
2010 年随着 iphone4 的发布,智能手机被广泛使用,从大学生到老人小孩,移动互联网的发展如火如荼。近两年,5G 技术让下载速度变得越来越快,相较于传统的文本搜索技术,语音搜索和图片搜索等新型搜索方式出现在越来越多的产品形态当中。
今天的内容主要分为 4 个部分来介绍多模搜索技术:
多模搜索:始于移动,繁荣 5G+智能时代
语音搜索:听清+听懂+满足
视觉搜索:所见即所得
“破圈”:无限可能
多模搜索:始于移动,繁荣 5G+智能时代
1. 多模搜索的概念
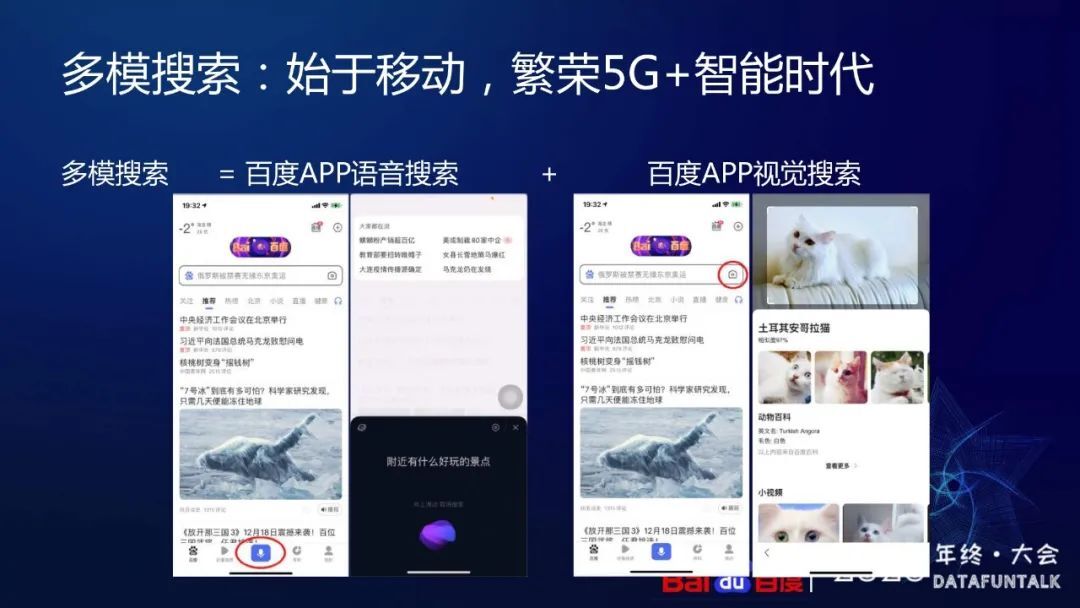
多模搜索包括视觉搜索和语音搜索两种形式。在百度 app 的下方,语音按钮的部分,是语音搜索的入口。在搜索框的右侧相机的按钮,是视觉搜索的入口。语音搜索可以很好地替代文字搜索,而视觉搜索,可以帮用户方便的找到图片背后所具有的信息。
2. 百度为什么在 2015 年开始多模搜索技术的积累

以 iphone 手机为代表的智能手机时代到来,使得语音输入成为可能。
4G 通讯网大大提高了上传下载速度,上传图片不再困难。
我们的网民从中青年开始向两侧的小孩儿和老人扩展。
3. 多模搜索在 5G 新时代产生的变化

沉浸式体验。在 5G 带宽更加强大之后,我们需要有一些超越视频的更加沉浸式的体验。
延时的降低。在 5G 推广开来之后,尤其是借着云边端三个阶段的服务的部署,包括很多的模型,从云端前置到端,这样的话可能会带来很大的便利。
新的硬件。伴随智能音响、蓝牙耳机、智能手表、智能眼镜的广泛使用,进一步催生多模搜索的用户需求。
语音搜索:听清+听懂+满足
1. 语音搜索的目标有三个,听清、听懂、满足
听清:准确地将我们说话的语音信号转换到文字,这里面临的挑战其实非常的多:① 环境比较嘈杂;② 方言;③ 声音过小。
听懂:即使当我们去把语音转换成文字,也不代表我们就能按照传统的搜索的方法把转换后的文字直接丢给搜索引擎去理解。原因:① 口语化的问题;② 长尾的问题;③ 连续搜索。举个例子,第一次用户会问“伦敦现在几点”,但下一次他不会再说“巴黎现在几点”,会直接问“巴黎呢”。
满足:一些特定的语音入口,比如智能音箱上,我们不太可能会把前十的搜索结果去给用户都播报一遍,我们只能给用户最精准的 top1 结果。
2. 技术方案

整体这三个阶段大的技术框架如下:
首先在听清这个环节。从输入角度来看,有两个:① 语音识别。这个阶段更多的是把声学的信号转换成基础的文本文字;② 语音纠错,语音纠错会把用户原始的文字表达改变成适合搜索引擎去真正理解的 query。在最后的内容表达的过程中,会经过一些播报生成、语音合成,使得交互更加的自然。
在听懂的环节主要有四个部分:① query 的泛化,这一步的目标其实会把整个用户的长尾表达,映射到搜索引擎更加好理解的一些比较高频的 Query 上去;② 对口语理解,可以转化为 QA 问题;③ 上下文的理解;④ 整个搜索 session 的管理
在满足这个环节层面。站在整个百度通用搜索的肩膀上,在某一些特定的场景需要给用户一些更精准的一些表达,所以这里面需要智能问答的技术,还包括知识图谱的技术,最后提供一些特定服务。
视觉搜索:所见即所得
1. 目标

视觉搜索要做的事情就是所见即所得,无论是用户通过手机拍摄,或者是通过摄像头实时摄像看到的一些东西,我们都能给到其背后的内容,这里面大概有三个挑战。
交互。交互技术是一个很重要,影响用户整个的交互效率比较高的环节。
感知。不同于文本搜索把每一段文字或者自己的需求通过比较高级别抽象的东西去表达出来,视觉搜索需要从像素级来感知和构成更高级的物体级信息。
识别。理解整个由像素集合所代表的一个个物体背后的信息。
2. 成就
经过几年的努力,百度取得了比较好的技术积累,实现了全球比较领先的视觉感知和搜索引擎。从交互上来看,基本可以在 100 毫秒左右,在手机端上就能给用户一个很好的感知反馈,同时覆盖了 60 多个场景,索引了 8000 多万种的实体,几十亿的商品,还有 1000 多亿的图片。
3. 视觉技术
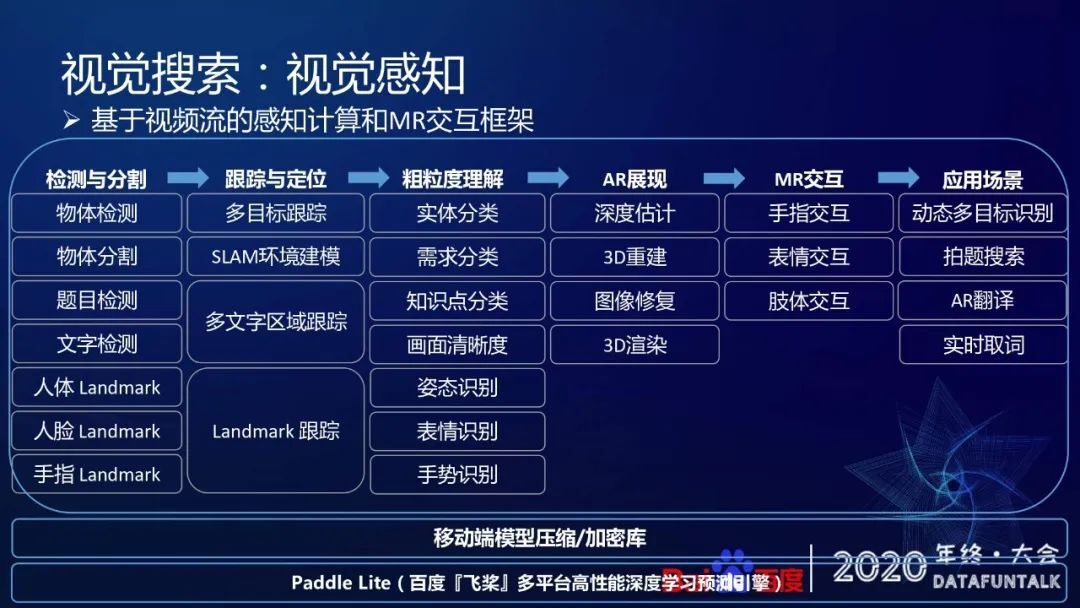
整个视觉搜索的技术大概分为三个层面,
第一个层面是视觉感知,这个层面主要再用户的手机本地计算,这里面包括 2D 和 3D 的检测,2d 和 3D 的跟踪,包括一些简单的场景识别,还有支持 AR 定位和渲染。
第二个环节是视觉识别,当我们在手机端完成这些感知之后,需要对感知到的这些物体做更详细的信息搜索和满足。
第三个是基础技术,主要用来支撑上面的感知和识别,包括图像的理解、文本的理解、视频的理解,还有关于人体、人脸等等一些感知技术,也包括一些基础的云和端上的性能优化、多模态的 QA 技术等。
4. 视觉感知流程
把视觉感知打造成一个基于视频流的感知计算和 MR 交互的一个框架,这个框架是完全在端上去计算,主要包含六个流程
检测与分割。主要是发现画面里面的一些基础的物体,以及它的一些物体类型。
跟踪。因为我们要做连续的交互,画面会有持续移动,所以就会需要做一些跟踪和定位,去保持住跟踪物体的具体位置。
粗粒度理解。端上对整个流量做一些简单理解,起到流量精准分发的目的。
AR 展现。在云端搜索结果返回之后,把结果信息通过 AR 的方式展现。
MR 交互。通过手指或者肢体表情交互,让用户可以与 AR 内容做更进一步的交互和交流。
应用场景。最后是支撑已有的几个产品形态,包括动态多目标识别、拍题搜索、AR 翻译、实时取词等。
视觉感知算法的演进
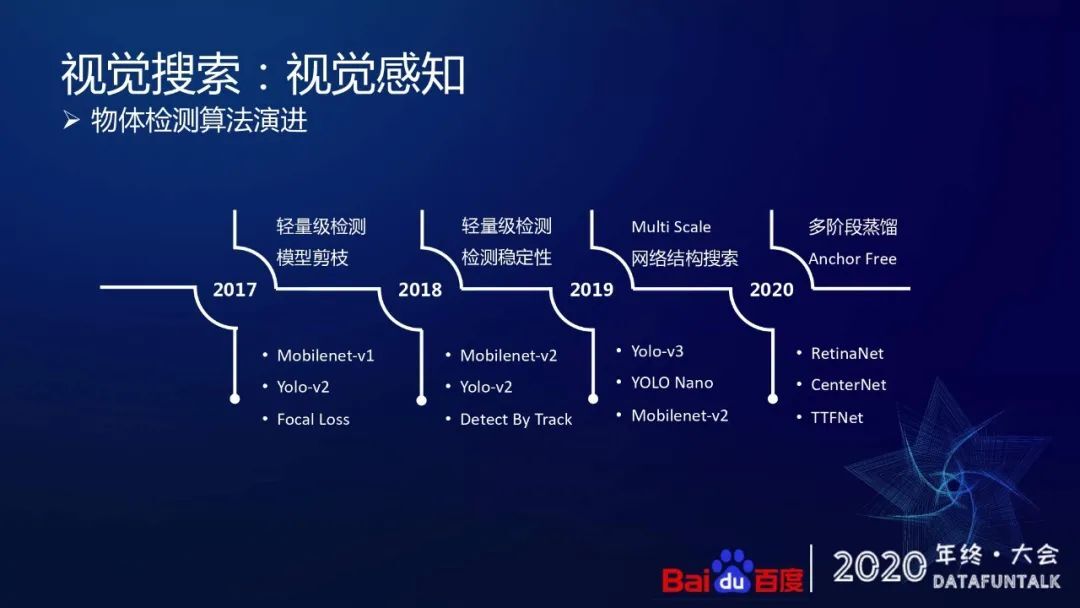
从 2017 年开始,我们第一次尝试在端上做物体检测技术,它的目标就是做轻量级模型。
第二个阶段是在 2018 年,在做连续的帧检测的时候,解决新的检测稳定性的问题。
2019 年开始,我们想进一步提升小物体的检测效果,在 Multi-Scale 检测和网络结构自动搜索上做了一些工作。
然后到 20 年会更多的去通过多阶段蒸馏和 anchor free 模型探索,进一步提升整体的检测效果。
算法迭代
第一代检测算法:首先在第一个阶段轻量级的阶段,我们选型直接选了 one stage 的检测方法,使用公开的 mobilenet-v1 结合剪枝增加模型的速度,loss 在 layer 层面也做了一些简单的优化,并且尝试使用了 focal loss。
第二代检测算法:刚刚提到我们发现了一个新的问题,在连续检测时检测的输出会发生很大的变化,这是影响着连续帧的检测稳定性的一个根本的原因。我们首次提出问题的定义和量化公式,最终结合多帧信息非常好的解决了检测稳定性问题,同时兼顾了性能。
第三代检测算法:第三代的主要目的是解决小物体召回,基本上从两个阶段来入手,第一个就是整体的网络模型结构,yolo-v3 对小物体会更加友好,第二个是引入了网络的结构化搜索,会进一步提升对小物体的优化。
第四代检测算法,我们观察到,虽然改进后 yolo-v3 效果已经很不错,但是与 retinanet-50 甚至更大的模型相比,还是有很大的差距。因此希望通过蒸馏的方式进一步提升检测结果的准确率。
5. 视觉识别检索的流程
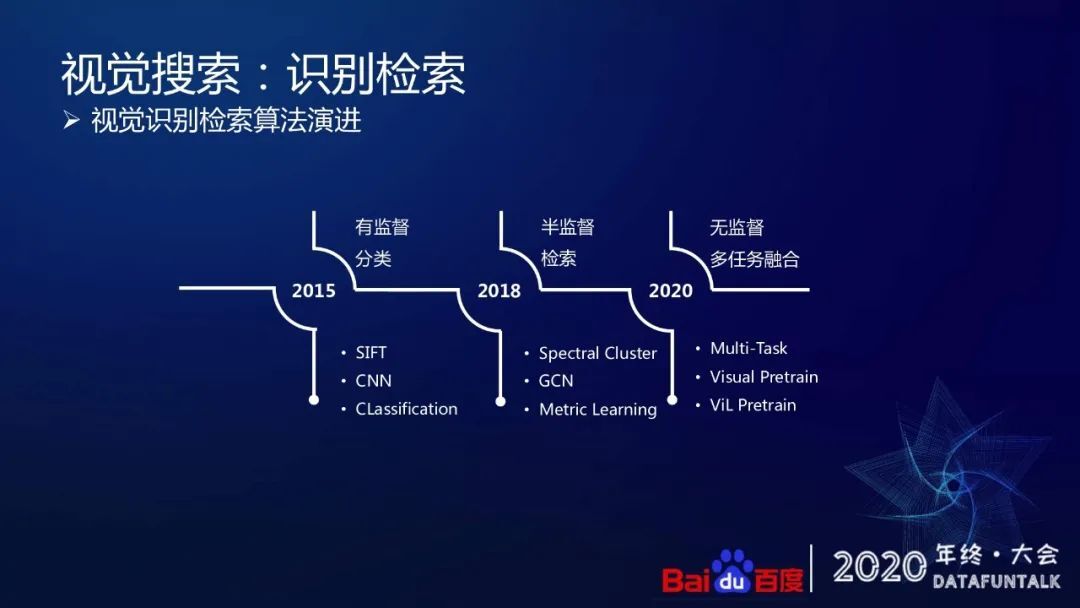
基本的流程是:基于 sift 或者 cnn 提取的特征,然后使用 ANN 进行检索。
我们大概经历了三个阶段的演进:
第一个阶段是 2015 年刚开始做的时候,基于有监督的方式。
第二个阶段是 2018 年的时候,我们开始引入了半监督的方式,通过数据驱动训练图像以及视频的特征表示。
从 20 年开始,我们从半监督向无监督的方式去升级算法,希望利用到更多的数据去学习到一个更加适合任务自身场景、泛化能力也更好的特征表示。
有监督方法存在的问题
第一个有标注的数据,数据规模往往比较小,而且噪声也相对来说比较多一些。
第二点由于它的规模比较小,所以样本多样性往往是不足的。
第三个问题是通过这种人工标注,有多少人工就有多少智能,标注成本也是非常高的,而且这个周期也比较长。
无监督方法的选型和演进
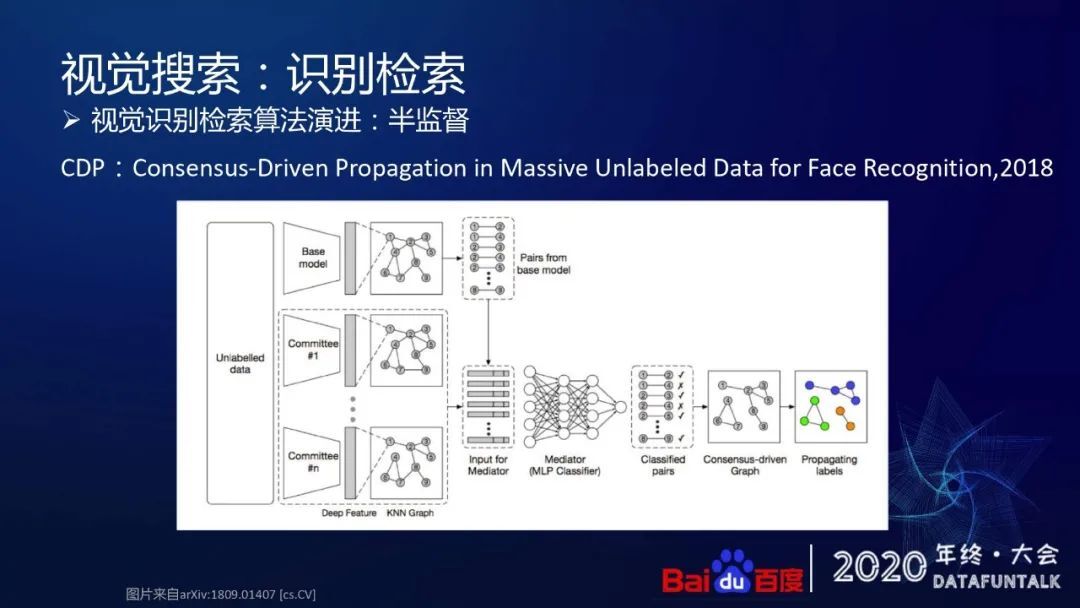
第一种是比较偏向于传统的谱聚类的方式实现,根据向量得到 pair 之间的相似度,然后将聚类的编号作为数据的 label。
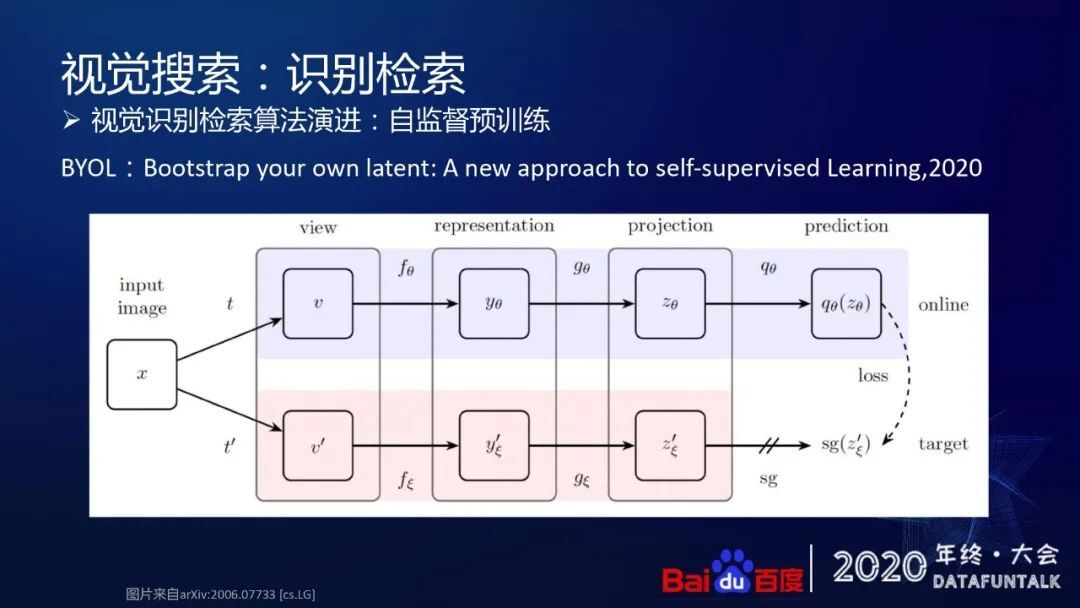
第二种是以 BYOL 算法代表的,将图片经过多种增强后得到自身的变形,通过原始图和变形图之间的对比学习,学习到整个图片比较好的特征表达。
“破圈”:无限可能
破圈无限可能,未来多模搜索的技术和产品形态会往哪里发展?度晓晓 App 是答案之一。

度晓晓是在 20 年百度世界大会上第一次发布的多模搜索新的产品,从技术角度来看它是语音、视觉、文本三大技术领域的一个交汇,汇聚了语音识别、图像识别,还有智能搜索、NLU 和多轮对话的技术,同时它本身有一个虚拟形象存在,富含多种情感的语音合成技术,它的背后是百度多种技术方法和产品的融合,包含着信息和服务搜索,以及互动娱乐的部分。
未来通过更多的整合多模搜索技术,将产生更多无限可能。
文章作者:
李国洪
百度资深研发工程师 | 百度多模搜索策略负责人
本文转载自:DataFunTalk(ID:dataFunTalk)
原文链接:5G+智能时代的多模搜索技术




