
当地时间 12 月 6 日,谷歌发布了自己“迄今为止功能最强、通用性最高”的 AI 模型 Gemini。
谷歌及 Alphabet CEO 桑达尔·皮查伊 (Sundar Pichai)表示,首个 Gemini 1.0 针对不同规模进行优化,具体分为 Ultra、Pro 和 Nano 三个版本。“这是 Gemini 时代的首批模型,也是我们今年早些时候重组 Google DeepMind 时所表达愿景的首个实现。此模型代表着谷歌作为一家企业,在 AI 新时代下所做出的最重要的科学与工程努力之一。”
但刚发布不久,科技专栏作家 Parmy Olson 指出,其中一个 AI 实时对人类的涂鸦和手势动作给出评论和吐槽的视频被曝出“不是实时或以语音方式进行的”。还有网友吐槽整个互动过程“特别慢,跟演示视频完全不同。”
这个视频主要是演示“多模态提示”(multimodal prompting),即为大模型提供不同模式的组合(在本例中为图像和文本),并让其通过预测接下来会发生什么来做出反应。
对此,Google DeepMind 研究与深度学习主管副总裁 Oriol Vinyals表示,“视频中的所有用户提示和输出都是真实的,只是为简洁起见进行了缩短剪辑。”但网友对此并不买账,认为谷歌在玩营销手段,误导大家。
在谷歌发布的一篇文章里,详细介绍了效果实现经过,可以看出是使用静态图片和多段提示词拼凑训练。
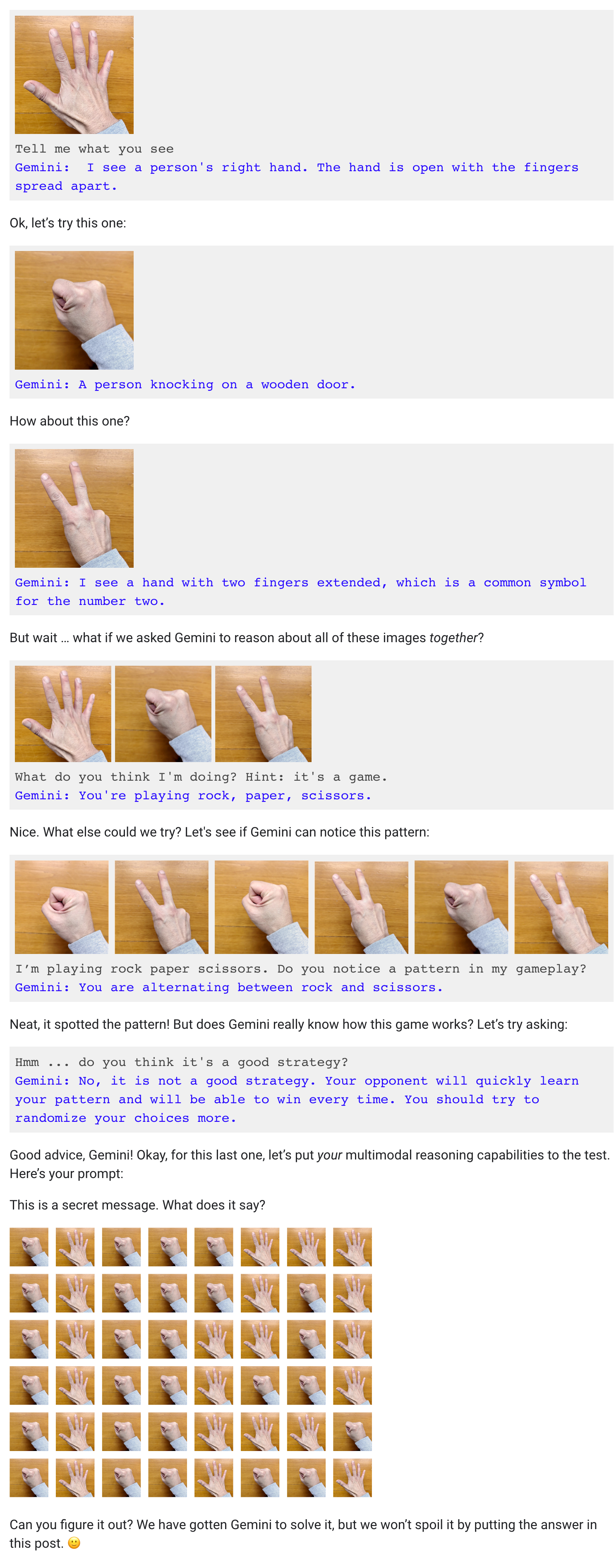
看看谷歌的测试
Gemini 被称为谷歌迄今为止最灵活的模型,能够从数据中心到移动设备实现高效运行,帮助开发人员与企业客户显著增强在利用 AI 进行构建和扩展时的操作方式。谷歌针对三种不同体量优化了 Gemini 1.0(首个正式模型版本),分别为:
Gemini Ultra — 最大、功能最强的模型,适用于高度复杂的任务。
Gemini Pro — 可处理各种任务类型的最佳模型。
Gemini Nano — 能够在多种设备上高效运行的任务处理模型。
值得注意是,本次尚未发布最强大的 Gemini Ultra,距离正式发布还需要几个月的时间。目前 Gemini Ultra 正在进行全面的信任与安全检查,包括由受信的外部合作方进行红队审查,并在广泛应用前通过微调和基于人类反馈的强化学习(RLHF)对其做进一步完善。
Gemini Pro 和 Gemini Nano 已分别集成到了聊天机器人 Bard 和智能手机 Pixel 8 Pro 上。此外,自 12 月 13 日开始,开发者和企业客户都可通过 Google AI Studio 或者 Google Cloud Vertex AI 中的 Gemini API 访问 Gemini Pro 模型。在未来几个月间,Gemini 将逐步登陆谷歌更多产品及服务,包括搜索、广告、Chrome 浏览器以及 Duet AI 等。
谷歌说得很厉害,那 Gemini 1.0 的实力到底如何?
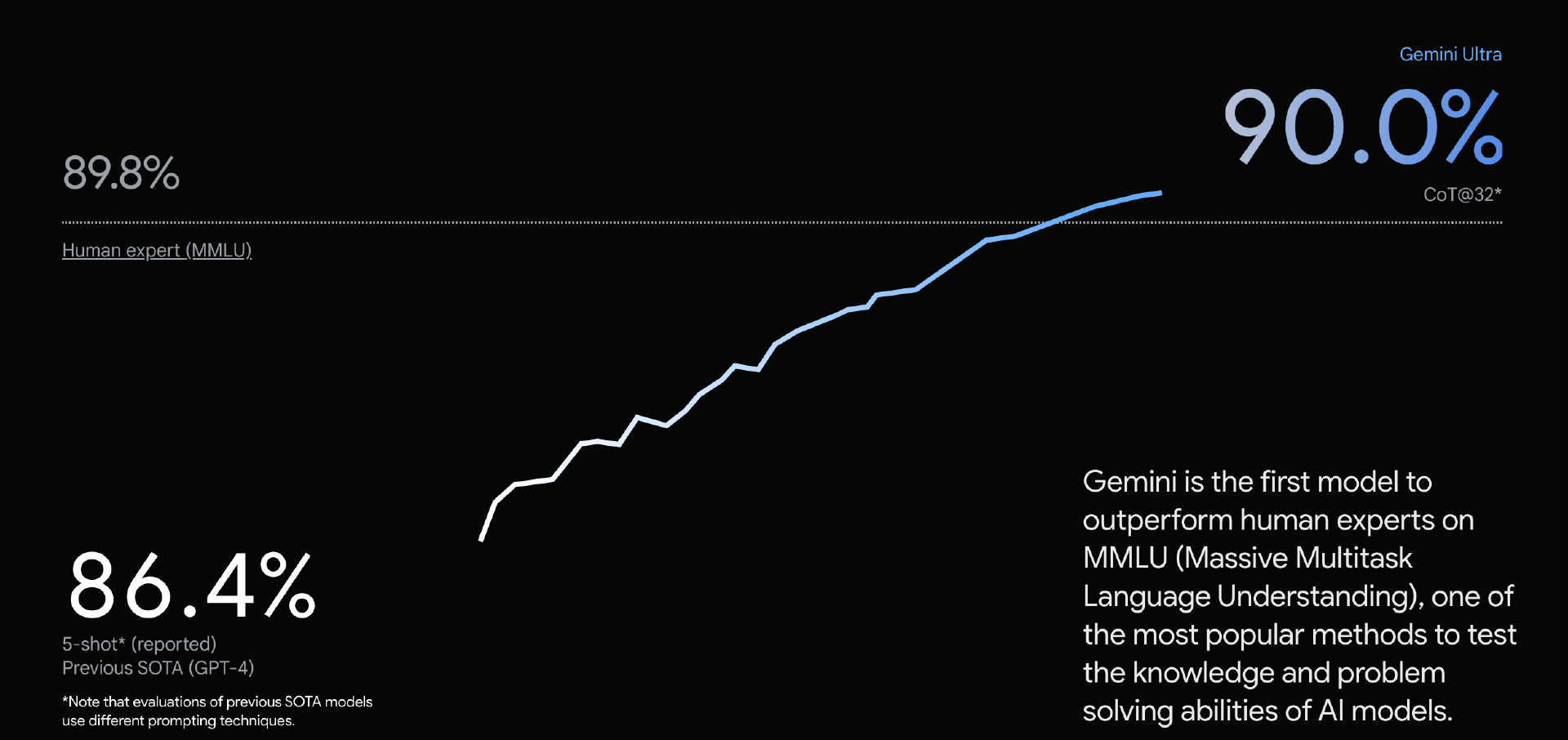
根据谷歌测试结果,从自然图像、音频和视频理解再到数学推理,在大语言模型(LLM)研发领域的 32 种常见学术基准测试中,Gemini Ultra 的性能一举创下 30 项最佳新纪录。
在 MMLU(大规模多任务语言理解)中 Gemini Ultar 的得分高达 90.0%,成为首个超越人类专家的模型。这项测试结合了数学、物理、历史、法律、医学和伦理学等 57 个科目,旨在测试 AI 模型掌握知识和解决问题的能力。
Gemini 在文本和编码等一系列基准测试中表现超过 GPT-4:
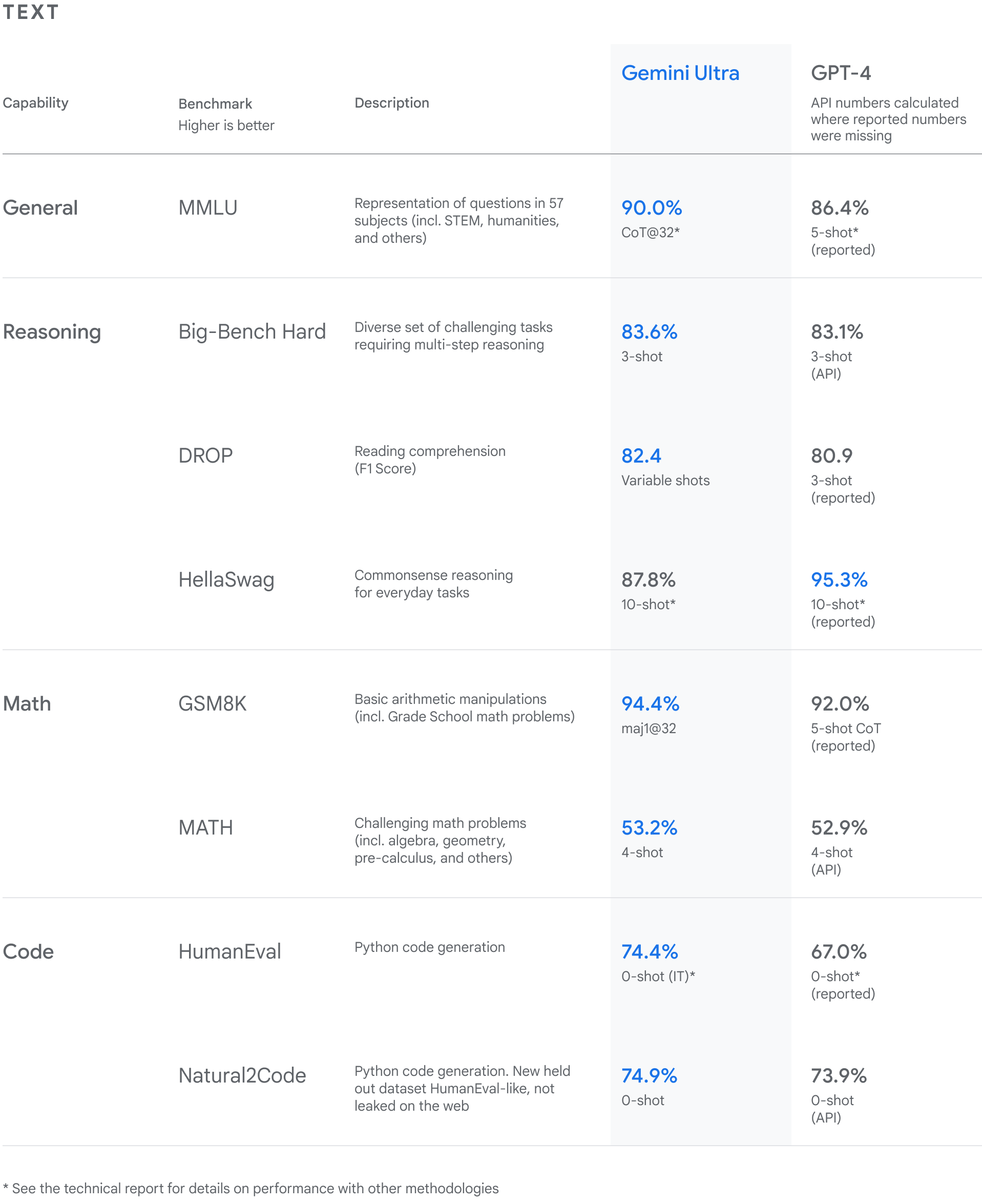
Gemini Ultra 还在新的 MMMU 基准测试中取得了 59.4%的最高得分。这项基准测试涵盖跨越不同领域、需要深思熟虑的一系列多模态推理任务。
根据谷歌测得的图像基准,Gemini Ultra 的性能优于以往最先进的模型,且无需借助从图像中提取文本以供进一步处理的对象字符识别(OCR)系统的辅助。谷歌表示,这些测试结果凸显出 Gemini 的天然多模态优势,也证明 Gemini 已经表现出具备复杂推理能力的早期特征。
Gemini 在一系列多模态基准测试中均创下性能新纪录,全面超越 GPT-4V:

多模态推理能力
到目前为止,创建多模态模型的标准方法主要是针对不同模态训练单独的组件,再将其组合起来以粗略模仿相应能力。由此实现的模型虽然比较擅长执行某些特定任务,例如描述图像内容,但却难以处理概念性更强、复杂度更高的推理任务。
在 Gemini 的起始阶段就将其定位为原生多模态形式,针对不同模态开展预训练。之后,谷歌又使用额外的多模态数据对其进行微调,希望进一步完善其有效性。现在,Gemini 可以同时识别和理解文本、图像、音频、视频和代码五种信息。
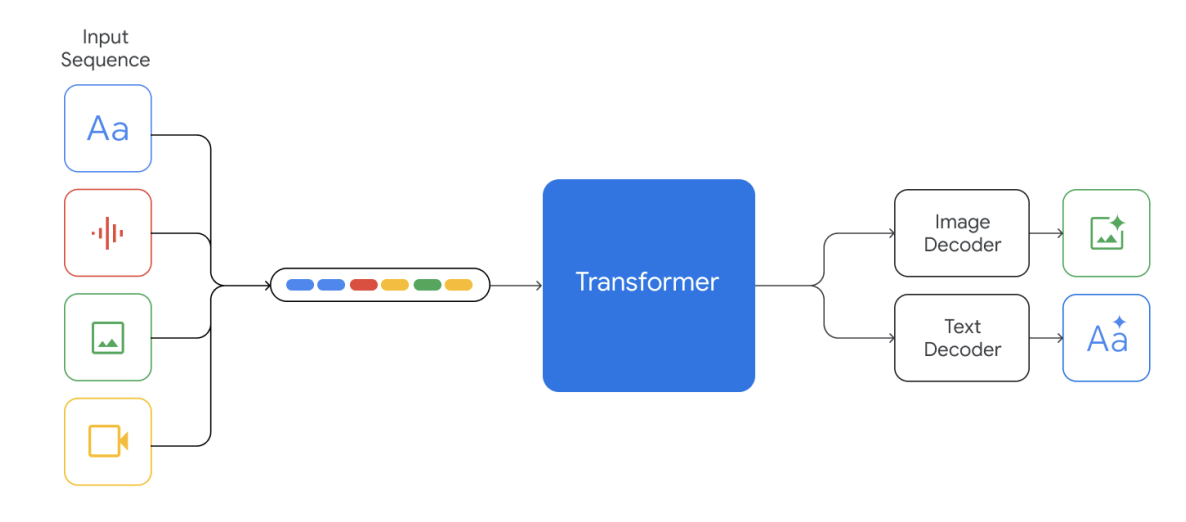
理解文本、图像、音频等各种素材
Gemini 1.0 拥有精妙的多模态推理能力,可以帮助理解复杂的书面与视觉信息,展现出了在大量数据中提取重要知识的独特能力。比如,Gemini 在阅读、过滤和理解信息的过程中,可以从数十万份文档中提取见解并进行分析。
Gemini 1.0 在训练之后,能够同时识别并理解文本、图像、音频等各种素材,因此可以把握住更加微妙的信息,并回答与复杂主题相关的更多问题。这使得它特别擅长解释数学、物理等复杂学科的推理过程。
比如,Gemini 可以识别学生的手写物理题答案,并验证正确性:

基于视觉线索进行推理:

音频方面,可以看下 Google DeepMind 研究科学家 Adrià Recasens Continente 演示 Gemini 能够理解来自多个扬声器的不同语言的音频,并结合视觉、音频和文本,在厨房做饭时提供帮助的场景:
高级编码能力
谷歌介绍,首个 Gemini 正式版能够理解、解释并生成基于目前各种流行编程语言(例如 Python、Java、C++和 GO)的高质量代码。其表现出的跨语言工作和复杂信息推理能力,也使得 Gemini 成为世界领先的编码基础模型之一。
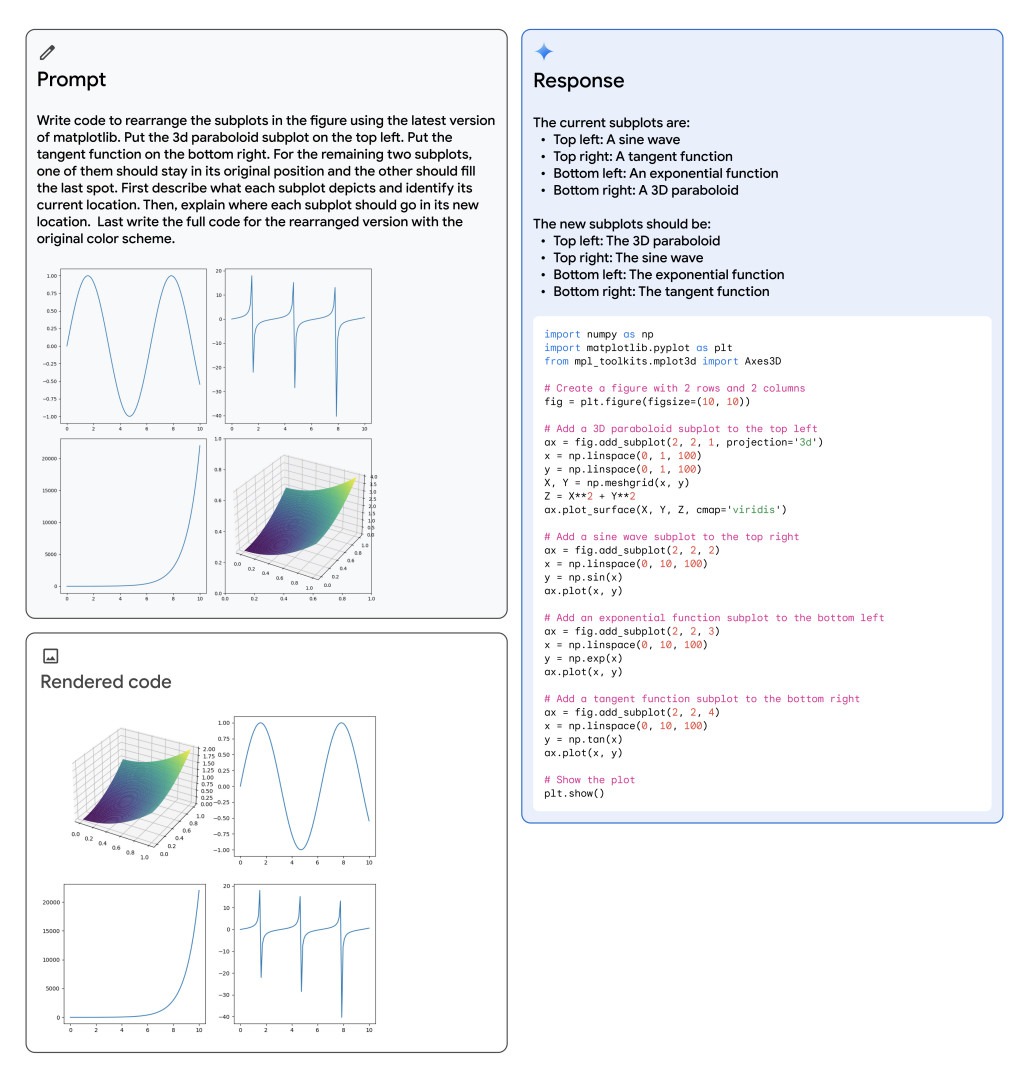
Gemini 的多模式推理功能生成用于重新排列子图的 matplotlib 代码
Gemini Ultra 在多项编码基准测试中表现出色,包括 HumanEval(用于评估编码任务性能的重要行业标准)和 Natural2Code(谷歌内部保留的数据集),此数据集使用作者专门创作的源素材、而非来自网络的信息。
Gemini 还能作为更高级编码系统的引擎。谷歌两年之前发布了 ALphaCode,这也是首个在编程竞赛中表现出一定竞争力的 AI 代码生态系统。使用 Gemini 的专用版本,谷歌推出更加先进的代码生成系统 AlphaCode 2。除了编码场景之外,它还擅长解决涉及复杂数学和理论计算科学的更多编程难题。
面对与初代 AlphaCode 相同的评估场景,AlphaCode 2 表现出巨大的性能改进,其解决的问题数量几乎达到初版的两倍,谷歌估计其成绩优于 85%的竞赛参与者,而 AlphaCode 成功解决问题的比例只接近 50%。因此当程序员通过代码示例来定义某些属性,并借此向 AlphaCode 2 寻求帮助时,其表现会更好。
“专为训练顶尖 AI 模型而生”的 TPU 系统
在介绍自家大模型的同时,谷歌顺势推出了了自己的 AI 训练基础设施。
谷歌使用内部设计的张量处理单元(TPU)v4 和 v5e 在 AI 优化的基础设施之上,完成了 Gemini 1.0 的大规模训练任务。
在 TPU 上,Gemini 的运行速度明显快于其他更早、更小且功能较差的模型。这些定制设计的 AI 加速器一直是谷歌 AI 产品的核心,负责为搜索、YouTube、Gmail、谷歌地图、Google Play 和 Android 等服务的数十亿用户提供支持。它们也使得世界各地的其他企业也能经济高效地训练出自己的大规模 AI 模型。
如今,谷歌宣布推出迄今为止“最强大、最高效且可扩展”的 TPU 系统 Cloud TPU v5p,专为训练顶尖 AI 模型而生。谷歌表示,作为下一代 TPU,它将加速 Gemini 开发,帮助开发者和企业客户快速训练大规模生成式 AI 模型,将新产品和新功能更快交付至客户手中。

谷歌数据中心内的 Cloud TPU v5p AI 加速器超级计算机
此外,在安全问题上,谷歌表示,Gemini 拥有迄今为止所有谷歌 AI 模型当中最全面的安全评估机制,包括偏见与有毒内容检测。谷歌还对网络攻击、说服与自主判断等潜在风险领域开展了新颖研究,并应用谷歌研究院领先的对抗性测试技术抢在部署之前帮助发现 Gemini 中的重大安全隐患。
为了诊断 Gemini 训练阶段的内容安全问题,并确保其输出结果符合政策,谷歌使用诸如真实毒性提示词 Real Toxicity Prompts 在内的多种基准。这是一组从网络提取的、包含不同程度毒性内容的 10 万条提示词,由艾伦 AI 研究所的专家们提供。为了限制伤害,谷歌还构建了专门的安全分类器,用以识别、标记并整理涉及暴力或负面刻板印象的内容。
附 Sundar Pichai 公开信内容:
每一次技术变革都代表着推动科学发现、加速人类进步和改善生活品质的机遇。我相信我们现在所见证的 AI 转变,将成为我们一生当中最具深远意义的事件,甚至远远超越之前的移动或者 Web 革命。AI 有望为全球各地的人们创造前所未有的日常生活体验和非凡的职业发展空间,将掀起新一波的创新与经济进步,并以前所未见的规模提升知识、学习、创造力与生产力。
这也让我感到兴奋,期待通过 AI 技术为各国各地的每一个人提供帮助。
作为一家 AI 优先的厂商,我们已经走过近八年历程,而前进的步伐只会不断加快:数百万用户正在我们的产品中运用生成式 AI 完成一年之前还难以想象的工作,包括为更加复杂的问题寻求答案、使用新工具协作与创新等等。与此同时,开发人员也在使用我们的模型与基础设施构建出新的生成式 AI 应用程序,世界各地的初创企业和组织正利用我们的 AI 工具不断拓展业务。
这是一股令人难以置信的发展态势,而且我们才刚刚开始触及这无限可能性的最表层。
我们正以大胆且负责任的态度开展这项工作。这意味着我们既需要追求雄心勃勃、能够为人类和全社会带来巨大收益的技术成果,同时也要建立保障措施并与政府和专家合作,应对 AI 发展过程中带来的种种风险。我们将继续投资打造更好的工具、基础模型和底层设施,并在我们 AI 原则的指导下将其引入自己的产品及其他方案当中。
相关链接:
https://blog.google/technology/ai/google-gemini-ai/#availability
https://storage.googleapis.com/deepmind-media/gemini/gemini_1_report.pdf




