
科大讯飞如何在人工智能的技术层面进行源头技术突破和多技术融合,以此来推动实现系统性创新。
在今年的 1024 开发者节活动上,科大讯飞高级副总裁胡国平在分享中提到,系统性创新有三个关键要素,第一是重大系统性命题到科学问题的转化能力。第二是从单点的核心技术效果上要取得突破,跨过应用门槛。第三是把创新链条上各个关键技术深度融合,实现真正意义上的系统性创新。
随后,他围绕端到端建模、无监督训练、多模态融合和深度学习框架等技术研究,展开介绍这些技术是如何应用于语音识别、翻译等业务上的,以及取得了哪些效果。
以下是胡国平老师的演讲整理:

从技术角度上讲,处在人工智能大时代,在深度学习框架下,讯飞研发了包括语音识别、语音合成、机器翻译手写识别等一系列的人工智能的技术和应用,当然,技术的生长和发展需要强大的源头技术的突破和滋养。
在过去的几年,科大讯飞一直关注并持续在 4 个 AI 源头和底层技术上投入,分别是端到端的建模,以此来解决分段建模式的信息损失问题。无监督训练,来实现用更少的有监督数据获得更好的效果。在多模态融合上的研究,能够充分的利用多维多元的信息。以及外部知识的融合,即如何把人类的常识、知识融入到算法模型的构建中。
一、端到端的建模技术
在深度学习框架下,端到端建模可以有效的缓解分段建模所带来的信息损失,以及错误的级联传播问题。
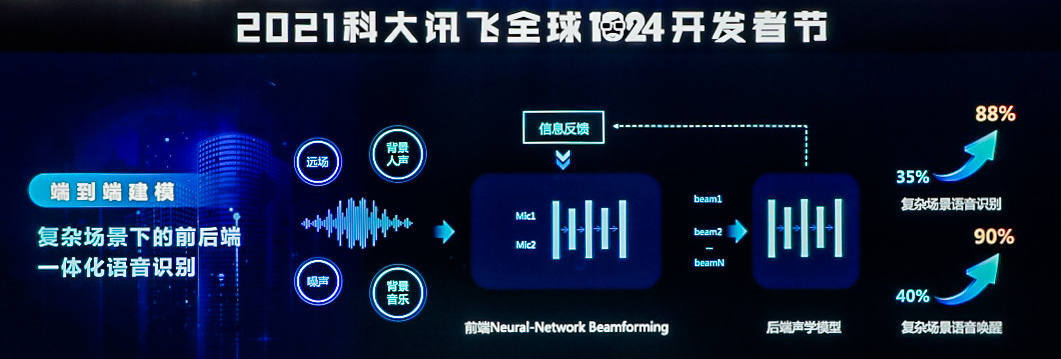
首先,科大讯飞把端到端的建模技术应用到了复杂场景下的语音识别,构建了前后端一体化的语音识别系统。做法是将前端麦克风阵列所产生的多路信号同步输入到后端的声学模块,让声学模块可以更充分的得到相关的信息,实现更精细的建模,从而可以显著的提高复杂场景下的语音识别效果。更关键的是在这样统一的建模框架之下,可以使得后端的声学模块的解码结果,如端点、文本信息等反向指导前端麦克风阵列的波数形成,进一步提升降噪的效果。以商场卖场这种极其嘈杂场景下的语音交互为例,科大讯飞的语音识别效果由原来几乎不可用的 35%,提升到了 88%,而且语音唤醒的成功率也从原来 40%提升到了 90%,首次实现了极复杂场景下的语音识别的成功应用。
另外,端到端建模的技术成功运用到了语音的翻译任务上,实现了基于建立的 CATT 语音翻译技术,把一个语种的语音输入自动识别并翻译成另外一个语种的文本输出,实现了语音识别和机器翻译任务的统一建模,缓解了语音识别错误对翻译效果的影响。更关键的是在这样一个统一建模的框架下,可以很方便的引入翻译延时损失函数,实现翻译效果和延时的有效平衡,实现更好的语音翻译体验。
基于这样的创新技术,讯飞在今年的 IWSLT 国际口语机器翻译大赛上包揽了所有三个赛道的冠军。此外,端到端的建模技术也有效支撑了科大讯飞的语音合成、作文评分、说话人分离等相关技术的持续进步。
二、无监督训练
这里面包括讯飞团队在弱监督半监督等一系列的创新。众所周知,AI 技术的前进,需要突破对大规模无监督训练数据的依赖,这样的依赖也成了 AI 进程中的关键瓶颈。
讯飞在无监督的源头之上,也实现了两个方面的关键突破。一是基于海量原始数据,无监督的自动挖掘出更紧致的特征表示。另一方面是,充分借助其他的弱标注,将弱监督数据更好的实现模型的优化训练。
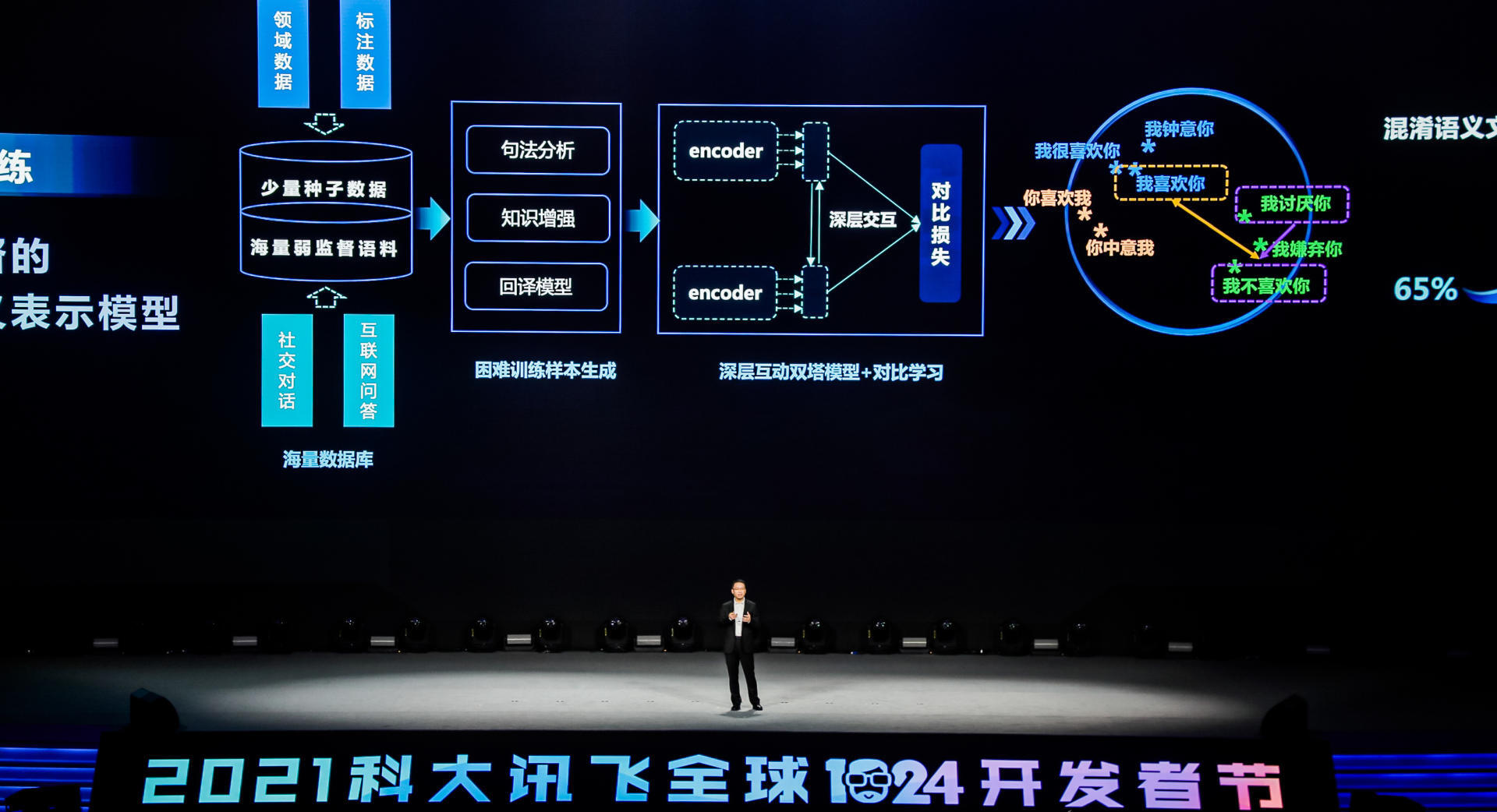
无监督训练在语音合成上的应用,为了降低对语音合成音库规模的要求,研发团队提出了听感量化的编码方法,充分借助了语音识别数据,用其他人的语音合成音库来实现多人的混合模型的训练,也就是说,只需少量发音人的数据,就可以实现发音人的高音质语音合成。
今年,讯飞提出了全属性可控语音合成方法,实现了从海量语音数据中无监督的学习发音内容、情感和音色这三个属性,并且使用信息约束训练,使得三个属性相互结合,这样就可以实现对音色情感等属性的自由控制。例如可以通过对音色空间的调节,实现音色甜美程度的自由控制。同样也可以进行情绪的调解,在悲伤情绪和高兴情绪之间任意切换。
同样,无监督训练模型也运用到了语音识别方向。对于小语种的语音识别而言,有监督的语音训练数据的获取其实是非常困难的,但小语种文本数据的获取是相对容易的。所以为了实现对海量文本数据的充分利用,胡国平团队提出了基于语音和文本统一空间表达的半监督语音识别技术。
首先,用抗噪性能好,风格更加丰富的 Follow CPC 语音合成系统,生成了大量的仿真语音,并与真实的语音训练数据一起实现了语音识别模型的构建。
其次,使用掩码语言模型(Masked Language Model,MLM)的任务与语音识别任务的联合训练,并且共享语音和文本的解码模块,使得它们的表达可以在同样的一个特征空间,可以充分利用海量的无监督文本数据,最终可以实现 100 个小时的有监督数据,加上大量的无标签文本数据,就可以达到 1 万小时的有监督语音数据的效果。这是一个关键技术的突破,也是全新的进展。
无监督训练的另一个重要应用领域,即基于弱监督的句子级的语义表达,这对于认知智能等相关任务的构建是非常重要的,利用大规模弱监督的数据来解决这一难题。
首先,从互联网上挖掘了大量相关联的问答,并且引入包括句法分析,知识增强以及回译模型来构建困难训练样本,让模型具有更好的语义区分性。
然后,胡国平团队提出了深层互动对比学习框架,大大提升了语义理解的深度,从而能够有效的区分在文本上“虽然很像,但意义相反”的句子,比如我喜欢你和我不喜欢你,最终在混淆的分类层的建立上,识别准确率从原来 65%提升到了 85%。
三、多模态融合
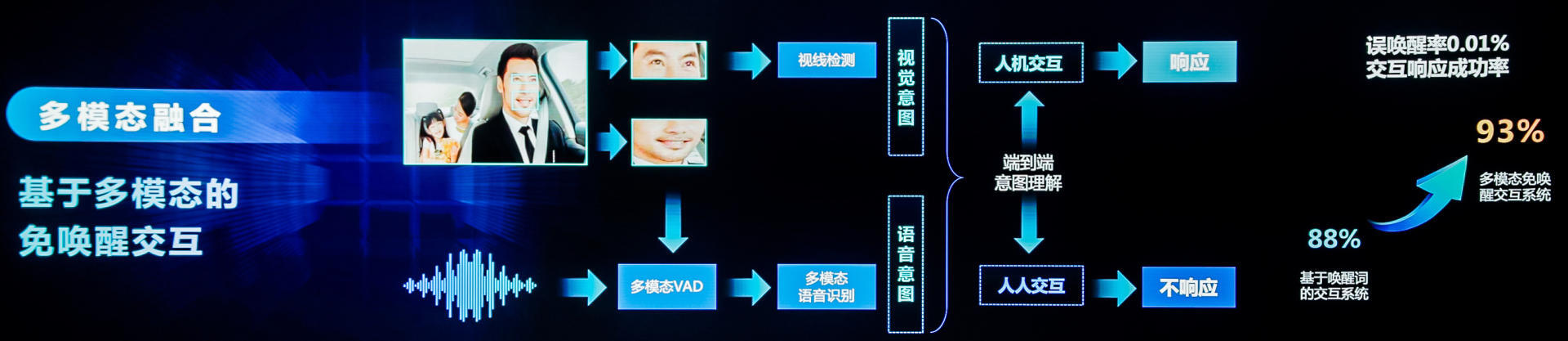
人机交互就是多模态融合的典型应用场景。讯飞在实现的基于多模态免唤醒的交互系统中,通过语音和口唇检测两个维度的信息来控制误唤醒。同时用语义理解语义视线检测的信息,来区分用户是在进行人机交互,还是在与其他人聊天,最终能将误唤醒率控制在 0.01%以下,使得交互响应的成功率从原来 88%提升到 93%,而且是从原来依赖唤醒式的语音交互升级到更自然的免唤醒的交互,可以说讯飞的研究重新定义了人机交互的方式。
另一个多模态融合的例子是复杂文档的结构化,比如考试中的一份试卷,具有各种各样的题目、表格、插图,以及学生手写的答题信息等。讯飞的 OCR 技术,包括手写数学公式识别等都已取得进展,但如何对这样的复杂文档,复杂版面进行自动的语义结构化,对于智能阅卷的相关应用是非常重要的。
讯飞也是基于多模态信息融合技术,不仅用到了题目中的相关语义信息,还用到了各种版面的特征,例如表示质地大小的视觉特征,表示缩进居中的空间特征等等,最终实现了不同场景下文档结构化的精度大幅提升。类似于教育这样一个场景下的教辅作业的语义结构化的精度,从原来 92%提升到了 98%。讯飞已将这些技术开放,帮助开发者在自己不同的行业领域开展智能化的文档处理,提供更好的技术支撑。
四、将外部知识融入到现有的深度学习框架
现在大部分的深度学习的模型都是基于有监督,或大量无监督的数据训练出来的。但是从智能系统角度来说,人类的知识其实是一个非常重要的信息来源,在这方面讯飞也做了两个关键的技术突破。
第一是在语音交互任务中,把人类的常识、知识总结为事理图谱,融入到整个交互系统中,从而实现机器能够与人主动交互。以儿童交互场景为例,机器人依据事理图谱的相关推理,实现对儿童更长时间更好玩的陪伴。
外部知识融入的第二个成功案例,即融入海量医学文献知识和病例的诊疗推理系统,传统的诊疗推理技术是基于电子病历的语义深层的解析和建模来实现的,如何使用海量的人类已有的医学文献知识,提高机器的自动诊疗的准确率也是非常关键。讯飞已经把各种医学文献知识进行了结构化处理,形成了医学的知识图谱,并且使用图神经网络对于图谱进行编码,这样就可以基于深度实时的推理网络,从知识和病历两个视角进行注意力的交互学习,综合决策给出最终的治疗结果。
单点技术的突破是人工智能技术落地的前提,但在使用的系统,人工智能系统往往是一个复杂的系统,从单点技术的创新,单点技术深度融合的复杂系统演进,需要攻克以下三个方面的系统层面的技术挑战:
第一,面向全局目标的技术架构的解析能力;
第二,全链条贯穿的多技术融合的这样一个创新能力;
第三,基于人机耦合复杂系统的自进化能力。
胡国平以三个具体的用复杂系统构建的案例,介绍了科大讯飞在多技术融合方面的关键进展和突破。
首先,以低延时下的多技术融合的语音同传系统为例来解释一下面向全局目标的技术架构能力。语音同传有个关键的技术挑战,关键的全局性约束,那就是时间延时问题,如前所述,讯飞已经基于模型,端到端的实现了从语音到文本的自动翻译,但要实现同声传译,还需要把传统句子级别的语音合成系统改造为流式的语音合成,以此实现对实时输入的片段文本进行合成。同时还需要实现基于一句话的语音合成系统的音色迁移,使得合成的语音人能够保持原始说话人的音色,实现更好的同传体验。
与此同时,为了提高类似于大会演讲上语音识别和翻译效果,讯飞还进一步的把大会演讲 PPT 中的文字全部 OCR 出来,特别是专业术语,实时送入语音识别系统进行实时优化,这样才可以在尽可能的保证翻译效果的同时又能实现低延时的同传翻译。目前讯飞最新的翻译系统平均延时已经从原来的 8 秒下降到 4 秒。
第二个案例是多模态虚拟人交互系统,虚拟人的交互需要集成语音识别、对话理解、对话生成、语音合成、虚拟人形象生成等多项人工智能单点技术。
讯飞需要实现全面和技术贯穿,才能实现更一致、更和谐的虚拟人交互系统。例如以情感维度而言,要实现继续多模态信息的情绪感知,基于情绪的回复对话文本生成,以及可展现对应情绪的虚拟人的表情和语音合成。只有基于全局的系统性的规划设计,以及全链条单点技术的有效配合,才能成功的造就一个有情感、有个性的多模态虚拟的人。

其实讯飞做出来的所有系统都是给人用的,都是人机耦合的复杂系统,人作为用户,特别是像医疗教育领域的这种专家型用户,人和机器的交互时机的选择,交互界面的设计,也是人机耦合复杂系统的关键创新所在。同时,如何利用人机交互过程中所留下来的信息,实现系统的自净化能力,也是系统性创新的核心所在。
以科大讯飞所研发的智医助理系统为例,智医助理系统在基层医生的诊断过程中就直接提供包括诊断建议,合理用药,进一步问诊问题等核心功能,帮助基层医生实现更好的诊疗。同时当现场的基层医生和机器诊断结果不一致的时候,系统还会将病历转移到上级的医院进一步诊断。系统也会持续的收集基层医生和专家医生在整个交互过程中的反馈信息,用于系统的实时净化。可以说 AI 系统和医生实现了相互启发,相得益彰,共同进步,实现了这样一个人机耦合复杂系统的持续进化。
【活动推荐】
以上是胡国平老师的演讲内容,如果您对科大讯飞的技术很感兴趣,可以关注 11 月 26 日北京 AICon 人工智能大会上科大讯飞研究院研究主管王宝鑫老师的演讲,他会介绍 NLP 在中文自动校正的技术实践。此外,NLP 相关的话题,还有华为、微软、百度的专家来分享,大家可以查看会议官网 https://aicon.infoq.cn/2021/beijing/schedule





