读者须知:《强者恒强:x86 高性能编程笺注》是云杉网络推出的系列技术分享,该系列文章将分享 x86 高性能开发方面的实践和思考。主要内容目录如下,欢迎各位业界同仁与我们讨论交流相关话题。
- 第一部分:介绍
- 寻找软件中的 Hotspot
- x86 CPU 架构
- Good/Bad examples
- 第二部分:性能因素
- 内存
- 缓存
- 数据对齐
- Prefetch
- NUMA
- 大页
- 实例
- 循环
- 数据依赖
- 循环展开
- pointer aliasing
- 实例
- 分支
- 流水线
- 分支预测
- Branch-less 编程
- 实例
- 多线程
- 锁 / 阻塞
- CPU 核绑定
- 无锁操作
- 内存
- 附:
- 性能测试工具
序言
以流水线的眼光来看,分支并不是高速公路上两个目的地的选择,如果预测失败,将是直接拐向出口处的收费站,还是不带 ETC 的。越是高级的流水线,受分支的影响也就越深。我们在观察各种性能测试工具提供给我们的结果的时候,经常会看到“stalled”这个单词,这个词与“发动机”这类词一起连用的时候,就是“熄火”的意思。而 stalled-cycles-frontend,作为一个衡量流水线前端 (Fetch & Decode) 运行水平的指标,与错误的分支预测 (Branch Misprediction) 有密切的关系。
有很多办法可以帮助我们优化分支,除了套用一个 likely()/unlikely() 这种熟知的方式之外,还有很多需要深入了解的知识。想尽量消除分支对性能的影响,先从了解分支开始吧。
分支的类型
分支分为条件分支 (Conditional Branch) 和非条件分支 (Unconditional Branch)。可以很容易的从字义区分:
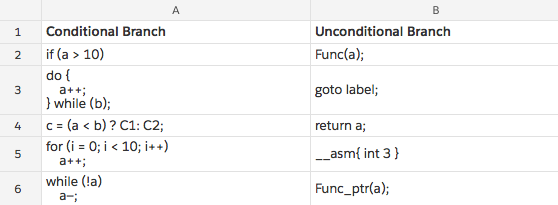
条件分支对性能的影响最为显著。从前面一节关于流水线的描述中我们已能得知,在判断条件的指令没有经过执行 (EXE) 阶段之前,是无法确定正确的分支的。但等待显然不是最优的方案,CPU 还是会继续选取某一个分支的指令继续送入流水线。当发现这一分支是错误分支的时候,流水线不得不停止所有现有的工作,清空错误分支的指令,并从分支正确的地方重新开始,性能的损失也就不可避免。
对于非条件分支,也需要注意除了 goto 这种专门的转跳指令之外,调用某一个函数,或是函数指针,以及从子函数中返回也都属于非条件分支的范畴。
分支优化的原则
简单来说,就是靠猜。当然,在学术上叫“预测”,其实叫“看人品”也没错。如果能一直猜对正确的分支,那么这部分代码运行起来和无分支代码也没什么区别。这个工作主要由 CPU 架构中的分支预测单元 (Branch Prediction Unit, BPU 或 Branch Predictor) 完成。不过呢,BPU 不掷骰子,所有的预测都是基于历史结果的记录和分析。
Side Note: 分支预测 (Branch Prediction) 和分支目标预测 (Branch Target Prediction) 有区别。分支预测是在确定(条件)分支之前判断哪一分支更有可能;分支目标预测是在确定某一条件分支或无条件分支之后预测其转跳目标以便预取。不过这两者通常由同一处 CPU 电路完成。
在这里简单地讲一下分支预测的原理。2-bit Saturating Counter 是一种古老的技术,但作为现代分支预测器之滥觞,仍然值得我们分析一下。
如下图所示的状态机,共存在 4 种状态。其状态转换的条件,是本次该分支是否被选择。如果以 1 代表被选择 (taken),0 代表没有 (not taken),那么 1 向右边移动,0 向左边移动。当该分支确实是大概率转跳的分支 (taken),那么状态会大部分时间维持在 strongly taken 附近,如此可为下一次的预测提供预测。反之,则状态会维持在 strongly not taken 附近,也可以作为预测的凭据。
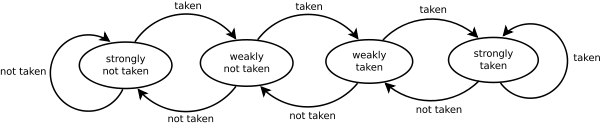
Side Note: 各个分支的 Saturating Counter 组织在一个表中,并以指令的地址作为 index,那么 CPU 就可以在 Fetch 阶段取得该指令的 Saturating Counter 状态。
Saturating Counter 确实帮助我们解决了一部分问题。但这种机制也存在缺陷。它对按某种规律重复出现的分支处理结果缺乏良好的支持,而这种情况在我们的程序中也经常出现,考虑如下代码:
for (i = 0; i < 1000; i++) {
if (i & 1) { /* If i is odd num */
count++;
}
}
奇数总是间隔出现,if 的分支也是每隔一次循环执行一次。如果继续采用如上的方式,那么 Saturating Counter 总是会在两个相邻状态之间摇摆,并且总是提供错误的预测。对此,又引入了二级自适应预测器 (Two-level adaptive predictor)。
该机制可以理解为,为一个分支分配多个 Saturating Counter,以历史的情况决定使用哪一个 Saturating Counter。以上面的代码举例,if 分支共分配有 4 个 Saturating Counter,Table Entry Index 分别为 00,01,10 和 11。由该分支的最后两次选取结果决定使用哪一个 Saturating Counter。在上面的代码中,选取结果为 01010101010…当最后两次结果为 01 的时候,Index 01 的 Saturating Counter 接受本次的选取结果 0,并向 Strongly not taken 移动且维持该状态;当最后两次结果为 10 的时候,Index 10 的 Saturating Counter 接受本次的选取结果 1,并向 Strongly taken 移动且维持该状态。故当 10 这一选取规律再次出现的时候,对应的 Strongly taken 状态便可帮助 CPU 预测本次该分支将会被选取。如此,便可以为按某一规律出现的分支提供预测。
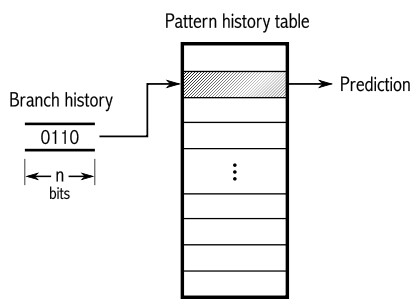
从上面的分析中可以得出,分支优化的原则就是让程序中分支的选取更加规律,这是一件十分合分支预测器胃口的事情。比如我们在第一节中所举的例子,对输入的随机数据首先排序再进行判断,就是利用的这一原则。但分支优化的最重要的原则,并不是这一条,而是在能不用分支的时候,尽量不要用分支。比如将上面的代码改成:
for (i = 0; i < 1000; i++) { /* Ignore the optimization of loop*/
count += (i & 1);
}
性能相关的分支类型
从性能优化的角度来看,程序中的分支大致可分为如下几类:
第一次执行的条件分支
所谓“第一次”执行,可以真的是第一次,也可以是因为缓存更新等原因导致分支预测器中没有保存其历史数据。因为是第一次执行,所以很难对分支的情况作出有效的预测。例如 C 语言中的 if,while,for 以及汇编中的 jz,jne 等指令,CPU 虽然在这种情况下也会有一套执行的标准,但这取决于不同 CPU 的不同实现。除了使用 likely()/unlikely() 人为标注之外,还可以使用一些消除分支的通用方法。但这种情况非常罕见,优化的效果也难尽如人意。对于分支优化,和其他所有的优化一样,首要是抓住经常多次执行的关键代码段,以期取得优化效果的最大化。
重复执行的分支
重复执行的分支可以理解为分支预测器中存有其相关历史的分支。分支预测器能够以历史为依据,对下一次的分支选择做出判断。对这一类型的分支,可以用测试工具查看其 Branch Misprediction Rate。程序员需要做的,是尽可能让此类分支呈现出规律性,消除随机性带来的负面影响。现代的分支预测器已经远远比上文中介绍的复杂,发现分支中隐藏的规律并不是一个有特别难度的问题,当前,前提是规律真的存在:D
间接转跳分支
除了 if,while 之外还有利用函数指针或者 Jump Table 进行的间接转跳分支。间接转跳与 if while 这类转跳的不同之处在于,其转跳目标 (Branch Targets) 存在无限多种可能(函数指针可指向任意函数)。而 if while 只存在两种可能:下一条指令,或者转跳分支的第一条指令。现代的 CPU 同样对分支目标准备了预测机制,但和分支预测类似,该机制也同样依赖于“规律”二字。
非条件直接转跳分支
此类分支属于最少让人操心的分支。分支预测,100% 正确,分支目标预测 100% 正确,很难引发性能下降。
分支优化的技术
使用 Setcc 及 CMOVx 指令
使用 SETcc 及 CMOVx 指令可以帮助消除分支。不过这其实是一种类似于“空间换时间”的交换。这两个指令消除了分支在指令流程上的依赖,但引入了数据依赖,并将进一步影响乱序执行核心 (OOO Core) 的操作。并且这两条指令相当于将两个分支都执行了一次,对于可以预测的分支,一定不要采取这种技术。
Side Notes: 现代 x86 CPU 往往拥有很高的分支预测正确率。持续的无法预测的分支是比较罕见的情况。对于是否采用这两个指令,一定要以实际测试数据为依据。
- SETcc
举一个经典的例子:
R = (A < B) ? NUM1 : NUM2;
R 最终的取值取决于 A 与 B 相较的结果。当 A 与 B 之间无甚关联的时候,CPU 很难预测结果。该条指令比较“正统”的汇编指令如下:
cmp a, b ; Condition
jbe L30 ; Conditional branch
mov ebx num1 ; ebx holds R
jmp L31 ; Unconditional branch
L30:
mov ebx, num2
L31:
在 jbe L30 处产生分支,最终 ebx 的取值,取决于 A 与 B 的比较结果。使用 SETcc 指令可以用如下的方式消除分支:
xor ebx, ebx ; Clear ebx (R in the C code)
cmp A, B
setge bl ; When ebx = 0 or 1
; OR the complement condition
sub ebx, 1 ; ebx=11...11 or 00...00
and ebx, NUM3 ; NUM3 = NUM1-NUM2
add ebx, NUM2 ; ebx=NUM1 or NUM2
setge 并没有真正避免 A 与 B 的比较,而是依据比较结果修改了寄存器 ebx 的值。之后又利用了补码的一个数学运算上的小技巧,消除了分支。
- CMOVx
CMOVx 所采用的思路,是将两种可能的结果都先计算出来,然后根据条件判断结果 (EFLAGS) 决定采用哪一结果。
考虑如下代码:
if (x < 0) {
x = -x;
}
mov edx, eax ; 假设 x 的值在 eax 寄存器, 该指令使 edx=eax
neg eax ;eax=-eax 该指令的结果将设置条件寄存器的状态
cmovs eax,edx ; 如果状态为负, 将 edx 的值传递给 eax
这两个指令表面看来不存在分支,但其实是将分支判断隐藏在了对条件寄存器(EFLAGS) 的状态判断中。只不过这些指令的判断有 CPU 硬件电路支持,所以和通常意义的软件分支判断有所区别。当分支预测正确率不理想的时候,采用这两个指令会带来一定的性能提升。
使用 likely()/unlikely()
likely()/unlikely() 是最常见的帮助分支预测的方法。其为 GCC 编译器提供的两个内建函数(其他编译器也有类似的功能)的宏:
#define likely(x) __builtin_expect(!!(x), 1)
#define unlikely(x) __builtin_expect(!!(x), 0)
程序员可以通过这两个宏将分支预测的信息提供给编译器,由编译器根据 CPU 执行代码的标准生成汇编代码,将可能转跳 (likely()) 或可能不转跳 (unlikely()) 的分支的代码放置于合适的位置,以达到人为提供分支预测信息的目的。这两个语句很常见,只要是稍微有点性能优化的意识,就会用到这两个宏。比较好奇的情况是,当实际运行情况与程序员标注的情况相左时,CPU 是否会自己纠正?这就要留给读者自己动手去验证了:D
使用无分支代码
还记得分支优化的第一原则吗?就是尽量消除分支。SETcc 和 CMOVx 指令是一种消除分支的方法,但也还有很多其他的方法。例如我们在第一节所举的例子:
if (data[i] > 128) {
sum += data[i];
}
对于影响分支预测的随机输入,除了先排序之外,当我们想采用 CMOVx 指令的时候,可以写为:
int t = data[i];
sum += (t > 128) ? t : 0;
CMOVx 指令固然可以消除分支,但并非是没有代价。当我们想避免这种代价的时候,还可以使用如下无分支代码 (Branch-less Code) 操作:
int t = (data[i] - 128) >> 31;
sum += ~t & data[i];
无分支的代码是一种编码风格,虽然它彻底消除了分支对 CPU 流水线的影响,但它也存在增加计算量,降低代码可读性的问题。现代 CPU 的分支预测正确率已经可以在一般情况下维持在 95% 以上,所以当分支存在可预测的规律的时候,还是以性能测试的结果为最终的优化依据。
作者简介
张攀,云杉网络工程师,专注于 x86 网络软件的开发与性能优化,深度参与 ONF/OPNFV/ONOS 等组织及社区,曾任 ONF 测试工作组副主席。




