
引言
目前腾讯云 ES 集群可以支持双可用区及三可用区的集群部署,且支持单可用区平滑升级到多可用区集群。当一个可用区出现故障时,剩余可用区依然能够保障集群的稳定性、服务的可用性和数据的完整性。
数据节点
当客户选择了跨多可用区的集群架构部署时,集群的数据节点必须是多可用区的倍数,如客户选择的是三可用区部署,则数据节点个数应为 3,6,9,12 等,以此类推。
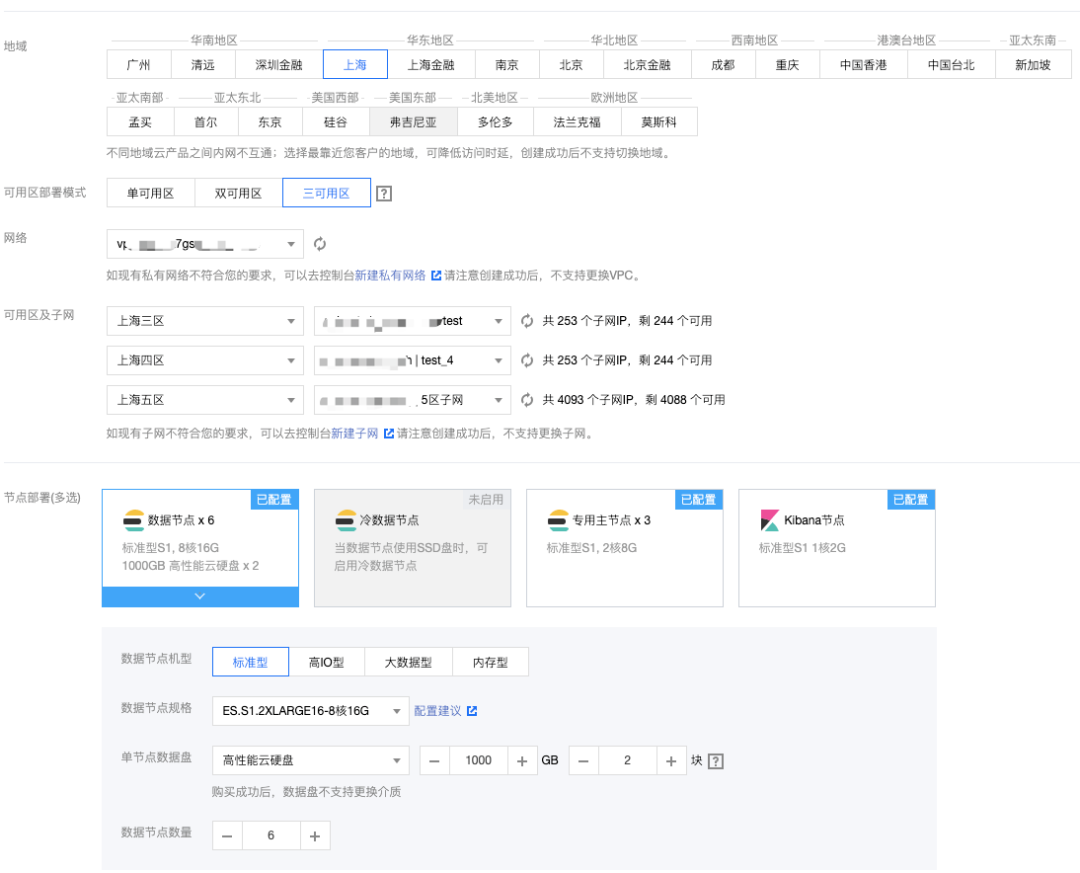
如上图 1 所示,我们在上海地域选择了三可用区集群的部署,数据节点数量选择 6 个。ES 会自动将 6 个数据节点均衡得分布在三个可用区中,并对每个节点标记上可用区属性,从而可以通过可用区感知功能将索引的分片自动分布在多可用区中,集群中节点的具体分布情况如图 2 所示。
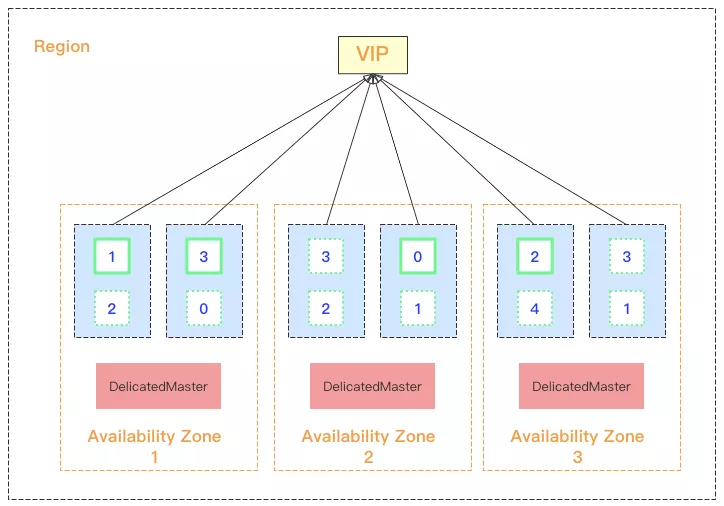
从图 2 中我们可以看到,腾讯云 ES 提供了 VPC 内的负载均衡功能,客户可以直接通过 VIP 连接集群,由于 VIP 下绑定了集群内部的所有数据节点,因此客户所有的读写请求会均衡的分布到各个数据节点上。
另外该 VIP 还自带健康检查功能,如一个周期内多次检测到某节点未响应,健康检查功能则会暂时从该 VIP 的路由列表中摘除该异常节点,直到节点恢复正常。这样就保障了当一个节点宕机或者某一个可用区不可用的情况下,客户端依然能够无感知的请求集群。
专用主节点
为了保障集群的稳定性和高可用性,当选择多可用区集群架构部署时,需强制设置三个专用主节点。其中专用主节点的分布机制如下:
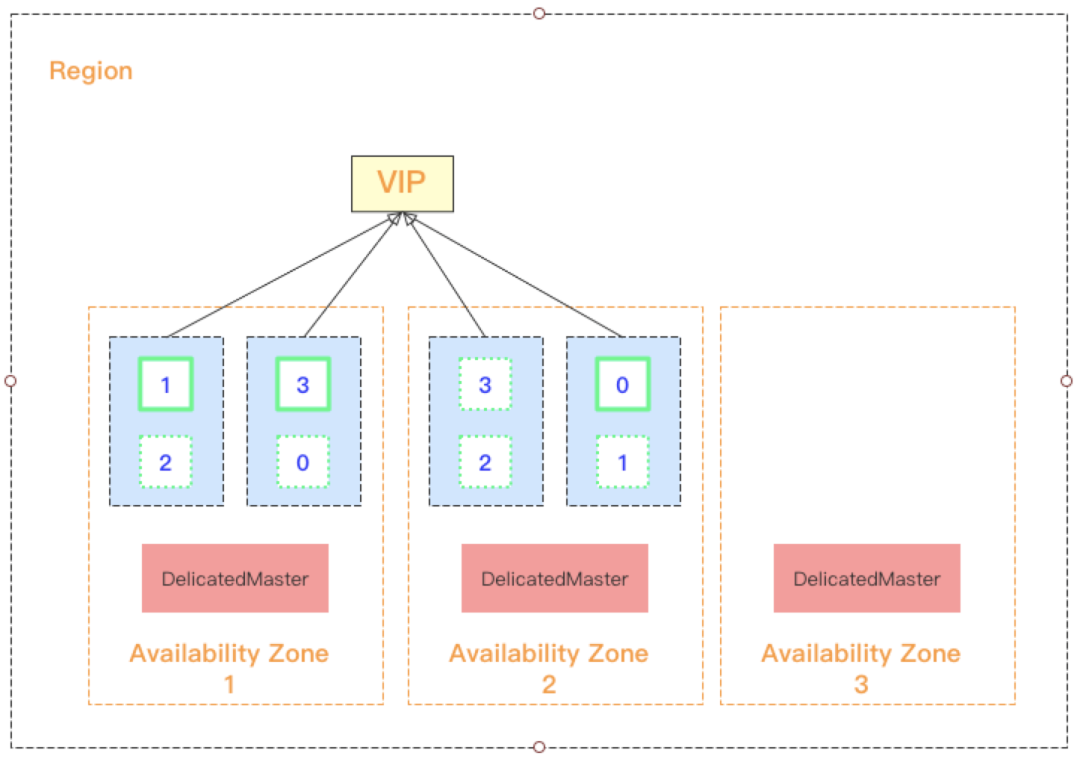
当选择三可用区部署时,会在每个可用区部署一个专用主节点,从而保障任何一个可用区不可用时,依然能够选出 Master 节点;
当选择双可用区部署时,为了避免出现一个可用区上分布两个专用主节点且出现“该可用区不可用”导致选不出 Master 节点的情况,腾讯云 ES 会选择一个隐藏可用区用来专门部署专用主节点,如下图 3 所示。
索引副本分片
为了保障在一个可用区不可用的情况下,依然能够保证数据的完整性和服务的可用性,索引分片至少设置 1 副本。如果选择三可用区部署,当两个可用区不可用时,希望剩下的可用区依然能够完整提供服务,则索引的副本个数至少为 2 个。
ES 多可用区架构部署实现机制
腾讯云 ES 多可用区集群部署依赖于 ES 提供的节点属性感知 awareness [1] 功能。通过对每个节点进行属性标记,即对节点进行可用区的属性标记:"node.attr.zone_id:shanghai-3"。
该属性配置在 elasticsearch.yml 文件中(也可以选择在启动节点时进行参数指定:"./bin/elasticsearch -Enode.attr.zone_id=shanghai-3"),设置完节点属性后,腾讯云 ES 集群通过设置如下参数:"cluster.routing.allocation.awareness.attributes=zone_id" 来让集群在分片分配中使用节点属性执行分配策略。
这样 ES 就可以通过可用区 zone_id 属性将节点进行分类。且将索引的主副本分片分布到属性 zone_id 不同的节点上。
例如,我们创建了一个具有 4 个数据节点的双可用区的集群,分别部署在上海 3 区和上海 4 区。那么上海 3 区的节点属性为: "node.attr.zone_id:shanghai-3",上海 4 区的节点属性为: "node.attr.zone_id:shanghai-4"。
当我们创建一个索引,该索引有 5 个主分片和 1 个副本分片,那么所有的主分片和对应的副本分片都会均衡的分布在上海 3 区和 4 区上,而不会出现主分片和副本分片同时分布在上海 3 区或者上海 4 区的情况。
需要注意的是:这时候如果有一个可用区挂掉,如上海 3 区整体不可用,ES 会将上海 3 区的主副本分片在上海 4 区进行重建。即这时候会出现主副本分片同时分配在同一个可用区的情况。
为了防止某一个可用区不可用,导致另一个可用区磁盘容量被重建的分片大量耗尽的情况,腾讯云 ES 启用了分片强制感知 (force awareness) 的功能。
腾讯云 ES 通知设置如下参数:cluster.routing.allocation.awareness.force.zone_id.values=shanghai-3,shanghai-4,从而保证了在一个可用区不可用时,不会使得剩余的可用区磁盘资源不足的情况。
单可用区平滑升级多可用区
前文图 1 演示了在腾讯云 ES 控制台购买多可用区集群的操作步骤。对于存量的单可用区集群,腾讯云 ES 同样支持平滑升级到多可用区的部署架构。具体操作如下图 4 所示:
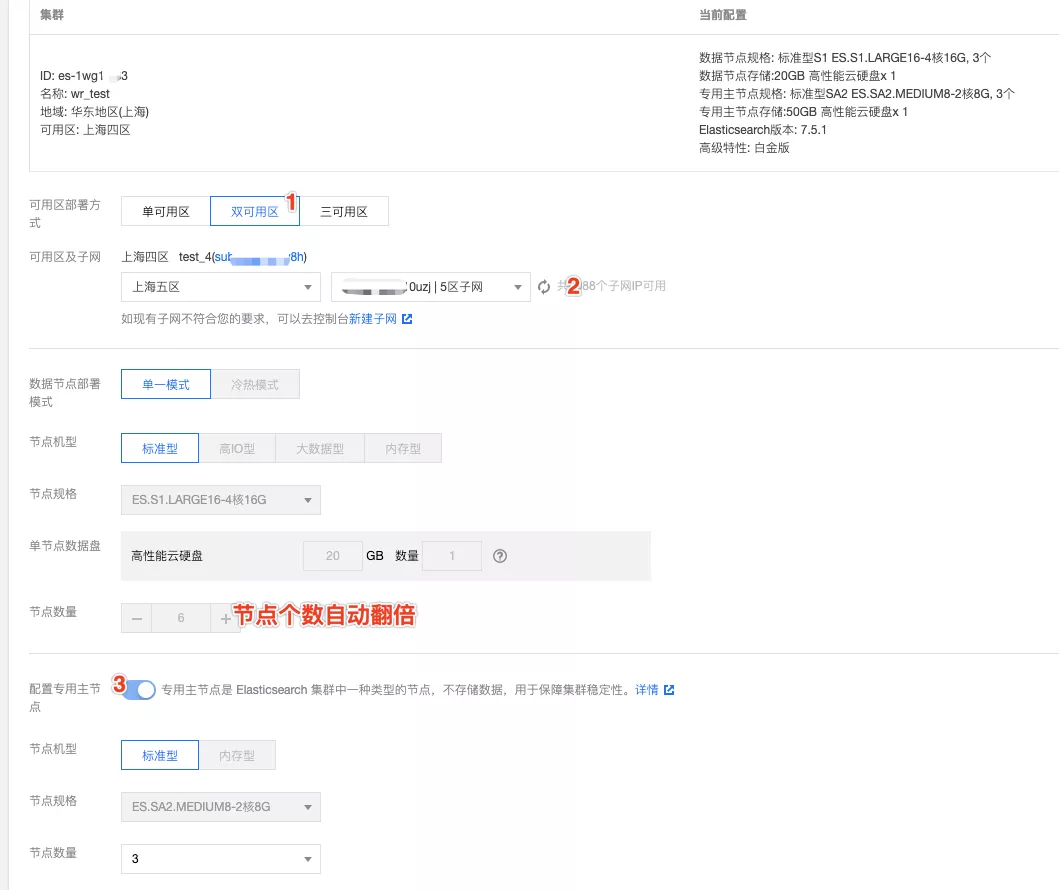
这里需要注意以下几点:
当选择了升级到多可用区时,只能设置新的可用区信息,不可更改节点配置和磁盘容量;
当升级到双可用区时,数据节点数量自动翻倍;当升级到三可用区时,数据节点数量自动乘三倍;当从双可用区升级到三可用区时,数据节点数量自动乘 1.5 倍;
如果原集群未设置专用主节点,则会强制选择设置 3 个专用主节点;如果原集群设置了专用主节点,则节点数量不变,腾讯云 ES 会自动完成专用主节点在各可用区之间的调度和分布。
单可用区升级到多可用区的变配流程最大的难点和挑战在于专用主节点的协调上。下面重点介绍腾讯云 ES 在处理可用区升级方案中专用主节点的实现机制:
为了下图说明方便,我们先对各类型节点使用不同颜色进行标记:

普通节点:包含 master、data、ingest 等所有属性,节点上存储索引数据,使用蓝色标记。

专用主节点:只包含 master 属性,在集群中属于专用主节点,不存储索引数据,只负责管理集群和存储集群的元数据信息,使用粉红色标记。

数据节点:只包含 data、ingest 属性,一般用于具有专用主节点的场景,该节点上存储索引数据,通常也被称为专有数据节点,使用绿色标记。
单可用区升级到多可用区场景分析:
(1)原单可用区集群没有专用主节点:
如果原单可用区集群没有设置专用主节点,这种情况下无论是升级到双可用区还是三可用区都是比较简单的。
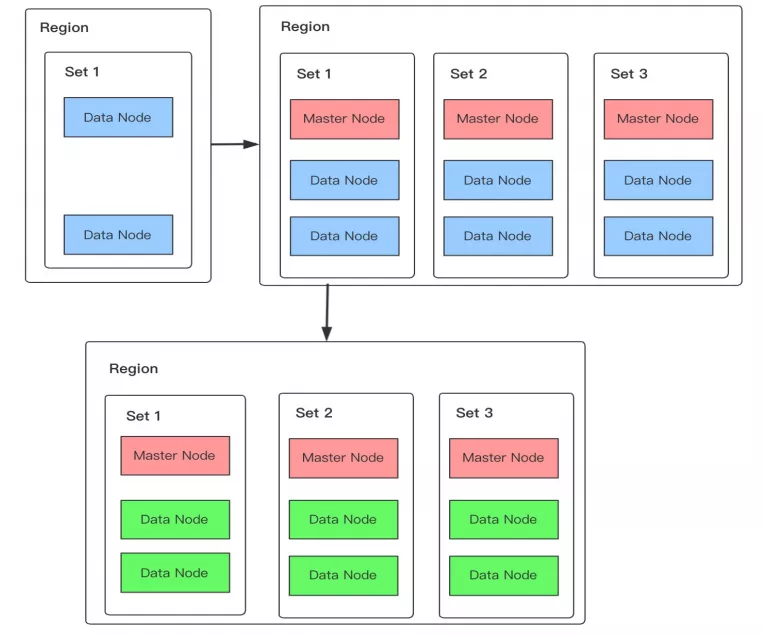
升级变配流程如上图 5 所示:
在新增的可用区中申请创建并加入普通节点以及在每个可用区中各加入一个专用主节点(如果是升级到双可用区,则会在隐藏可用区加入一个专用主节点);
修改各可用区中普通节点的属性为专有数据节点,即上图中将蓝色变更为绿色。
在流程的第 2 步修改节点属性时,每重启一个节点,min_master_node 都会重新计算并设定,避免在中间状态发生脑裂。
(2)原单可用区集群已设置专用主节点:
如果原单可用区集群中已经设置了 3 个专用主节点,那么按照最终的状态来看,应该是每个可用区都会均衡分布一个专用主节点。
自然想到的流程是先在新增的可用区中各加入一个专用主节点,然后再将原可用区中的多余两个专用主节点下线即可。如下图 6 所示:
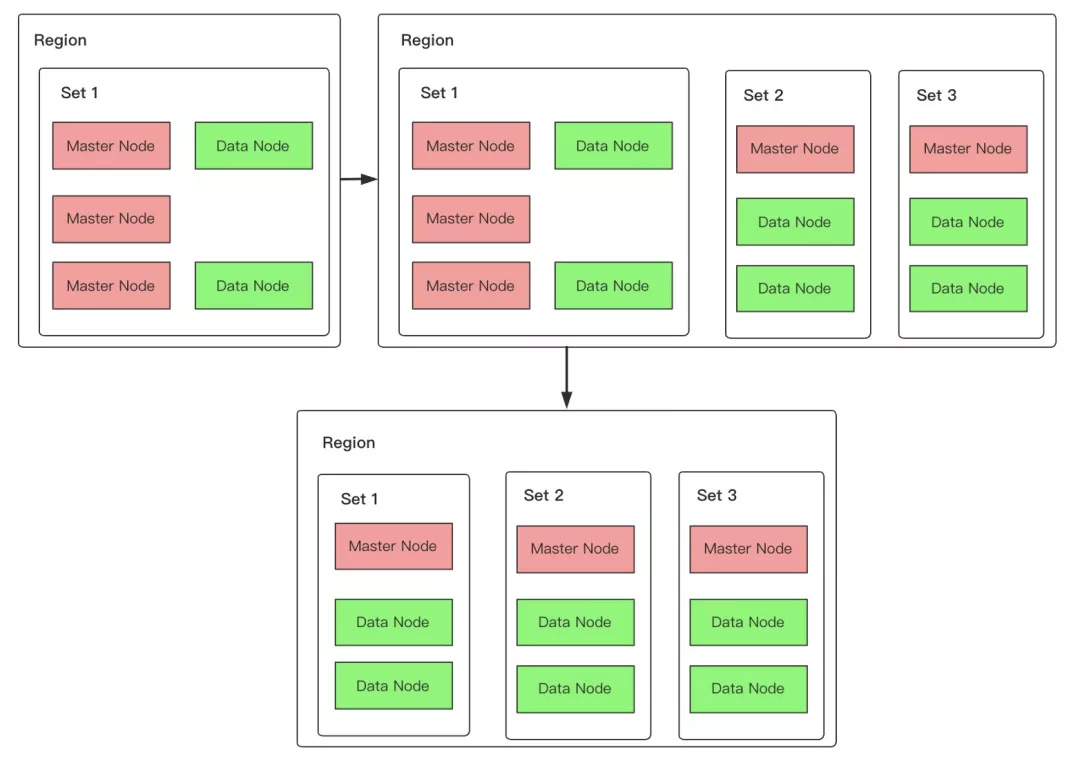
具体流程步骤如下:
在新增的可用区中加入数据节点及一个专用主节点(如果是升级到双可用区,则只需要在隐藏可用区申请加入一个专用主节点即可);
将原单可用区中多出的两个专用主节点下线。
但是这种升级变配流程存在一个隐藏的集群不可用风险。如图 7 所示:
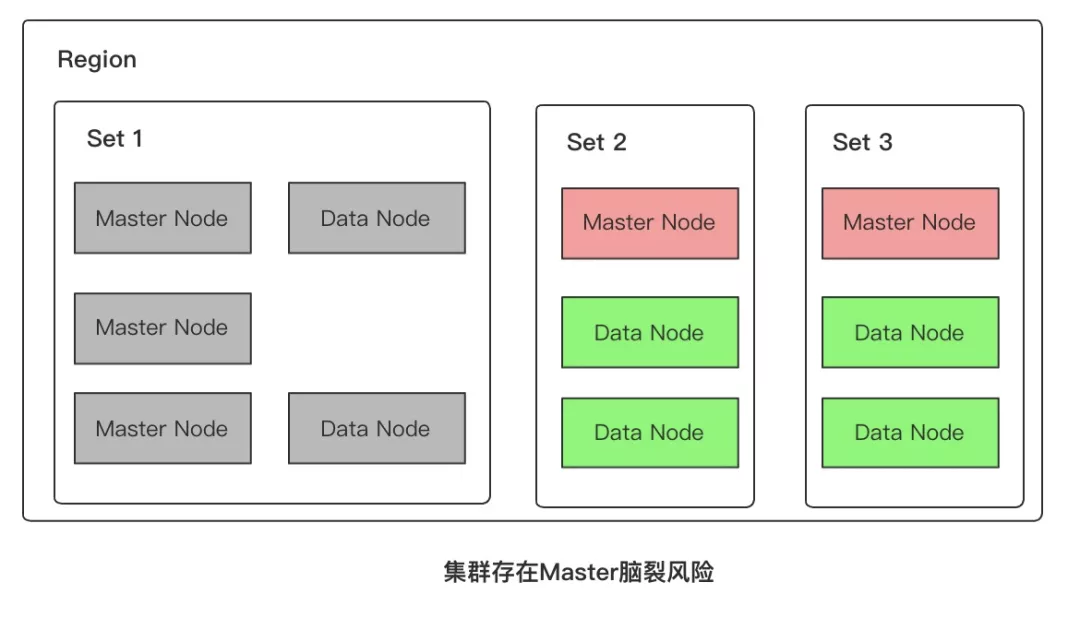
从图 6 的第一个流程上我们再结合图 7 可以看到,如果在中间状态原单可用区突然发生不可用,那便会出现剩余的可用区中只剩下 2 个专用主节点,这时候从 5 个专主变成了 2 个专用主节点,便会出现选不出 Master 节点的情况,从而使得集群整体不可用,违背了跨可用区的容灾初衷。
为了规避上面分析的这种异常风险,我们对图 6 的第 1 个流程的中间状态做了优化,如下图 8 所示:
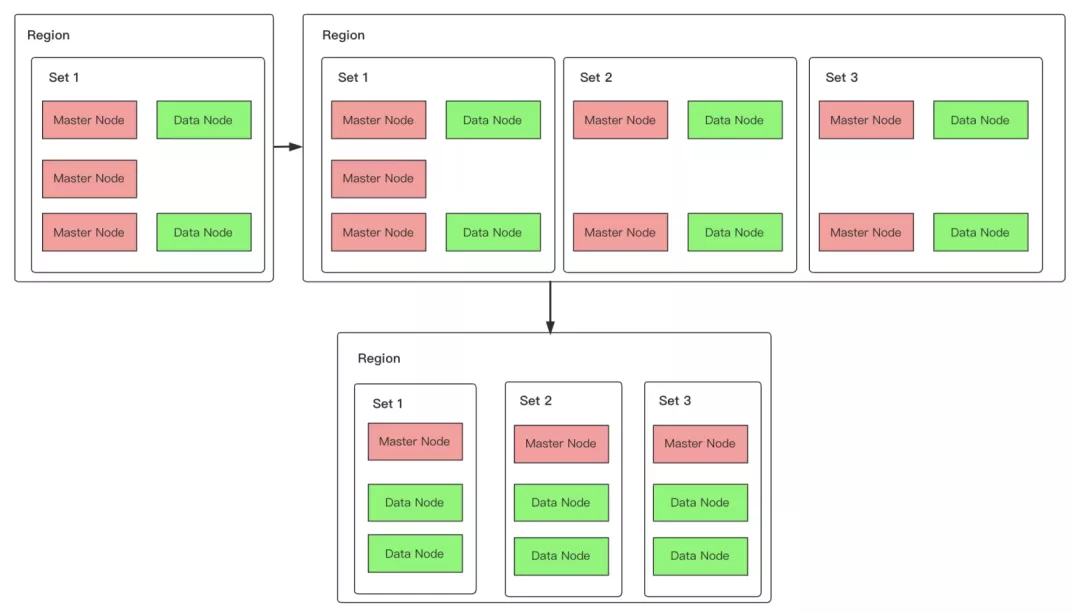
具体流程如下:
在新增的可用区中加入数据节点及两个专用主节点(如果是升级到双可用区,则只需要在隐藏可用区申请加入两个专用主节点即可);
将原单可用区中多出的两个专用主节点和新增的可用区中多出的一个专用主节点下线。
这样便可保证即使在流程一的中间状态下任何一个可用区不可用,依然不影响剩余专用主节点选出 Master 节点。从而保障了集群的高可用性。
结语
本篇文章我们详细介绍和分析了腾讯云 ES 集群多可用区容灾的实现原理和操作实践。并重点介绍了单可用区集群升级到多可用区的几种场景及具体流程细节,希望能够帮助到腾讯云 ES 的客户朋友们。
头图:Unsplash
作者:吴容
原文:https://mp.weixin.qq.com/s/7VzmoK4ZsVfnJflEs_B9tA
原文:腾讯云 Elasticsearch 集群多可用区容灾实现原理及最佳实践
来源:云加社区 - 微信公众号 [ID:QcloudCommunity]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




