
去年 ChatGPT 爆火后,国内迅速迎来了“百模大战”。其中,复旦大学自然语言处理实验室在去年 2 月率先发布了国内首个类 ChatGPT 的对话式大语言模型 MOSS,开放不到 24 个小时,由于瞬时访问压力过大,MOSS 服务器显示流量过载而无法访问。
当时,平台官网发布解释称,MOSS 还是一个非常不成熟的模型,计算资源不足以支持如此大的访问量,距离 ChatGPT 还有很长一段路要走。MOSS 的发布是一个重要的里程碑,打通了大语言模型研发的完整技术路径,展示了在资源受限的情况下构建高效大语言模型的可能性,还为全球研究者和开发者提供了重要的技术参考和实践经验,也提升了国人研发大语言模型的信心。
至今一年多的时间过去,在 6 月 6 日举行的 CCF 大模型论坛上,复旦大学计算机学院教授邱锡鹏教授坦诚道,当时发布的 MOSS 技术框架是 GPT-2 时代的架构,比较与后面出现的 LLaMA 等模型架构相比,相对过时,并且训练数据量和参数量也不够,导致能力有限。
邱锡鹏教授表示,MOSS 之前的路线,基本上和 OpenAI 差不多,但由于学术界的数据有限,所以团队更多使用了“AI Feedback”的方法,而非后面大家普遍采用的蒸馏方法。团队构造了很多自指令,通过宪法 AI 的方式生成的大量数据去训练模型,以及与真实的人类需求对齐。
在本次论坛上,邱锡鹏教授详细介绍了 MOSS 最新的研发进展。AI 前线基于邱锡鹏教授演讲内容整理了本文,经过不改变原意的编辑,以飨读者。
下一代 MOSS:世界模型
AlphaGo 虽然取得了非常大的突破,但是它还是属于上一代的人工智能(弱人工智能),即一个模型解决一个任务。现在,以 ChatGPT 为代表的通用人工智能,是用一个模型来解决非常多的任务,即多任务通用性,这是通向 AGI 的模型。
邱锡鹏教授表示,自然语言处理这十年,一直在进行缓慢的范式迁移。原来自然语言处理的任务非常多,比如分类任务、匹配任务、序列标注任务、阅读理解任务、句号分析等结构化学习任务。这些任务已经逐渐收敛到了语言模型任务,语言模型任务逐渐统一了自然语言处理的所有任务。
为什么现在通用模型是从 ChatGPT 或者大语言模型开始?邱锡鹏认为,关键的一点是,现在语言某种程度上是人对外界的一种认知,是在自己大脑中的反应。这里的语言并不是语法本身,而是以语言为载体的人类知识。
人类总结的知识必须要用语言来总结,语言代表了人类智能对世界的压缩。现在人工智能领域 有“压缩即智能”的说法,压缩率越高,智能程度就越高。某种程度上,语言就是对世界的极致压缩,只不过这个压缩是由人类智能完成的。
构建世界知识可以不经过语言,直接让模型通过观察这个世界自己发现世界的规律,但这往往非常困难。
现在的大语言模型具有世界知识,第一步是由人类来完成的。人类观察世界、总结知识,用语言写下来。大模型通过模仿学习的方式,把知识学到模型里面,并且通过语言的方式与世界进行交互。注意的是,与世界交互时不一定限于自然语言。
“我们最终希望达到所谓的‘世界模型’,即让模型本身和世界进行交互,观察世界、理解世界,并进行相应的决策。”邱锡鹏教授说道。这也是继去年第一代 MOSS 发布之后,团队设想中的第二代 MOSS。
世界模型的概念提得非常早,它可以回避掉语言模型的缺点,但它本身到底怎么实现的路径并不清晰。邱锡鹏团队的看法是,即使世界模型,也需要依赖到大语言模型这种基础模型上。因此,实验室的努力方向之一就是如何将现有的大语言模型改造成理想中的世界模型。
这一想法也有实践支持。有很多研究者通过对 GPT-4 做各种实验,发现 GPT-4 已经具有非常强的时间和空间概念、对现实世界的物体有了解,只不过需要在符号空间把它映射到现实世界,做一个比较好的对齐。
邱锡鹏教授提到,这也是现在比较热的概念:具身智能 + 世界模型。
“我们要赋予大语言模型感知能力、增强它的决策规划能力,以及让它拥有更好的记忆、更好地使用工具等等,需要其通过不断和现实世界进行交互来学习。MOSS 2 希望围绕着这方面去做研究。”邱锡鹏教授表示。
如何实现?
“如果一个模型经常和世界进行交互,现在的模型肯定是不行的。”邱锡鹏教授举例称,如何让交互数据和模型迭代起来,如何更好地使用工具、跨模态和智能体等都需要解决。
在高效架构搭建方面,团队在 KV-Cache 上做了很多改进,让第二代模型具有更好的稀疏性,大幅降低成本,比如长文档的计算速度可以提升 70% 左右,同时保持能力不太下降。
对于底层架构的改进,团队用 Triton 重写了 Attention Kernel,让模型更好地利用硬件加速自身能力。团队发还布了一个工具 CoLLiE (牧羊犬):一个高效的 LlaMA(羊驼)等大模型微调工具。
CoLLiE 集成了现有的并行策略、高效参数微调方法和高效优化器,来加快训练速度,提高训练质量,降低训练开销。除 MOSS 外, CoLLiE 还支持 InternLM, LLaMA, ChatGLM 等模型。
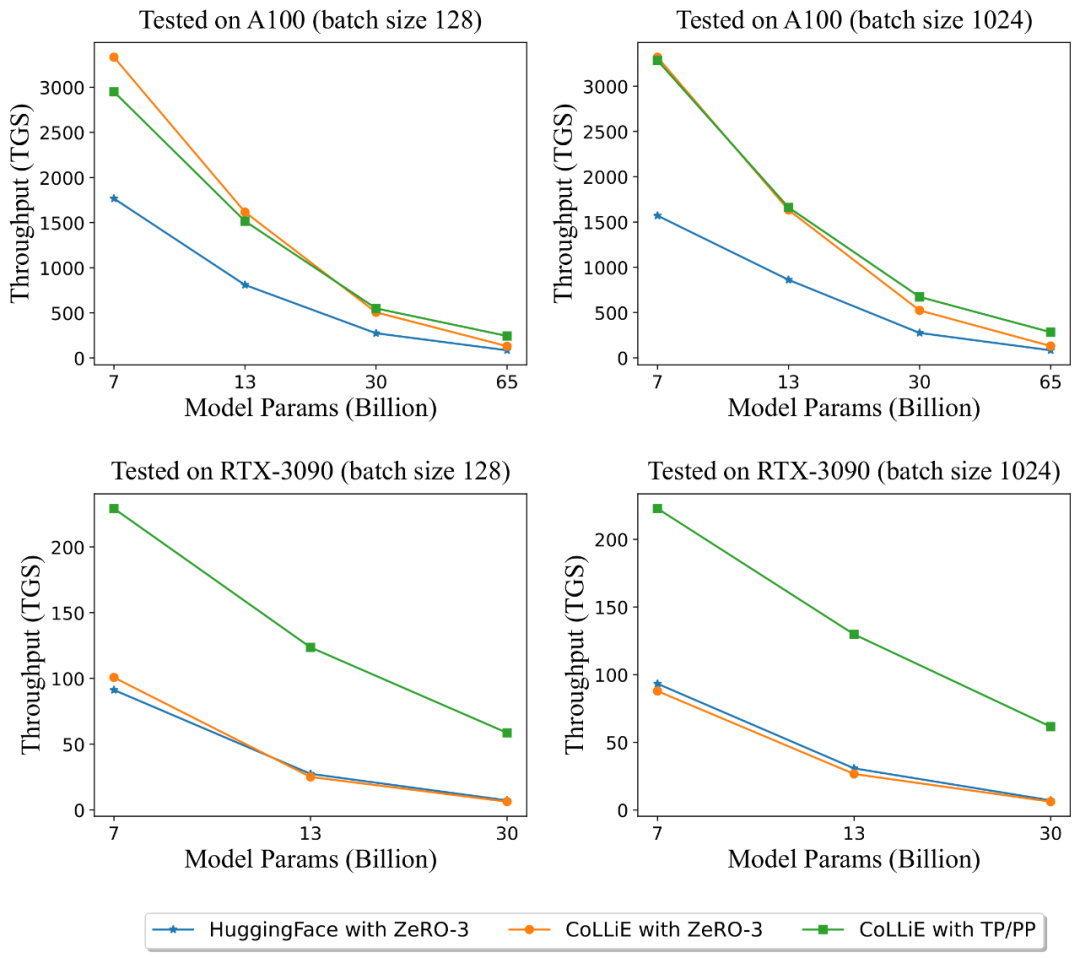
在 A100 和 RTX-3090 上测试不同批量下使用 Adam 优化的吞吐量结果
在 MOSS 2 中,团队还开发了很多的中文能力。邱锡鹏教授强调,“这个中文能力并不和刷榜一致。现在的榜单和用户实际需求差异比较大,所以我们组建了上千种的能力点,按照不同能力体系去梳理强化,对用户的使用感受会非常好。”而这些数据未来可能作为训练集和评测集公开。
多模态融合
“多模态的能力对于下一代的架构非常重要。”邱锡鹏教授表示。但是目前所谓的多模态,都是多模态进、大模型出,即输入端是多模态、输出端是多模态的文本。这并不符合要求具身智能多模态输出能力的要求。
那要怎么做模态之间的融合?团队提出了“以语言模型为中心,具有任意模态组合的输入输出能力”的思路。
实现这样的架构并不容易,特别是模态之间的任意组合是非常困难的。团队在去年 5 月份就做这方面的工作,发布了 SpeechGPT。当时,想到的一个方法是离散化。把连续的声音、图像、音频等离散化,好处是可以和文本任意打乱,也可以支持图像等输出。
以语音为例,语音是一个连续的信号,通过 Tokenizer 把语音信息离散化。研发人员可以把语音当成一个新语言,它有自己的词表,只要把词表并上去就可以去训练了。这种方式就是把语音当成一个新语言去训练。
语音当中,除了 Speech 信息之外,还具有非常丰富的情感信息需要保留。团队提出了语音离散化的工具 Speech Tokenizer,用大量语音信息来训练,做了语言信息和非语言信息之间的自动化分离,可以只提取语言信息,也可以提取非语言信息或者富语言信息。这样就可以让大语言模型直接接受语音进行交互,不需要经过 TTS,也不经过 ASR。大模型如此就具有跨模态的语音交互能力,指令可以跨模态、回复也可以跨模态,相当灵活。
“最近 GPT-4o 展示了这方面路线的前景。我们没有做到那么极致,但是 GPT-4o 展示出来的这种交互能力非常好。它就是语音进、语音出,和 SpeechGPT 大概相似。端到端的方式会让大语言模型具有很强的交互能力。”邱锡鹏教授说道。
邱锡鹏教授表示,这种想法扩展到多模态,所有的连续信号都可以 Token 化,实现任意 Token 的组合。所有的模态在 Token 后,都可以用自回归的形式生成,生成的词符通过还原器,还原成原来的模态。这就是多模态的扩展。
对齐
邱锡鹏教授透露,MOSS 2 模型训练阶段没有做过多的价值对齐,因为人类价值是非常多样化的。团队选择的是推断时对齐。推断时对齐的实现方法非常多,可以利用宪法 AI,告诉它一些准则让它遵循,也可以用一些对齐好的模型来做。
跨模态对齐现在也有非常多的方法,但邱锡鹏教授强调,现在跨模态对齐只是跨模态任务,对齐还是单模态对齐。
“一些从单模态上可以看出来,它的安全性不好。还有一些所谓的跨模态对齐,从单模态看都没什么问题,但是合在一起就有问题。比如自拍一张照片、在高楼上拍一张照片、发一些心情的内容,分开来看没有问题,但合在一起看就有问题。这就是大家需要关注的,真正要解决的是跨模态安全对齐。”
邱锡鹏团队还在模型内部做了很多可解释性方面的工作。可解释性非常难,团队就先从小任务上开始,从合成任务,比如下围棋每一步的执行,去分析 Transformer 内部的特征。最近,团队也在小规模语言模型上做了尝试,发现非常多的特征能够预测大模型,比如什么时候产生幻觉。邱锡鹏教授也举例道,有些特征和时间相关,当回复已有时间的问题时,这些特征不会激活,但是问它关于未来的问题,这些特征就激活了。
自我调控
此外,复旦大学 NLP 实验室还希望增加 MOSS 的自我调控能力。现在大模型没有自我调控,都是人为的。“之前 MOSS 部署的时候问题,希望有些场景下它的回答多样性一点,有些场景不要,当时是人为调一些比较好的参数,达到比较好的平衡。”邱锡鹏教授举例道。
而人在很多时候都是能够自我调节的,所以可以让大模型像人一样,通过心率、血压、荷尔蒙释放等调整它的行为。为此,团队就提出了一种名为 Hyperparameter Aware Generation(HAG)的范式。让大模型能够感知到自己超参的存在,然后调节这些超参,从而适应各种不同的场景。
结束语
正如 MOSS 团队当初所言,“中国版 ChatGPT 的诞生还需要中国全体 AI 从业者的努力,也更需要不断和人交互以提高能力。”很明显,团队正在努力实现自己的目标,我们期待 MOSS 2 的正式发布。




