
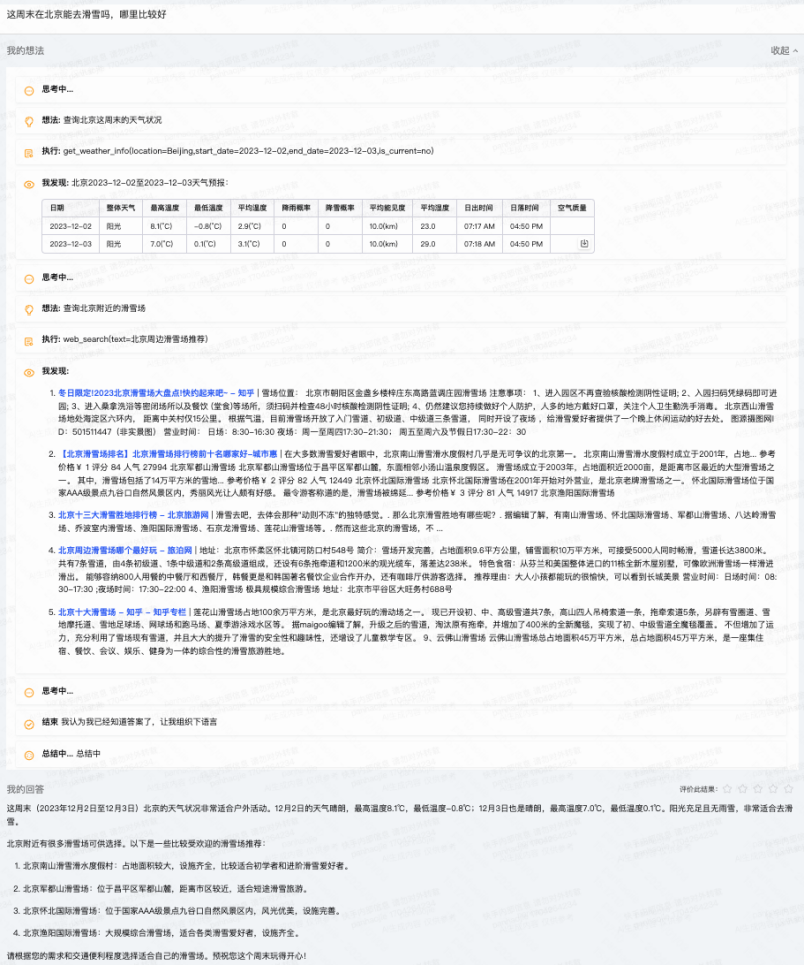
7B 的模型也能玩转 AI Agents 了?近期,快手开源了 Kwai Agents,亲测发现,问它周末滑雪问题,它不但能帮你找到场地,连当天的天气都帮你考虑周到了。
大语言模型(LLM)通过对语言的建模而掌握了大量知识,并具备一定认知和推理能力。但由于无法跟世界保持实时的交互,在单独使用的情况下,常会出现一本正经地胡说八道的现象。而 AI Agents 就是解决这个问题的道路之一,它通过激发大模型任务规划、反思、调用工具等能力,使大模型能够借助现实世界工具提升生成内容的准确性,甚至有能力解决复杂问题。
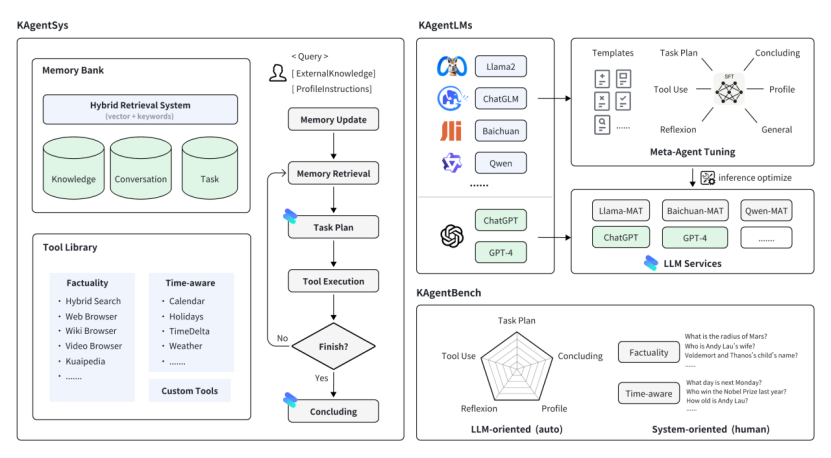
据了解,KwaiAgents 是一个先进的 AI 智能体系统,由快手联合哈尔滨工业大学研发,通过使用大型语言模型来模仿人类认知技能,可应用于自然语言处理、语音识别等领域。Kwai Agents 可以使 7B/13B 的“小”大模型也能达到超越 GPT-3.5 的效果,目前该项目已将系统、模型、数据、评测全部开源,使得更多的研究人员可以参与其中。
技术报告:https://arxiv.org/abs/2312.04889
项目主页:https://github.com/KwaiKEG/KwaiAgents
从「KwaiAgents」的 Github 主页中可以看到,本次开源内容包含:
1.系统(KAgentSys-Lite):轻量级 AI Agents 系统,并配备事实、时效性工具集;
2.模型(KAgentLMs):Meta-Agent Tuning 后,具有 Agents 通用能力的系列大模型及其训练数据;
3.评测(KAgentBench):开箱即用的 Agent 能力自动化评测 Benchmark 与人工评测结果。
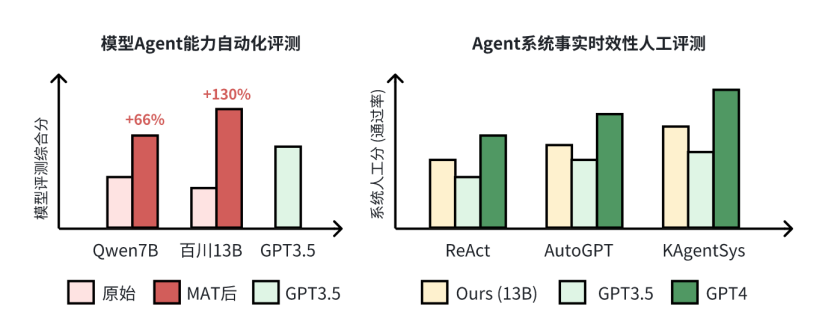
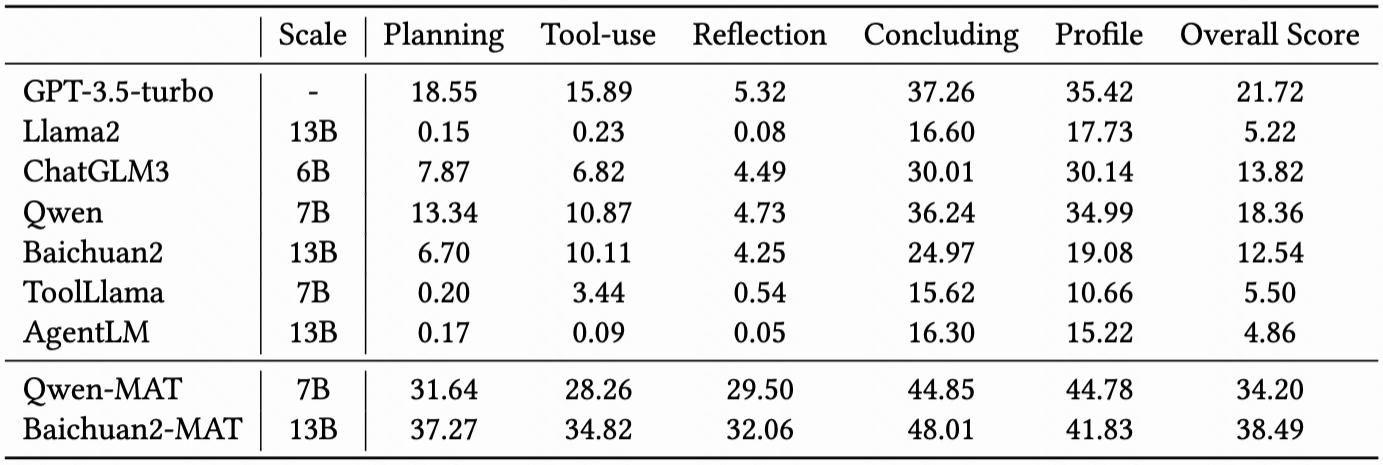
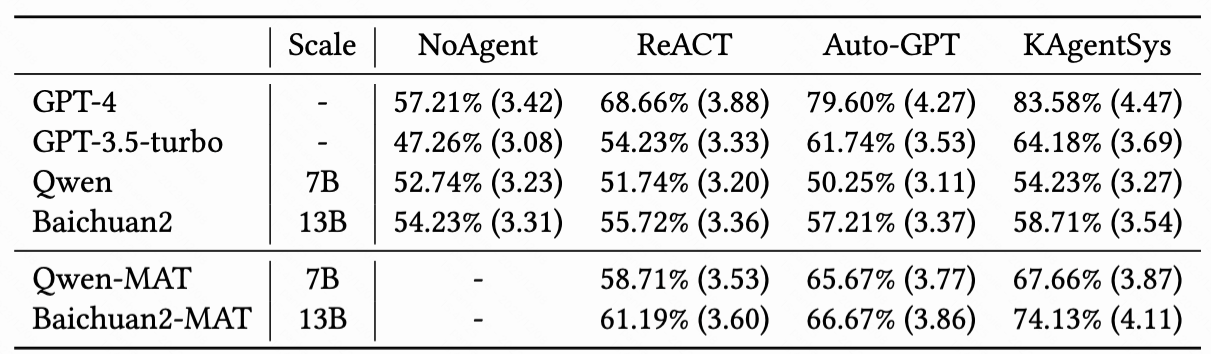
KAgentBench 通过人工精细化标注的上千条数据,做到了开箱即用,让大家能够用一行命令评测一个大模型在不同模板下,各方面的 Agents 能力。下表显示了经过快手团队调优后,7B-13B 模型各项能力的提升,且超越了 GPT-3.5 的效果:
同时,作者们还请人类标注者在 200 个事实性和时效性的问题(如“刘德华今年几岁了”),对不同的大模型和 Agent 系统进行了交叉评估,可以看到 KAgentSys 系统和 MAT 之后模型提升显著(百分号前为正确率,括号内为 5 分制均分)。
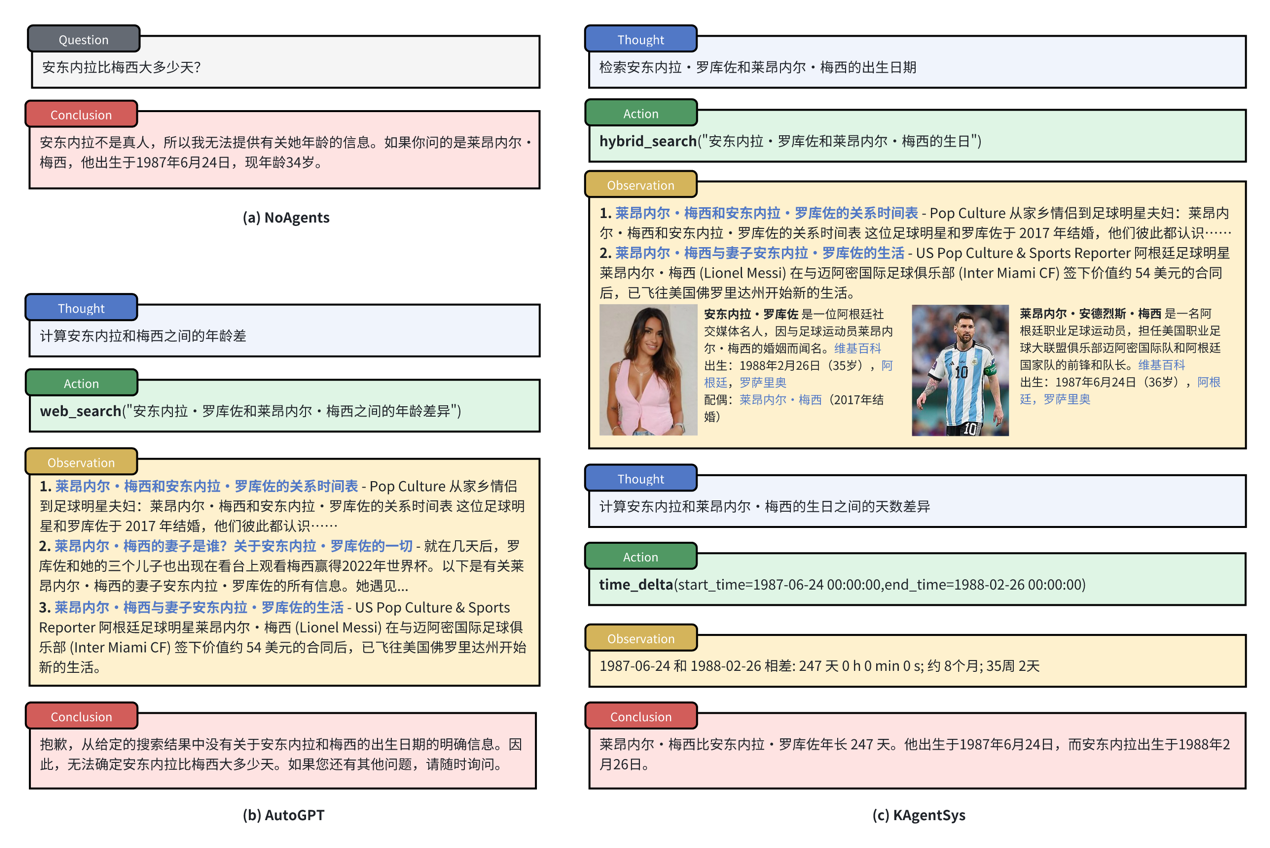
通常仅依赖网页搜索对一些长尾问题和热门问题返回结果不佳。比如问到“安东内拉比梅西大多少天?”这类长尾问题,往往搜索结果返回的都是一些两者的八卦新闻,而返回不了一些关键信息。而 KAgentSys 通过调用百科搜索工具获取精准的出生日期,再调用 time_delta 时间差工具算出年龄差,就能精准回答这个问题了。
快手技术人员表示,AI Agents 是一条非常有潜力的道路,未来一方面会在这个方向持之以恒地沉淀核心技术,并为整个社区不断地注入新的活力;另一方面,也会积极探索 Agents 技术与快手业务的结合,尝试更多有趣、有价值的创新应用落地。




