
本文整理自 Pulsar Summit Asia 2022 上腾讯互娱 GDP 微服务开发平台网关技术负责人江烁的演讲《打通 Apache Pulsar 与 Envoy,构建高效游戏 OTO 营销平台实践》。本文将介绍介绍腾讯互娱利用 Apache Pulsar 和 Envoy 运营游戏 OTO 营销平台的经验。
腾讯互动娱乐旗下涵盖腾讯游戏、腾讯文学、腾讯动漫等多个互动娱乐业务平台。其中,腾讯游戏注册用户超过 8 亿。2022 年 6 月,腾讯游戏旗下王者荣耀日活跃用户数量超过 1 亿 6 千万,和平精英日活跃用户数量超过 8 千万。
OTO 是 One-Time Offer 的缩写,是从商品购物中衍生出来的术语。它指的是顾客下单过程中出现一次性销售机会的产品。比如消费者付款时销售人员会提醒顾客,只要加一点费用就可以换购很划算的商品,错过就没有机会。OTO 在游戏场景中的应用是在一定场景下为玩家提供限时优惠礼包,或推荐比较适合用户的任务。这就需要系统能够及时为用户产生个性化的内容,有效触达用户,造成紧迫感,使更多用户能够参与活动。
传统架构及其问题
为实现上述目标,腾讯互娱早期基于传统上实时数据处理的系统经验搭建了基于 Kafka + Flink 的 OTO 干预系统:
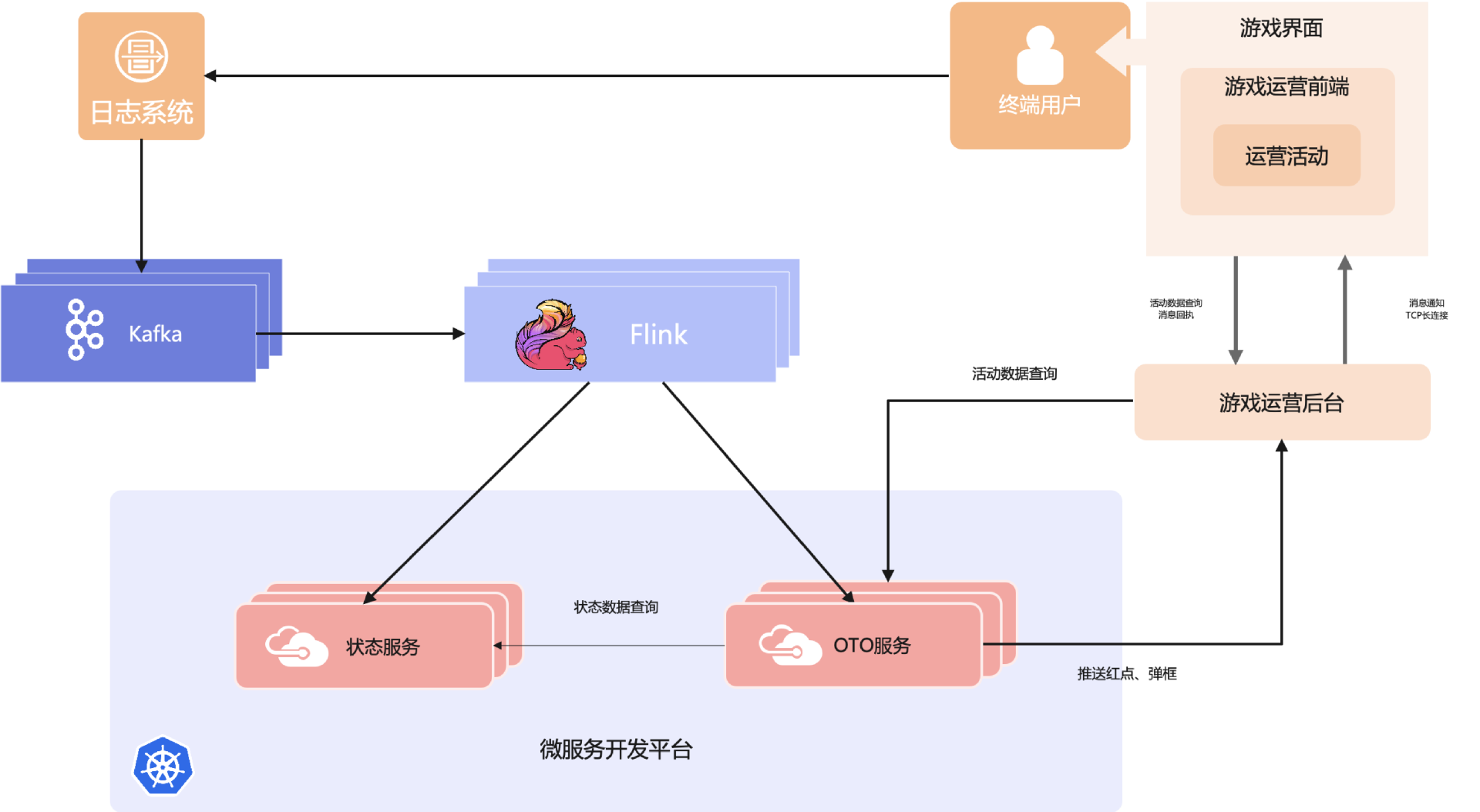
活动中的用户游戏日志接入到 Kafka,Flink 实时消费 Kafka 中的消息,分发到状态服务和 OTO 服务。状态服务记录用户的累积状态,如是否参与过活动、累积输了多少次等数据,供 OTO 服务查询。OTO 服务包含推荐模块和任务系统模块,根据用户日志和状态判断用户是否触发活动,再通过推荐模块生成个性化任务,以红点/弹窗方式通过游戏运营后台推送到终端用户 App 的运营活动模块,为用户展示相应的活动参与界面。
上述架构分为两大部分,分别为 Kafka + Flink 的大数据处理套件,和以微服务方式部署在 K8s 上的微服务开发平台。后者是以云原生理念搭建的开发平台,方便开发和运维。
系统运营上线一段时间后团队发现了 OTO 营销活动具有以下特点:
活动多,效果好的活动经常被复制到其他业务中;
活动具有周期性,如双周、一个月、几个月和长线活动,还有很多活动会复开,活动上下线频繁;
活动期间流量不稳定,每日各时段流量差距较大,高峰时段流量是低谷段的十几倍;
不同业务和活动的量级不一样,差距较大。
OTO 服务通过基于 Kubernetes 的 GDP(游戏微服务开发平台),可以快速部署、自动扩缩容和资源回收复用。但这里 Kafka + Flink 的架构存在一些问题:
Kafka 的消费并行度基于 Partition,如果应用直接消费 Kafka Topic,并行度就会受此限制。例如 Kafka 只有三个分区,那么只有三个 Pod 在消费数据,其他 Pod 都在空转。因此团队加入了 Flink 来分发,解决了并行度问题。但如果消息量变大,要调整 Kafka 的分区数是一件复杂的事情,会造成集群重平衡。而且引入 Flink 还带来了一些问题。

引入 Flink 带来的问题主要是 Flink 的作业资源调整需要重启作业,对实时在线业务有着较大影响。在 OTO 场景中 Flink 只用来消费事件、调用下游微服务,为此专设集群比较浪费。出海时还需要考虑兼容不同云端 Flink 的接口,作业调度比较复杂,需要专设运维人员协助开发,增加额外成本。
触达失败率较高。原因有多个:
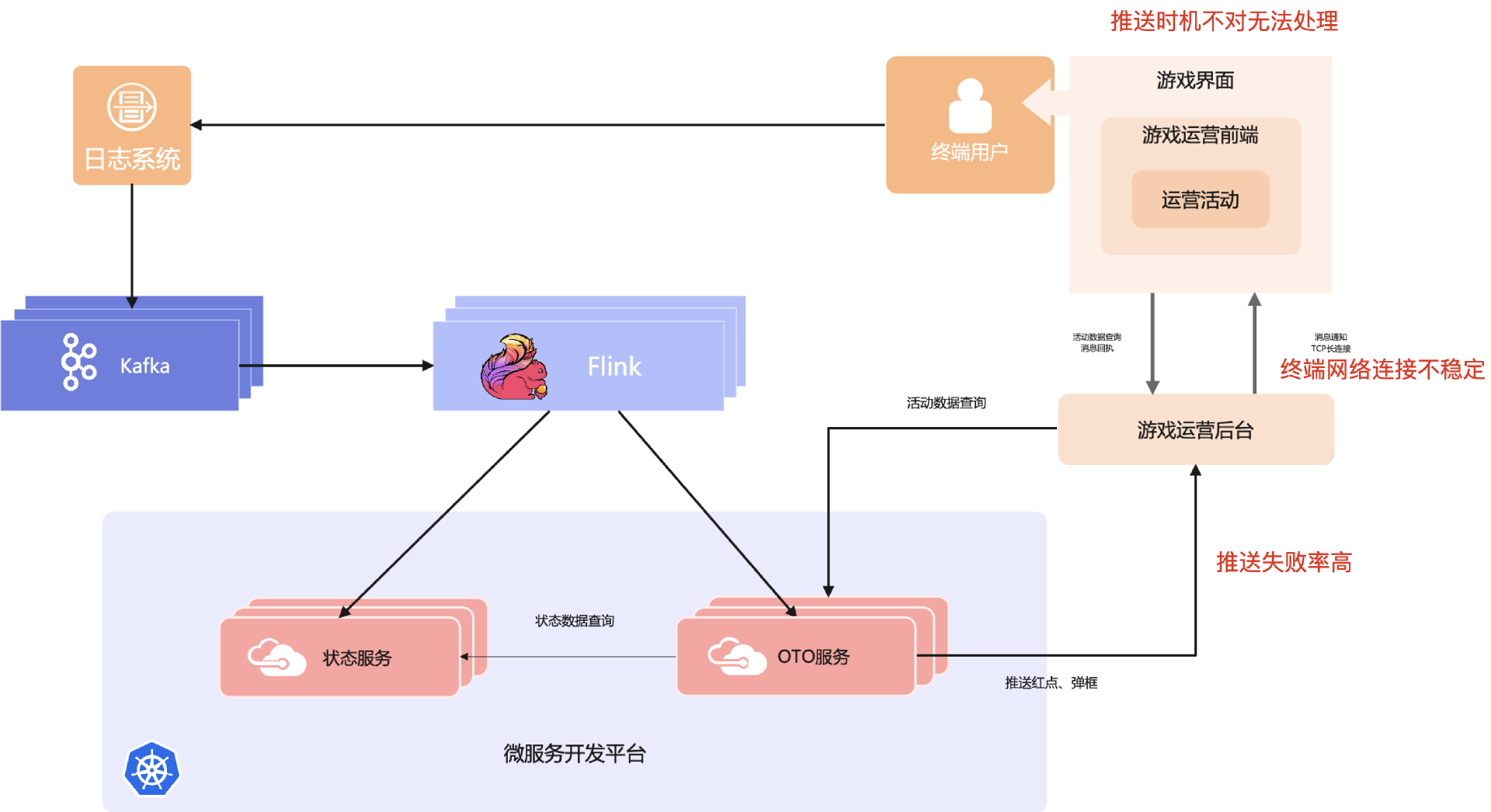
调用推送接口时可能会失败,例如用户对局结束马上推送。很多在对局期间为了保障用户体验,会停止其他模块,在对局完成后重新拉起。但我们经常处理完对局相关事宜后就会推送,此时推送链接还未建立。
终端网络不稳定会造成推送消息丢失。
即时推送消息到达客户端,也存在游戏不在安全区(如尚在对决结算中)而无法弹窗,导致推送失败。总体来看触达率只有 60%。
业务与活动的资源需要隔离。一方面需要通过隔离防止不同业务和活动互相影响,另一方面需要对业务进行独立成本核算。采用共享集群会导致费用结算复杂,集群太多又导致运维管理成本过高,活动上下线资源管理困难。
云原生架构与网关扩展
为解决上述问题,腾讯互娱团队做了诸多优化。
优化一:用 Pulsar 代替 Kafka
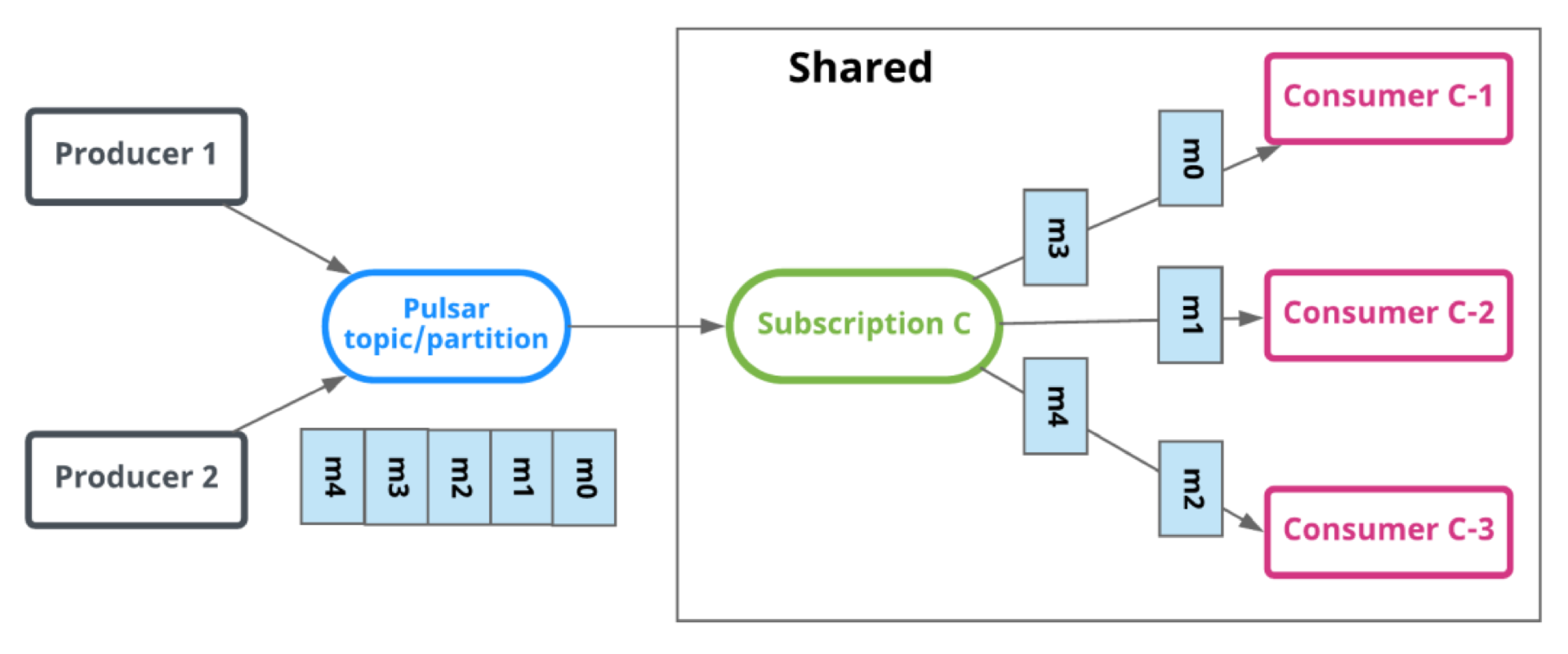
在此不赘述 Pulsar 和 Kafka 对比,只针对我们的场景介绍一些用 Pulsar 代替 Kafka 的好处。Pulsar 提供了 Shared 消费模式,并发量不受 Partition 限制。这样消费服务完全不需要关心分区数,后端服务需要时即可调整副本数,直接提高了并发度,增强了处理能力。再配合 K8s 的 HPA 即可自动根据后端性能指标扩缩容,极大提升资源利用率。
Pulsar 还支持对单个消息独立 Ack,可以很好地防止重复消费。Pulsar 还提供 Key_Shared 消费模式,在某些并发控制场景非常方便。
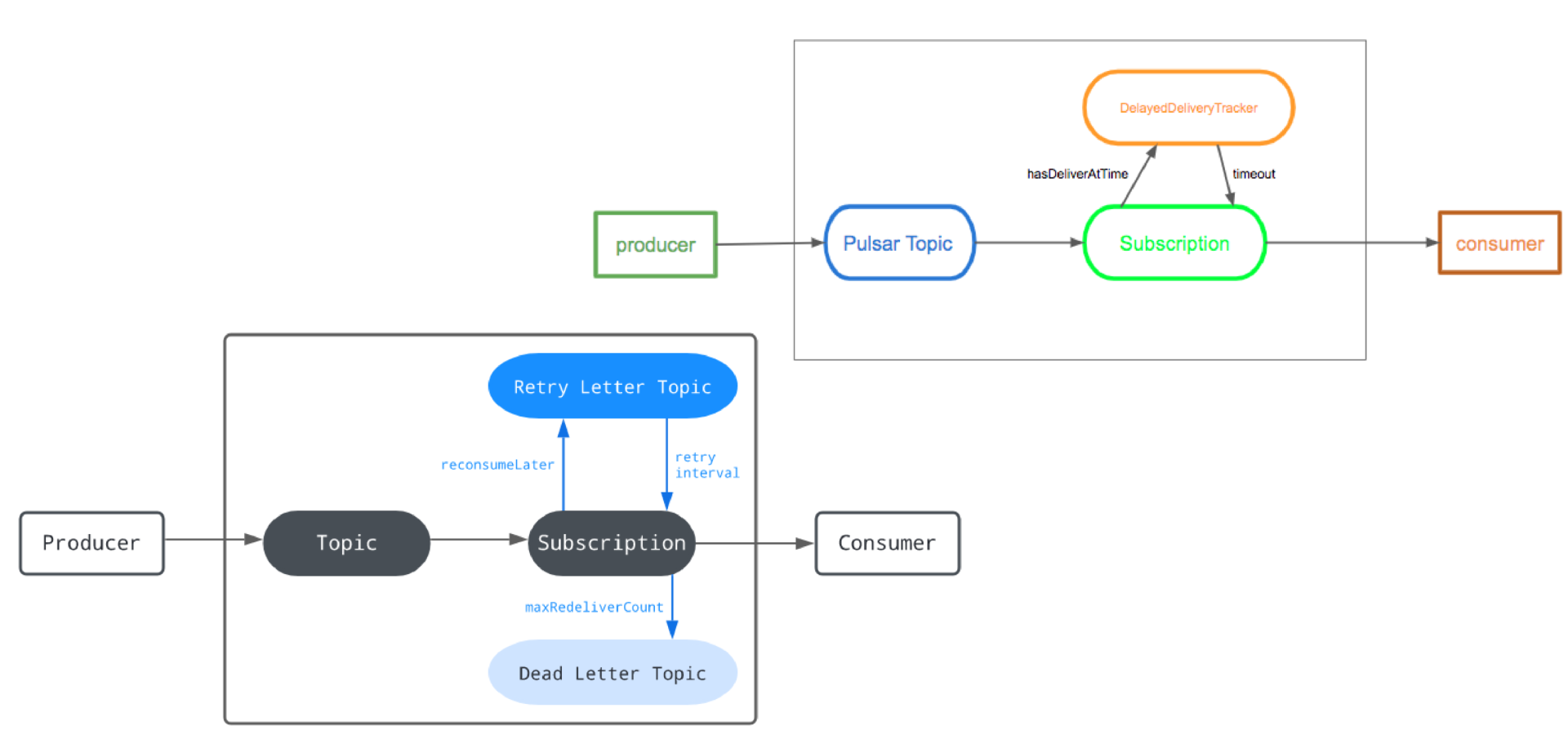
Pulsar 还提供了延迟处理能力,包括延迟投递和延迟重试。使用这两个能力可以轻松解决触达率较低的问题。
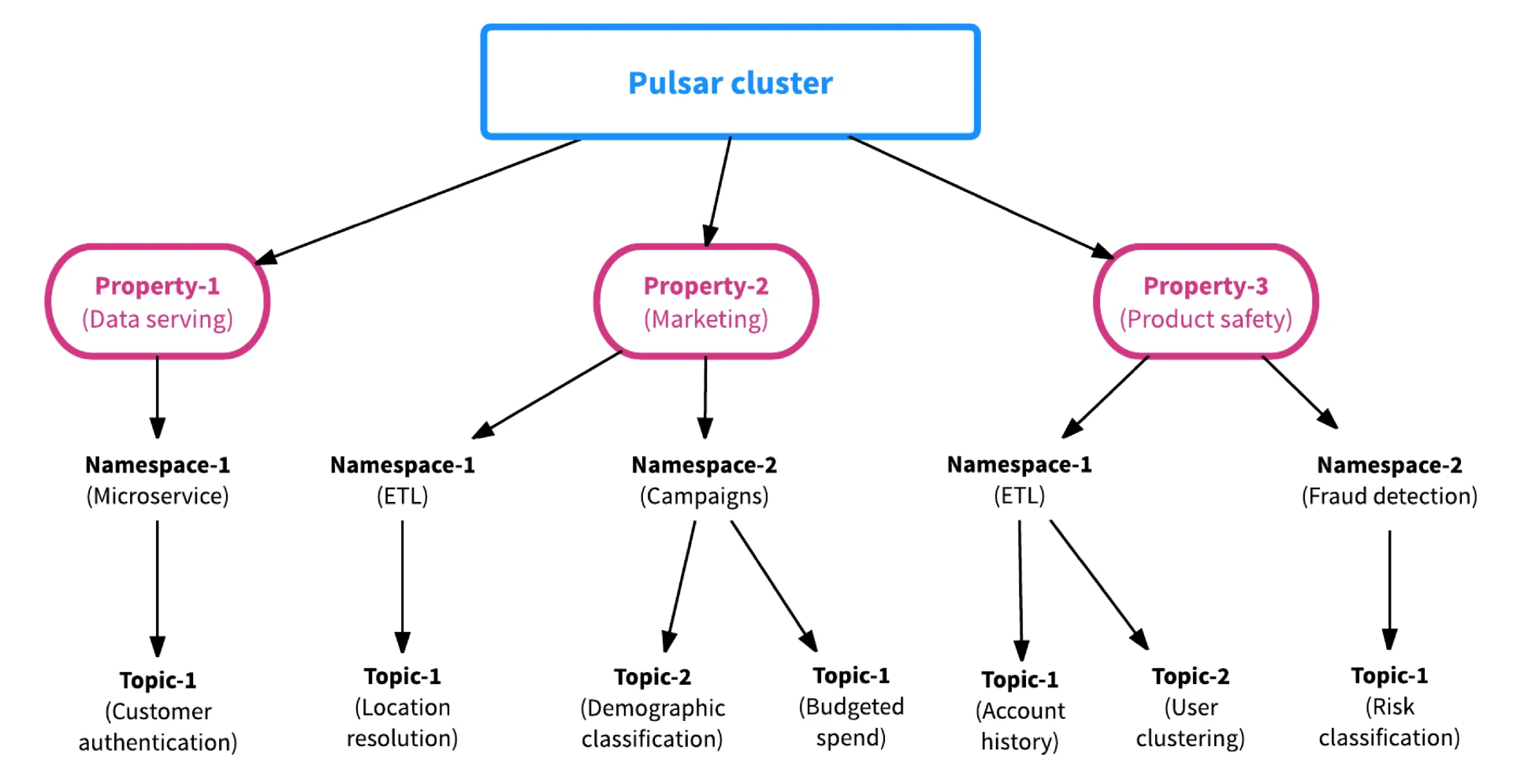
Pulsar 还提供了多租户能力,一个集群就可以解决多业务/活动资源隔离和 SLA 的需求,大大降低了运营压力,方便业务成本核算。
优化二:采用云原生方案代替 Flink
使用 Pulsar 代替 Kafka 后无需再用 Flink 做并发分发,可以去掉 Flink。为兼容之前的服务,又考虑到后续的微服务平台灵活性,简化其他微服务的开发工作,团队在平台的 Envoy 网关上扩展了几个特性,使 Envoy 可以处理 Pulsar 协议。结合 Envoy 已有的灵活规则配置和大量功能插件,可以配置出很多便利功能。
云原生架构
经过上述优化,新的系统云原生架构如下:
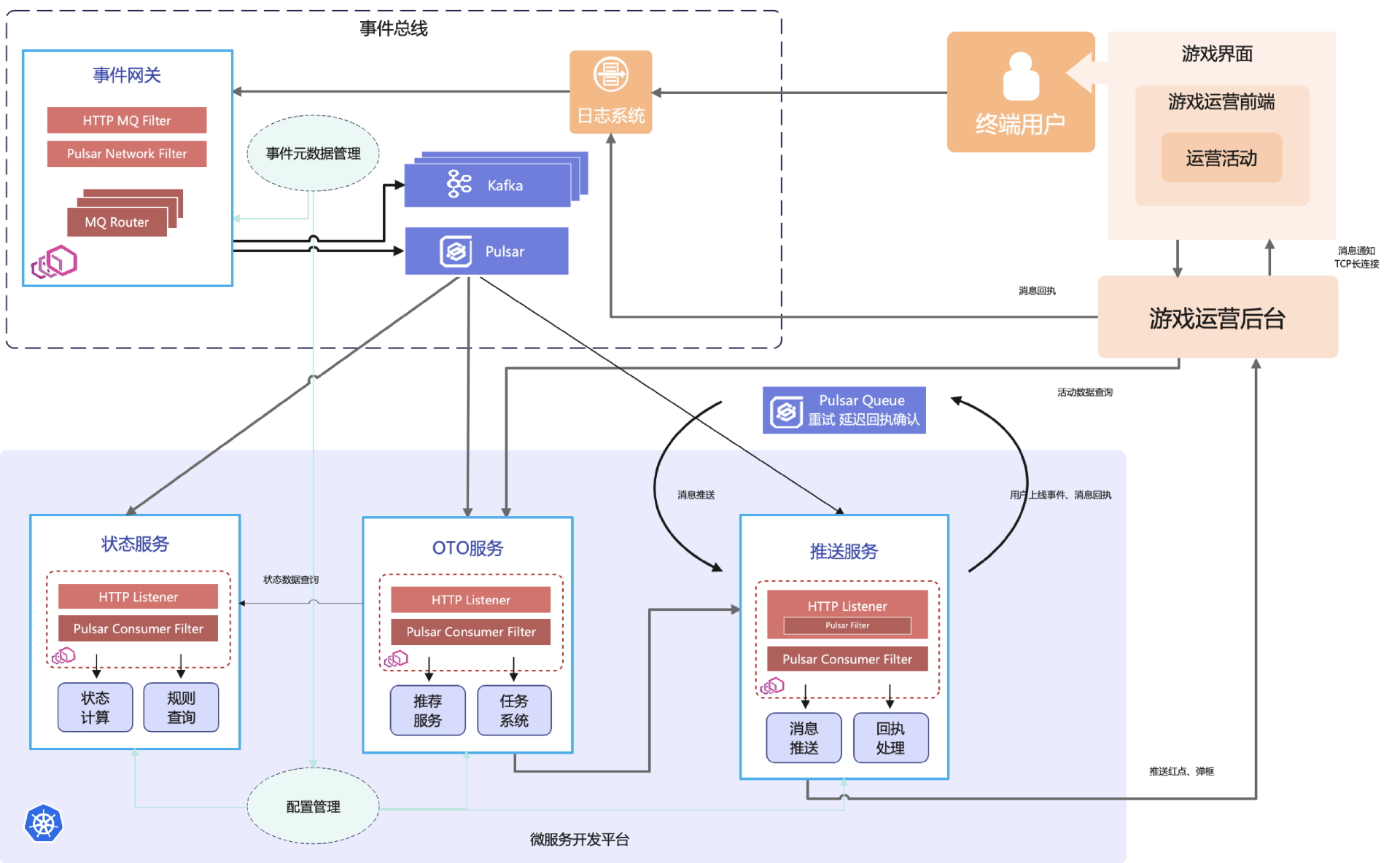
上述架构分为事件总线和微服务两大块。前者负责日志到 Pulsar 消息的生产,增加了事件元数据管理模块,统一管理业务事件到 Pulsar Topic 的映射。这里为了兼容性,还会有部分数据流向老的 Kafka 流程。
微服务层加入了 Envoy 网关,通过配置管理获取元数据信息,监听相应的 Topic 路由到微服务进行处理;增加推送服务,利用 Pulsar 的延迟投递与延迟重试能力进行重推和回执处理,提高触达率。这样所有服务都在云端通过 K8s 调度,有高可用保障,只需调整副本数即可轻松扩缩容。
基于事件总线的事件分发
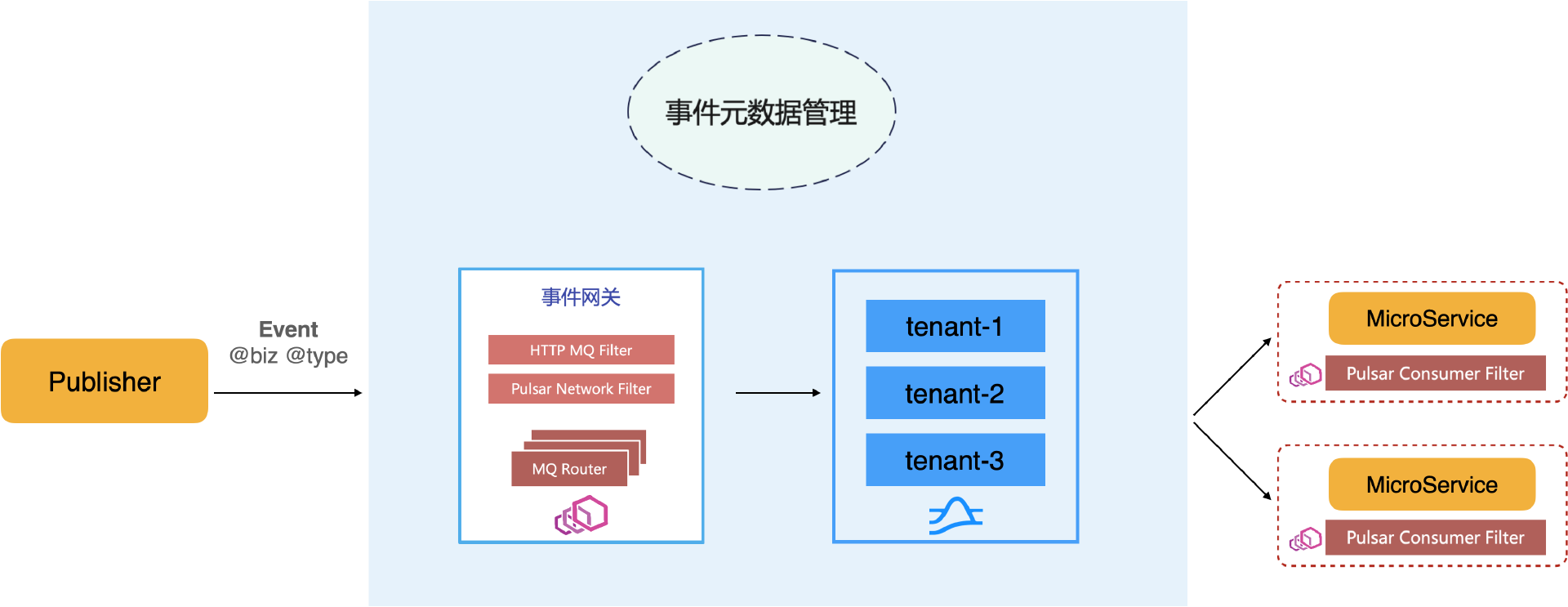
事件总线用于规范事件管理,事件按业务和类型维度管理。事件元数据管理登记各业务的各种类型事件应存放在 Pulsar 的哪个租户的哪个 Topic 下,由事件网关负责路由。微服务侧由配置中心将微服务需要处理的指定业务事件类型在事件元数据管理处查询到具体的 Topic 后下发给 Envoy 网关,再通过 Pulsar Consumer Filter 消费 Message 后路由给微服务进行处理。这样事件的生产和处理两方都无需知晓具体的事件存放类型和位置,只需关心业务和事件类型,简化了业务复杂度。
通用延迟重试
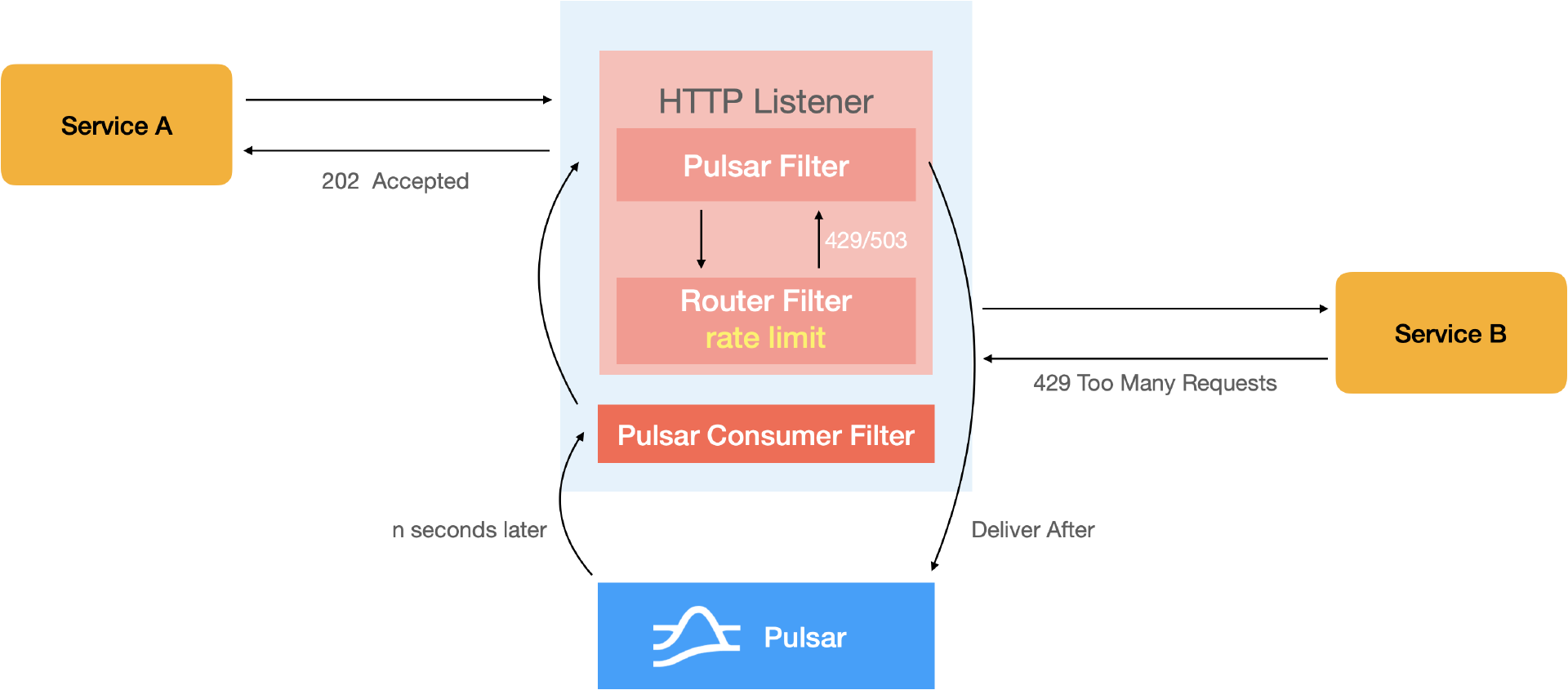
Envoy 网关有失败后立即重试的能力,在很多场景下没有意义,例如在推送服务连接还没有建好的情况下,立即重试毫无意义。有了 Pulsar 后,就可以在 Envoy 上部署通用的延迟重试。当服务 A 通过网关来调用服务 B,网关插件可以提供限速,服务 B 也可以有限速。超过限速的请求会返回 429 状态码。如无限速,可能返回 503 码。如果网关针对特定状态码配置了延迟重试,Pulsar Filter 就会将请求做 Deliver After 处理,或者 Reconsume Later 按配置的时间间隔写入指定 Topic,并返回 202 Accepted 给服务 A。Pulsar Consumer Filter 会监听该 Topic,在指定时间间隔后收到该 Message,还原成 HTTP 请求,并加上带有重试信息的请求头重新路由,发送到服务 B。如果这段时间内,服务 B 或者其以来的资源恢复就会重试成功,最大程度保障服务成功率。这样,初始推送成功率不到 10% 的对局结算比较慢的业务在重试后成功率也能提升到 80% 以上,其他业务也有很大提升。
通过回执确认与补推提高触达率
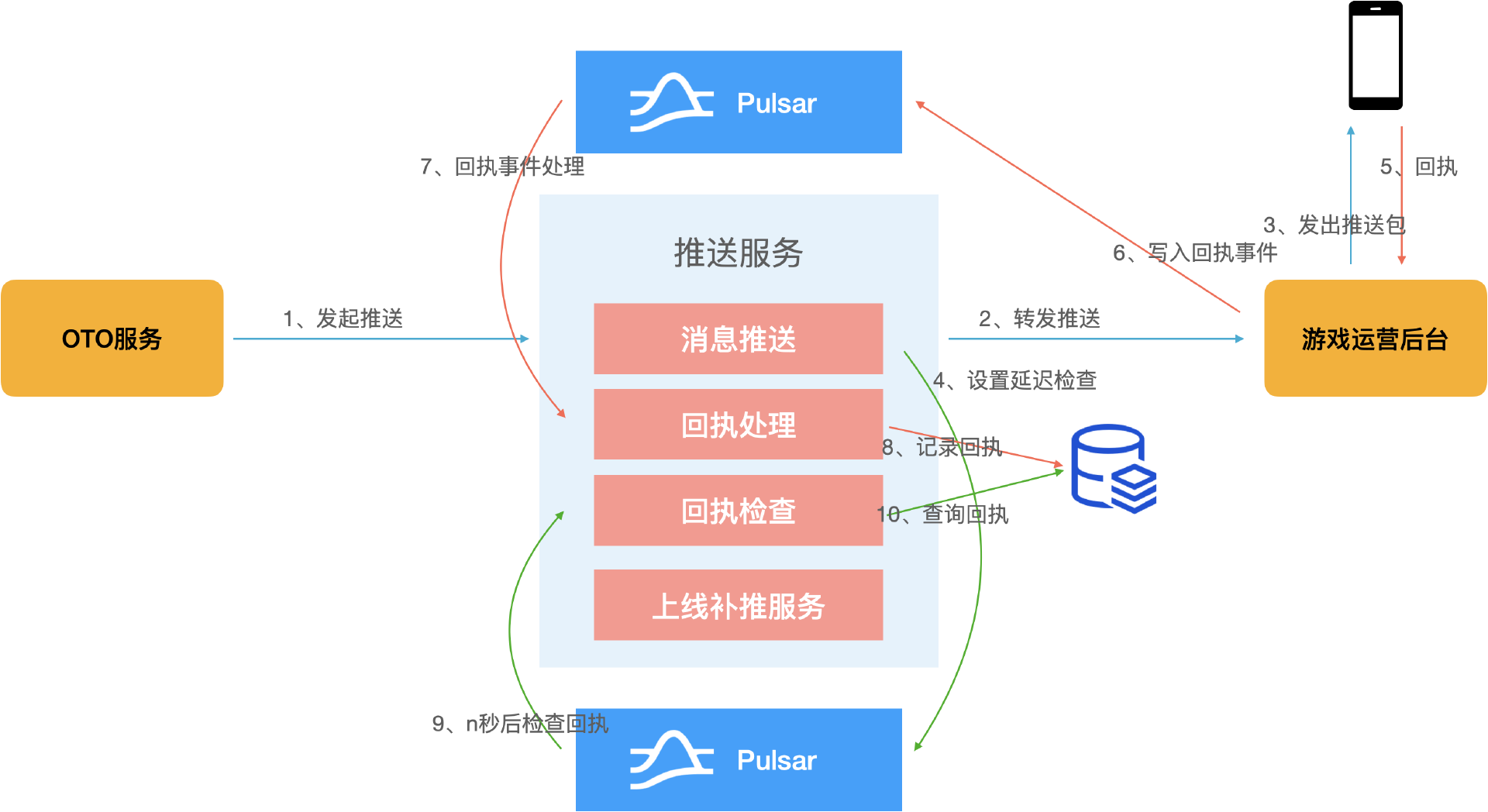
推送成功并不意味着成功触达用户,因为游戏 OTO 服务发起推送给游戏运营后台,后台通过客户端连接发送推送包,就会直接返回成功消息,但客户端不一定能收到推送包,因为可能终端网络不稳定或者网络断开,游戏运营后台无法感知,也存在即使感知到也无法弹窗的情况。为此团队和客户端协商了一套回执协议,在推送成功后利用 Pulsar 的延迟投递能力写入延迟检查消息。如果运营前端收到推送并成功触达,就会向后台发送回执。后台经过事件总线写入 Pulsar,回执处理模块消费该消息,并记录回执。设置回执检查的时间(延迟消息)Timeout 后,回执检查模块会消费延迟检查消息,并查询回执记录。如果记录存在则流程结束,说明用户已被触达,不存在则进入补推流程。
上述机制可将整体触达率提升到 90% 左右。
Pulsar 延迟消息的其他应用
定时任务:可以实现在某个时间给特定用户发送通知;定时活动上下线和物品上架等。
礼包未领取提醒:给用户推送礼包或任务后,用户一段时间未领取,可以通过延迟消息来触发一些动作。
优化效果
改用 Pulsar 并发量不受 Partition 的限制;
去掉 Flink 分发请求,降低成本;
微服务方式部署扩缩容方便;
基于 Pulsar 的延迟重试和回执确认与补推提升了触达率;
通过单集群、多租户隔离各个业务或活动,简化运维工作。
通过网关来集成 Pulsar 的好处
兼容原有服务,状态服务和 OTO 服务无需改造;
减轻微服务开发者的工作量,开发者只需开发 HTTP 接口即可;
结合网关能力实现可灵活的配制化功能:通用触发、削峰填谷、延迟重试和计划任务等。
后续规划
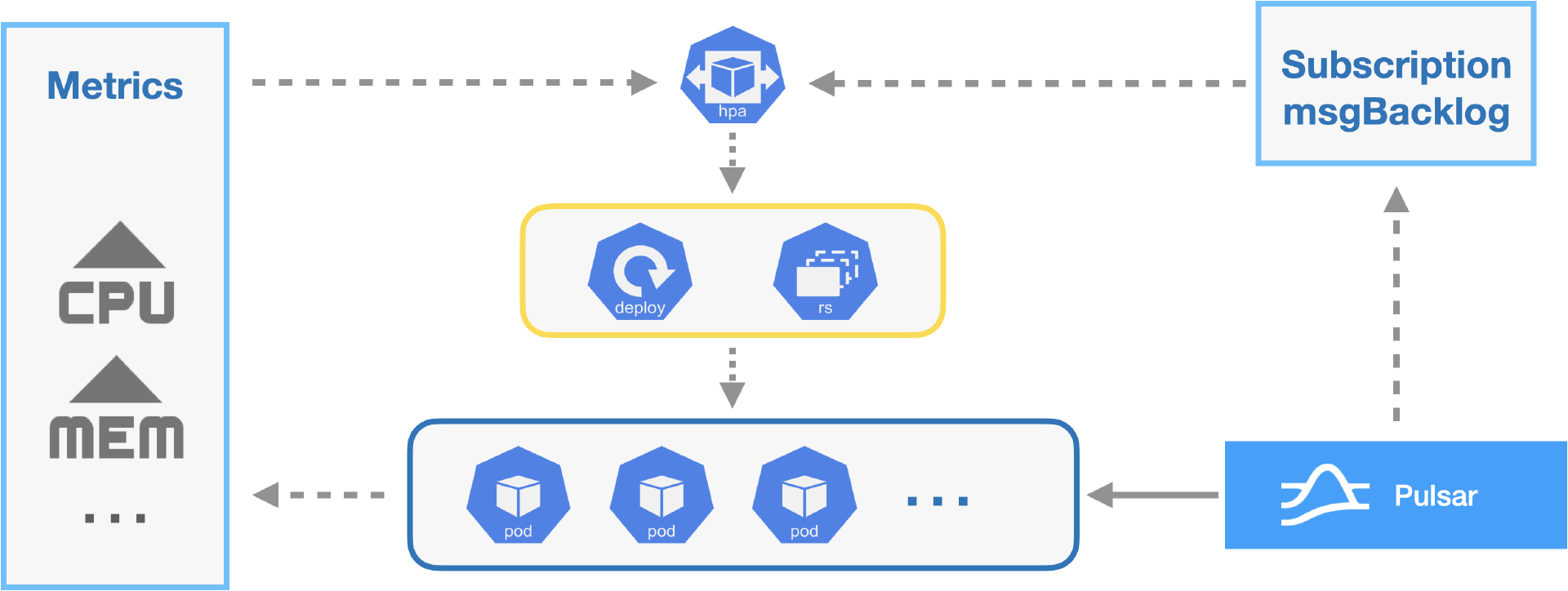
腾讯互娱团队未来计划进一步集成 K8s 和 Pulsar。K8s 支持 HPA,通过监控容器 CPU 和其他内存指标,当达到一定阈值时,触发服务扩缩容。这对一些队列消费服务不适用。有时依赖的第三方服务延迟较大会导致消息堆积,此时消息处理服务内存和 CPU 指标可能不高,但是需要增加并发度来提高处理能力。我们计划扩展 K8s 的 HPA,在监控 CPU 和内存等指标基础上再监控 msgBacklog,增强扩缩容灵活性,防止消息堆积。
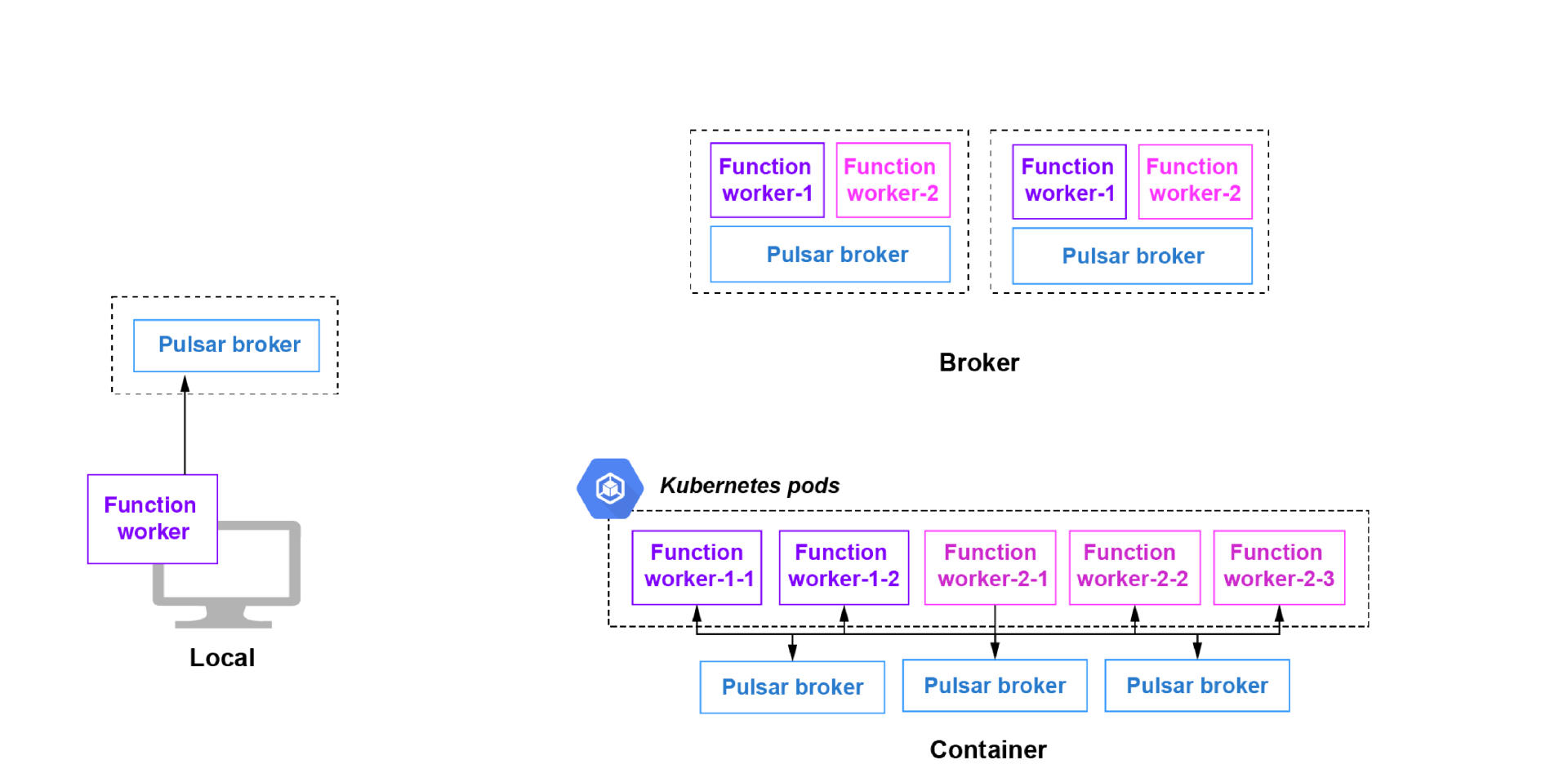
Pulsar 官方提供了非常方便的无服务器计算框架 Pulsar Functions,可以方便地开发 Serverless 消息处理服务。Pulsar Functions 还提供了方便的 K8s 部署方式。未来团队会探索这一方面的应用。
作者简介:
江烁,腾讯互娱 GDP 微服务开发平台网关技术负责人。




