有一天,一个读者给我发邮件,问我是否有兴趣做一个翻译应用,根据《美食译苑——中文菜单英文译法》把中文菜名译成英文菜名,因为他经常和老外吃饭,所以希望他的WP 手机上能有一个这样的应用,而我们则正好借此机会探索LINQ to SQL 的查询以及相关的优化技巧。
使用现有的数据库
Windows Phone 7.5 新增了对 SQL Server CE 数据库的支持,但 Visual Studio 2010 没有为 Windows Phone 的项目提供数据库的工具支持,比如表的设计和实体类的生成等,另外,数据库也须通过 LINQ to SQL 进行访问。
一般而言,应用会在首次运行的时候在独立存储里创建数据库,然后在运行过程中保存用户创建的数据,不过,这个应用不是创建一个新的数据库,而是使用现有的数据库,这个数据库会随应用一起部署到用户的手机上。 首先,在 Solution Explorer 里通过项目菜单把数据库添加到项目里,如图 1 所示。
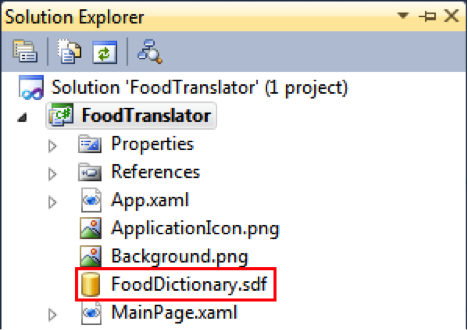
图 1
然后,在 Properties 里把数据库的 Build Action 的值设为 Content,如图 2 所示,这样数据库将会以独立文件的形式打包进 XAP 文件。相对的,如果我们把 Build Action 的值设为 Resource,那么数据库将会以资源的形式嵌入 DLL 文件,这样会导致应用的加载时间延长,应该尽可能避免。
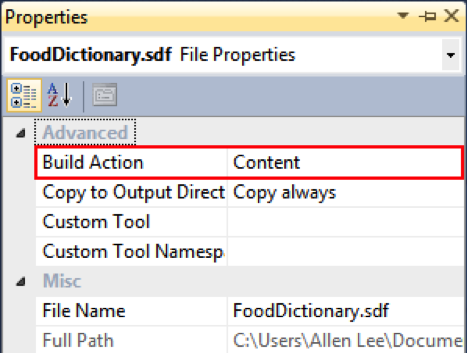
图 2
LINQ to SQL 是一个 ORM,这意味着我们在使用它访问数据库之前先要有和表对应的实体类,假设我们的表如图 3 所示,那么我们的实体类应该如代码 1 所示。
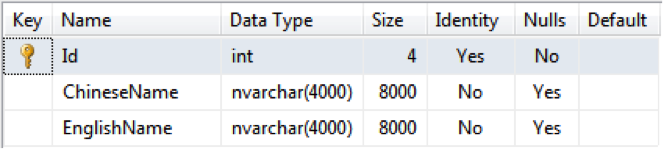
图 3
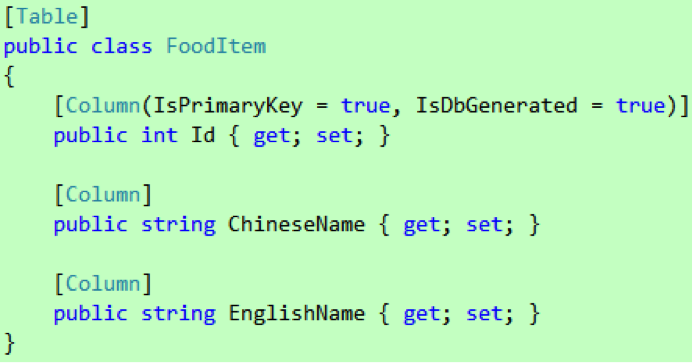
代码 1
我们通过 TableAttribute 告诉 LINQ to SQL,FoodItem 实体类和数据库里的 FoodItem 表对应。如果你的表名是不同的,你可以通过 TableAttribute 的 Name 属性指定。ColumnAttribute 则用来指定属性和表里的列对应,其中 IsPrimaryKey 用来指定主键,IsDbGenerated 则用来告知此属性的值将由数据库自动生成。如果你的列名是不同的,你也可以通过 ColumnAttribute 的 Name 属性指定。这些特性位于 System.Data.Linq.Mapping 命名空间。
有了数据库和实体类,现在就差 DataContext 了。你可以和我一样,创建一个强类型 DataContext——FoodDataContext,如代码 2 所示,也可以直接使用 DataContext 类。
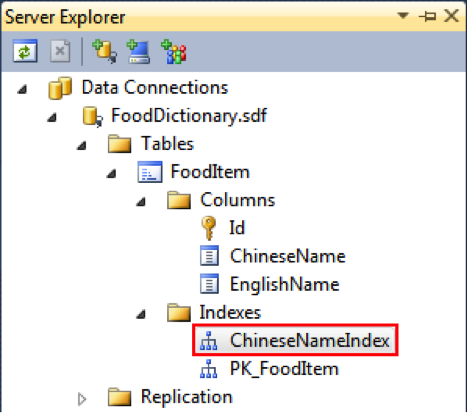
代码 2
在这里,强类型 DataContext 和弱类型 DataContext 的唯一区别是前者通过一个专门的属性访问 FoodItems 表。咋看一下这种做法似乎仅仅带来些许方便,是的,对于我们这里的情况确实如此,但对于前面提到的一般情况,即应用会在首次运行的时候在独立存储里创建数据库,LINQ to SQL 必须知道它要创建的数据库包含了什么表,而这个属性正是承担了这个责任。如果没有这个属性,那么创建数据库的时候就会抛出异常说 FoodDataContext 没有包含任何表,如图 4 所示。
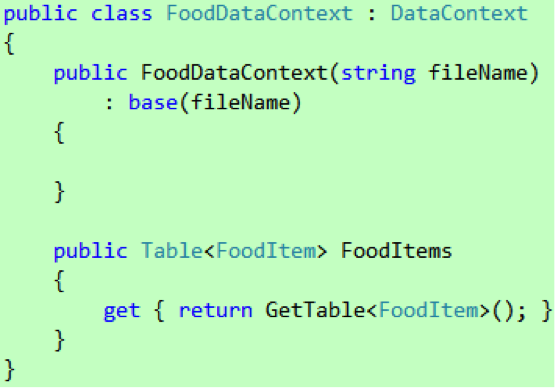
图 4
有了这些准备,我们就可以开始访问数据库了。首先,我们需要创建一个 FoodDataContext 对象,如代码 3 所示。这段代码有两个地方需要说明的,一个是 Data Source 里的“appdata:”,另一个是 File Mode。“appdata:”用来指定安装目录的路径,因为我们的数据库是随应用一起部署到用户的手机的,所以会放在安装目录下,如果你想指定的路径位于独立存储,那么你需要使用“isostore:”。位于安装目录的文件是只读的,因此需要把 File Mode 的值设为 Read Only,否则查询数据库的时候会抛出异常。
代码 3
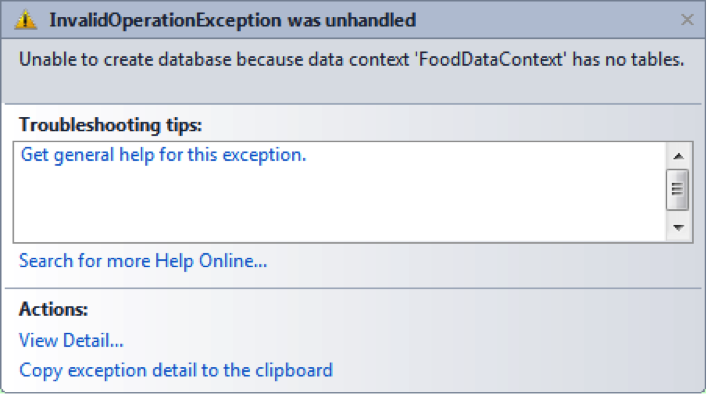
最后是查询数据库,我们需要使用 LINQ 查询表达式,如代码 4 所示。这段代码查询包含指定关键字的中文菜名,然后根据中文菜名进行排序,非常简单直接。

代码 4
接下来,我们将会在此基础上探讨三个常见的 LINQ to SQL 优化技巧:
- 为经常参与查询的字段建立索引以便提高查询效率。
- 通过编译查询免除每次编译 LINQ 查询表达式的开销。
- 通过禁用对象跟踪减少 LINQ to SQL 对内存的额外占用。
建立索引
通过建立索引提高查询效率是常见的数据库优化技巧。假设我们想为 ChineseName 字段建立索引,我们需要做的事情有两件:
- 在数据库里建立这个字段的索引。
- 更新实体类的定义。
你可以在 Server Explorer 里建立这个索引,如图 5 所示,然后在 FoodItem 类上添加 IndexAttribute ,如代码 5 所示。为了使用在实体类上 IndexAttribute,我们需要引用的 Microsoft.Phone.Data.Linq.Mapping 命名空间。
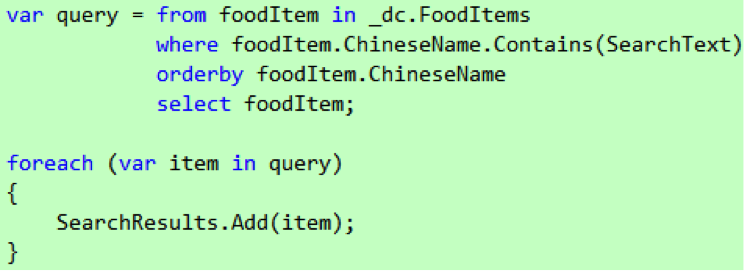
图 5

代码 5
IndexAttribute 是 Windows Phone 7.5 的独家特性,无法在其他平台的 LINQ to SQL 上使用,因此不能在代码层面上和其他平台直接共享使用 IndexAttribute 的实体类。如果你确实有这种共享的需要,可以通过预处理器指令有选择性地把它引进来,如代码6 所示。

代码 6
因为我们的数据库会随应用一起部署到用户的手机上,而且是只读的,所以通过前面这种方式建立索引,然后在新的版本里提供是可行的。但如果你的数据库是应用在首次运行的时候在独立存储里创建的,而里面的数据则是用户在运行的过程中创建的,那么你就要考虑使用DatabaseSchemaUpdater 了,如代码7 所示。这段代码应该在新的版本启动的时候执行,而且你需要在执行之前检查数据库的版本,看看是否已经更新过了。
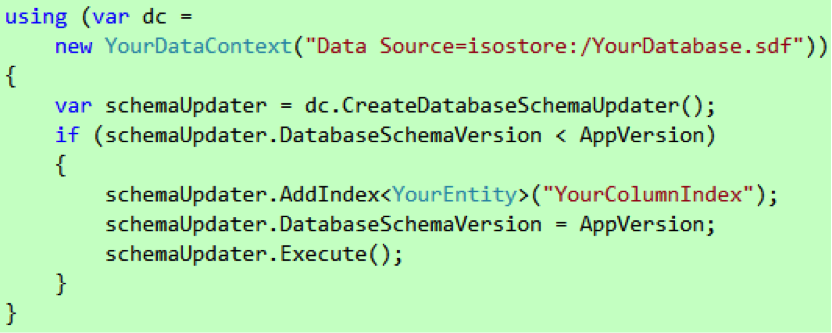
代码 7
最后,我不得不承认这个应用并非演示索引的好范例,因为我们的查询表达式使用Contains 方法进行筛选,它会被翻译成“LIKE %S%”,这会导致全表扫描,换句话说,我们建立的索引没有发挥到作用,却增加了数据库的大小,成为不必要的负担。
使用编译查询
编译查询不是数据库的优化技巧,而是LINQ to SQL 的优化技巧,它的存在意义和LINQ to SQL 的工作原理有关。我们知道,LINQ to SQL 的查询表达式并不是在CLR 上执行的,而是编译成T-SQL 语句在SQL Server CE 上执行的,这个过程会在每次执行查询表达式的时候发生。为了避免重复编译,我们可以使用编译查询预先生成T-SQL 语句,然后在需要的时候直接使用。
编译的工作有CompiledQuery 的Compile 方法完成,我们需要为它提供一个Expression 类型的参数,编译完成之后它会返回一个Func 类型的对象,如代码8 所示。回顾我们的查询表达式(参见代码4),有两个东西需要提取成参数,一个是_dc,即FoodDataContext,另一个是SearchText,即用于查询的关键字,因此Func 类型的完整写法是Func
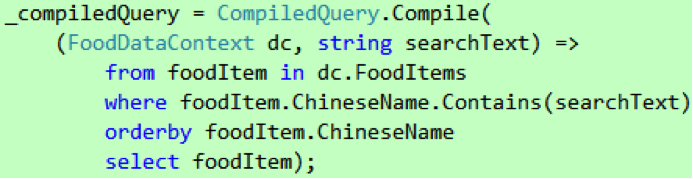
代码 8
需要说明的是,FoodDataContext 必须通过Expression 类型的第一个参数传给Compile 方法,而不是通过闭包捕获,否则代码无法编译。
接下来,我们需要把代码4 的查询表达式部分替换成编译查询,如代码9 所示。
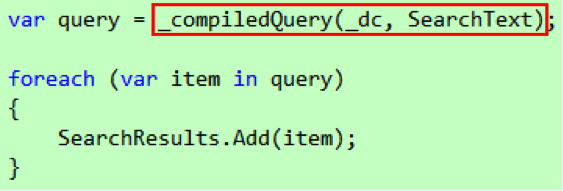
代码 9
如果你的编译查询比较多,你也可以考虑把它们放在一个静态类里管理起来,并通过静态属性提供对这些编译查询的访问,如代码10 所示。

代码 10
禁用对象跟踪
当你看到这个标题时,你很可能会问,对象跟踪是什么,为什么要禁用?回答这两个问题正是本节的任务。 通过LINQ to SQL 更新数据是非常简单的,你只需修改目标对象的属性,然后调用DataContext 的SubmitChanges 方法就行了,问题是,LINQ to SQL 如何得知你修改了哪些对象的属性呢?答案就是对象跟踪。不过,使用对象跟踪需要耗费额外的内存,这对于执行只读数据库操作的应用来说显然是不必要的,因此会通过禁用对象跟踪减少内存的开销。
对象跟踪默认是启用的,若想禁用它,只需把DataContext 的ObjectTrackingEnabled 属性的值设为false 就行了。现在,请思考一个问题,是不是只要不涉及到更改操作就禁用对象跟踪?下面,我们将会通过一个实验探索这个问题。
首先,我们启用对象跟踪,并通过设置FoodDataContext 的Log 属性把执行的SQL 查询输出到Debug 窗口,如代码11 所示。DebugWriter 是我自己定义的一个TextWriter,内部调用Debug 的WriteLine 方法把东西输出到Visual Studio 的Output 窗口。
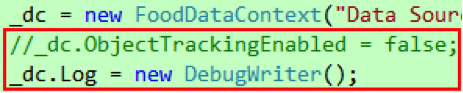
代码 11
接着,执行同一条LINQ to SQL 语句两次,如代码12 所示,此时,你会看到Output 窗口只输出一次SQL 查询,如图6 所示,这意味着两条相同的LINQ to SQL 语句在数据库里只执行过一次。

代码 12
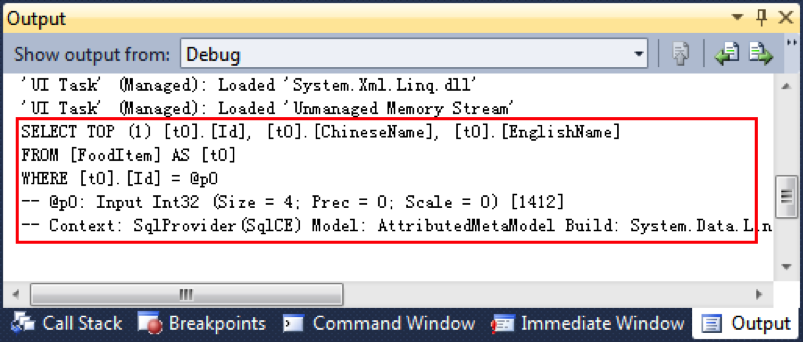
图 6
现在,禁用对象跟踪,即把代码11 的第二行注释去掉,然后再次执行代码12,此时,你会看到Output 窗口输出两次相同的SQL 查询,如图7 所示,这意味着每次执行LINQ to SQL 语句都会在数据库产生一次SQL 查询,即使数据库没有任何更改。
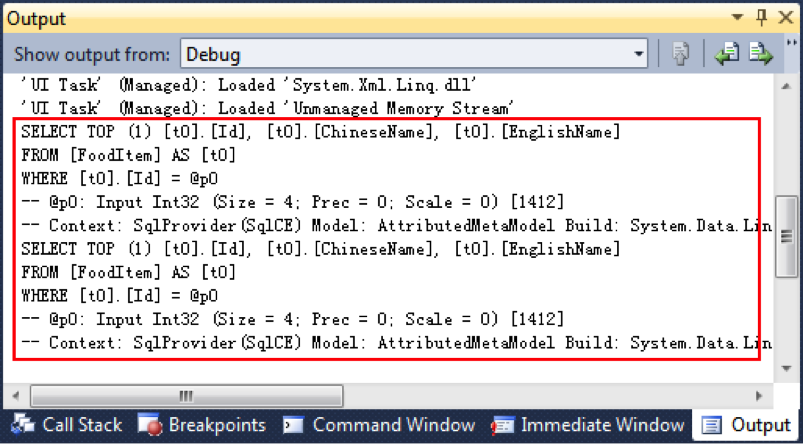
图 7
为什么会这样呢?当我们启用对象跟踪时,DataContext 会把我们基于主键查询到的单个对象缓存起来,下次查询会先到缓存里找,没有才去数据库里找;当我们禁用对象跟踪时,DataContext 不会进行任何对象缓存,每次都会从数据库里查询并返回一个新的对象。
如果你需要频繁地进行基于主键的查询,那么你可能希望好好地利用DataContext 的缓存机制避免不必要的查询,从而提高应用的性能。至于这个应用,因为它没有任何基于主键的查询,所以通过禁用对象跟踪减少内存的开销是正确的做法。
最终的优化方案
根据前面的讨论,我们为这个应用选择的优化方案是使用编译查询和禁用对象跟踪。注意,这只是目前的优化方案,因为随着应用的进化可能会出现基于主键查询的功能,或者新的数据库增加了一些可以通过建立索引提高查询效率的字段,所以我们不应该机械地套用优化技巧,而是根据实际的情况选择合适的组合。
感谢崔康对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




