前言
虽然企业中多数项目往往通过自定制的界面和数据载体与后台系统交互,但在办公自动化、电子政务领域仍存在大量面向包括 Word 在内的电子文档操作。区别于 Excel、Access 和 InfoPath 等数据为中心的处理,Word 更侧重于对于文章段落内容、格式的操作。
实践中,Office 自动化开发中往往要面对下列挑战:
- Office 版本更新快,但用户群更新相对较慢,项目中需要同时兼容多个版本,但 Office 产品不同版本间接口兼容性经常断裂;
- 单机版 Office 软件容易因为格式错误导致运行错误,相关进程不妥善清理很容易破坏文档造成无法修复的问题;
- 面对日益严峻的信息安全问题,很多企业内网安全策略会禁用 Office 宏、内嵌脚本和客户端渲染的处理;
- 第三方 Office 中间件技术支持力量往往无法保障,尤其是部分开源项目其适用性有限,且经常存在无法绕过的“黑盒”By Design 问题,最终不得不放弃该中间件并推倒整个设计重做。
但同时我们也要看到 Word 自动化处理中的特点:
- Word 提供模板机制,可以通过模板完成绝大部分章节段落以及文稿样式的设计;
- 尽管原始数据类型差别迥异,但实际 Word 操作中使用的类型主要是 string,图形、图表对象则可考虑集成 Visio 或 Excel 完成;
- 文档数据填充形式相对固定,一般是下列三种情况之一或组合:
- 操作一系列单独的内容区域;
- 操作一个表格区域;
- 操作单一区域。
针对上述特点,为便于重复开发量、便于开发人员访问 Word 文档须进行局部架构设计。
定义书签
但在此之前,为了简化 Word 编程,本框架针对 Bookmark 访问并操作 Word,定义方法如下:
1、打开 word 文件,选择显示 Bookmark
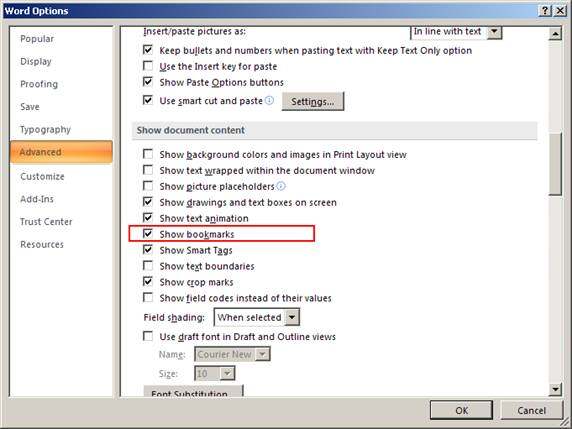
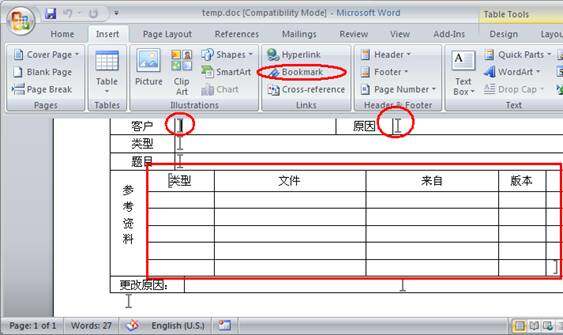
2、选择位置,然后插入 Bookmark。对于需要操作的表格区域可以选择整个区域后插入 Bookmark。
局部架构设计
抽象角度看,Word 自动化过程可归并为“读”、“处理”和“写”三个主要过程,其基本工作原理如下:
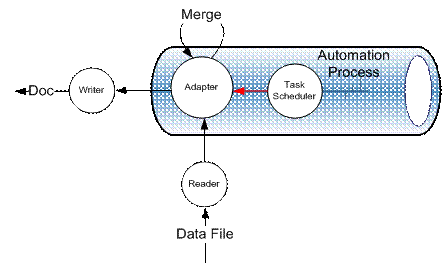
图:局部架构的工作原理
其中:
- Reader 根据数据文件类型及数据内容特点完成数据提取;
- Writer 根据目标文档类型及数据内容特点完成数据写入;
- Adapter 根据文档处理情景选择 Reader 和 Writer,实现数据和文档的合并过程;
- Task Scheduler 根据处理负载通知 Adapter 执行处理;(该部分用于扩展 Word 自动化为后台任务时定制处理过程)。
逻辑组件关系如下:
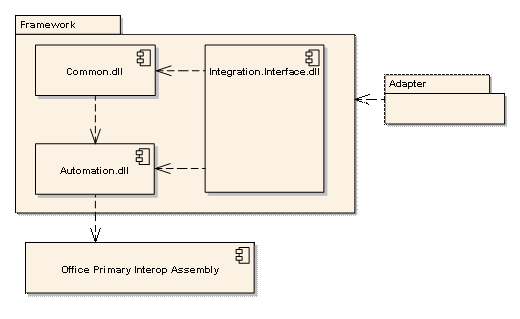
图:Word 自动化处理主要组件
其中:
- Common.dll 保存一些公共功能的编译结果;
- Automation.dll 提供对 Office 对象的(包括 Word)的封装;
- Integration.Interface.dll 则提供外部 Adapter 的规范性要求以及进一步扩展的基础;
- 而真正的 Adapter 则独立在框架外,通过配置 IoC 加载到执行环境中。
适配器部分
考虑不同项目对 Word 自动化处置的差异性,设计上将 Adapter 独立于应用之外,同时将每个 Adapter 需要执行的操作尽量固定,这样对于常规操作只需调用标准 Reader 和 Writer 即可。
(注:此外,考虑到自动化处理中文档内容的差异性,根据项目实践为提高数据的扩展性,一般推荐采用 XML 形式的数据文件。)
设计上,我们先抽象文档操作对象 Adapter 的行为接口,定义所需的数据与文档合并(Merge)操作:
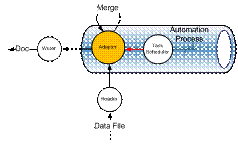

图:适配器逻辑结构
其中:
IDocumentAdapter定义基本的行为,其内容甚至可以在没有 Reader 和 Writer 的环境下完成合并工作,所有行为可以由用户程序独立定义;IGenericDocumentAdapter<TData, TString>则提供基本的操作行为,其中通过泛型参数定义 Reader 反馈的数据类型以及它对应的字符串类型;DocumentAdapterBase作为实际 Adapter 的抽象类型,不仅提供对应配置节的内容,同时进一步补充 Reader 所提取实体内容的泛型参数。
这样,通过对 Adapter 的三层封装,下游程序开发人员可以根据自动化情形的复杂程度选择适合的扩展基础。进一步,我们对 Reader 和 Writer 进行扩展,提供标准情景下标准数据类型的读写操作。
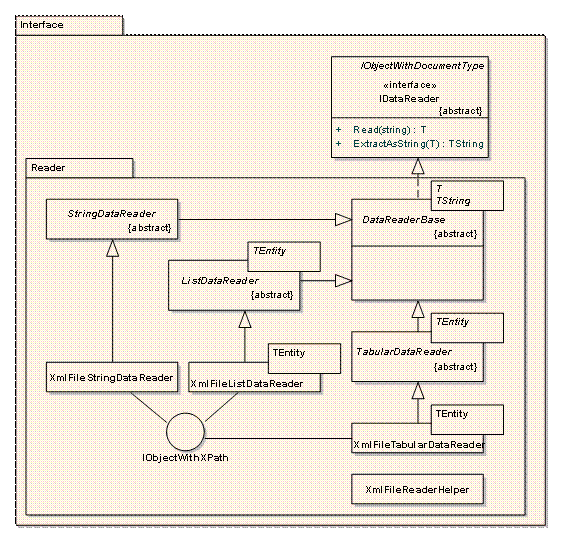
图:Reader 部分的逻辑结构
其中:
- Reader 部分默认提供针对实体组(Tabular 表格)、具有多属性的单个实体(List 列表)和单值实体(String)的读取支持,更复杂数据的读取工作可以通过组合上述 Reader 类型或直接实现 IDataReader 接口完成;
- 为了提供对 XML 数据的内置支持,提供基于 XPath 的封装类型。
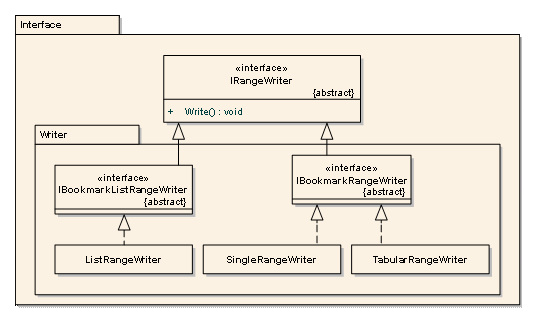
图:Writer 部分的逻辑结构
对于 Writer 部分:
- 考虑到表格内容和单值内容均可通过一个 Bookmark 定位,因此抽象出 IBookmarkRangeWriter 接口用于提供对这两类 Writer 的定制操做;
- 对于多值实体(List),由于它的写入需要一组 Bookmark 定位,因此抽象出 IBookmarkListRangeWriter 接口对该类 Writer 的操作;
自动化部分
在完成了外部调用关系的设计后,我们需要完成 Word 自动化的核心部分——通过 Office Primary Interop Assembly(Office PIA) 访问 Word 的基本操作。
图:项目中引用 Office 的 PIA 库
实际使用中,Word 对象模型如下:

图:Word Object Model(摘自 MSDN Microsoft Visual Studio Tools for the Microsoft Office system (version 3.0) 部分)
其中,Application 代表一个 WinWord.exe 进程,对其打开关闭代价较大,频繁的打开、关闭势必会对后台文档自动化带来较大的运行负载,为此,需要集中控制。而每个 Word 文档可以通过 Document 获得引用,然后通过 Bookmark 检索到对应的区域 (Range),进而通过 Writer 操作 Range 对象,填充、清除、修改该区域的内容。此外,考虑到类似电子表格的合并操作,往往外部数据记录数量超过 Word 模板(或文档)表格区域的大小,为此还需增加必要的 Add Row 方法、Add Column 方法,本文示例为了简便,只设计了 Add Row 方法。
综上,Word 自动化部分设计如下:
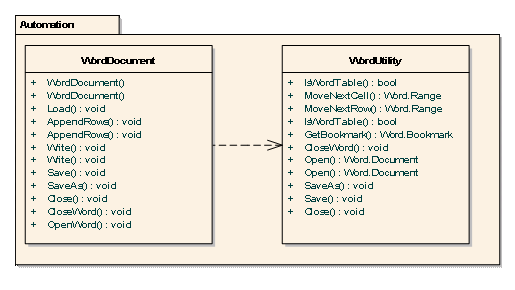
图:Word 自动化部分设计
配置
为了减少客户端程序的工作量,常见的操作参数保存在配置文件中,这样我们定义整个模型的自定义配置节如下:

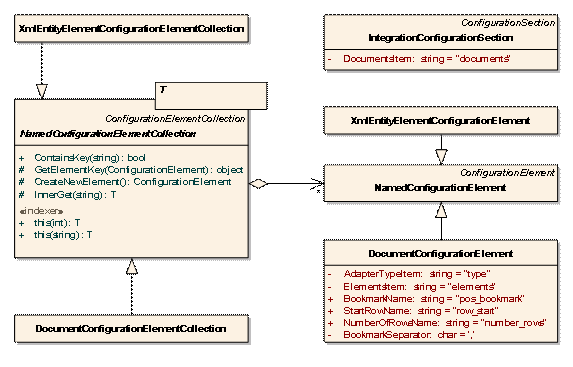
图:配置对象
其他
虽然直接调用 Word PIA 接口可以较快的完成一个具体 Word 自动化处理,但随着用户需求的变化,该类项目往往必须面临经常性的修改,为了尽量将修改控制在局部、提高下游开发人员的使用效率,一般可以通过对局部进行架构建模提升自动化框架的灵活性,而额外的工作量主要集中在抽象出 Reader、Writer 和根据文档操作目标定义相关的 Adapter。
示例
完成上述内容后,我们可以通过三个示例验证上述局部架构的适应性。
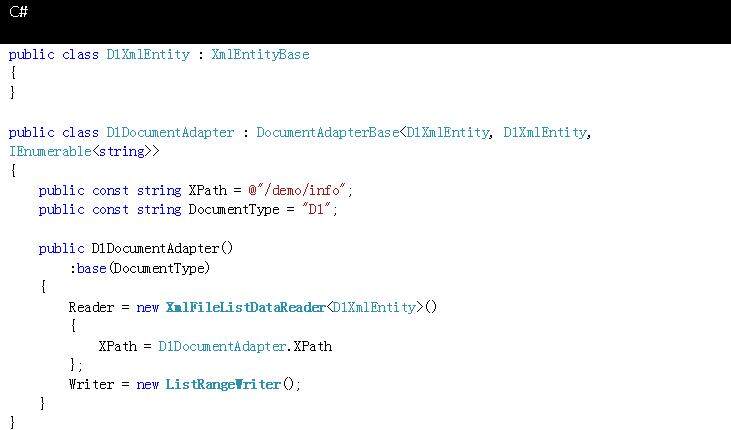
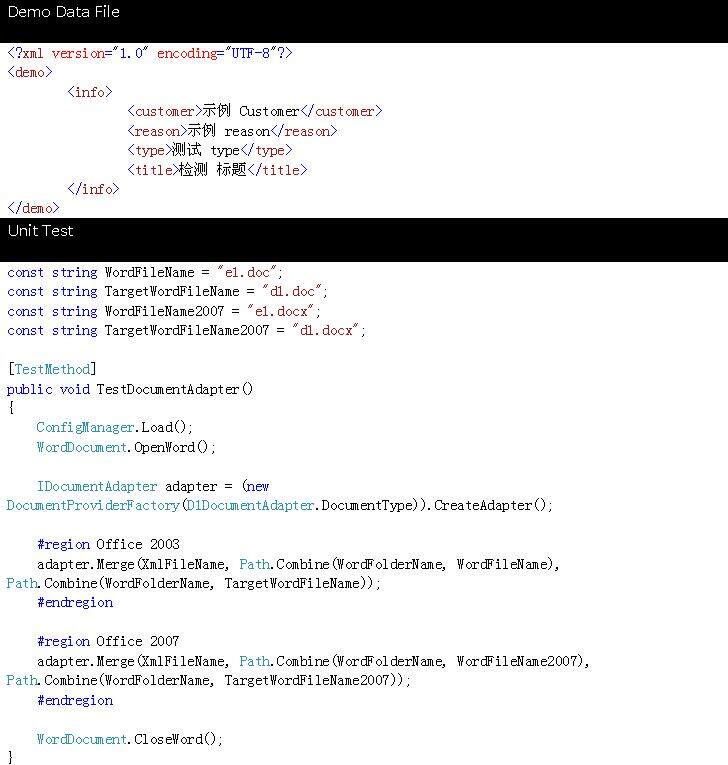
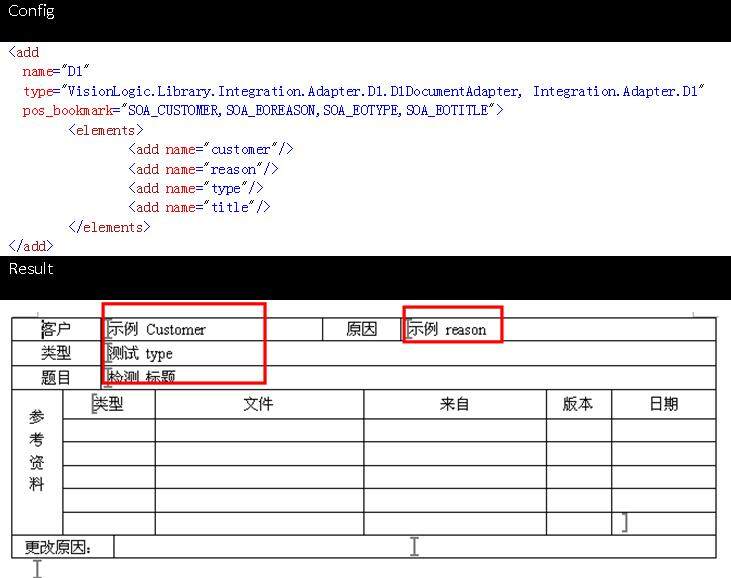
示例 1:操作单个多值实体
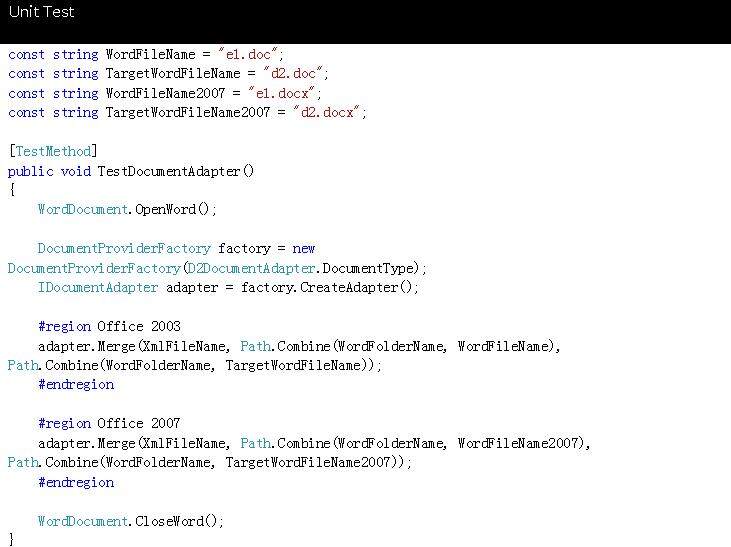
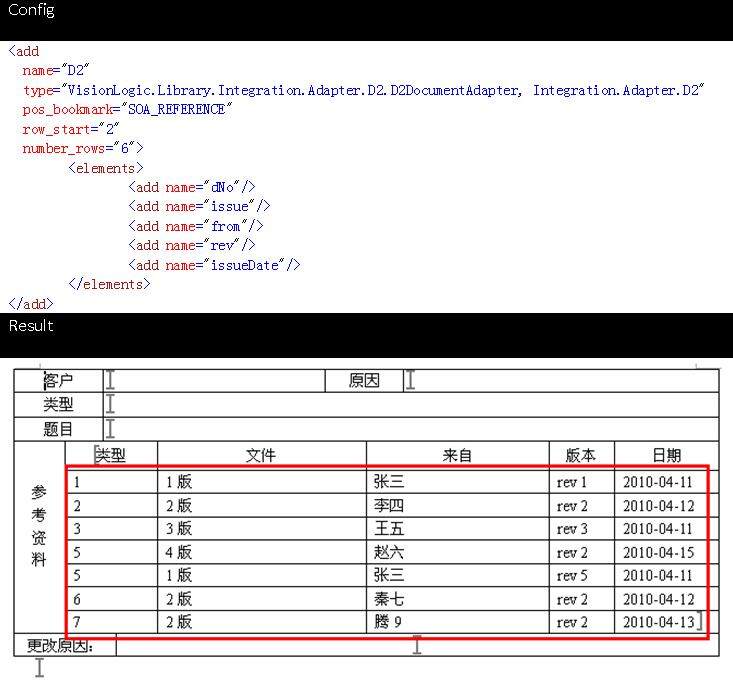
示例 2:操作 Word 中的表格
为了操作 word 中的表格,Reader 往往可以从数据文件中提取一组多值实体。
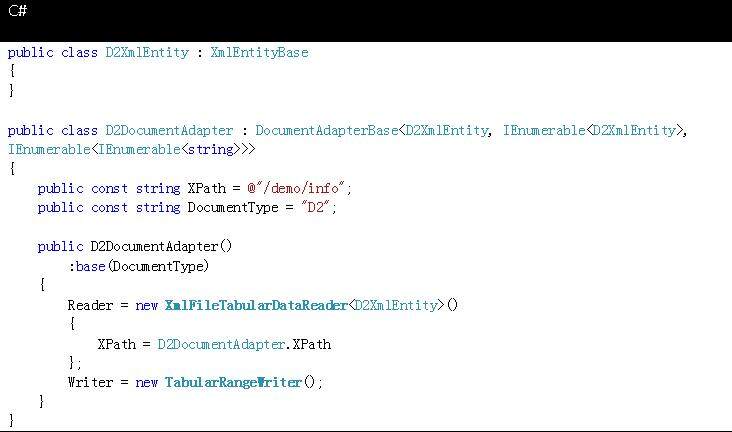

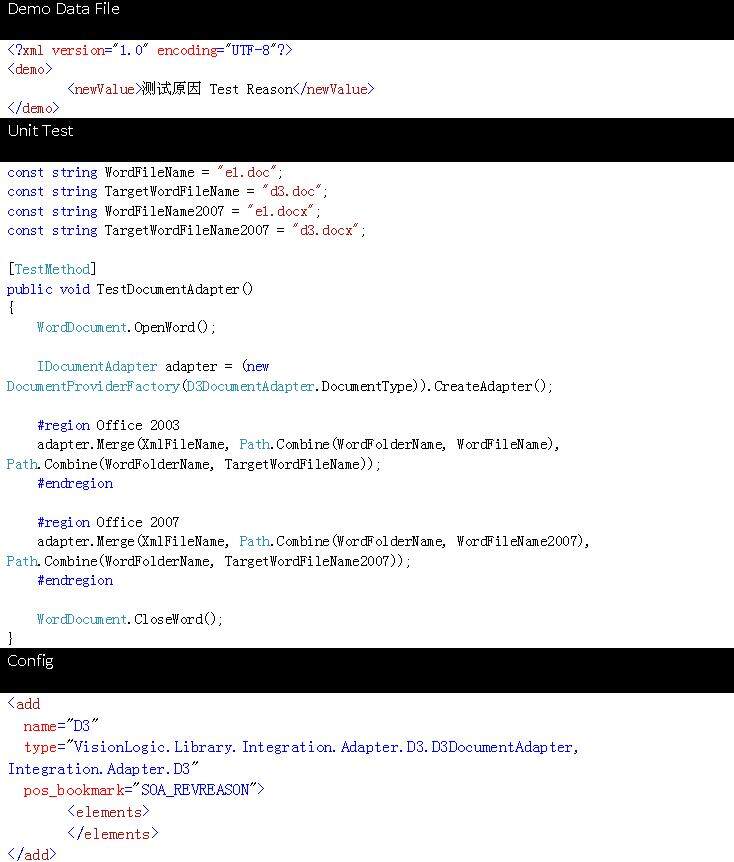
示例 3:操作 Word 中的单值对象


下载示例代码
点击下载示例代码。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家加入到 InfoQ 中文站用户讨论组中与我们的编辑和其他读者朋友交流。




