

1、序言:广告排序机制的前世今生
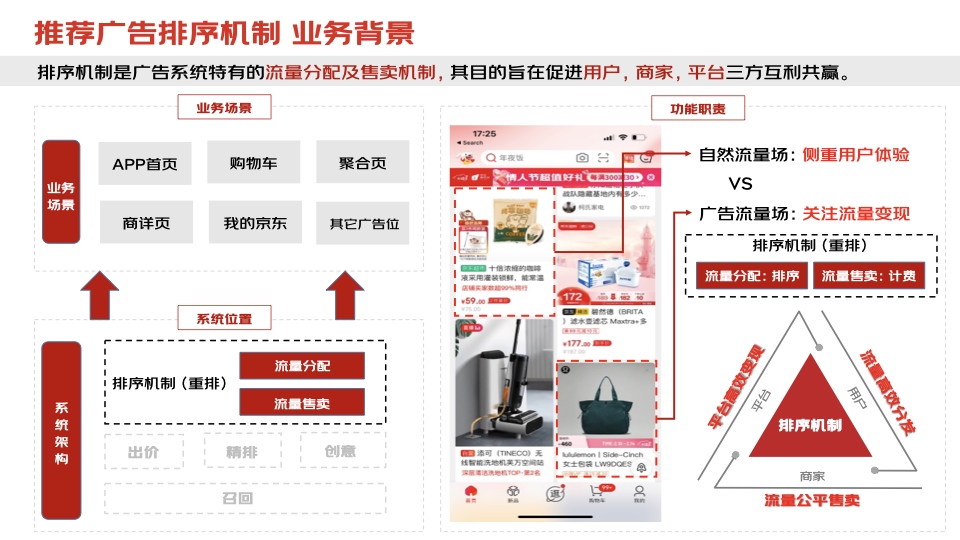
1.1、简介:广告排序机制
在线广告是国内外各大互联网公司的重要收入来源之一,而在线广告与传统广告最大的区别就在于其超大规模的实时竞价环境:数以万计的广告主在一天内可以参与亿级别的流量竞拍。在这复杂的实时竞价环境中,广告系统的重排模块(Rerank)担负着确定流量最终分发以及计费方式的重要职责。其中,流量分发会决定最终曝光的广告物料,而流量计费则会对曝光广告进行合理的收费,转化为广告收入。
不同于自然搜推系统侧重用户体验的场域定位,广告流量场考量的是在用户体验约束下的流量变现问题。在这个背景下,传统重排模块(Rerank)在电商在线广告中的业务定位发生了相应的变化,需在原有多业务目标(点击、GMV、时长等)基础上进一步兼顾平台广告收入,同时对胜出的广告进行合理公平的计费。由于其特殊的业务属性,广告系统中的重排有时也被称为广告排序机制,其目的旨在促进用户、商家以及平台三方互利共赢。
结合业务背景和系统功能,我们将广告排序机制的目标 定义如下:
广告排序机制目标:根据系统上游提供的物料(召回 / 粗排)及 流量价值预估值(精排 pctr、出价 bid 等),综合考虑 用户体验(上下文、多样性等)、平台收益(点击、收入、GMV 等),设计激励相容(鼓励广告主说真话)的拍卖机制(分配和计费规则)。
1.2、前世:经济学视角下的传统拍卖机制
在排序机制目标中我们提到了激励相容(鼓励广告主说真话),事实上,激励相容是经济学中机制设计的重要原则之一。下面,我们简要回顾一下传统拍卖机制的经济学相关背景,
1.「机制设计」从经济学的视角来看,广告流量的分配及售卖可以被看作是 机制设计(Mechanism Design)【1】中的一类问题,拍卖机制设计及其相关工作在过去 60 年中,先后四次获得诺贝尔经济学奖。经典拍卖机制如 GSP、VCG 由于其良好的博弈性质以及易于实现的特点使其在 2002 年前后开始被互联网广告大规模的使用。
2.「广告主类型」传统拍卖机制往往假设广告主是利益最大化(Utility Maximizer)的,即最大化 GMV 与成本的差值,然而,随着智能营销手段在广告投放端的普及,越来越多的广告主通过向平台表达期望成本和目标,借助智能出价的算法能力进行广告实时投放,广告主的类型逐渐转变为价值最大化(Value Maximizer)【2】,即在满足成本约束的条件下最大化分配价值(例如 GMV),而非单纯追求差值的最大化。
3.「激励相容约束」鼓励广告主在平台按照真实意愿出价是拍卖机制设计中一项非常重要的经济学约束,激励相容的拍卖机制通过鼓励广告主说真话,大大简化了出价策略设计,优化了博弈环境,同时也为平台设计收入最大化的机制提供了更便捷的抓手。
4.「个体理性约束」除了激励相容的约束以外,一个良好的拍卖机制还需满足个体理性的约束条件,简单来说,个体理性的约束条件要求平台对广告主的最终收费不高于广告主的出价,保障广告主的最低收益非负。
1.3、今生:电商场景下的推荐广告排序机制
随着互联网广告的飞速发展,流量增长迅速,用户规模及行为都更加庞大且丰富,广告物料也从原来简单的商品展示,拓展到了包含聚合页、活动、店铺、视频以及直播等多种多样的物料类型,此外,广告主的目标和表达方式也从原先的手动出价,转变为了由平台代理的,带有预算和成本控制的智能出价。因此,广告排序机制的设计也遇到了许多新的挑战。结合京东业务场景,我们总结了以下三个问题与大家分享:
1.「多元物料价值可比」:更为丰富的物料类型(活动、店铺、直播等内容类广告)需要更为准确和全面的物料价值预估,使得多元的物料价值可比,进而提升流量分发效率;
2.「模糊用户兴趣捕捉」:相比于搜索广告与用户搜索 query 强相关的广告展示结果,推荐广告的用户兴趣更难精确捕捉,需在流量分配环节兼顾用户兴趣的探索和利用;
3.「信息流多物品拍卖」:信息流广告序列级别的分发和售卖的场景是经济学中典型的多品拍卖问题,与单品拍卖不同,多品拍卖面临着指数级增长的机制搜索空间,复杂的出价策略空间以及更难满足的激励相容约束条件等问题,是学术界和行业的公认难题。
为了更好地刻画上述提到的三个挑战,我们将排序机制的问题进行了以下数学建模。 在上文中我们提到,机制要解决的问题是如何基于上游提供的信息(物料、价值预估),完成在用户体验约束下流量的高效分发以及变现。
流量的高效分发依赖于我们对流量价值的精准衡量以及高效的探索利用机制,将流量质量简写为 adq,我们有

其中,pctr 为上游精排给出的点击率预估值,bid 为广告主的出价,e 为扰动项用以建模探索力度,映射 f 则决定流量价值的融合排序关系。可以看到,流量的高效分发依赖于对流量单点价值的准确衡量(函数内的重要因子如 pctr、bid 等),以及流量高效探索利用的分发机制(即 e 及映射关系的设计)。对于流量的变现问题,与单品拍卖设计一样,需设计适配流量分发机制的计费方式,来保障机制的激励相容,假设了一次请求曝光四个广告,广告收入可以拆解为
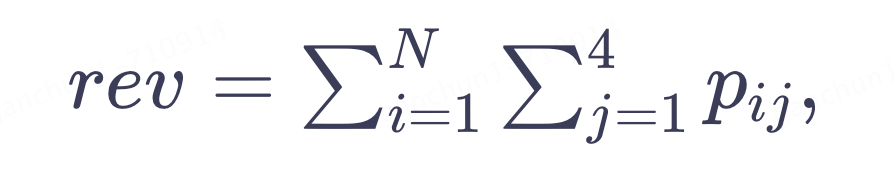
其中,pij 为第 i 次请求对第 j 个广告的扣费。因此,我们可以将问题进一步拆解为以下三项。
1.「流量价值精准衡量」:在物料形式丰富多样的环境中,如何将流量分发依赖的重要排序因子(pctr、bid 等)预估准确?
2.「流量高效探索利用」:在用户兴趣模糊难捕捉的情况下,如何设计一套高效的利用和探索(映射 f 以及探索扰动项)分发机制?
3.「流量高效公平变现」:在推荐信息流广告多品拍卖场景下,如何设计一个适配的计费方式,在保证机制激励相容(DSIC)的同时,提升平台收入(rev)?
下面,我们结合京东推荐广告排序机制演化发展的路线,给出我们对这三个问题的思考和解决方案,也希望抛砖引玉,与大家一起进行探讨。
2、正文:京东推荐广告排序拍卖机制演化
2.1、价值先行:复杂业务场景下的流量价值准确衡量
随着电商业务的飞速发展,推荐物料展示形式从一屏单品、单一商品形式逐渐拓展到一屏多品、多样物料形式(包括商品、店铺、活动页、聚合页)的复杂业务场景,如何统一且准确衡量不同物料的价值,是困扰排序机制的一大难题,为此,我们从京东业务场景出发,重新审视排序阶段的价值理解,通过对单点价值进行更准确地预估,全局信息更深入地使用,实现了复杂业务场景下的流量价值准确衡量。
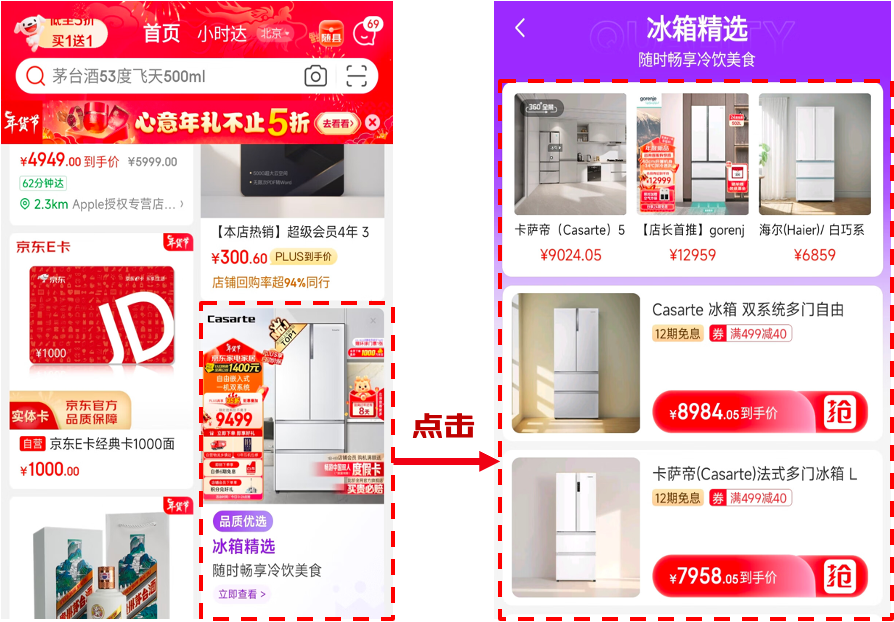
「用户行为的 MDP 建模」京东推荐广告信息流场景每次以一个组合形式曝光,如下图所示,用户访问京东 app,浏览推荐场景时是一个典型的马尔科夫过程(MDP),对于某个曝光序列组合,用户可能发生点击、下翻和退出等动作,针对某一个序列排序价值,我们拆分为当前价值、点击后价值、下拉后价值。很自然地,我们可以将不同的候选曝光序列作为不同的状态(State),用户的点击、下翻以及退出等常见操作作为动作(Action),点击率、下翻概率以及退出概率作为转移概率(transition probability),收集用户后验反馈作为奖励(reward)。

由点到线:从单点到全局的价值预估
传统排序机制通常使用以 ctr 以及 ecpm 作为重要排序因子,然而,根据上述 MDP 建模,我们可以清楚的看到 ctr / ecpm 只反映了当次请求的价值,并没有准确反映这次请求在内页 / 剩余访问带来的整体价值。事实上,一次请求不仅在曝光的当下产生价值,某个物料在被点击或者序列被下翻后也依然产生价值,这两个动作分别通过点击概率和下翻概率与当前曝光发生关联。
因此,针对某个曝光物料,我们定义点击进入内页后产生的点击和消费为内页价值,并搭建了一套与精排并行的预估系统;针对曝光序列,将优化的视野从单个请求扩展到会话,最大化考虑在更长时间范围内的价值,为此,我们定义下翻进入下一页产生的点击和消费为序列下翻价值,并在精排模块之后搭建了长期价值预估模型,负责对下翻概率和下页价值进行预估。
相比于点击率预估的二分类任务,内页价值和长期价值是连续值,是典型的回归任务,这种任务受离散点的影响比较大,而且有效样本更稀疏(有效正样本为外页发生点击且内页有行为样本),样本内分布差异大。此外,不同于时长预估任务【3,4】,价值预估任务还存在预估时看不到内页信息的 partially observable 等问题,这些都是准确预估内页价值和下页价值面临的特有挑战。针对以上这些问题,我们通过将回归问题分类化、多场景多任务联合建模、先验信息辅助、离线蒸馏等方式,显著提高了模型的价值预估能力,为流量价值的高效分发打下了坚实的基础。
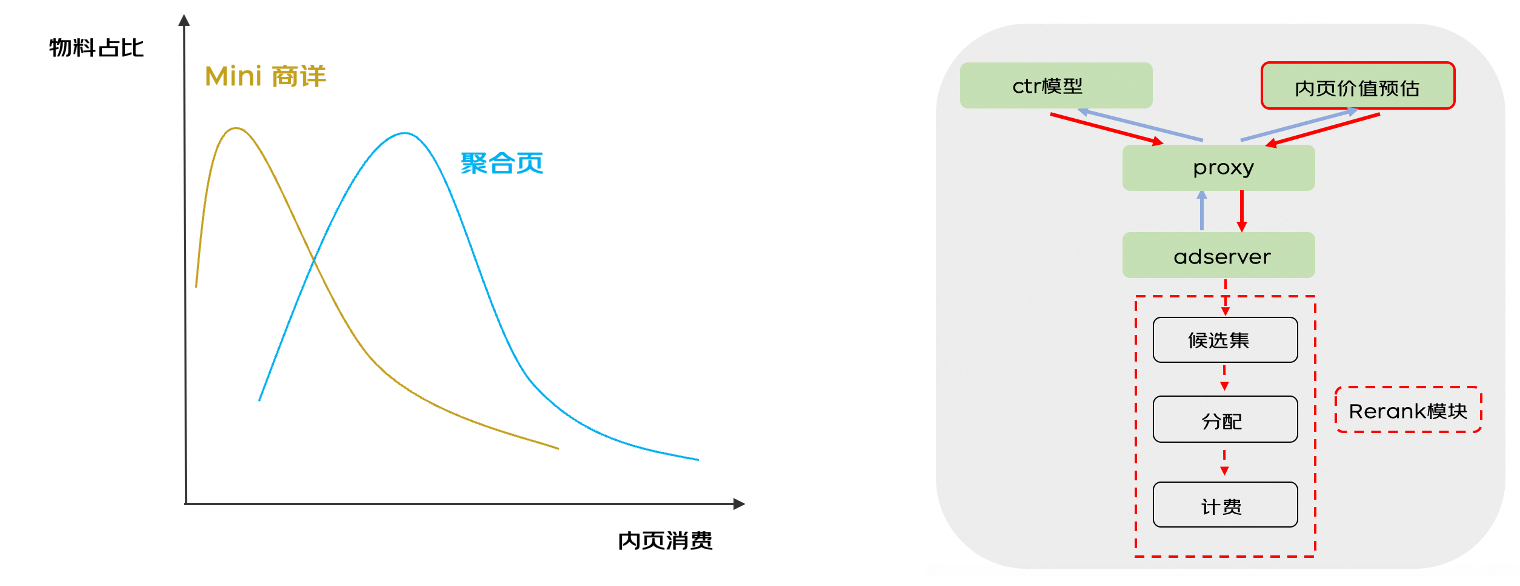
点线成面:基于异步计算的价值校准
价值预估模型考虑的是单个物料的全局价值,然而信息流广告是多坑位曝光形式,单个物料的价值(点击率、内页价值等)不仅受到当前物料影响,而且还受到周围其他物料影响(例如,某物料内页价值特别高,说明内页具有极大吸引力,用户进入内页后再退出外页的意愿显著降低,那么周围其他物料的点击率将受到明显影响),仅基于单点信息的前序模块预估值存在严重偏差。
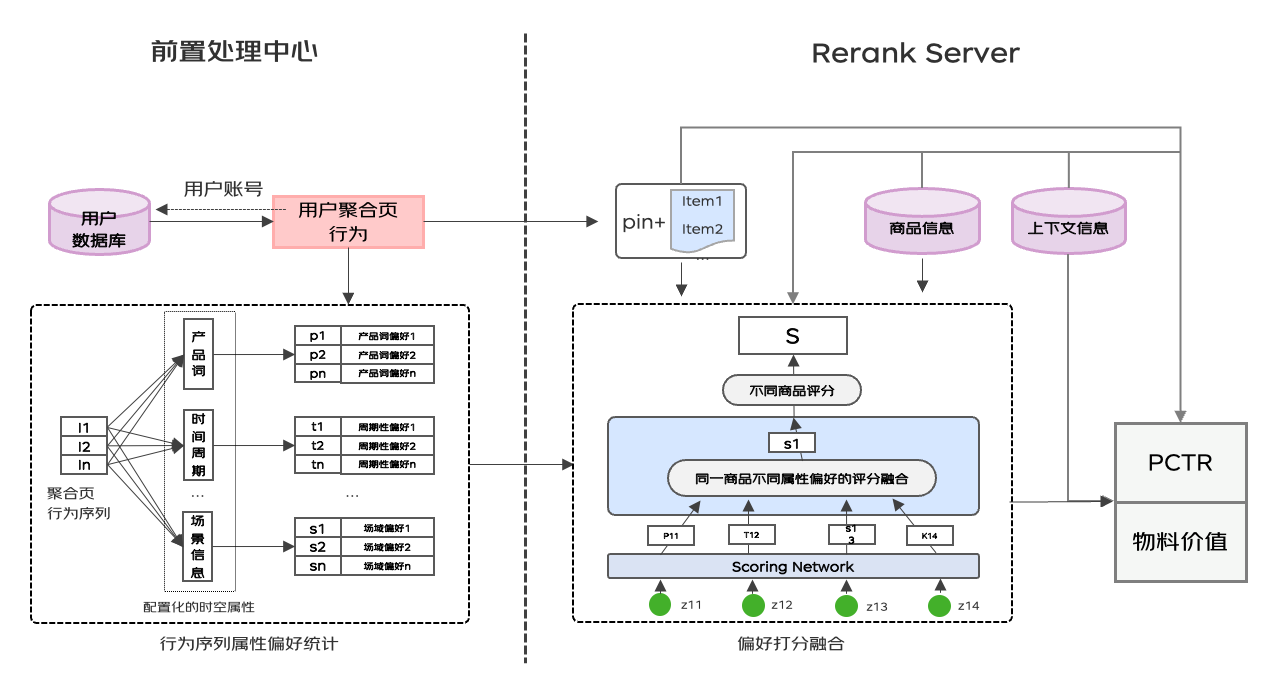
相比于精排阶段,重排阶段拥有更丰富准确的序列信息、内外页信息和下翻概率等全局信息。由于重排环节位于系统的出口处,可用的耗时空间有限,无法进行大规模复杂的特征提取和计算,因此,我们采用了异步前置计算的方式,利用前链路充足的耗时以及算力空间,提前计算价值校准需要的序列以及候选队列信息,同时我们在重排阶段引入了价值纠偏模块,对序列内各物料的点击率、内页价值等指标同时做校准。对于点击率校准任务,采用曝光未点击做负样本,曝光点击做正样本,对于内页价值校准任务,以点击消费数据为正样本,点击无消费数据为负样本,曝光未点击数据作为中间样本,使用 stop-grident 阻断中间样本对内页价值预估任务的影响。通过异步计算在耗时约束下引入全局信息,同时建模序列点击率和内页价值信息相互学习,在价值校准模块实现离线 auc 以及 rmse 指标的双提升,上线带来了显著的收益提升。
2.2、柳暗花明:模糊用户兴趣场景下的的流量高效探索利用
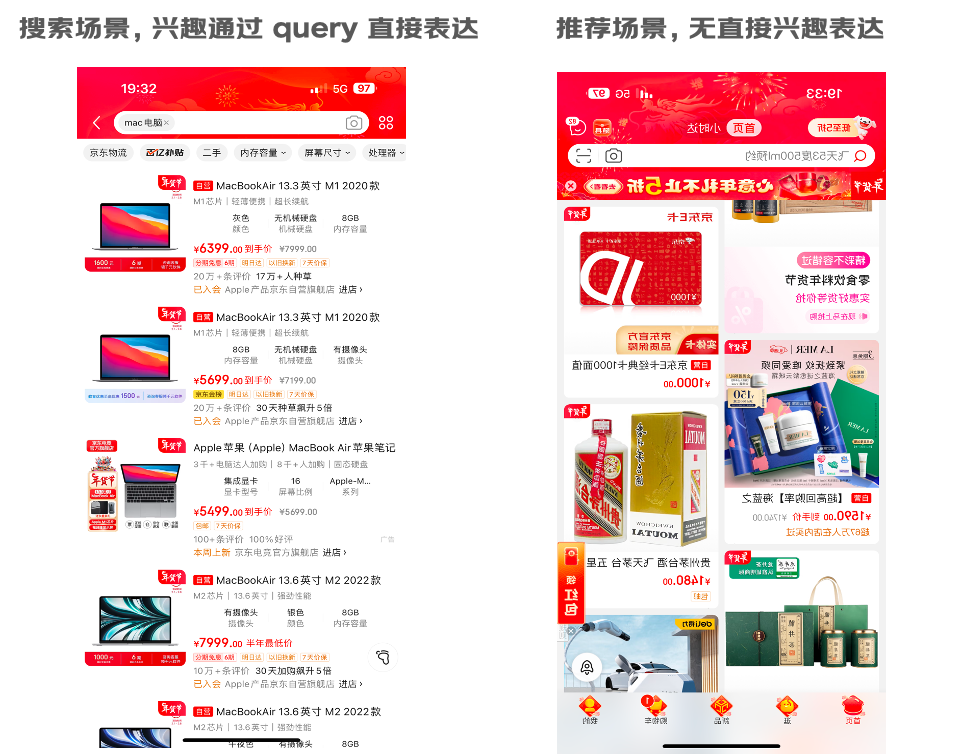
不同于搜索场景下用户有明确的意图表达,推荐场景中无用户 query ,无法获取直接兴趣,若过于关注相关性而推荐用户历史经常访问的类目,则无法满足用户的潜在兴趣,带来信息茧房效应,导致用户厌烦,极端情况还会产生投诉和舆情;流量的高效探索利用同样也存在很多难点。首先,流量的探索利用依赖召回、精排、重排等全链路的工作,难以单点优化;探索往往与平台短期目标(点击、收入)呈负相关,如何实现探索与利用的平衡是一个挑战;不同用户对探索的偏好是个性化的,探索偏好需做到千人千面,然而用户对于曝光列表的探索偏好真实反馈难以直接获取,导致探索的端到端学习目标难以量化。
针对模糊用户兴趣场景下的流量高效探索利用问题,我们从基于用户兴趣的商品预训练【5,6】,以及系统化探索【7,8,9】两个方面进行建模。
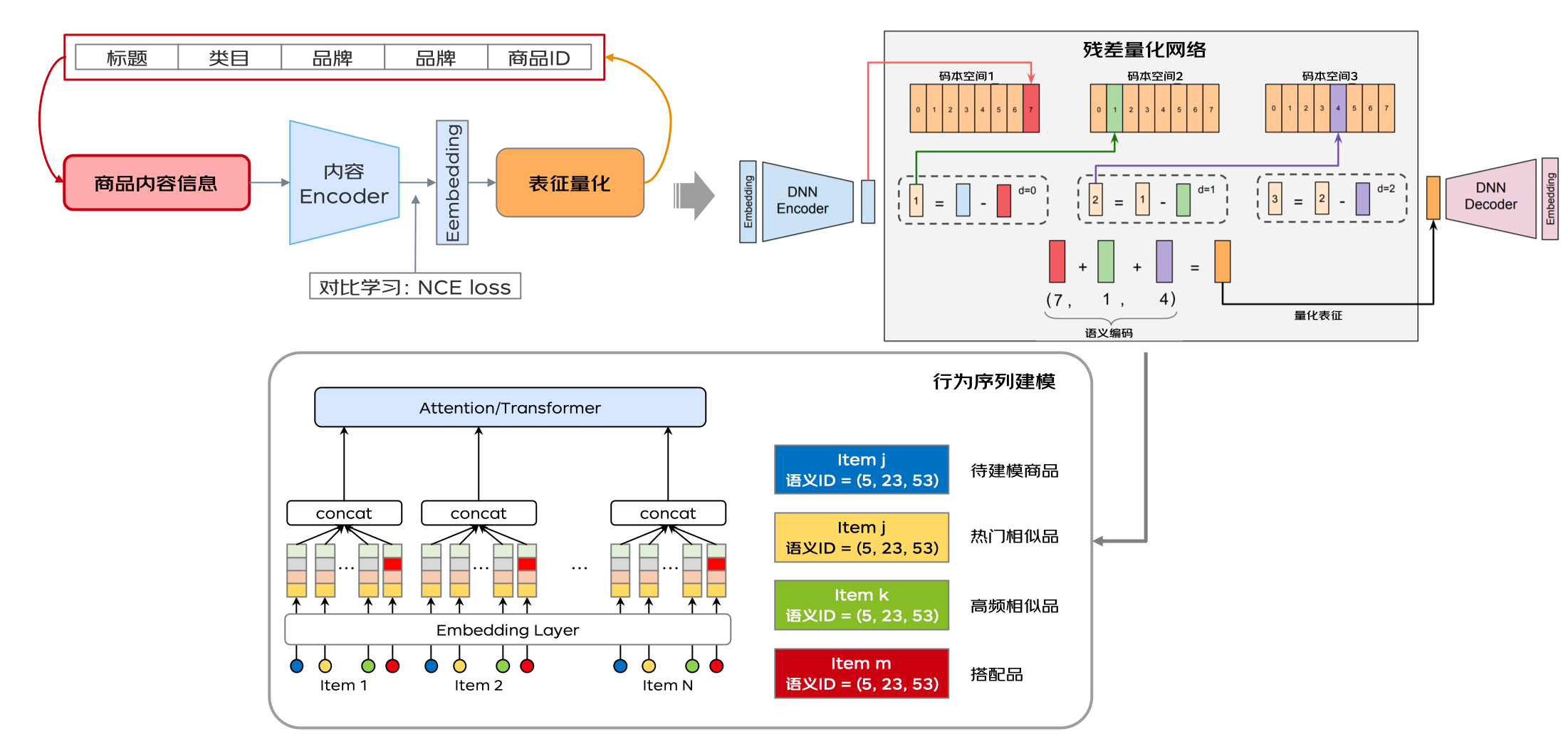
磐石之固:基于用户兴趣的商品预训练
对模糊用户兴趣的精细化建模,依赖对商品物料理解的建设。电商场景下自有的商品标签体系如类目、产品词等,存在不准确、冗余、粒度过粗、层次化不足的问题。对此,我们基于大规模的 NLP/CV 多模态预训练模型,产出更准确的物料类目标签和商品 embedding,为流量的高效探索利用奠定基础。基于残差量化变分编码的思想,对 embedding 表征进行残差量化,保留了 item 之间的层次化语义关联,将预训练语言模型的模式从“text ==> representation”改为“text ==> code ==> representation”的方式,缓解了预训练 embedding 过度依赖文本描述信息的问题,防止 item 之间的 gap 被过分夸大。
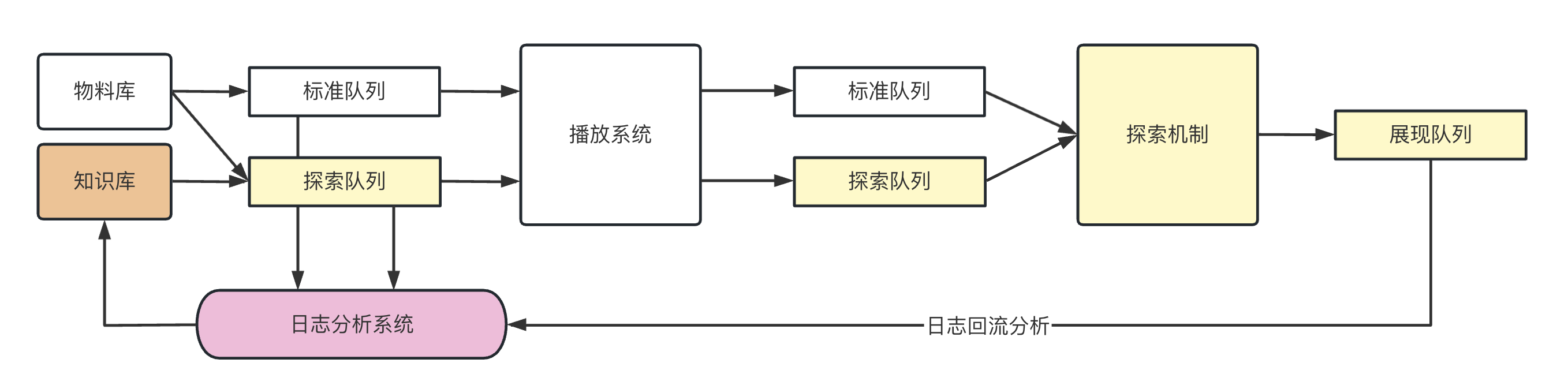
高山流水:系统化流量探索和利用
流量高效探索利用包括多样性控制、探索与利用的分配机制等,核心是如何在满足多样性约束情况下,平衡流量探索和利用效率,提升用户长期体验和业务效果。因此,在模糊用户兴趣场景下进行流量的高效探索利用,对于推荐广告的分配提效至关重要,可以辅助用户开拓兴趣边界,提升用户体验和长期留存,有利于业务长期增长。
为此,我们提出了层次化、全链路、个性化的流量探索利用方案。通过多维度的密度打散策略高效解决了极端多样性问题;在召回、候选集阶段、序列生成评估阶段等上下游全链路引入多样性和探索模块;在重排模块,基于序列生成-评估框架,实现了列表级探索利用方案,其中在序列生成阶段,基于端到端生成模型实现了相关性和多样性多目标协同优化;在序列评估阶段,将用户的长期体验和探索偏好建模为可量化的中短期反馈,实现对用户整体价值的端到端建模。
2.3、百花齐放:多品拍卖场景下的流量高效公平变现
在单品拍卖场景中,经典的 Myerson 引理告诉我们:一个机制是激励相容的,当且仅当其分配方式同出价是单调非减的,根据 Envelop Theorem,其收费公式由分配规则唯一确定(至多相差一个常数)。然而,在多品拍卖场景下,由于指数级别的组合搜索空间,激励相容的严格要求,导致收入最大化的多品拍卖机制设计十分困难。
因此,自 2019 年起,学术界兴起了一个新的方向:Mechanism Design with Deep Learning,尝试使用神经网络来近似激励相容的收入最大化多品拍卖机制,如 RegretNet[10]、RDM[11]等,通过将机制设计问题建模成为带激励相容约束的收入最大化问题,利用神经网络强大的学习能力,来逼近收入最大化的激励相容多品拍卖机制。然而,由于计算复杂度等原因,这些工作并不能很好的在业界大规模落地。此后,工业界也逐渐出现了利用海量数据驱动的深度拍卖机制,如阿里妈妈的 DeepGSP【12】,DNA【13】以及美团的 NMA【14】等工作。
京东自 2021 年起开展了深度拍卖机制在推荐广告场景的实践和应用,由最初的 TopK 贪心排序 + GSP 的拍卖机制,升级为基于 GSP 的分坑位模型化拍卖 DeepAuction,最终演化为基于强化学习的多品拍卖 ListVCG,实现了从行业跟随到行业领先机制的转变和突破,下面我们分别介绍相关工作和机制的演化过程。
DeepAuction:从 TopK 贪心排序到分坑位模型化拍卖
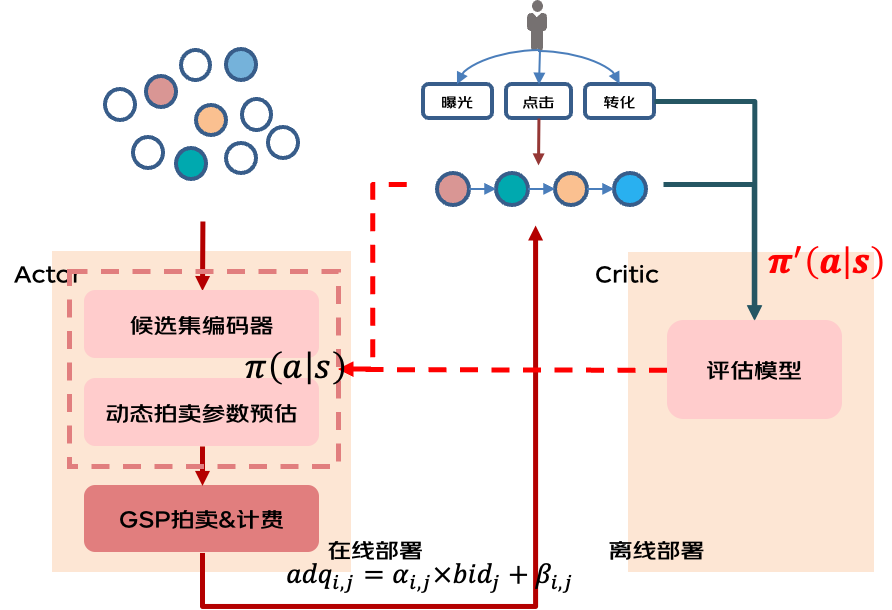
在模型化拍卖逐渐成为行业主流之前,TopK 贪心排序 + GSP 计费的方式是行业通用方案。然而,传统 GSP 不适用于多品组合拍卖,多品拍卖计费算法(VCG)由于其计算复杂度以及短期对平台收益的损失,落地困难。因此, 我们首先尝试通过基于 GSP 计费的分坑位模型化拍卖实现传统拍卖机制到模型化拍卖的切换。具体地,我们通过神经网络在每个坑位对不同广告物料计算质量分,根据该质量分进行排序以及二价扣费。
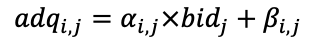
不同于传统基于 ecpm 的排序方式,模型化打分支持多业务目标的端到端学习。我们引入了基于强化学习 Actor-Critic 框架来建模流量长期价值,离线使用策略梯度回传方式对策略打分参数进行学习更新,在线我们通过 permutation invariant 的候选集编码器对候选物料进行建模,传入动态拍卖参数预估模型,进而实现分坑位的动态质量分计算。
ListVCG:基于课程强化学习的序列拍卖机制
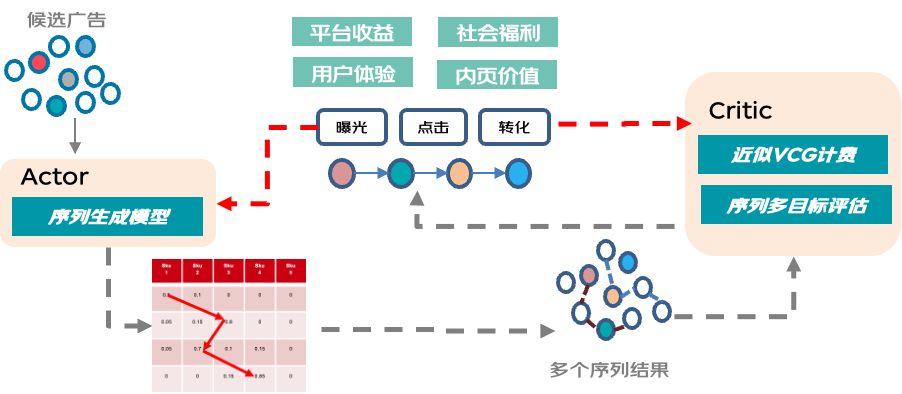
前面有提到,信息流广告是典型的多品拍卖场景,业界通用方案 GSP 在理论、效率上均不是最优解,VCG 多品拍卖机制是我们的理想方案。但是 VCG 仅仅是一个理论上的解决方案,他的前提是需要高效的找到最佳组合拍卖结果。与此同时,推荐业务复杂,是典型的多目标优化场景,但是标准 VCG 是追求社会福利最大化的机制,因此在由 GSP 切换到 VCG 时,平台收益在短期内会显著下降,这也是业界公认的 VCG 机制切换难题。因此如何将 VCG 与多目标优化进行结合也是我们面临的主要挑战。结合京东的实际应用场景,我们提出了 ListVCG 拍卖机制,来解决上述问题。
首先面临要解决的是 700 选 4 的排列组合问题,序列的搜索空间上千亿,我们将此定义成一个强化学习的问题,借鉴了经典的 Actor-Critic 架构,Actor 输出概率矩阵,通过采样的手段去求解排列组合问题,同时我们利用用户的真实反馈去提升 Critic 的评估水平,挑选出的最优组合会利用策略梯度的方式指引 Actor 学习。通过这种互相迭代自提升的方式去高效逼近最优组合。

VCG 下的多品拍卖同时是一个经济学问题,需要满足激励相容的拍卖理论约束来保证长期的生态健康发展,然而常见的多目标问题的优化思路会使得无法使用 vcg 计费。因此我们在 Listvcg 中对于 ECPM 价值进行了参数化的变形,在保证可计费的同时通过可学习的参数来满足平台收益、社会福利、用户体验以及物料整体价值多目标优化的诉求。
为了更好地对流量长期价值进行建模,我们自然地引入了强化学习的方式,起初我们尝试了传统 off-policy 的 Q-Learning 算法如 DDQN 等,然而,由于后验反馈的奖励稀疏,模型训练效果不稳定,因此,我们尝试引入 reward shaping 以及 curriculum RL 的思想,通过加入稠密先验奖励缓解数据侧的奖励稀疏,并让模型在相对简单的单步决策任务(如序列曝光、点击、单步价值预估等)收敛后,再学习长期决策任务,使得模型效果有了显著提升,在优化长期竞价环境的同时,实现了短期收入和广告主 roi 的上升。
3、结语和展望
推荐广告排序机制通过对流量价值的准确衡量,模糊用户兴趣场景下的流量高效探索利用以及多品拍卖场景下的流量高效公平变现,打造了符合京东推荐广告场域特点的排序机制,实现了流量的高效分发和变现,助力推荐广告业务增长。未来,排序机制团队会持续沿着这三个方向,并在自然结果混合排序、智能出价环境下持续进行排序机制的迭代优化。
最后,我们也欢迎对排序拍卖机制、推荐系统或在线广告感兴趣的小伙伴加入京东推荐广告组,共同成长,一齐助力京东广告业务的发展!联系邮箱:ganchun1@jd.com。




