
Julia 正在迈向主流编程语言。
本文是“2021 InfoQ 年度技术盘点与展望”系列文章之一。
在刚刚过去的 2021 年,Julia 编程语言社区依然保持了高速发展。据统计,目前 Julia 的全球总用户量已超过一百万,有一万多家公司和一千五百多所高校下载和使用了 Julia。此外,一些世界名校,如北京大学,MIT、Stanford 和 Berkeley 等,已经在教学中使用 Julia 语言。
我们可以从以下多个维度来体会下 Julia 编程语言社区目前的活跃度。
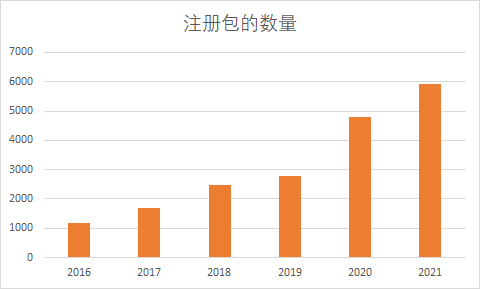
过去一年里,Julia 默认的注册表中新增了 1128 个包,累计达到了 5397 个。详细的信息可以前往JuliaHub.com查看,获取各个库下载信息的方法也已在官方论坛中公布。
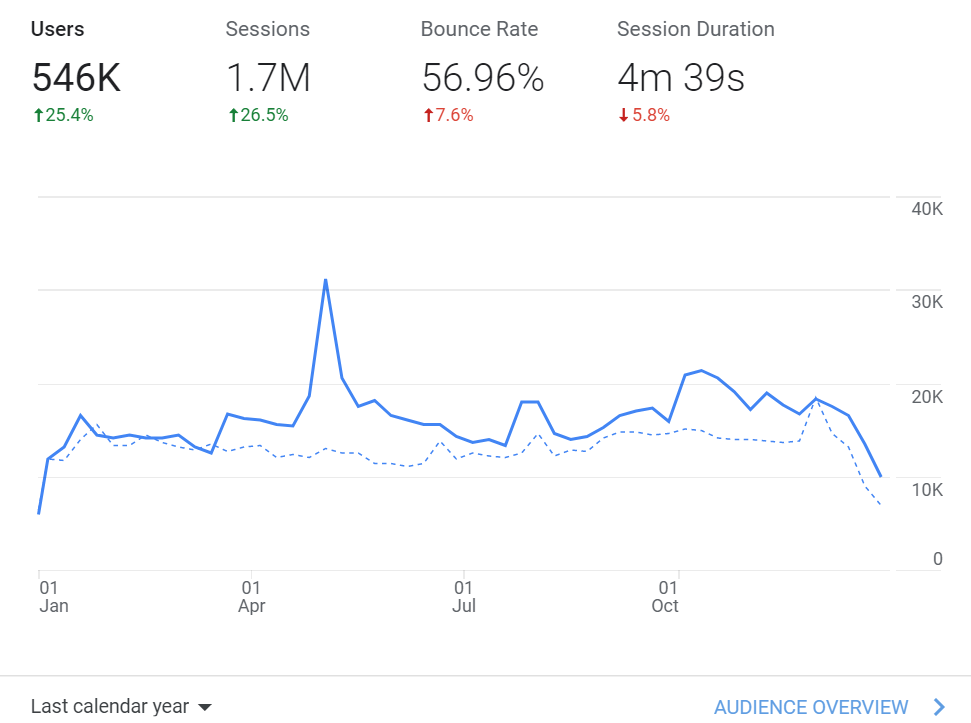
从 Julia 英文文档的访问量来看,过去一年里,用户流量同比增长了约 25%。
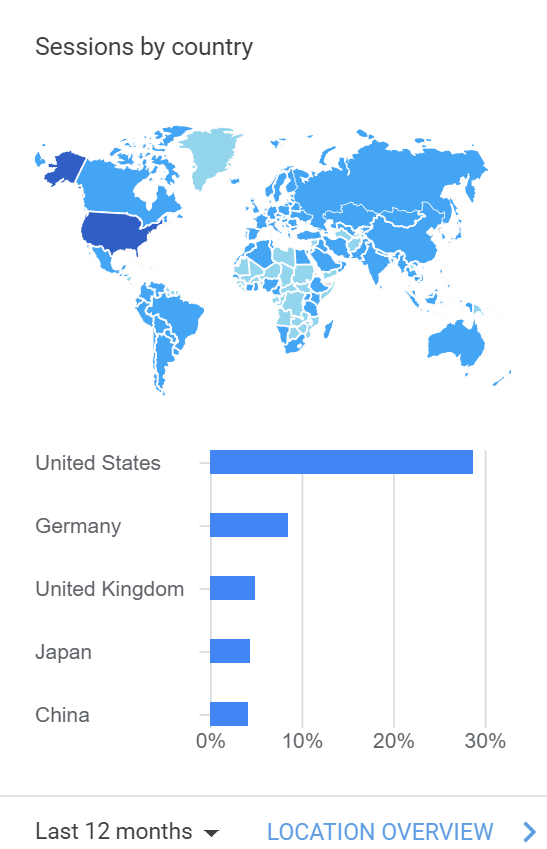
而从浏览文档的用户分布上来说,目前 Julia 语言的使用者还是以美国为主,德国和英国其次,日本和中国的用户量紧追其后。
不过由于目前Julia中文文档翻译的质量非常高,我们可以进一步看下中文文档访问量。
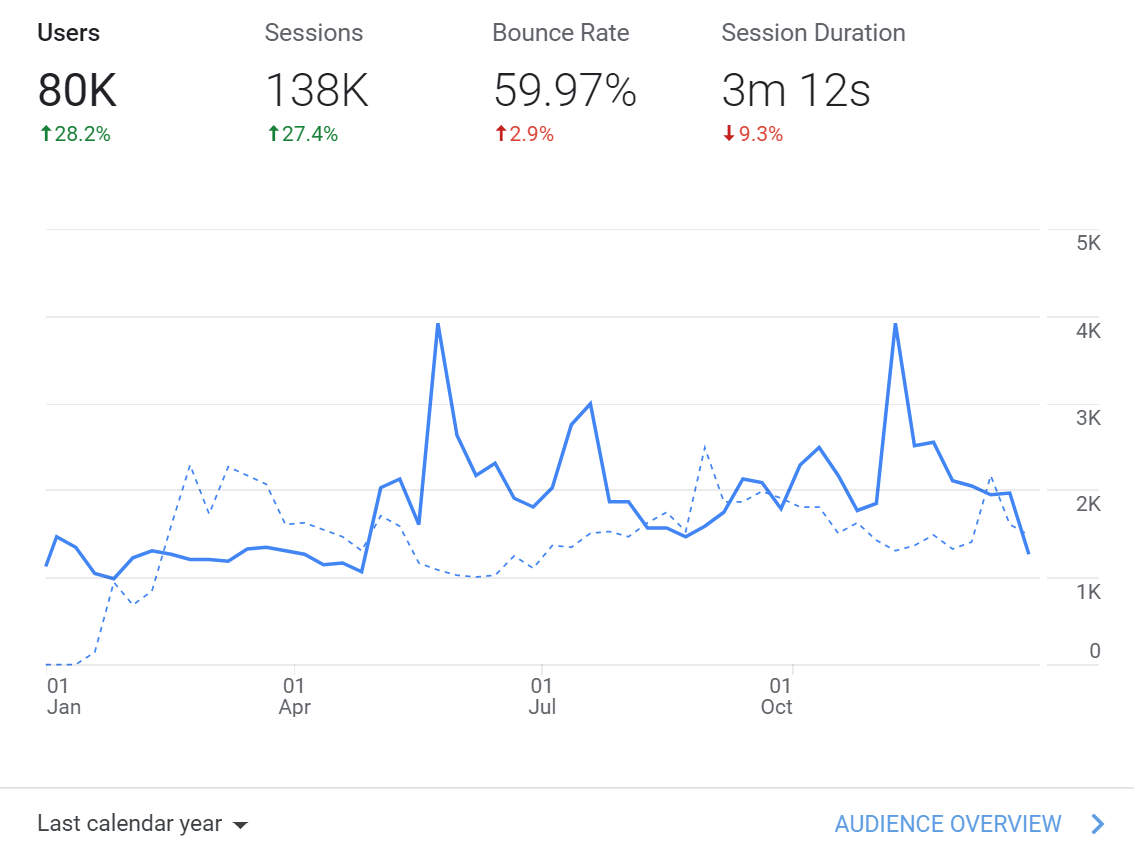
相比上一年,Julia 中文用户量增长了约 28%,实际占英文用户量的 14.6%左右,应该仅次于美国用户量。
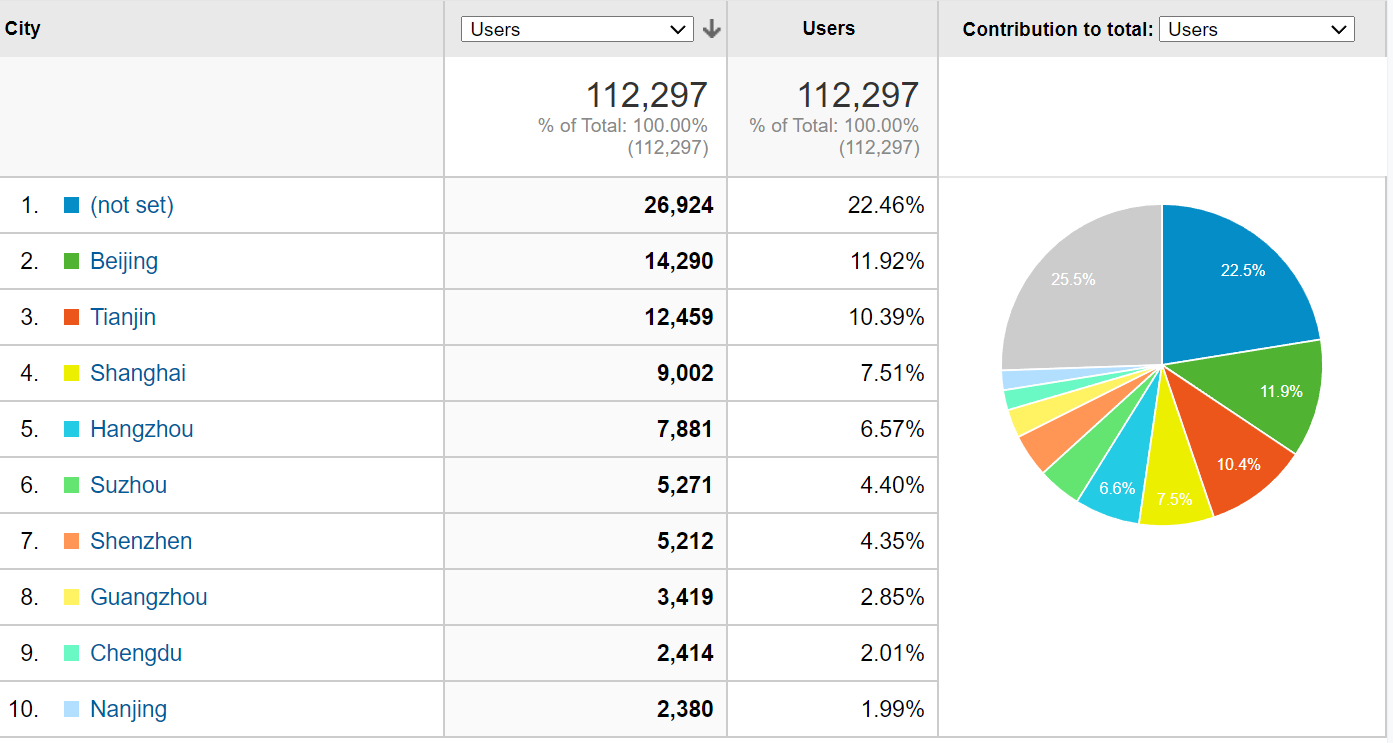
从国内用户量的分布情况来看,目前仍然以北京地区的用户为主。
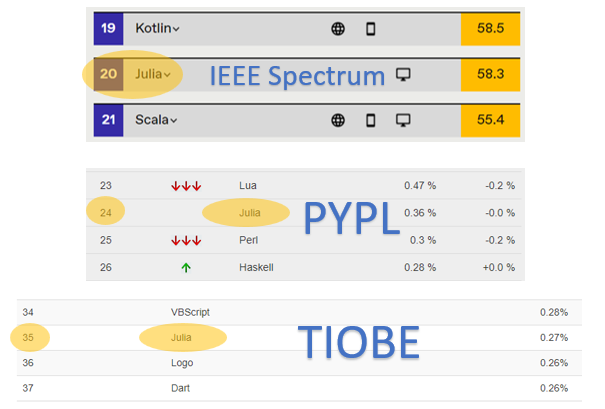
从各大编程排行榜来看,Julia 的整体排名稳中有升。 根据 IEEE Spectrum 的排名,今年 Julia 新入榜,位于第 20 位。 在 PYPL 的排名中,目前 Julia 位于第 24 位,相比去年同期变化不大,不过占比由去年的 0.26%增长至了 0.36%。而在本月最新的 TIOBE 排名中,Julia 位于 35 名,相较去年变化不大。
Julia 社区进展
过去一年,我们观察到 Julia 社区有一些重要的新进展,或将对 Julia 未来发展产生积极影响。
国内镜像站进一步增加
以往国内用户尝试使用 Julia 的最大障碍是,经常受网络环境影响,导致下载和安装失败。过去一年,国内对 Julia 镜像服务的支持进一步增加,目前已有以下六所国内高校提供镜像服务,来加速国内用户下载和安装 Julia 相关的库。
北京外国语大学 (https://mirrors.bfsu.edu.cn/julia)
中国科学技术大学 (https://mirrors.ustc.edu.cn/julia)
南方科技大学 (https://mirrors.sustech.edu.cn/julia)
用户仅需在运行 Julia 程序前,配置好 JULIA_PKG_SERVER 环境变量指向以上任一链接即可,详细信息可前往中文论坛相关讨论贴查阅。
此外,北京、上海和广州三地还分别部署有默认的服务器,即便用户没有配置镜像站,目前国内的下载和安装也会享受到加速效果。
Flux 加入 NumFocus

FluxML 社区于 12 月 1 日正式宣布挂靠在 NumFocus,能走到这一步,离不开整个 Julia 社区和开发者们的支持。
Flux 一直致力于提供一套简单、可扩展且高效的机器学习解决方案,借助可微分编程扩展到科学计算的各个领域。此次与 NumFocus 的合作将进一步壮大社区,吸引更多新的开发者参与到整个生态中来,同时有利于管理筹集到的资金用于接下来的一些项目,如自动微分相关的编译器方面的工具,以及更通用的 GPU 上的低精度运算等。
JuliaComputing 完成 A 轮融资

JuliaComputing 由 Julia 编程语言的创始人们于 2015 年创立,该公司主要以 JuliaHub 提供企业级计算解决方案。
近期公司的重心主要在提供一套现代化的建模和模拟工具,如用于药物模拟的 Pumas 框架,用于多物理模拟的 JuliaSim 以及用于电路仿真的 JuliaSPICE。其于今年 7 月完成的一笔 A 轮融资,在一定程度上打消了人们一直以来关于 Julia 商业化应用前景的疑虑。
Julia 在商业公司中更多落地
Julia 语言在商业公司也得到了进一步的应用,例如,冷原子方案的明星量子计算公司 QuEra Computing Inc 使用 Julia 构建他们的模拟器;RelationalAI 利用 Julia 来构建他们的网络服务和关系数据库;同元软件公司则开始使用 Julia 语言开发用于代替 MATLAB simulink 的软件,其产品已应用在中国航天相关的建模中,例如中国空间站;Pumas 则使用 Julia 构建了他们的临床药物研究套件,而基于 mRNA 的 Moderna 新冠疫苗也使用 Pumas 的服务完成临床药物的数据分析。其它未披露其产品细节但也在使用 Julia 的公司包括大家熟知的各个大公司(Google、AWS、华为等),也包括一众新兴的创业公司。Julia 在商业公司应用的相关生态(例如私有注册表、私有包管理、私有 CI/CD 等)也在日益完善。
Julia 核心功能演进
2021 年,Julia 发布了两个重要版本,分别是 Julia@v1.6 和 Julia@v1.7。此外,在 Julia@v1.7.0 于 11 月 30 日发布的同时,社区正式宣布 Julia@v1.6 为新的长期支持版(LTS)。Julia官方博客中详细介绍了 Julia@v1.7 的一些新特性,这里我们列出尤其值得关注的几点:
全新的多线程特性
在过去的几个 Julia 版本中,多线程相关更新一直是重点。
最新的 Julia@1.7 版本解决了许多运行时的竞态条件,优化了多线程之间任务的调度,同时让默认的随机数生成器对多线程更加友好,此外还新增了一类原子操作作为基本的语言特性。借助 @atomic 宏,现在可以更高效地以原子的方式去访问和更新可变结构体内的成员变量。在今年的JuliaCon上,Jameson Nash 给大家展示了如何使用该特性。
目前社区里已经有一系列库提供了线程安全的抽象,可以预见的是,未来会有越来越多的库使用该特性。
包管理的更新
在之前的版本中,如果 using 某个包时,这个包并没有在当前环境中提前安装好,就会直接报错,而新版的包管理工具会自动识别出该包是否已经注册,如果是的话,则会提示你是否要自动安装。
此外,新版的 Manifest.toml 文件相比之前的版本做了一个比较大的改动:所有包相关的信息放到了 [deps] 下,此外在最顶层新增了一个 julia_version 入口,该改动已经合并到了 Julia@v1.6.2 之后的版本中。
另一个值得关注的点是,新版的包管理器大幅提升了在 Windows 和分布式文件系统(尤其是 NFS)中的性能,这主要得益于在内存中将文件解压缩而非直接先解压文件。
对 Apple Silicon 的支持
Julia@v1.7 是首个能运行在 Apple Silicon 上的版本。不过需要注意的是,尽管官方的下载页面提供了相关的二进制安装文件,但对该平台的支持还仅处于 tier 3 (即仅处于实验性质,编译/测试有可能失败)。
BLAS/LAPACK:运行时的后端切换
在 Julia 1.7 之前,如果想要使用 MKL,需要编译一份新的 Julia 镜像再使用,这在一定程度上给使用者带来了不便。
Julia 1.7 中提供了一个 libblastrampoline (LBT)的弹性 BLAS/LAPACK 代理模块,允许用户在运行时动态地选择具体的调用后端。LBT 一方面提升了使用的便捷性(例如 MKL.jl 可以无需编译镜像直接使用了),另一方面也提供了 “从多个 BLAS 实现中调用最好的那一个” 这样的弹性调用机制。由于不需要完全替换现有 BLAS 的全部功能,这甚至为未来提供纯 Julia 的 BLAS 实现(例如基于 LoopVectorization 的 Octavian)提供了操作上的可能性。
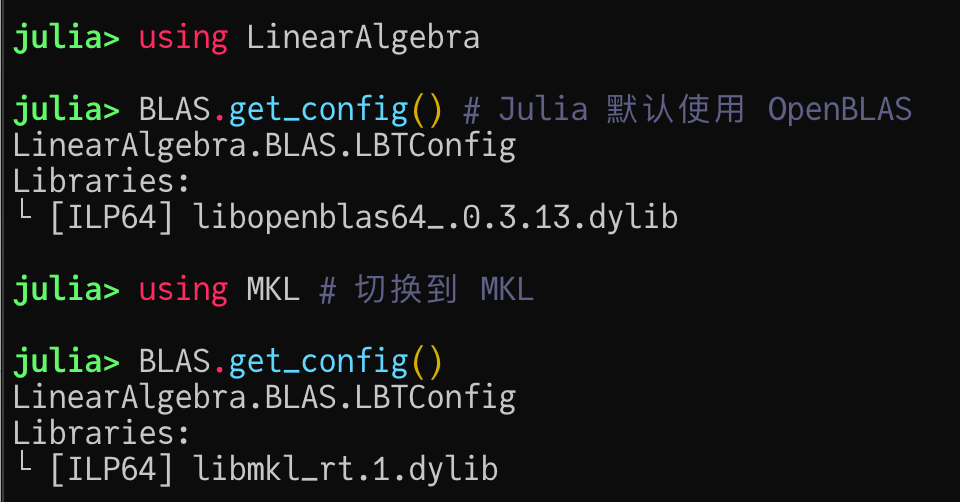
在 Julia 下可以尽情想象使用一门动态高级语言去写性能相当的 BLAS 库是一种什么样的体验。
编译延迟和运行时体积优化
由于 Julia 动态编译的特性,函数在第一次执行的时候需要触发一次编译操作,因此当使用一些比较大的工具箱(比如说 Plots、Makie)时,就会遇到比较漫长的等待环节。
下图是在 Intel 12900k 使用 Julia 1.7 得到的时间,在 Julia 1.5 里 using Plots 的时间大概是 7s,如果你的 CPU 主频比较低的话时间则会更久一些。
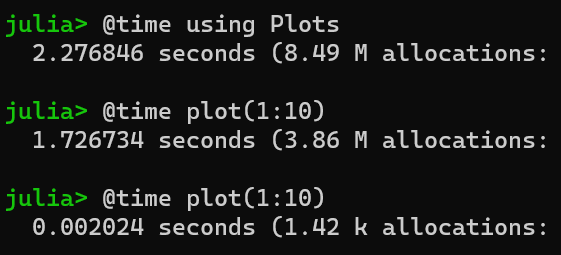
对于服务器程序或者需要跑很久的大型程序来说,编译延迟并不是很大的问题,但是对于绘图或者命令行程序来说,编译延迟势必会让 Julia 的使用体验变得比较差。
关于编译延迟,Julia 1.6 版本带来的最大变化有两个:一个是引入了并行的预编译机制从而可以利用到 CPU 的多核性能(但是在加载包的时候依然是单线程模式),另一个是支持通过手动调优来减少那些显著影响方法无效化(method invalidation)的代码,进而提高预编译结果的利用率。这些手段在一定程度上缓解了编译延迟的问题,但要做到更进一步的编译延迟优化,可能需要通过在 Julia 中引入更好的解释器或者类似于 JVM 的热点(hotspot)编译和多级执行的机制才能够解决问题。
由于将 LLVM 打包塞进了 Julia 运行时 (runtime),这就带来了使用 Julia 的另一个痛点:比较大的运行时体积。例如:仅仅只是打开 Julia 就需要占用大约 200M 的内存,编译一个最小的 hello world 程序也会生成超过 250M 的内容。
为了解决编译延迟和运行时体积过大的问题,正在开发中的 Julia 1.8 对编译器性能做了大量优化,通过将 LLVM 从 Julia 运行时中分离,使 Julia 可以完全运行在解释器模式下,从而产生体积更小的二进制文件。
在不久的将来,我们可以期待将部分有性能需求的代码被提前静态编译,而其余代码则运行在解释器下。这将大大降低编译延迟,并且使得部署 Julia 服务更加容易。
更好的类型推断、代码分析和检查
Julia 1.7 引入了大量与编译器有关的类型推断方面的优化,其主要作者是 Shuhei Kadowaki,这包括全新的 SORA(Scalar Replacement of Aggregates,)优化,大量的编译器代码类型稳定性提升等。这能够给 Julia 代码带来近乎免费的性能加速。一些过去已知的性能优化技巧(例如在判断 singleton 是否相等时使用 === 代替 == )也因此变得多余。
这些类型推断方面的优化另一方面也促进了静态代码检查工具 JET 的提升。目前我们可以通过手动调用 JET 来进行一些更高质量的代码类型检查和性能优化,未来它也许会被集成到 IDE 中。
Julia 生态演进
随着 Julia 语言逐步趋于稳定,我们在过去一年看到整个 Julia 生态发展出了非常丰富的细分领域。总的来说,在科学计算领域,越来越多的 Julia 细分领域项目变得成熟,并且赶上甚至超越基于其他语言的同类项目。在接下来这部分内容里,我们将尽力列举一些我们认为大部分 Julia 用户都比较感兴趣的领域:自动微分、for 循环优化、异构编程、编程理论、编辑器和绘图工具箱。我们也列举了一些我们所了解的领域:深度学习、动力系统。
但由于知识范围有限,依然存在一些 Julia 生态中的细分领域,我们很难给出概述性的回顾,例如:以 SciML 为核心的微分方程生态、以 JuMP 为代表的优化领域和以 Turing 为代表的概率编程,等等。我们知道很难全面覆盖 Julia 生态的全部细分领域,因此这里仅仅希望可以让大家了解 Julia 生态目前的主要发展趋势以及 Julia 目前发展得比较好的优势领域。
自动微分:依然非常活跃
Julia 在自动微分领域方面的探索一直处于比较前沿与活跃的状态:从有限差分 FiniteDiffs 和前向模式自动微分的 ForwardDiff,到基于 Julia IR 的源到源自动微分框架 Zygote,再到基于 LLVM IR 的支持多语言的自动微分框架 Enzyme,以及今年提出的支持更高效高阶微分生成的 Diffractor,还有刘金国博士基于可逆编程 (reversible programming) NiLang 打造的自动微分工具,这些不同基于设计理念但都非常优秀的自动微分框架的存在,实在很容易让人陷入选择困难症。
这背后很大程度上是因为,在 Julia 下不需要花费太多精力就可以实现一个性能比较不错的代码框架。除去这些 AD 框架之外, ChainRules 提出了一套可复用和可扩展的自动微分规则集和测试框架,让整个社区生态全面接入自动微分这件事情变得更加容易和可靠。在未来我们可以期望有更多的生态引入自动微分支持并从而迸发出一些全新的想法。
LoopVectorization: 高效的 for 循环优化
LoopVectorization 通过对 Julia 的 for 循环 IR 表达式进行开销分析来推断最优的 for 循环展开模式,从而实现了非常高效的代码生成。
下图是 LoopVectorization 对矩阵乘法实现进行优化后的实现,在这里 @turbo 可以看到,LoopVectorization 取得了与 MKL 接近的性能。

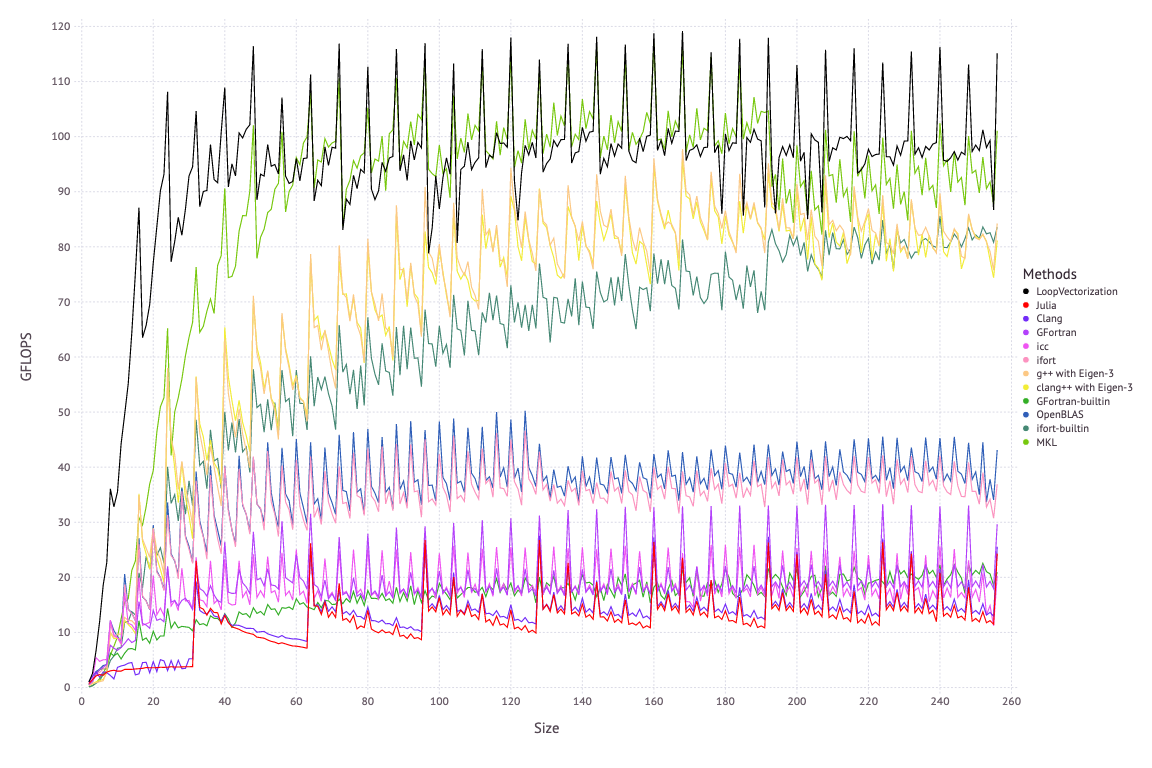
自从去年 LoopVectorization 发布以后,就收获了大量的社区关注和好评,同时其作者也被评为 JuliaCon 2020 社区最佳贡献者。今年 LoopVectorization 最大的新增功能是引入了对多线程的支持 @tturbo 。未来我们可以期待有更多的工具箱会借助 LoopVectorization 来更好地利用 CPU 的性能。
异构编程:CPU/GPU 和量子计算设备
利用 GPU 的计算能力通常有两种思路:一个是写向量化代码来调用已有的支持 GPU 的函数,另一个就是直接写 CUDA kernel 核函数(一般在 C/C++ 上进行)。由于 CUDA.jl 允许将 Julia 代码直接编译到 CUDA 设备上,这使我们可以在 Julia 上直接写 kernel 函数。还记得今年一度火遍朋友圈的 OpenAI triton 吗?它背后和 CUDA.jl 做的工作非常类似。
在 CUDA.jl 提供了直接编译核函数到 CUDA 设备上的能力之后,今年出现了一些围绕这一点展开的高级封装,例如: KernelAbstractions 和 ParallelStencil。他们提供了将手写的核函数根据需要编译到 CPU、GPU 等异构设备上的能力,从而避免了对不同计算设备写多个核函数的需要。
除去经典的 CPU/GPU 异构编程之外,在量子计算领域, Yao.jl 也提供了将 Julia 代码直接编译到量子设备上的能力。在今年 JuliaCN 组织的冬季会议上可以看到相关报告 (bilibili 链接)。
CUDA.jl 和 Yao.jl 的开发对 Julia 提出了一些额外的编译器插件方面的需求,也产生了 JuliaCompilerPlugins 的小组,一些相关的语言特性将在 Julia 1.8(开发版本)中得到支持。可以预料,未来会有更多将 Julia IR 作为中间表示的编译工具出现。
Julia 语言的相关编程理论形式化研究
形式化研究将有助于更好的理解和验证 Julia 程序,而 Julia 编程语言的相关理论研究也在稳步推进,继 2020 年十月对 Julia 的代际(world age)机制进行了研究(arxiv:2010.07516)和形式化(JULIETTE, a world age calculus)之后。来自东北大学和康奈尔大学的研究者形式化了 Julia 的类型稳定子集,并展示了类型稳定性如何产生编译器优化,并证明程序的正确性(arxiv:2109.01950)。这篇论文很好的解释了为什么 Julia 能够利用类型稳定的代码达到媲美传统静态语言的的性能。
编辑器:VSCODE、Jupyter、Pluto 为主流开发平台
在 VSCode 还没有成熟的时候,Julia 早期推荐使用的 IDE 是 Atom+Juno 的组合,后来随着 VSCode 的成熟以及 Atom 逐渐停止更新,2020 年 Sebastian Pfitzner 宣布 Juno 团队加入到 Julia for Visual Studio Code 的插件开发中来。
随着更多的 Juno 功能(如行内显示、变量工作区、调试器)在 VSCode 插件上得到完善,今年 Juno 已经基本完成它的历史使命,也在 Julia 的 IDE 列表中被移除。除此之外,在 VSCode 的文档列表中也添加了关于 Julia 语言的说明。
对于接触过数据科学的程序员来说, Jupyter Notebook 应该是比较常用的一个开发和实验环境:它提供了基于浏览器的 IDE,并且支持数十种编程语言。相比于传统 IDE 来说, Jupyter 提供了类似于 Office 套件的所见即所得的编程体验,从而大大降低了科研工作者的编程难度。Julia 通过 IJulia.jl 插件提供了 Julia 支持,并且一如既往的十分稳定,属于 Julia 社区最受欢迎的工具包之一。
相比于 Jupyter 项目来说, Pluto.jl 项目则是完全围绕 Julia 自身特性打造的一个 Jupyter 替代平台。基于对代码块的执行顺序进行依赖分析,它提供了一个自动执行代码并更新结果的编程体验。由于 Pluto 提供了比 Jupyter 更好的响应式编程体验,Pluto 在教学和演示场景下的使用体验非常出色,例如:MIT 的 Computational Thinking 这门课上使用 Pluto 进行教学并得到了非常好的效果。
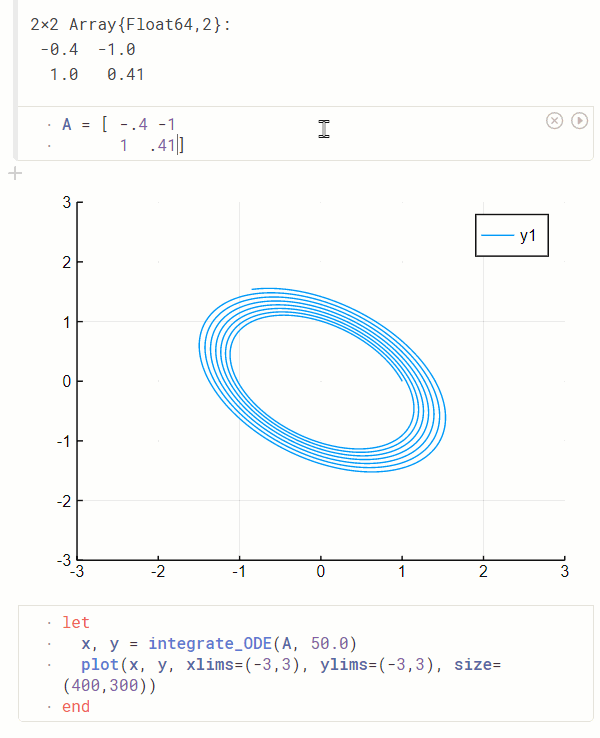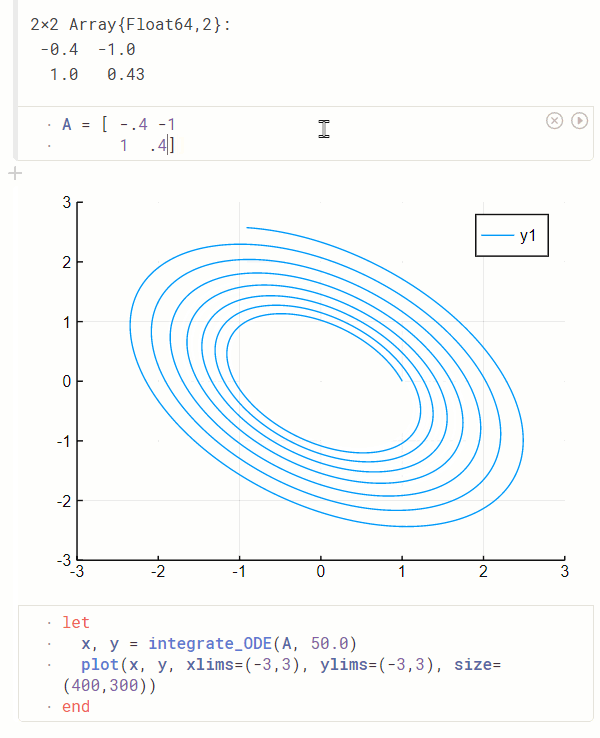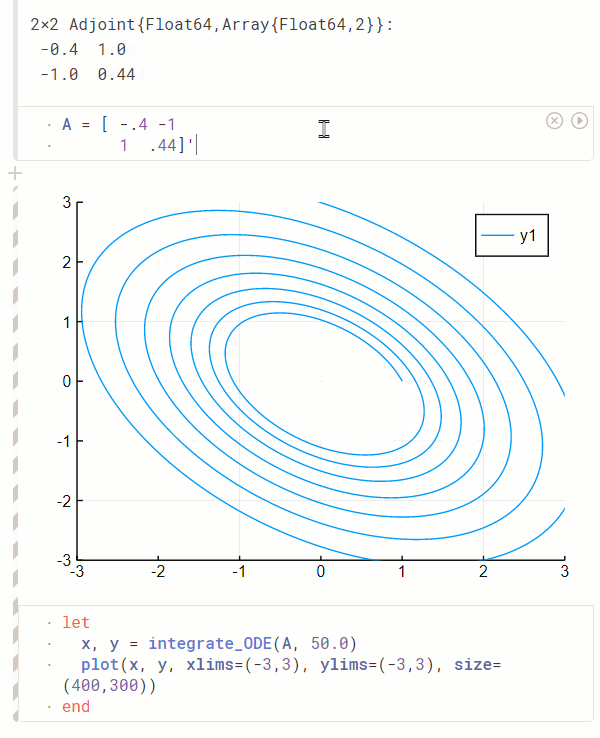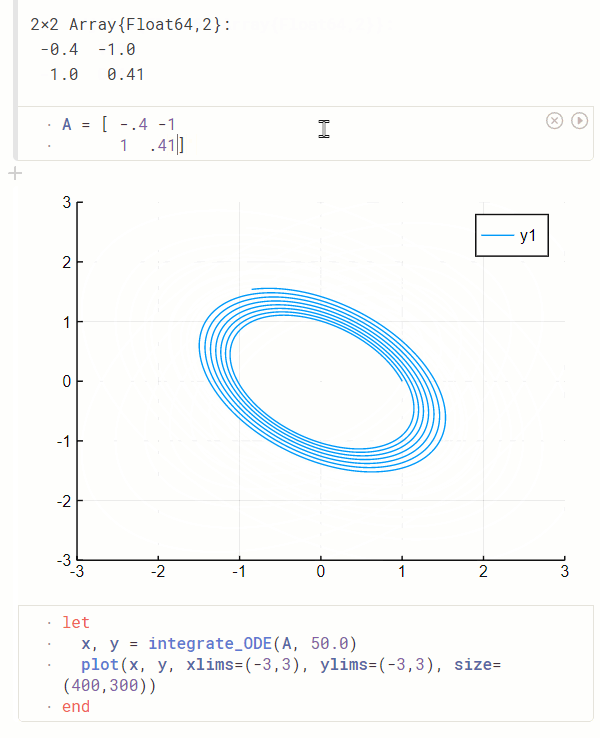
绘图工具箱:Makie 焕然一新, AlgebraOfGraphics 让人眼前一亮
Julia 绘图生态下比较稳定的主流工具箱中,GR.jl 自从去年切换到可以借助镜像进行分发的 jll artifacts 版本之后,在国内一直让人诟病的装包时由于网络原因构建失败的问题得到了妥善的解决。
一直以来,Julia 的主流绘图工具箱都是对其他语言绘图工具箱的封装,例如 GR.jl 基于 C 语言的 GR、PyPlot 基于 Python 下的 Matplotlib。 相比于这些绘图工具箱,基于纯 Julia 打造的 GPU 绘图库 Makie 提供了非常强的交互式绘图的支持,并且在今年合并了 OpenGL、Cairo 和 WebGL 的后端仓库,做了一次比较大的文档更新,整合了灵活的多图布局功能,这吸引了非常多社区开发者的贡献和关注。
受限于 Julia 本身的编译延迟问题,在 Makie 下进行首次绘图需要等待几分钟的编译时间,这一直是 Makie 的一个主要痛点,因此在使用体验上还不是非常理想。目前如果你需要日常使用 Makie,可以考虑利用 PackageCompiler.jl 提供的提前编译的 image 预先加载。随着越来越多的 Julia 开发者开始着手解决编译延迟问题,可以期望未来 Makie 会变得更易于使用。
相比于传统绘图工具箱的查 API 文档和例子的绘图模式,基于 Makie 的 AlgebraOfGraphics 对基本的图形元素(数据、坐标轴、图层)定义了加法和乘法运算,并由此提供了一个让人眼前一亮的基于图形代数的绘图 API。
深度学习:侧重学术探索,工业化程度不足
在深度学习领域,目前看下来 Julia 的主要发展有以下三条线路:1) 通过 PyCall 直接调用成熟的 Python 下深度学习生态;2)使用 Julia 重新实现一部分底层工具如 NNLib, Flux, Augmentor, DataLoaders, FastAI, Dagger+Flux 等基础深度学习模块;3)发展新的深度学习领域和工作模式,如可训练的微分方程求解器 NeuralOperators 、基于微分方程求解器的深度神经网络 DiffEqFlux 以及几何深度学习 GeometircFlux。
虽然短期内 Julia 的深度学习不会像 MindSpore、PyTorch 和 TensorFlow 这些成熟的深度学习框架那样易于使用和部署,但是在可定制性和扩展性方面, Julia 却始终可以在不丧失性能的前提下满足那些最前沿研究者的探索欲。
JuliaDynamics:非线性动力系统与混沌
今年 JuliaDynamics 中值得注意的最亮眼的工作大概要数 Springer Nature 下 “本科物理学讲义系列” 中关于非线性动力系统的入门级教材《Nonlinear Dynamics:A Concise Introduction Interlaced with Code》这本书的出版。
这本书包含了大量基于 DynamicalSystems.jl 的代码示例。与此同时,今年 DynamicalSystems 也顺势推出了 2.0 版本,其中包含了一些新的特性和算法,例如:用于熵值计算的工具箱,以及估计吸引域的全新算法(https://arxiv.org/abs/2110.04358)。关于教材和 DynamicalSystems 的更详细的信息可以参考在 discourse 上的总结。
除此之外, 作为 JuliaDynamics 的另一个主要工具箱,Agents 提供了基于代理 (agent) 的一种建模方法。在今年年初的时候发布了 4.0 版本,经过大量的功能更新之后,目前已经发布到 4.7 版本,并且也正在准备 5.0 版本的更新。根据其最新的文章(https://arxiv.org/pdf/2101.10072.pdf),无论是在性能、特性还是易用性等方面, Agents.jl 都已经超过了其他同类工具箱(如 Mesa、NetLogo、MASON)。
总结
引用公开课 MIT 6.172 《软件系统性能优化》中的一句导言:“性能就是计算领域的金钱” (performance is the currency of computation)。一方面人们永远不会嫌钱多,另一方面人们在足够有钱的时候也会说对钱不感兴趣之类的话。很多时候当我们说性能不重要,实际上是因为我们在享受前人的工作成果所带来的好处,然而一旦需要去探索新的计算领域(例如量子计算、自动微分、图计算)时,我们就被抛到了一个无人探索区域。想要在这个无人探索区域里走得更远,我们就不得不更高效地利用身边全部的资源:找对探索的方向,以及更高效地探索。
作为一门动态编译型语言,Julia 一方面给予我们像 Python 一样的开发效率,另一方面又给予我们像 C/C++ 一样的执行效率,因此吸引了大量优化算法、微分方程、自动微分、量子计算、机器学习等计算领域的研究者。目前 Julia 语言已经逐渐成熟和稳定,我们有理由相信未来随着 Julia 生态的进一步成熟,Julia 的优势能够更进一步地发挥出来。
最后再引用哲学家维特根斯坦在《逻辑哲学论》中的一句名言:“语言的边界就是世界的边界” (the limits of my language mean the limits of my world) 。很多时候我们会认为编程语言仅仅只是工具,一门编程语言能够做的事情在另一门编程语言下也一定能够做到,然后拒绝学习和使用其他的编程语言。但实际上这和自然语言非常类似:你只有深入学习一门语言,才能更好地了解这个语言所代表的民族文化和它背后的思想,就像不懂中文的人可能永远也无法真正理解儒家文化背后的思想。作为一门函数式编程语言,Julia 采用了与 C/C++/Python 这些主流语言全然不同的思维模式,当你深入去了解和使用它的时候,相信总能够给你带来一些额外的体会和收获。
既然现在 Julia 已经在稳步迈向主流编程语言了,你还在犹豫什么呢?
如果你对 Julia 的发展有其他观察和看法,欢迎在文末留言,或点击加入 InfoQ 写作平台话题讨论。后续,迷你书、专题将集合发布于 InfoQ 官网,快将 InfoQ 添加进收藏夹,精彩不错过。
我们还准备了 2021 年度技术盘点交流群,欢迎各位小伙伴进群讨论!





