
多年来,Reddit 已经发展成互联网世界一片广阔而多样化的土地。Reddit 的核心是众多社区组成的网络。从你时间线的内容到整个站点的无数讨论中反映的文化,社区犹如 Reddit 流动的血液,让它变成今天这个模样。Reddit 多年来的增长给一直以来为我们服务的数据处理和服务系统带来了极大压力。
本文介绍了我们构建适应 Reddit 规模系统的历程,并会谈到为什么这一历程是寻找更佳途径的必要之路。
需求
探索新去处从来不是什么舒舒服服就能做到的事情。无论是学习新主题,还是探索不一样的环境,我们都曾在某种程度上体验过那种喘不过气的感觉。这种感受让我们退缩,直到我们找到了合适的路径来帮助我们探索新的地域。
Reddit 具备的庞大规模和多样性,一开始可能很容易让人头晕。如果 Reddit 是一个城市,则 r/popular 页面就会是市政厅,你可以在其中看到那些吸引最多讨论的内容。这里是新用户首次体验 Reddit 的去处,也是我们的核心用户偶然发现新社区,进而添加到他们丰富收藏中的地方。reddit.com 上的 home feed 相当于一个社区公园,每位用户都可以根据他们订阅的内容获得个性化的推荐内容。对我们用户来说,这些 feed 是重要的指南,可帮助他们浏览 Reddit 并发现与他们的兴趣相关的内容。
挑战
在 2016 年,我们的机器学习模型开始向用户推荐与他们相似的人们所喜欢的讨论和内容。这促进了新内容和社区的发展,进而让人们意识到 Reddit 彼时还应该提供哪些事物。
随着更多多样化的内容被发布到平台上,我们一开始采用的方法开始不堪重负。今天,Reddit 上的内容在几分钟之内就会完全改变;而与某位用户相关的内容可能会根据他们最近访问的内容而改变。
Reddit 上的用户群体比以往任何时候都更加多样化。具有各种各样的背景、信仰和处境的人们每天都会访问 Reddit。此外,我们用户的兴趣和态度会随着时间而改变,并期望他们的 Reddit 体验能反映出这种变化。
我们的传统方法并没有提供个性化的 Reddit 体验以适应这种动态环境。考虑到正在发生的变化,我们意识到我们正在迅速接近一个转折点。
重构
要构建我们用户所喜欢的东西:
我们的 feed 需要在每个用户加载时为他们送上量身定制的内容
我们的系统需要适应用户兴趣、态度和消费方式的变化
我们必须迅速接收用户的反馈并改进底层系统
为此,我们将用户个性化实现细分为一系列有监督的学习子任务。这些子任务让我们的系统能学习一套通用的个性化策略。为帮助我们迭代地学习这一策略,我们建立了一个闭环系统(如下图所示),其中每个实验都基于先前的学习:
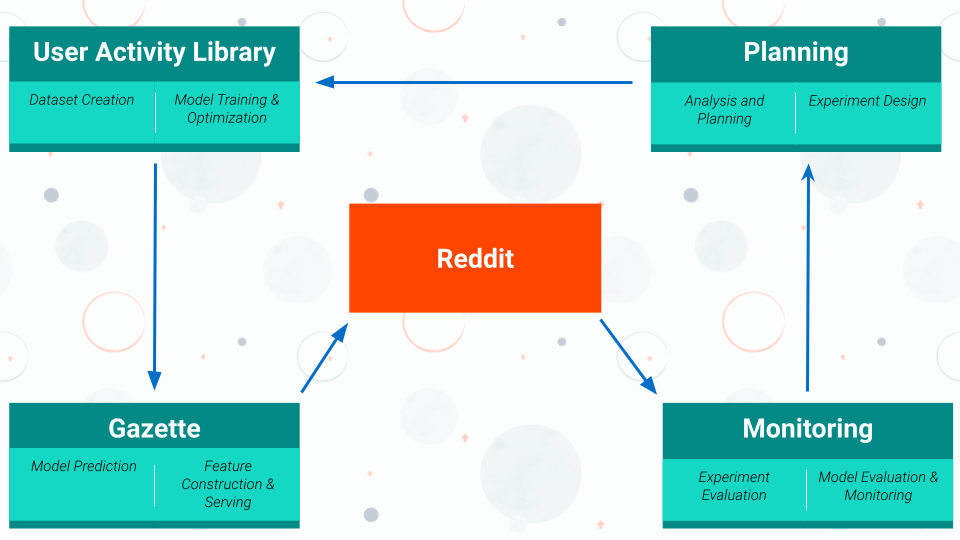
这一系统由四大关键组件组成。这些组件可以共同为每位 Reddit 用户生成个性化的 feed 体验。进一步来看每个组件的细节:
用户活动库(User Activity Library):该组件可帮助我们清理和构建数据集。这些数据集用于训练多任务深度神经网络模型,这些模型学习个性化实现所需的一个子任务集合
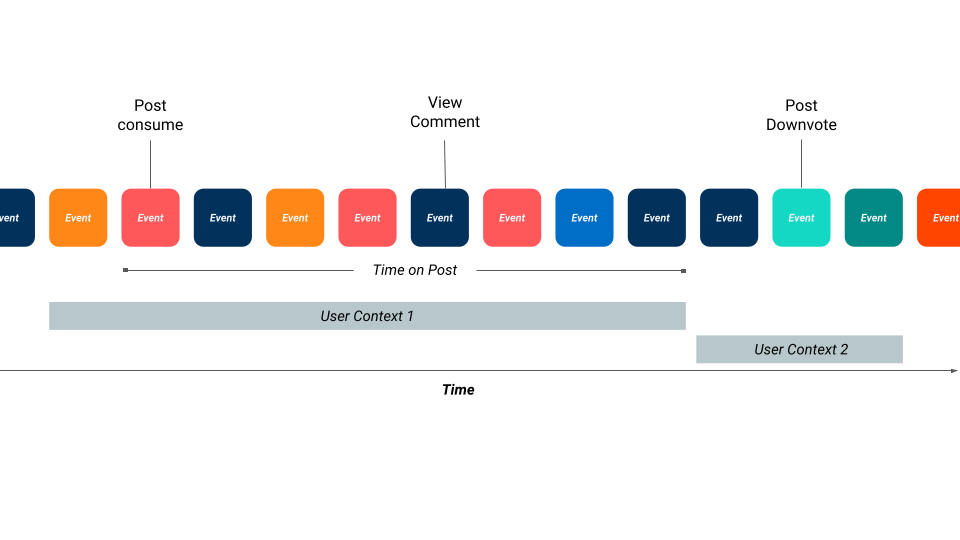
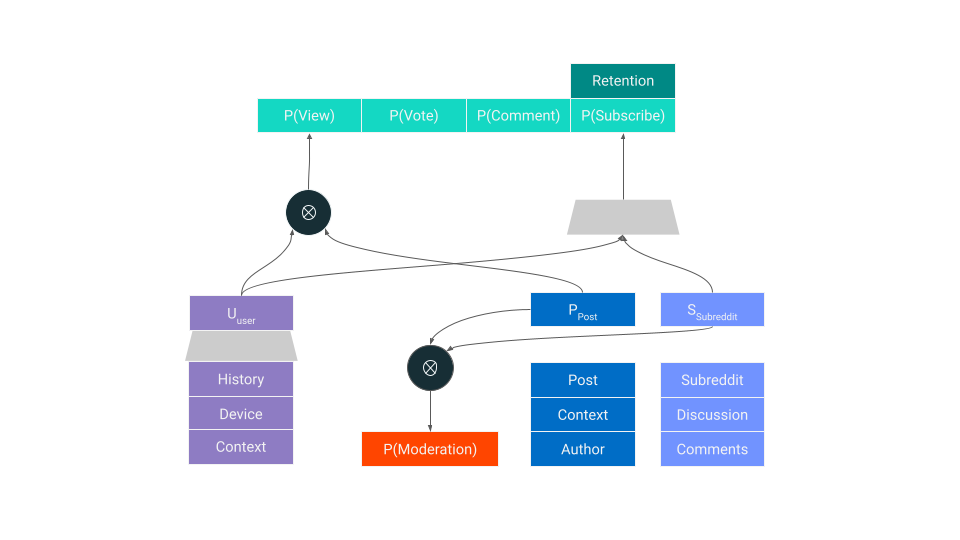
这些数据集包含一些在有限的时间范围内按每个用户、每个帖子汇总的特征(如上图所示)。在这些数据集上,训练的模型会同时嵌入用户、subreddit、帖子和用户上下文,从而使它们能针对特定情况预测用户操作。例如,对于每位 Reddit 用户,模型都可以分配一个用户对任意新帖子投票的概率,同时还可以分配一个用户订阅某个 subreddit 的概率,以及他们是否会对帖子发表评论的概率。这些概率可用于估计一些长期度量,例如留存率。
在 Reddit 中,多任务模型变得尤为重要。用户以多种方式与多种类型的内容互动,而互动水平(engagement)则告诉我们他们重视哪些内容和社区。这种类型的训练还能隐式地捕获了负面反馈——用户选择不参与的内容、投出的反对票或他们退订的社区。
我们使用简单的梯度下降式优化(像 TensorFlow 提供的那样)训练我们的多任务神经网络模型(如下所示的示例架构)。在 Reddit,我们将顺序蒙特卡洛算法放在最上面,以在给定子任务集合的情况下搜索模型拓扑。这让我们可以轻装上阵,并系统地探索搜索空间,以证明深度和多任务结构的相对价值。
Gazette——特征存储和模型预测引擎:鉴于时间限制和预测所需的数据规模,我们的特征存储和模型位于同一微服务中。该微服务负责协调在每个 GET 请求期间进行预测所涉及的各个步骤。
我们有一个系统,使 Reddit 的任何员工都可以轻松创建新的机器学习特征。这些特征被创建后,该系统将负责以高效的方式更新、存储这些特征并将其提供给我们的模型。
对于实时特征,一套基于 Kafka 管道和 Flink 流处理的事件处理系统直接实时消费每个关键事件来计算特征。与批量特征类似,我们的系统会以高效的方式将这些特征供模型使用。
该组件可保持 99.9%的正常运行时间,并以 p99/不足 100 毫秒的速度构建一条 feed。这意味着这套设计在我们扩展到处理每天万亿计的推荐时性能依旧稳定。
模型评估和监视:当你每天需要做出数十亿次预测时,出现错误是肯定的。鉴于 Reddit 的规模,一些显而易见的事情(记录每个预测、实时分析模型行为并确定漂移)变得非常具有挑战性。扩展系统的这个组件时我们需要考虑很多事情,并且正在积极研究中。
计划:在每个实验周期中,我们都在寻找改进方法,以让每个迭代都比过去更好。我们会查看来自模型的数据,以便更好地回答以下问题:
我们可以在模型中添加哪些新任务,以更好地了解用户策略?
我们可以在当前系统中添加或删除哪些新组件,以使当前系统更加成熟?
我们可以发起哪些新的实验,以便更多地了解我们的用户?
下一步计划
随着世界的不断变化,我们对 Reddit 平台做出了很多改进:
为每位用户提供更相关的内容。
加入可能会增强用户体验的实时更改。
为了提高迭代速度,我们改进了底层系统。
“演变(Evolve)”是 Reddit 所有员工推崇的一项核心价值。该系统不仅使我们能够应对平台不断增长的规模,而且能够以更快的速度尝试不同的方法。接下来的计划将涉及更大规模的实验,让我们可以更好地了解这片虚拟地域对我们的用户而言为什么如此特别。
我们相信我们只是迈出了第一步,而我们最重要的变革尚未到来。
原文链接:




