
信息抽取是从文本数据中抽取特定信息的一种技术,命名实体识别(Named Entity Recognition, NER)是信息抽取的基础任务之一,其目标是抽取文本中具有基本语义的实体单元,在知识图谱构建、信息抽取、信息检索、机器翻译、智能问答等系统中都有广泛应用。基于监督学习的 NER 系统通常需要大规模的细粒度、高精度标注数据集,一旦数据标注质量下降,模型的表现也会急剧下降。利用不完全标注的数据进行 NER 系统的建立,越来越受到专家学者们的关注。
第九届国际自然语言处理与中文计算会议(NLPCC 2020)针对此业界难题,推出技术评测任务:Auto Information Extraction(AutoIE),即信息抽取系统的自动构建,任务旨在通过利用只有少量不完全标注的数据集来完成 NER 抽取系统的构建。本文将主要介绍本次比赛过程中使用的主体技术方案以及对应的评测结果。
背景介绍
得益于互联网发展和数字化进程,信息的丰富程度呈指数级爆炸增长,但同时也让我们陷入无法快速找到所需信息的困境中,信息抽取技术应运而生。信息抽取(Information Extraction,IE)就是指从自然语言文本中,抽取出特定信息,以及信息之间的相互关系,帮助我们将海量内容自动分类、提取和重构。这些特定信息通常包括实体(entity)、关系(relation)、事件(event)。例如从新闻中抽取时间、地点、关键人物,或者从技术文档中抽取产品名称、开发时间、性能指标等。能从自然语言中抽取用户感兴趣的事实信息,无论是在知识图谱、信息检索、问答系统还是在情感分析、文本挖掘中,信息抽取都有广泛应用。
目前,信息抽取的主流方案是靠数据驱动的机器学习方法,即在有监督、有足够多标注数据的场景下训练出适用的机器模型完成信息抽取。而信息抽取系统一般都是针对某一特定领域量身定做,根据业务需求人工标注相关数据集以供训练模型使用,例如从经济新闻中抽取新发行股票的相关信息,包括 “股票名称”、“股票价格”、“上市公司”、“募资金额”等等,就需要有大量已经标注好,包含上述信息的模板新闻进行训练,而“标注”这个过程需要纯人工来完成。也就是说,构建某一特定领域的信息抽取系统很大程度依赖于人工标注足够多的数据,这无疑使得信息抽取技术的人工成本急剧扩大,实施周期也随之拉长。
怎么减少模型对标注数据的依赖,如何自动化构建模型所需的数据集,以及对于不完全标注的数据集怎样利用等问题成为了攻克信息抽取难题的关键所在。本次比赛我们针对此类问题,构建了针对目标实体类型的信息抽取系统。本系统大大减少了模型对人工标注数据的依赖,符合业界实际需求。
任务场景描述
对于基于有监督学习的命名实体识别(NamedEntity Recognition, NER)的信息抽取系统,解决命名实体识别的领域自适应问题十分关键,而能够获取到目标领域的人工标注数据是最为理想的解决方法。为此,常用的方法包括使用半监督的方法,如 Bootstrapping 学习框架;选用更为通用的、领域无关的特征来训练模型;模型融合等。这些方法最终的目的都是想要在模型训练过程中,让模型学习到更多的目标领域的特征,从而提高模型在目标领域数据上的性能。
学习目标领域特征的方法有很多,其中,一种较为直接的方法是使用目标领域的不完全标注数据。在解决领域自适应问题时,我们通常拥有大量的目标领域未标注的数据,同时,还有其中一些数据的不完整的标注信息,这些不完整的标注数据其实也包含了目标领域的重要信息,因而如何利用这些不完整的标注信息也是一个非常值得研究的工作。
在本次 NLPCC-2020 AutoIE 任务中,主办方发布了优酷视频标题文本数据集,其中包含电视、人物和系列三类信息。训练数据集由不完整的标记语料库组成,其中的实体根据与给定实体列表匹配的字符串进行标记,标签数据样例如下图所示:

图 1.优酷视频标题数据集样例“实体漏标”样本数据如下:

图 2. 不完全标注数据样例
“不完全标注问题”主流解决方案
目前针对“未标注实体问题”的解决方案大致分为以下几种:
①AutoNER + Fuzzy CRF:通过自动抽取短语回标训练集[1];
②AutoNER + 自训练:通过多轮迭代伪标签进行自训练,达到自动降噪的目的[2];
③positive-unlabeled(PU)learning:为每个标签构建不同的二分类器,从而减轻噪声数据的影响[3];
④Partial CRF:拓展改进 CRF,使其可以绕过未标注实体进行训练[4]。
上述各类解决方案存在如下的一些缺陷:
方案①依赖于远程监督的质量,因而从本质上来讲,未标注实体问题仍然存在;方案②的多轮迭代自训练过程计算非常耗时;方案③中虽然为不同标签单独划分了数据,但是未标注的实体仍然会影响相应实体类型的分类器;方案④中在绕过未标注实体的同时,忽略了负样本的作用,只适用于含有非常少量漏标实体的高质量数据集。
技术方案
本次比赛我们使用的技术包括 Classifier-stacking、Word-merging Representation、PredictionMajority Voting (PMV)等,下面将会逐一介绍。
在我们的技术方案中,Classifier-stacking 算法被用来作为基础组件对数据集进行交叉推断,实现数据集的“修复”。并且我们融合了多种特定领域的预训练词向量来让我们的实体边界识别更加精准。同时我们在不同的预训练模型上进行对比实验,找出与任务最匹配的预训练模型,最终在集成学习的帮助下,将模型的潜力发挥到最大。
我们的技术方案相较于上一节提到的四大主流方案在以下几方面有了改进。一是采用 Classifier-stacking 算法将未标注实体问题从数据层面转移到算法层面,能减轻模型对高质量数据集的依赖性;二是针对性地使用特定领域预训练词向量对实体边界进行了一定的约束,改善了实体抽取的完整度。三是就比赛而言,我们用实验充分对比了不同预训练模型在当前数据集的表现异同,使我们的算法效果在本次比赛的具体场景下得到更大的发挥。
4.1 构造不完全数据集的方法探讨
对于不完全标注数据集的构造,大致可以分为三种:
①从完整标注语料随机去除一定量 word_level 的标注;
②从完整标注语料随机去除一定量 span_level 的标注;
③从完整标注语料随机去除一定量 span_level 的标注,并将所有 O 标签也去除。
其中,word_level 是指任意的“多字片段”,span_level 则是指的某个完整实体片段,具体含义可参考下图样例。
从实际应用场景来看,第 3 种做法更符合标注人员漏标场景的真实样本,因为首先大部分情况下的标注遗漏都会发生在实体层面,而非字的层面,因而第 1 种做法并不妥当;其次,在真实标注场景下,我们会将所有未被标注人员作为实体标注出来的 Token,统一作为 O 标签处理,因此对于 O 标签和遗漏实体,我们无法将其区分开来,所以方法 2 也不符合真实的不完全标注样本“生产”场景。
数据样例如下图所示,其中 A.1、A.2、A.3 分别为如上所述的三种数据构造方法:

图 3. 构造不完整标注的数据方法
4.2 Classifier-stacking 算法流程及要点
训练集通过 K-Fold 交叉验证的形式,K-1 与 K-2 分别训练标注模型进行交叉推断来“修复”数据集,然后用“修复”后的训练集训练出 final 模型,不断迭代上述过程,直到验证集效果达标。
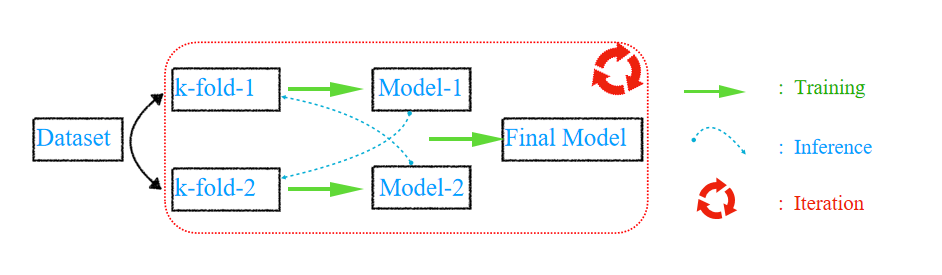
图 4.Classifier-stacking 算法流程图
在构造 Loss 函数时,我们在 CRF loss 函数的基础上进行改造,对于不完整标注的序列,应当给予所有可能的完整序列一个可训练权重矩阵 q,如下图所示:

图 5 不同的 Loss 构造方法
相较于原生 CRF 损失函数,以及平均分配权重的 Uniform 损失函数,可训练权重的做法使得模型在每次迭代训练中对每个标记为 O 的 Token 的候选标签给予不同的“关注度”,从而使数据的“修复过程”更快且更精准地完成。
对于以上几种不同 Loss 函数的标签权重可视化示意如下,颜色的深浅示意了权重的分布情况。
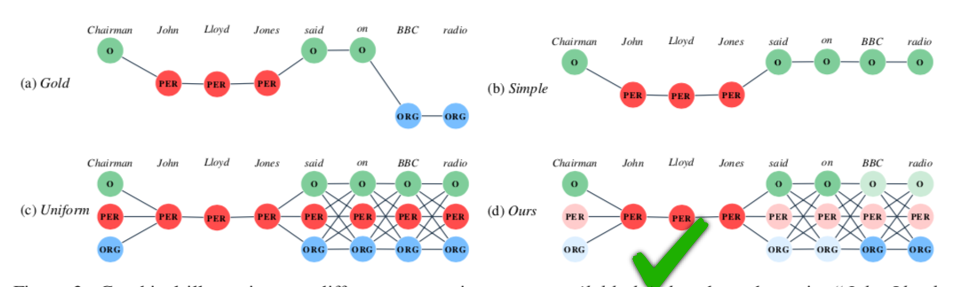
图 6. Loss 函数中可训练权重的可视化示意图
4.3 Word-merging Representation 方法的应用
预训练词向量[5,6]是许多神经语言模型中的标准组件,在命名实体识别中,引入词汇信息是提升中文 NER 指标的重要手段。引入词汇信息可以强化实体边界,特别是对于 span 较长的实体边界更加有效,并且也是一种数据增强的方式,引入词汇信息的增强方式对于小样本下的中文 NER 增益明显。
本次比赛我们从[7]获得具有不同性质的预训练向量来进行我们的实验,实验中采用了基于 Skip-Gramwith Negative Sampling (SGNS)技术训练的词向量,如下表所示。具体做法是将 Transformer-model 的输出 H 通过词汇融合层,做一次词汇增强表征。我们利用中文分词工具和词向量表征来获取每个样本的不同词汇层特征,并将得到的词汇特征对齐融入到原本的字符特征中,然后输入到线性层进行标签路径的映射。最后通过 CRF 学习标签路径的约束进一步提升模型的预测效果。
表 1. Word2vec / Skip-Gram with Negative Sampling (SGNS)
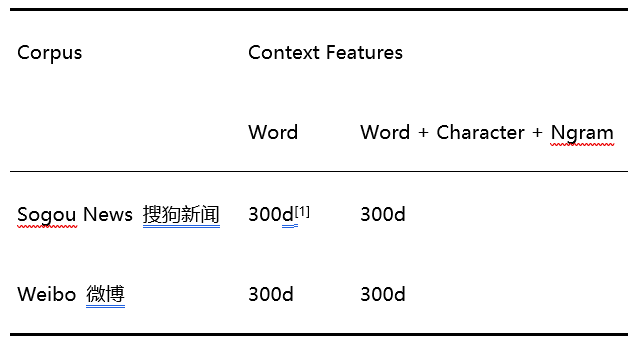
[1] The dimension of the Chinese Word Vectors is 300.
4.4 Prediction Majority Voting (PMV) 投票法的应用
在模型的预测阶段,我们采用了 Prediction Majority Voting (PMV) 投票法进行实体择优推断。我们尝试了两种不同的组合方式来利用多模型的输出,第一种方法很简单,对于 k 个模型,每个模型为句子中的每个单词中分配候选标签,并在所有 k 种预测结果中,选择获得多数票最多的实体作为最终预测输出。另一种方法是对于每一个 Token,将各个模型预测结果取平均值,得到唯一的标签序列输出。实验表明,在本次任务中,前一种策略相对而言对实体边界的查准率更高。
4.5 不同预训练模型的表现效果研究
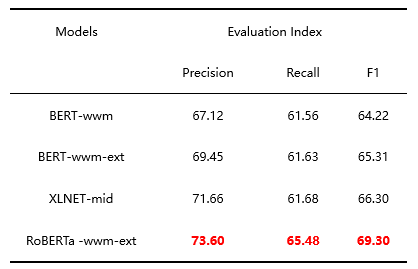
下表展示了我们利用不同预训练模型进行实验的效果对比,作为选取合适的预训练模型的参考依据。
从结果可以看出 BERT-wwm 模型的效果最差,显著低于使用更多预训练数据的 BERT-wwm-ext 模型。说明模型训练数据量大小直接影响了实体抽取的效果。从精确性、召回率和 F1 来看,RoBERTa -wwm-ext 模型都要显著高于其他模型。
鉴于预训练模型在体系结构和训练数据上的差异,我们可以通过结果做如下推测:首先,使用更多数据进行预训练,可能有助于提高模型性能。这可以解释为什么 BERT-wwm-ext 模型(训练数据为 5.4B Token)比 BERT-wwm 模型(训练数据为 0.4B Token)具有更好的性能。其次,去掉下一句预测任务(NSP)和增加训练步数(1M 步)的策略,导致 RoBERTa-wwm ext 模型性能具有显著优势,因为 RoBERTa-wwm ext 模型和 BERT-wwm ext 模型都是在包含大约 54 亿个 Token 的 Wikipedia 文本和扩展数据标记上训练的。
表 2.预训练模型的影响评估实验
为了比较这些预训练模型对训练集尺度变化的鲁棒性,我们进一步研究了在训练集尺度从 2000 个样本到 10000 个样本变化时,开发集上的性能曲线。总体趋势如下图所示。结果表明,训练集规模的减小对 RoBERTa-wwm-ext 模型的影响最小,也即在小样本数据集的场景下,我们倾向于选择表现更好的 RoBERTa-wwm-ext 模型来作为我们的预训练模型。
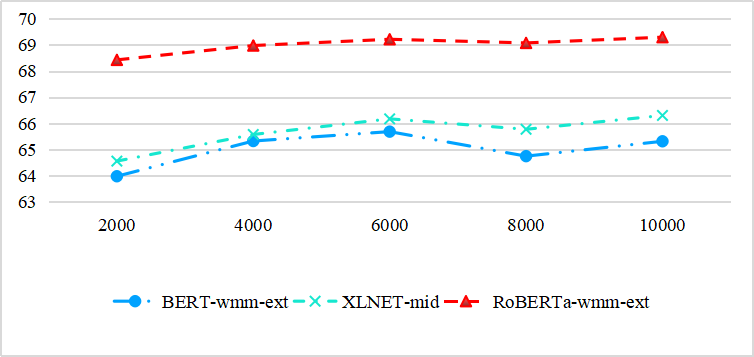
图 7. 预训练模型对训练数据集规模的鲁棒性研究实验
评测结果
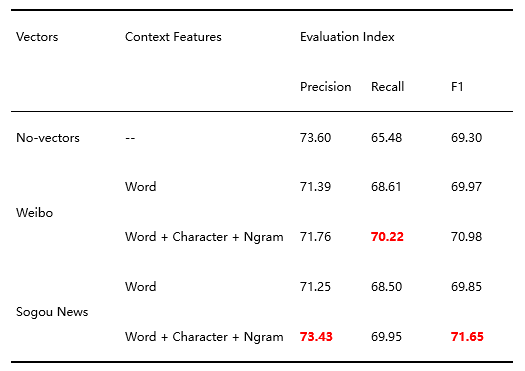
通过对本次比赛采用数据集的类型分析,我们选用了基于 Weibo 和 Sougou News 预料训练的词向量进行融合实验,实验结果如下表所示。在开发集上使用了 Sougou News 词向量的模型表现更优。
表 3.词向量融合表征实验
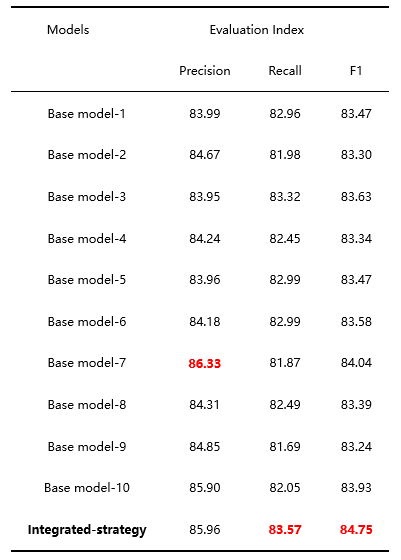
我们在最终测试集上使用了 k-fold(k=10)交叉验证,并利用 10 个基本模型进行特定策略的 PMV 投票,在 NLPCC-2020 AutoIE 排行榜上提交的最终结果 F1 为 84.75。
表 4.模型集成学习实验
总结
本次比赛是在解决不完全数据集 NER 的难题上的一次尝试,我们在 Classifier-stacking 技术路径之上,融合了特定领域词向量表征和 Prediction Majority Voting (PMV)等方法,为解决不完整标注数据场景下的信息抽取难题提供了有效且易于实施的解决方案。在信息抽取领域,本方案能够在一定程度上缓解监督模型对高质量标注数据的依赖,使得信息抽取更易于在工业界落地实施。
参考资料
[1] Shang J , Liu L , Gu X , et al.Learning Named Entity Tagger using Domain-Specific Dictionary[C]// Proceedingsof the 2018 Conference on Empirical Methods in Natural Language Processing.2018.
[2] Jie Z , Xie P , Lu W , et al.Better Modeling of Incomplete Annotations for Named Entity Recognition[C]//2019 Annual Conference of the North American Chapter of the Association forComputational Linguistics (NAACL). 2019.
[3] Peng M , Xing X , Zhang Q , etal. Distantly Supervised Named Entity Recognition using Positive-UnlabeledLearning[J]. 2019.
[4] Nooralahzadeh F , Lnning J T ,Vrelid L . Reinforcement-based denoising of distantly supervised NER withpartial annotation[C]// Proceedings of the 2nd Workshop on Deep LearningApproaches for Low-Resource NLP (DeepLo 2019). 2019.
[5] Tomas Mikolov, Ilya Sutskever,Kai Chen, Greg S Corrado, and Jeff Dean. 2013. Distributed representations ofwords and phrases and their compositionality. In NIPS.
[6] Jeffrey Pennington, RichardSocher, and Christopher D. Manning. 2014. Glove: Global vectors forwordrepresentation. In EMNLP.
[7] Shen Li, Zhe Zhao, Renfen Hu,Wensi Li, Tao Liu, Xiaoyong Du. 2018. Analogical Reasoning on ChineseMorphological and Semantic Relations. In ACL.
本文作者:宁星星 苏海波
本文转载自:百分点认知智能实验室(ID:baifendian_com)




