
GitHub 宣称,源代码搜索引擎将给业界带来颠覆性变革。
GitHub 上可供搜索的代码浩如烟海,全球代码仓库已经超过 2 亿,并且这些代码不是静态的:它在不断变化,这就给代码搜索引擎带来了相当大的挑战。
上线 15 年来,GitHub 一直努力给大家提供一个好用的代码搜索引擎,但一直不能如愿。这两年,GitHub 用 Rust 从头开始构建了自己的搜索引擎,专门用于代码搜索领域,并且自发布后已经极大地改善了该平台的代码搜索能力。
GitHub 从头构建代码搜索引擎的动机
搜索是工程师最常用的功能之一,谷歌内部曾对工程师做一次调研,发现平均每位工程师每天会进行 5.3 次代码搜索会话 (session),执行 12 个代码搜索请求。
对于 GitHub 这个用户已经达到一亿的代码托管平台来说,具备一个性能良好的搜索引擎尤其重要。然而 GitHub 自身的代码搜索引擎一度被用户吐槽“形同虚设”,连 GitHub 工程师 Timothy Clem 自己都吐槽说“用户体验糟糕”。在这种情况下,一些开发者会使用额外的工具查找代码,比如https://grep.app/或https://sourcegraph.com/search。
实际上,GitHub 在这十几年中一直在努力改进其搜索引擎,第一版搜索引擎通过将所有公共文档索引到 Solr 实例中来工作。对于公共存储库,当时看起来“一切都挺好”,但大型私有存储库仍然无法搜索。
到 2010 年,搜索领域出现了相当大的动荡,Solr 作为一个子项目加入了 Lucene,而 Elasticsearch 作为一种在 Lucene 之上构建和扩展的好方法逐渐兴起。在 2013 年初,GitHub 推出了由 Elasticsearch 集群支持的全新代码搜索,整合了公共和私有存储库的搜索体验并更新了设计。
“当我们第一次部署 Elasticsearch 时,花了几个月的时间来索引 GitHub 上的所有代码,当时大约有 800 万个存储库,平均每秒能响应 5 个搜索请求。”
因为运营规模巨大,在发布后的几天或几周内,GitHub 就马上经历了第一次代码搜索中断......
再加上代码库的不断增加,“代码搜索是迄今为止我们运营的最大集群,自发布以来,它的规模又增长了 20-40 倍”,该公司发现现有技术的正常运行已经越来越难以维持,“从 Solr 到 Elasticsearch,我们尝试用各种通用文本搜索产品来支持代码搜索,但效果都不好。除用户体验糟糕之外,托管成本还非常昂贵,而且索引速度也很慢。”
他们意识到,代码搜索与一般文本搜索有着很大的区别,毕竟代码是写给机器来理解的,需要利用代码之间的结构和相关性,并且还需要支持正则表达式进行搜索。
“归根结底,现成的东西都不能满足我们的需求,所以我们放弃了开源方案,从头开始构建了搜索引擎。”
基于 Rust 语言的搜索引擎
从 2020 年开始,GitHub 开始全力以赴构建自定义搜索引擎。这款代码搜索引擎被命名为 Blackbird,用 Rust 编写,它创建并增量维护一个由 Git blob 对象 ID 分片的代码搜索索引。增量的形式能节省大量存储空间,并保证了跨分片的均匀负载分布。同时支持对文档内容进行正则表达式搜索,还可以捕获额外的元数据,例如它还维护符号定义的索引。最终 Blackbird 满足了大家的性能目标:速度非常快,索引也非常紧凑,重量约为(去重)语料库大小的 1/3。
本周一,Clem 发布了一篇博文,讲述了 Blackbird 的工作原理,深入探讨了这个可对四分之一代码仓库进行搜索的新技术。
Blackbird 目前可对近 4500 万个 GitHub 代码仓库进行访问,涵盖的代码总体量达 115 TB、涉及 155 亿份文档。要在这么多行代码之间切换,单靠 grep(类 Unix 系统上用于搜索文本数据的常用命令行工具)显然是远远不够的。
Clem 解释道,在 8 核英特尔 CPU 上,通过 ripgrep 对内存内的 13 GB 文件执行详尽的正则表达式查询大约需要 2.769 秒,相当于 0.6 GB/秒/核心。
“我们很快意识到,面对 GitHub 所拥有的大量数据来说,用 grep 的办法根本行不通。代码搜索实际运行在每节点 64 核、总计 32 节点的集群之上。即使我们设法将 115 TB 的代码全放进内存并实现了完美并行查询,那 2048 个 CPU 也要饱和运行 96 秒才能完成一次查询!在此期间,只有当前查询可以运行,其他操作全都得排队。”
每秒只能执行 0.01 次查询,这就直接给 grep 判了死刑。
于是,GitHub 决定将大部分工作预加载至预先计算出的搜索索引当中,这些索引本质上属于键值对映射。如此一来,我们就能使用数字键(而非文本字符串)来搜索编程语言或单词序列等文档特征,从而大大降低对计算资源的需求。
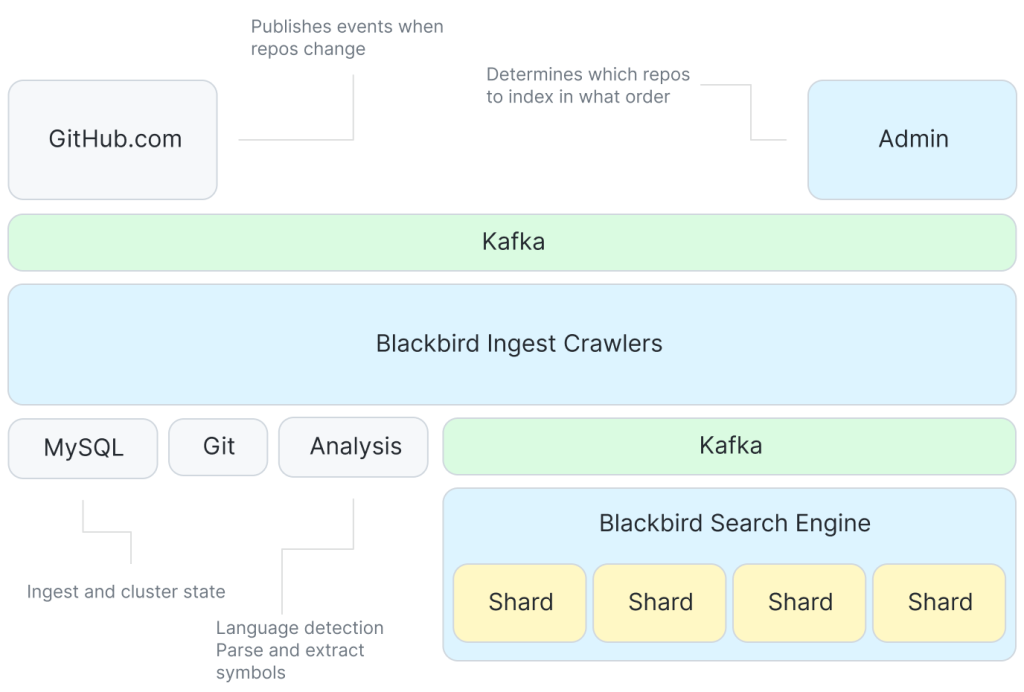
尽管如此,这些索引还是太大、远远超出了内存容量。因此 GitHub 又为需要访问的各个索引构建了迭代器。根据 Clem 的介绍,这些迭代器会延迟返回经过排序的文档 ID,而各 ID 所代表的正是关联文档的级别和满足的查询条件。
为了保持搜索索引的可管理性,GitHub 采取分片方法——使用 Git 的内容可寻址哈希 schema 与增量编码将数据拆分成多个部分,借此存储数据差异(增量)以减少需要抓取的数据和元数据。考虑到 GitHub 上存放着大量冗余数据(例如不同 fork),这套方案确实效果拔群,一举通过重复数据删除技术将 115 TB 数据缩减至 25 TB。
最终系统的运行速度要远超 grep,将最初可怜的每秒 0.01 次查询提升至每秒 640 次查询。此外,索引的执行速度可达到每秒约 12 万个文档,所以处理全部 155 亿个文档需要约 36 个小时。而由于增量(变更)索引减少了所需抓取的文档数量,重新索引只需要 18 个小时。
GitHub Code Search 目前处于 beta 测试阶段,感兴趣的朋友可以点击此处前往体验(https://github.com/features/code-search)。
参考链接:
https://github.blog/2021-12-15-a-brief-history-of-code-search-at-github/
https://www.theregister.com/2023/02/07/github_code_search/?td=rt-3a
https://github.blog/2023-02-06-the-technology-behind-githubs-new-code-search/




