
ClickHouse 版本的“云数据库是不是杀猪盘”?
ClickHouse 最近发表了一篇精彩的文章,描述了 Snowflake 和 Redshift 等云数据仓库已经不能满足新的客户需求,并且指出许多企业已经发现他们的云数据仓库成本是不可持续的。
“云数据仓库的成本呈指数级增长”,“我们感谢云数据仓库多年来的辛勤付出,但它们引领的霸权时代即将落幕”。
在这篇文章中,他们还探讨了数据库技术的发展,认为成本将成为一个重大的痛点,从而促使企业重新评估其数据堆栈。
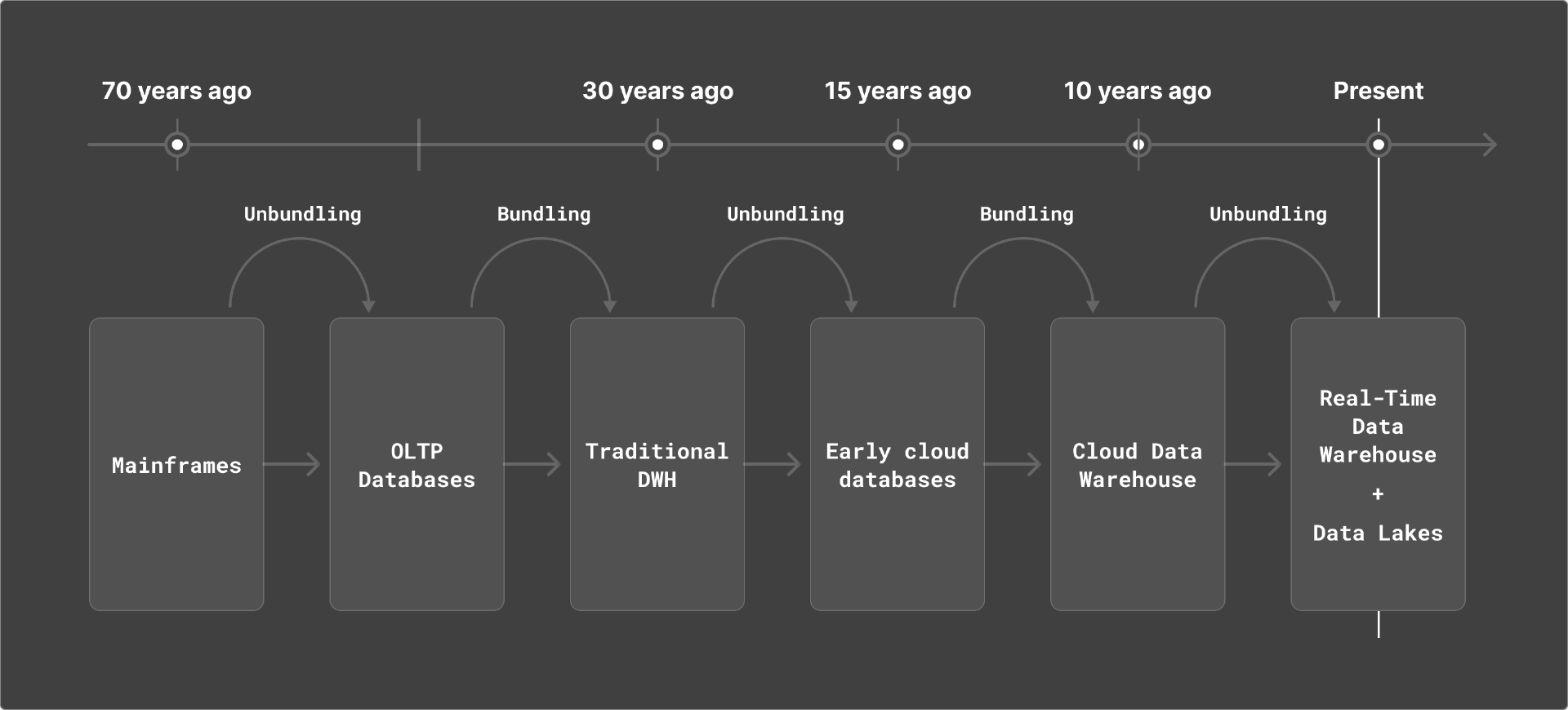
数据生态系统的演变
数据生态的演变,经历了从大型机到关系数据库,再到传统数据仓库,再到早期的云提供商的过程。在过去十年里,像 Snowflake 这样的厂商推动了整个行业的现代化,打破了以往高度依赖封闭且专有的自我管理型部署生态(主要由甲骨文、Teradata 等提供)的传统。
新方案帮助组织将 PB 级关键工作负载迁移至云端,将这些数据集开放给更广泛的集成、协作与应用程序,由此实现了数据访问普及化并创造出巨大的市场价值。
但随着时间推移,企业开始认真审视自己的数据存储架构,考虑其中信息的具体性质以及能够实现的潜在用途。随着组织数据获取门槛的逐渐降低,开发团队开始从静态批量报告转向建立交互式应用,在供内部使用的同时也可以对外发布。
而到了这一步,云数据仓库的短板也开始暴露出来。此类存储方案专为离线报告模式而设计(目前仅运行在云基础设施当中),因此其架构与计费模式并未针对作为交互式数据驱动应用的后端进行优化。
于是乎,组织往往面临着性能不佳(响应时间从数十秒到几分钟不等,无法做到亚秒甚至是毫秒级响应)、成本飙升(通常是替代方案的 3 到 5 倍)以及查询并发性过低(不适合对接外部应用)等现实难题。
传统云数据仓库的局限性日益凸显
传统数据仓库已有多年历史,在设计上主要服务于离线和批量处理时代下的统一内部业务报告,而且大多具有以下特征:
依靠大批量 ETL 作业从源系统中移出数据;
对大表进行大规模 join,借此将不同数据集统一起来进行集中查询;
通过静态“views”或“marts”供不同团队使用特定数据集。
以 Snowflake、BigQuery 及 Redshift 等平台为主导的云数据仓库,大多专为特定类型的重要数据工作负载提供可扩展性、便利性,以及最重要的灵活性与开放性,借此实现数据仓库的现代化改造。
然而,随着这些数据登陆云端,数据仓库的固有应用边界也被很快打破,迫使云数据仓库成为一种“一刀切”式的解决方案,全面承担起服务器端转换、仪表板、可观察性、机器学习等各类面向用户的分析用例。但受其自身局限性影响,云数据仓库开始成为性能问题、用户体验下降及成本失控的根源,对数据架构的重新评估已经刻不容缓。
交互式、数据驱动的应用场景正成为主流
对于已经发展成熟的行业来说,人们更倾向于把构建各种新兴应用的趋势理解成利基性质的小众需求。如果去询问传统数据仓库架构师,他们很可能仍然坚称“批量数据摄取和报告”仍是正确答案……但事实并非如此。
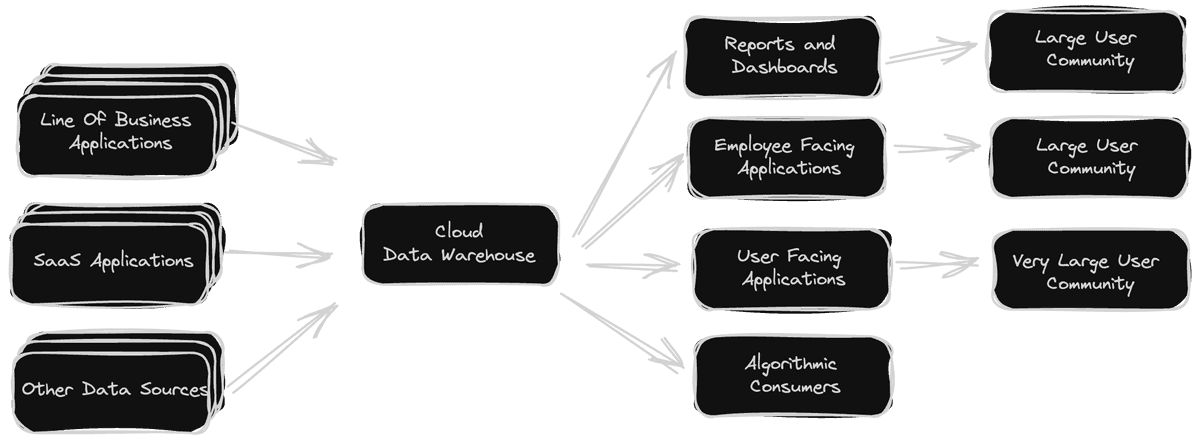
如今,营销、销售、工程、运营等各个部门的专业人士都需要频繁使用交互式、由数据驱动的生产力应用,其特征就是以高度交互的方式对大量数据执行分析。例如,作为营销人员,我们需要了解谁访问过产品网站、谁在关注社交媒体帖子,已发布广告的接受情况如何等——所有这些都必须实时获取答案。作为一名金融分析师,大家需要在快速变化的市场中迅速反应,每天多次做出决策。而对于负责 24/7 SaaS 服务的 DevOps 工程师,我们则很可能要对应用程序的可用性提出极为严苛的要求——正常运行时间至少要达到 99.999%,即每年只能容忍 5 分钟的停机时间!
于是乎,全新的行业由此诞生,其服务对象就是那些无法通过传统数据仓库解决、而只能借助实时数据仓库的业务需求。
营销分析,提供来自多种渠道(包括网络、社交媒体、广告活动)的宣传效果,对信息进行总结,并允许营销人员运行交互式查询及报告功能,主动显示海量数据中的异常值(例如快速增长的区域、子市场或行业),并提出营销支出优化建议。
销售分析,显示各销售区域的具体活动,例如按来源划分的销售线索流、免费/试用产品接受情况、销售周期活动、售后消费、账户健康状况以及客户流失数据等。汇总这些数据并主动提取出重要信息之后,销售专业人士可以据此评估不同措施的机会或风险因素,把握住关键潜在客户并发现态度摇摆的风险客户。
电子商务与零售分析,涵盖整个零售生命周期——从营销到库存、再到销售活动和商品配送,全程实现对数据的长期跟踪与交互式查询,并主动提出物流运营的优化方法。
金融分析跟踪金融工具的具体操作,包括买入、卖出、看跌期权、看涨期权,并允许分析师根据此类信息选择标准及建议的行动(包括潜在的后续交易与对冲操作)。
可观察性与物联网监控,要求从 SaaS 基础设施或制造车间/设备处获取结构化日志、指标并跟踪事件,将结果与设备和用户信息等元数据交叉引用,据此总结错误与延迟信息,并结合历史数据预测可能发生故障的区域。
分析类应用的内部用户包括产品、营销及业务分析师,他们也是数据仓库系统上的主要目标受众。但这些用户明显不再满足于缓慢的分析体验。为了保持职能竞争力,他们必须加快数据驱动的决策速度,而如果内部数据平台无法满足要求,他们则会提议采用更快、交互式表现更好的第三方工具。
除了现有内部用例之外,企业内部的 AI/机器学习团队也在逐步扩大,内部数据科学家也需要访问并查询数据以开发出更好的机器学习模型与 AI 功能。数据科学家对于交互性能同样高度关注,因为查询速度将直接决定他们发布新机器学习模型、构建 AI 新功能的效率。
云数据仓库的短板
在这些场景下,云数据仓库的表现往往令人头痛。由于传统数据仓库的架构与计费模式缺少针对性优化,所以无法充当交互式数据驱动应用的高效后端。此类应用通常要求数据仓库具备以下能力:
将连续加载的数据与历史数据(周期长达数年)相结合以提供查询服务;
在高交互访问模式下提供高并发查询,例如复杂的过滤与聚合操作;
为沉浸式应用提供必要的低延迟查询(理想情况为亚秒级);
处理高达 TB 甚至 PB 级别的历史数据,且每秒能够处理数百万次事件摄取。
而目前的云数据仓库明显表现乏力:
数据传播延迟。由于经由复杂 ETL 管道进行的数据传播往往会有数小时的延迟,而且高度依赖于非规范化的数据集(需要昂贵的 JOIN 并拖慢应用的运行速度),因此内部数据工程团队很利用传统数据仓库满足日益提高的服务需求,而且在遗留架构上支持实时查询将产生高昂的财务成本。
查询性能低下。用户获取查询结果的响应时间往往长达几十秒甚至几分钟,远远达不到毫秒级的延迟需求。如果希望投入更多算力来提高查询性能,那么成本这个老问题又会制约可行性。
成本飞涨。与替代方案相比,云数据仓库的用户往往需要承担 3 到 5 倍的高昂成本,且性能低于一般标准。而且在更高的成本之下,其架构需要消耗更多的系统资源才能处理相同的工作负载。
查询并发性低下。如今,用户对于查询并发性的要求远高于传统数据仓库的设计预期——成百上千的用户会同时运行查询,希望把延迟控制在毫秒级别,同时要求把成本控制在合理水平。
最终,云数据仓库只能通过成本方面的过度投入来暴力解决服务延迟、工作负载交互等需求——要么为 Snowflake 中的物化视图等高级功能支付更多费用,要么投入更多算力资源来加快 BigQuery 中的查询处理。
这就像是投入巨资改造一辆旧车,指望它能在激烈的竞速比赛中获胜——正确的思路,显然是用更低的价格直接购买一台赛用车辆。
云数据仓库的成本呈指数级增长
有 ClickHouse 其他相关专家总结说,随着未来发展,云数据仓库已经变得不经济,它根本不是为实时工作负载和高度并发的访问模式而设计的。因此,我们唯一的选择是增加更多的计算量,这使得它们的扩展成本非常昂贵。
从业务案例的角度来看,云数据仓库可以根据用户需求进行扩缩。许多具有普通 BI 需求的企业每月仅运行几个小时的云数据仓库来支持不频繁的访问模式和过时的数据就可以了。然而,在新世界中,我们需要有更多的服务器以更长的正常运行时间运行,以便支持所有并发用户的苛刻要求。这样的话,你会发现,如果我们假设它 24x7 运行,即使是 Snowflake 等平台的小型部署也会变得非常昂贵。

在模拟的小型部署中,Snowflake 每月需额外花费 187 美元。
如果在随后需要支持更多并发用户时,这种情况会显著放大。如果我们天真地通过添加更大或更多的服务器来进行扩展,那么我们将不可避免地面临昂贵的始终在线成本,并且这些成本将呈指数级变化。

在模拟的大型部署中,Snowflake 每月需额外花费 11899 美元。
在实际的大型企业部署中,这可能会迅速变成数百万美元的增量。对于高用户负载、始终在服务器上和高并发的云数据仓库来说,其经济性非常糟糕。
写在最后
现有数据技术栈高度依赖传统数据仓库,ClickHouse 建议引入实时数据仓库概念,用数据湖+实时数仓方案,脱离单一云数据仓库的演变趋势。
云数据仓库实现了许多人认为不可能的任务:将庞大的分析型任务从类似大型机管理的专有解决方案迁移到云端。这种演变最终引发了对如何利用仓库数据构建日益互动的数据驱动应用程序的深入研究,并导致了云数据仓库分拆的趋势不断增长。ClickHouse 认为,通过分拆、采用单个分析数据库可以减少大量的 ETL 工作,借助简化的架构节省大量的工程和管理时间,同时降低潜在的许可和托管成本。
参考链接:
https://mp.weixin.qq.com/s/qofX4mHYUy7TkR3JQ-dEsA
https://ClickHouse.com/blog/the-unbundling-of-the-cloud-data-warehouse
https://ensembleanalytics.io/blog/why-cloud-datawarehouses-too-expensive




