storm/Flink)对 Kafka 中的数据进行对应的处理,再写入一个新的 Kafka topic 中供 Kylin 消费。
2)任务的定时调度
Cube 的构建任务需要调用 API,如何定时消费 kafka 的数据进行构建,以及消费 kafka 的机制究竟如何。由于对 Kylin 理解的不够,一开始建出来的 Cube 消耗性能十分严重,需要对所建的 Cube 配合业务进行剪枝和优化。
构建实时 Cube 和构建基于 Hive 的离线 Cube 有很多不一样的地方,我们在使用和摸索的过程中踩了很多坑,也有了一定的经验。
由于是近实时 Cube 构建,需要每隔一小段时间就要构建一次,采用服务器中 Kylin 主节点上部署 Crontab-job 的模式来实现。
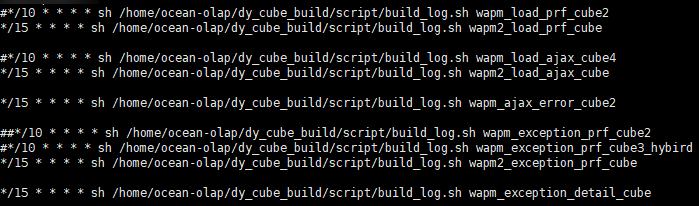
调度的时间间隔也经过了多次试验,调度的时间短了,上一个任务还没有执行完,下一个就开始了,容易产生堆积,在高峰时期容易造成滚雪球式的崩塌;调度的时间长了,一次处理的数据量就会特别大,导致任务执行的时间和消耗的资源也随之增长(Kylin 取 Kafka 的数据,是比较简单粗暴的从上一次调度记录的 offset 直接取到当前最新的 offset,所以间隔时间越长,数据量越多),这是一个需要平衡的事情。经过反复测试使用,以及官方相应的介绍下,我们发现任务执行时间在 10~20 分钟为最优解,当然根据数据量的不同会有不同的调整。
3)Kylin 的剪枝与优化
由于业务比较复杂,每个 Cube 的维度可能特别的多,随着维度数目的增加 Cuboid 的数量会爆炸式的增长。例如 WEB 端网络性能分析的 Cube 维度可能达到 47 个,如果采用全量构建,每一个可能情况都需要的话,最多可能构建 2 的 47 次方,也就是 1.4 * 10^14 种组合,这肯定是不能接受的。所以在 Cube 设计的时候一定要结合业务进行优化和剪枝。
首先是筛选,将原始数据中根据不同的业务,选择不同的字段进行设计,以 Ajax 性能分析为例,选择出需要使用的 25 种维度。(2^47 -> 2^25)
接下来是分组,将 25 种维度按照不同的场景进行分组,例如,地域相关的可以放在一起,浏览器相关的也能分为一组。我们将场景分为了 4 组,将指数增长拆分为多个维度组之和。好的分组可以有效的减少计算复杂度,但是没有设计好的分组,很可能会由于设计问题没有覆盖好各种场景,导致查询的时候需要二次聚合,导致查询的性能很差,这里需要重点注意。(2^25 -> 2^12 + 2^13 + 2^14 + 2^13)
然后是层级维度(Hierarchy Dimensions)、联合维度(Joint Dimensions)和必要维度(Mandatory Dimensions)的设置。这三个官网和网上都有大量的说明,这里不加赘述。最终实现 Kylin 的剪枝,来减少计算的成本。
最后是 Kylin 本身一系列的配置上的优化,这些针对各自业务和集群可以参照官方文档进行调参优化。

3. Kylin 集群相关优化
起初我们为 Kylin 集群申请的机器类型是计算密集型,没有足够的本地存储空间。Kylin 在运行的过程中磁盘经常满了,常常需要手动清理机器。同时在前期运行的过程中时不时会出现「Kylin 服务挂了(或者管理端登不上)」,「HBase 挂了」等等情况,针对遇到的这几个问题,我们有一些解决的措施。
1)磁盘不足。因为 Kylin 在构建 Cube 的时候,会产生大量的临时文件,而且其中有部分临时文件 Kylin 是不会主动删除的,所以机器经常会出现磁盘空间不足的问题(也跟我们计算型机器磁盘空间小有关)。
解决办法:采用定时自动清除,和手动调动 API 清除临时文件,扩容 2 台大容量机器调整 Reblance 比例(这才彻底解决这个问题)。
2)服务不稳定。刚开始的时候集群部分角色总是挂起(例如 HDFS、HBase 和 Kylin 等),排查发现是由于每台机器存在多个角色,角色分配的内存之和大于机器的可用内存,当构建任务多时,可能导致角色由于内存问题挂掉。
解决办法:对集群中各个角色重新分配,通过扩容可以解决一切资源问题。添加及时的监控,由于 Kylin 不在 CM 中管理,需要添加单独的监控来判断 Kylin 进程是否挂掉或者卡住,一旦发现需要重启 Kylin。要注意有 job 的节点重启时需要设置好 kafka 安装路径。
4. HBase 超时优化
Kylin 在后期维护中,经常会有任务由于 operationTimeout 导致任务失败。如图:
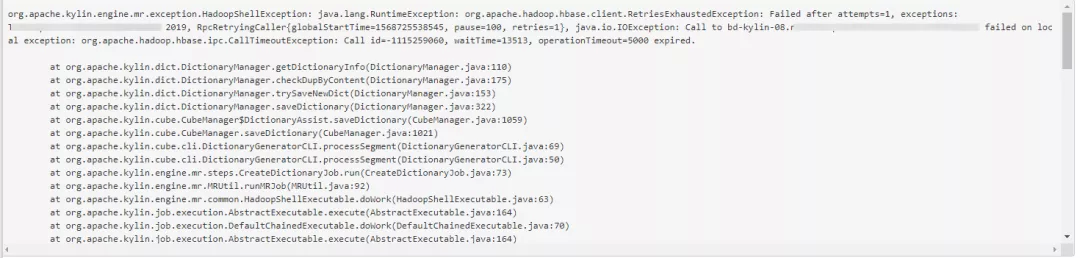
这个报错让 Cube 构建常常失败,且一旦构建失败超过一定的次数,该 Cube 就不会继续构建了,影响到了业务的使用,针对此问题也进行了相应的排查,发现是构建的时候,可能会由于 HBase 连接超时或者是连接数不够造成任务失败。需要在 CM 中调整 HBase 相关参数。包括调整 hbase.rpc.timeout 和 hbase.client.operation.timeout 到 50000 等(之前是 30000,可以根据业务不不同自行调整,如果还有超时可以优化或者继续调整)。
5. 已有 Cube 的修改
由于业务的迭代,新增了几个维度和指标需要增加在已存在的 Cube 上,又例如原先 Cube 设计上有一些不足需要修改。在这方面例如 DataSource 没有修改功能,新旧 Cube 如何切换,修改经常没有响应等等问题让我们十分为难。
已有 Cube 的修改是目前使用 Kylin 最为头疼的地方。虽然 Kylin 支持 Hybrid model 来支持一定程度的修改,但是在使用的过程中因为各种各样的原因,例如 Streaming Table 无法修改来新增字段等,还是未能修改成功。
目前采用的修改模式为,重新设计一整套从 DataSource 到 Model 再到 Cube,停止之前 Cube 的构建任务,开始新 Cube 的构建调度。使用修改我们 Java 代码的方式动态的选择查询新 Cube 还是旧 Cube,等到一定的时间周期之后再废弃旧 Cube。目前这种方式的弊端在于查询时间段包含新旧时,需要在程序中拼接数据,十分麻烦且会造成统计数据不准。所以在设计之初就要多考虑一下后面的扩展,可以先预留几个扩展字段。
效果对比
这里我们从多个角度对比一下几个方案的优缺点:

总结
基于以上的探索和使用,我们在使用 Kylin 之后,带来最大的改变就是在查询速度上的提升,给斗鱼 APM 系统的用户体验上带来了极大的改善:之前 ES 实时聚合需要将近 90 秒的查询,改为 Kylin 只需 2~3 秒即可展示,原来需要加载几分钟的仪表盘,现在仅用几秒就能全部加载完成,提高多达 30 倍。
在开发效率上,切换至 Kylin 在前期不熟悉的情况下的确走了一些弯路,踩了不少坑(跟数据质量、对 Kylin 原理的掌握等都有关)。但是后面在熟悉之后便可以有不逊色于 ES 的开发效率,用起来非常不错。
目前版本的 Kylin 也有一些不足,例如数据的时效性,因为 Kylin 2.x 的流数据源只能达到准实时(Near Real-time),准实时延迟通常在十几到几十分钟的,对 APM 系统中的实时告警模块还不能满足业务要求。所以目前实时告警这一块走的还是 ES,由于告警只需要对上个短暂周期(1~5 分钟)内的数据做聚合,数据量较小,ES 对此没有性能问题倒能承受。对于海量历史数据,通过 Kylin 来查询的效果更好。
新系统于 2018 年 11 月正式上线,目前已经稳定运行近一年。我们也注意到 Kylin 3.0 已经在实时统计上开始发力,能够做到 ES 这样的秒级延迟,我们会持续关注,希望 Kylin 可以发展的越来越好。
作者介绍:
戴天力,斗鱼高级大数据开发工程师,斗鱼 Kylin 团队主要负责人。
本文转载自公众号 apachekylin(ID:ApacheKylin)。
原文链接:




