
一、何为特征血缘关系?
特征血缘关系是好分期在构建风控系统过程中,产生的一种描述在数据源,特征和策略文件之间的数据转换、依赖的概念。它用于记录和追踪特征的来源,衍生以及影响的路径,能够帮助理解特征的产生和使用历史,以及对模型或是决策结果的贡献。
二、背景
在开始整体介绍之前,我们需要先了解一下几个特定的概念:
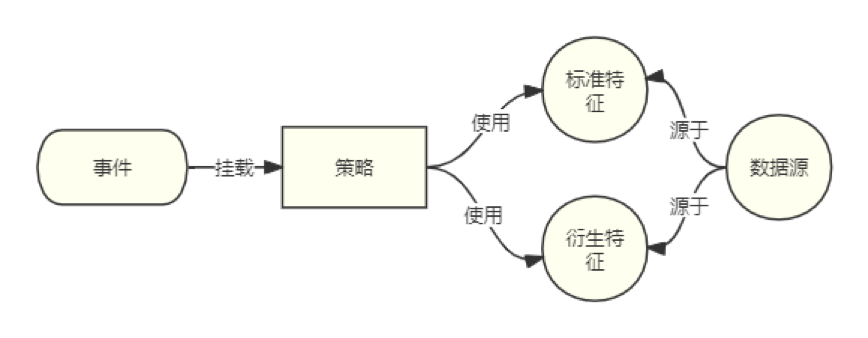
数据源:包括自有数据、三方数据、加工数据等,可以来自不同的数据库(如 MySQL、MongoDB、HBase)或者离线数据(Hive)。这些数据经过一定的加工逻辑生成了一个数据集合。
标准特征:仅有一个依赖的数据源做加工计算的特征。
衍生特征:可以依赖多个数据源,多个标准特征甚至是衍生特征聚合加工所计算的特征。
事件:包括用户授信、放款、额度等事件,这些事件通过流程引擎进行流转,并分为多个步骤。每个步骤包含数据节点、特征节点和策略节点。我们在流程中设计了自上而下的缓存机制,确保后续步骤能够获取到之前步骤的数据源或特征缓存。同时,特征的计算需要保证其所依赖的数据源或特征在当前步骤上线或能够获取到之前步骤的缓存,否则可能导致特征计算失败或结果为空,从而影响到策略节点的判断。
策略:风控事件以策略决定事件结果。策略文件以代码或是数据的格式存在,存在着包括决策流,决策脚本,规则集,决策表等多种格式的文件集合,这些文件中既可以包含 Python 代码,也可以是以 JSON 格式表示的规则集合。
各个概念的关系如下图所示:
随着好分期业务的飞速发展,我们面临的数据增长量也在加速。用户基础数据、三方数据和加工数据等,都在快速积累和扩张。同时,由于各类模型和策略所使用的特征数据关系复杂多变,其维护工作变得尤为困难。在这样一个大数据环境下,如何追踪大量特征和数据源的流向,从而明确每个数据系统中上游数据来源和下游数据去向,对于完成数据治理这一环节至关重要。
特征血缘关系的建立,旨在解决这一问题。通过构建一个清晰、有效的血缘关系,我们能更好地追踪和管理数据流动,以便进行有效的数据治理。
在实际运营过程中,我们会遇到一些挑战和问题:
1.数据间的血缘关系不明确导致重复存储和处理,定义标准混乱导致数据质量好坏参差不齐,同时特征价值评估也因此变得异常困难。这一系列问题相互影响,使得整个数据管理工作陷入困境。
2.另外,三方数据源的异常也可能对我们的业务产生影响。三方问题导致依赖于这些数据源的特征出现分布偏移,我们将很难定位影响范围,从而无法及时采取有效的纠正措施。
3.在特征衍生多层的过程中,其溯源问题也让人头痛。特别是在数据流转过程中出现问题时,由于无法确定具体错误发生在哪个环节,我们往往难以找到问题的产生源头并进行修复。
4.此外,特征之间的计算依赖性也会带来麻烦。例如在一个复杂的衍生特征计算场景中,当某一个层级的依赖特征未能及时上线,就可能导致当前特征以及下层特征计算失败,从而造成业务流程的中断。
基于以上的痛点问题,我们迫切需要一个能够清楚呈现血缘关系的方法,通过可视化的图表展示,为数据的流转提供一个清晰的链路。此外,我们也需要建立策略文件与特征之间引用关系,以进一步优化和丰富血缘关系。这不仅可以帮助我们更好地管理和控制数据,还能为风险人员提供一个更加安全、可靠的数据使用环境。
三、与现有血缘关系的对比
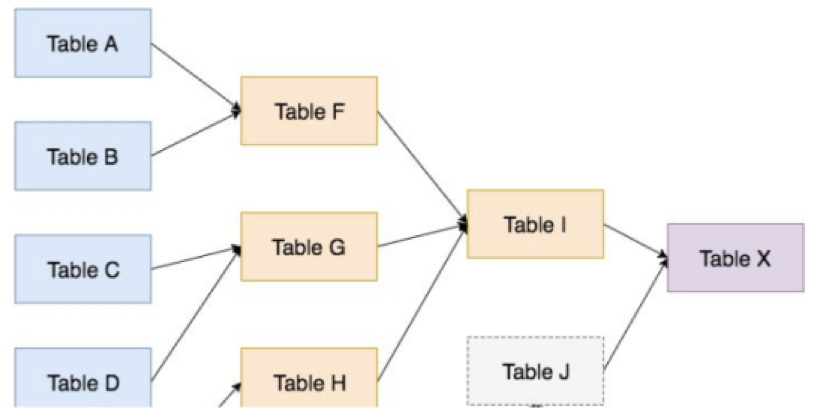
目前市面上常见的血缘关系是以数据库、表、字段等为出发点,主要建立表与表之间的血缘关系,如上图所示。这种血缘关系的维护多依靠人工检索和手动更新的方式,展示了数据如何在表之间进行流转。好分期血缘关系以特征为出发点,旨在建立从数据源到依赖该数据源计算的特征,再到更深层次的衍生特征,最终到引用这些特征的策略,这个完整链路的血缘关系。
另一方面,业务中的数据源、特征、策略间上下线也存在着依赖关系,如果仅支持展示数据流转的功能远不能满足我们业务对于血缘关系的要求。对于特定事件的某个步骤的特征血缘关系,需要一个更细粒度的展示,把依赖关系精细到事件乃至步骤上面。通过构建这种血缘关系,来解决目前业务中遇到的痛点问题。
四、特征血缘关系方案设计
先前的章节介绍了特征血缘关系的定义,产生的背景以及与现有血缘关系的差异。那它又是如何实现的呢?本章节将会通过整体架构设计,依赖树构建、基于节点属性的减枝算法、策略层的设计四个方面来进行具体介绍特征血缘关系的实现方案。
1、架构设计

整体采用前后端分离,前端引入了 Vue 做界面展示和 AntV G6 对依赖树进行可视化。
MySQL 数据库:创建一张记录依赖关系的表。数据源和特征、特征和特征的依赖,需要在创建特征时进行记录,每个依赖都会生成一条记录,表示当前的特征依赖的一个数据源或是特征关系。
数据源层:数据源层主要负责建立数据源到特征的依赖树。能够展示所有直接或是间接依赖该数据源的特征情况。
特征层:特征层负责标准特征和衍生特征之间的依赖树构建。提供特征溯源的功能。同时,考虑到实际情况中存在事件某个步骤上的特征依赖关系,我们对特征节点的依赖进行了进一步的细化,附带了包括事件、步骤等多个属性的概念,相应的需要对特征依赖树做父级特征的属性匹配和子级特征的减枝操作。
策略层:策略层主要负责构建策略与引用特征之间的依赖关系。不同于数据源层和特征层,策略层的关系来源于对策略文件的解析,首先对策略文件进行按类型的拆分,通过特定的正则表达式抽取出每个策略所使用的特征,然后引入倒排索引的思想构建特征到策略的映射以提高查询效率。
缓存和数据变更监听:对依赖关系以及策略文件的预处理结果需要保存在缓存当中,我们采用了 Redis Hash 的格式进行保存处理,在一定程度上提升了查询的效率。在这种情况下,也需要保证缓存与数据库数据的一致性,防止由于缓存不一致导致的误判问题,我们采用了 Binlog 监听的方式保证缓存能够维持在最新状态。
2、依赖树构建
通过 MySQL 表方式记录依赖关系,在程序启动时加载数据到内存当中进行预处理形成点和边的数据结构。具体定义如下:
边格式为:’EDGE’# from_node # to_node
点格式为: ’NODE’# node_id # node_name [#property_name:property_value]
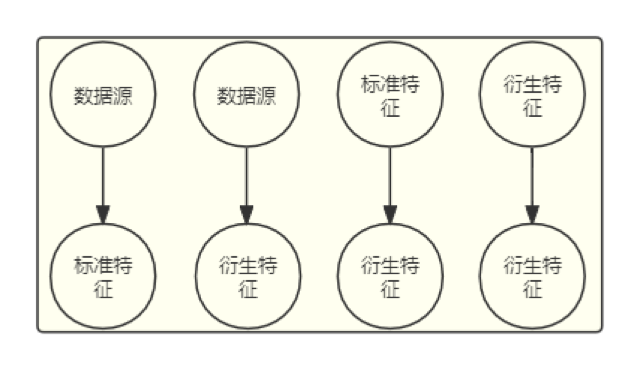
由之前的描述我们可以得出,目前业务中存在着三种不同类型的节点和四种不同的边。定义如下:
点集合: [ service_node, sd_node, dr_node ] ,其中 service_node 表示数据源节点,sd_node 表示标准特征节点,dr_node 表示衍生特征节点。
边集合:[ service_node->sd_node, service_node->dr_node, sd_node->dr_node, dr_node->dr_node]
在预处理生成边结构之后,我们通过检索边的同源节点,然后以栈递归算法对边进行组装,即可生成如下图的树状图结构。
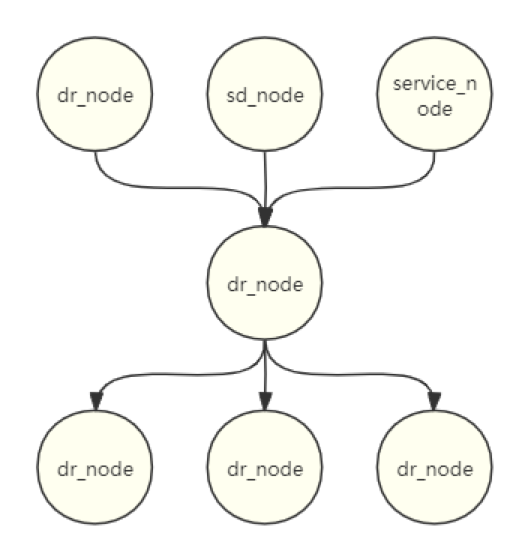
主要的递归算法逻辑:
1).选定一个 node A 作为递归的根节点。
2).新建两个栈结构命名为 parentStack 负责 node A 父级节点递归、childrenStack 负责 node A 子级节点递归。
3).查询 node A 父级节点并 push parentStack,子级节点 push childrenStack,进入并行递归。
4).栈是否为空?
5).取栈顶元素,重复查询其父级或者子级特征 push stack,同时构建边、节点结构。
6).重复 4)、5)流程直至栈为空。
为了提升算法的执行效率,我们采用了两个栈的方法:parentStack 和 childrenStack。在递归过程中,我们对数据源节点进行了特殊处理,因为数据源节点已经是最顶层节点,所以无需进行重复的递归操作。除数据源节点之外,parentStack 和 childrenStack 的算法流程基本相同。
然而,在这个过程中,我们需要注意一种特殊情况。如果在依赖树结构中存在重复的节点,可能会导致我们的算法进入重复递归的状态,甚至在极端情况下会导致栈溢出的问题。为了避免这种情况发生,我们采取了记忆化递归的策略来避免这个问题以及降低冗余计算。
3、基于节点属性的减枝算法和属性匹配
考虑到特征在具体事件及其各个步骤上的依赖关系,我们更进一步地细化了特征依赖的粒度。在当前的业务逻辑中,存在一个复杂的依赖关系如下图所示:一个事件 a 包含了 A、B、C 三个步骤。此时,节点 C 需要上线一个衍生特征 dr1。
为了成功计算该衍生特征 dr1,它的父级特征 dr2 必须能够在同一事件 a 被获取到。此时,dr2 的步骤属性可以是 B 或者 C,即在事件 a 的 B 或 C 步骤中我们都能得到 dr2 的值。
类似地,对于衍生特征 dr2,其父级特征 sd 也需要能在同样的事件 a 被获取到。此时,sd 的步骤属性可以是 A 或者 B,意味着在事件 a 的 A 或 B 步骤中我们都能获取到特征 sd 的值。
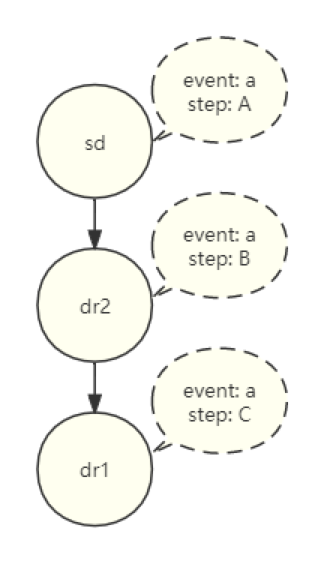
总结而言,特征在指定事件上的依赖关系,其属性当中,事件需要相等,而步骤存在置顶向下不断增大的规则。换句话说,一个衍生特征的父级特征可在该衍生特征所在步骤或其之前的步骤中获取到,但不能在其后的步骤中获取。
因此,对于 4.2 节中介绍的依赖树,我们在附带上属性的概念后,按照以上的规则算法进行进一步的处理。
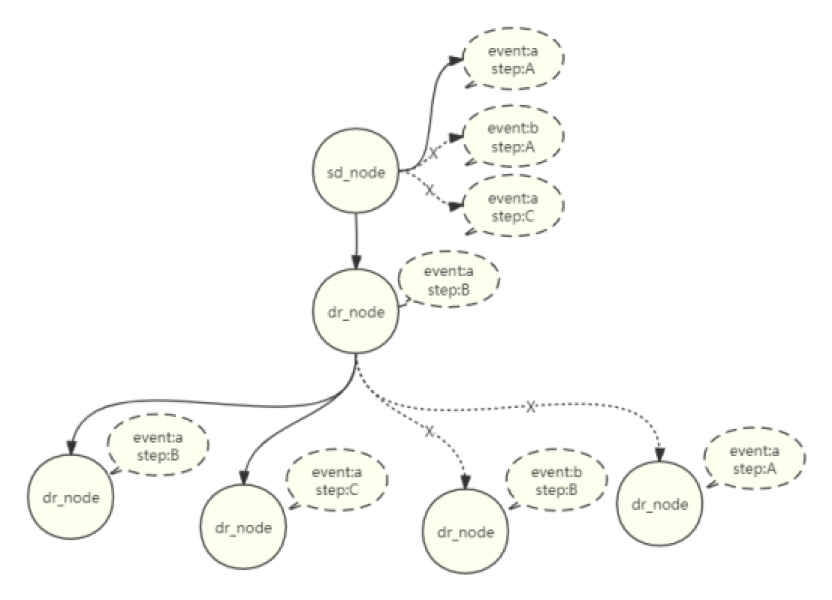
在指定一个特定事件步骤下的衍生特征时,我们需要对其父级依赖的特征在多个属性中筛选出符合之前所述规则的属性。同时,对于它的子级特征,我们要剔除那些不满足上述规则的依赖关系。
通过这个算法,我们能够构造出一个指定事件步骤下的特征依赖树。这种依赖树可以清晰地展示出每个特征在各个步骤中的依赖关系,从而为我们提供了一种直观的理解方式。更重要的是,它能有效地防止因缺失依赖特征而导致当前特征计算失败的情况发生,也让特征间的复杂依赖关系更加易于理解和操作。避免了由于遗漏或错误的依赖关系而引发的误差,确保了特征计算的成功进行。有利于我们更好地处理和使用各个特征,进一步提升整体的数据处理和结果质量。
4、策略与特征间的依赖关系构建
为了方便查询策略中使用的特征,我们在业务中规定了标准特征命名以"_sd"结尾,而衍生特征则以"_dr"结尾。利用这个命名规则以及在策略中使用特征时必须使用单引号或双引号包围的特点,我们可以制定一个正则表达式来匹配出各个策略中使用的特征。
目前,好分期面临 100 多个风控事件,并且对应的策略文件数量也超过 100 个的情况。其中一些复杂的策略文件大小可能达到 3-4MB。如果按照传统的检索方式,在如此庞大的文件集合中查找引用的特征,必然会遇到效率缓慢的问题。
为了解决这个问题,我们引入了倒排索引的思想。在程序启动时,对策略文件进行预处理,提取出所使用的特征,并建立如下图的依赖关系。通过这种倒排索引结构,我们有效地解决了查询时间长和占用内存过大的问题。

五、上线后的效果
目前,特征血缘关系已经成功上线到风控平台,并且在风险和模型同学中逐步推广开来。对于数据源和特征影响范围的定位,以及特征溯源和策略是否使用等相关场景,我们不再需要通过查询文档或咨询业务人员,而是可以通过一键查询功能来实现。这样做不仅极大地缩短了问题定位的时间成本,减少了超过 90%以上的耗时,还避免了评估不当导致的特征遗漏现象。血缘关系作为底层的支持工具,已经成功支持了好分期多个项目的正常运转。
下面将介绍几个业务中真实的应用场景。
案例一:查询依赖指定数据源的特征

我们使用不同的节点颜色来区分节点类型,例如黄色节点表示数据源,蓝色节点表示特征。整棵树按照从左到右的方式展开,依次展示依赖于查询数据源的一级特征、二级特征、三级特征等。
通过这种直观的树状图,我们可以清晰地看出数据源的引用路径。如果由于三方问题导致的数据源分布抖动,我们也可以迅速评估影响范围。同时,这样的可视化展示也方便我们快速了解数据源与特征之间的依赖关系,帮助我们更好地管理和维护数据源,并及时应对可能出现的风险。
案例二:查询指定特征在具体事件步骤的上下游依赖

查询特征节点支持展示具体到事件步骤级别的依赖情况。我们将事件和步骤作为节点的属性进行展示,在图中以冒号隔开的字段形式呈现。
通过这种方式,我们可以更详细地了解每个查询特征在具体事件和步骤下的依赖,可以帮助我们更加全面地理解特征之间的关系,并能够更准确地分析和处理相关特征间的相关问题。同时,也有助于快速评估特征对具体事件、步骤决策的影响,以便及时做出相应的调整和优化。
案例三:查询指定特征在策略中的使用情况

我们使用表格形式展示策略和特征之间的依赖关系,以支持查看策略文件中哪个类型的哪一行代码引用了特定的特征。
通过这种展示方式,我们可以清晰地了解特征在策略文件中的引用情况。更方便地追踪特征与策略间的依赖关系,同时也有助于快速定位特征在策略中的调用位置,以便于进行相应的问题排查工作,提高工作效率并减少出错的可能。
六、总结
总的来说,好分期专注于构建一个全面且独特的特征血缘关系系统,并在实现方法上与当前存在的血缘关系技术有显著的区别。至今,我们已经形成了一套比较完善和高效的解决方案,对业务中的各种问题提供了有效的处理方式。
未来,我们计划深度挖掘特征血缘关系在不同领域的潜力:例如在评估特征价值、保证数据质量、识别数据孤岛等方面,使其能够为更多领域提供深入的应用。我们会继续发展并扩展这个系统的功能,以适应业务需求的持续发展。
我们坚信,通过不断拓展特征血缘关系的应用范围和深度,能够更好地理解数据的流动和变化,从而提高模型的准确性和风控效果,同时也能为用户提供更优质的服务。我们将持续投入,为未来的风控管理提供更强大的技术支持。
作者介绍:
倪继昌,微财数科 变量中心高级工程师
王黎明,微财数科 变量中心资深工程师
孙丽川,微财数科 风控平台资深工程师
钱奔,微财数科 产品经理
李军,微财数科 技术负责人
吴迪,微财数科 副总裁




