
API 对于组织来讲正变得越来越重要,但是,构建安全、可扩展的 API 并非易事。本文从执行环境、API 技术、安全性等角度出发,介绍了如何构建高效、可扩展的 API。
本文最初发表于 Salesforce 站点,经作者 Nitesh Kumar 授权,由 InfoQ 中文站翻译分享。
API 是一个重要的工具,允许合作伙伴、开发人员和其他应用消费我们提供的微服务,与之进行通信,并基于此构建各种各样的功能。
高质量的 API 要能够随着业务生态系统的发展而扩展,构建这样的 API 并不是一件容易的事情,需要对所有的事情进行通盘思考和规划,涉及到选择哪种执行环境,甚至要决定该使用哪种 API 技术。
那么,我们是如何实现的呢?在本文中,我将会分析在 Salesforce 为 Activity Platform 构建 API 的经验,它可以作为你自己编写 API 的一个指南。Activity Platform 是一个大数据处理引擎,每天会摄取和分析超过 1 亿次的客户互动,以自动捕获数据并产生分析、推荐和 feed。Activity Platform 提供了 API 来为我们的客户交付这些功能。
选择执行环境
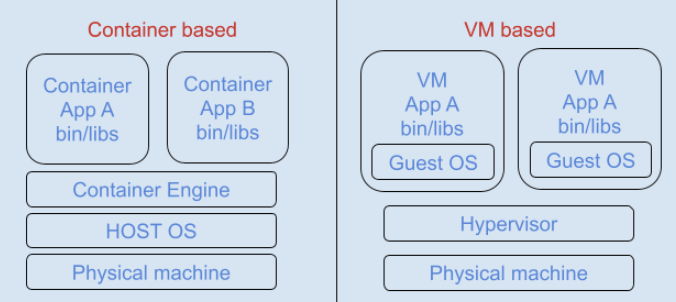
根据需求不同,执行环境可以是裸机、虚拟机(VM)或者应用容器。我们选择了使用应用容器,因为它可以在物理机或 VM 上运行,一个操作系统实例能够支持多个容器,每个容器都在自己独立的执行环境中运行。简而言之,容器是轻量级、可移植、快捷的,并且易于部署和扩展,所以它们天然适合微服务。
关于容器编排
如果你像我们这样决定使用容器,容器编排能够帮助你实现自动化部署,管理容器、扩展以及网络。在这方面,有很多可选的容器编排工具,比如 Kubernetes、Apache Mesos、DC/OS(with Marathon)、Amazon EKS、Google Kubernetes Engine(GKE)等。
我们使用的是 Hashicorp 的 Nomad 集群。它非常简单、轻量级,并且能够编排任何类型的应用,而不仅仅是容器。它能够无缝与 Consul 和 Vault 集成,实现服务发现和 secret 管理。我们可以很容易地将需求描述为一个待执行的任务(task),比如内存、网络、CPU,以及我们水平扩展服务所需的实例数量。
选择 API 技术
为了构建 API,我们选择了使用 GraphQL。如果你没有听说过它的话,它是其他可选技术(如 REST、SOAP、Apache Thrift、OpenAPI/Swagger 或 gRPC)的一个替代方案。
我们为什么选择 GraphQL
我们想要构建的 API 能够服务于多种客户端,涵盖 Web 和移动应用。它需要具备高效、强大和灵活的特点。
鉴于以下的原因,GraphQL 是最合适的方案:
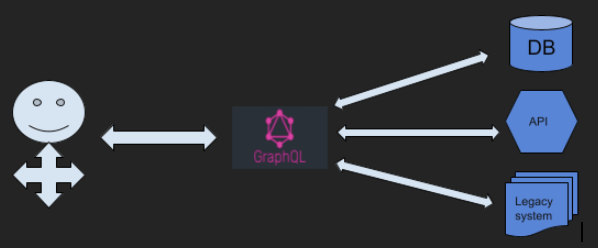
GraphQL 是数据库无关的技术,能够从任何地方为我们预先定义的业务领域提供数据。这意味着为了满足一个查询,底层可以使用 Cassandra、Elasticsearch 或其他模块的现有 API。
它允许客户端精确请求想要的数据,避免过量加载(overfetching)或加载不足(underfetching)。如果 API 返回的数据超出了客户端的需求,这会导致性能问题,如果返回的数据比预期要少,那么会进行多次网络调用,从而减缓渲染时间。GraphQL 能够避免这两种情况。
尽管大多数的 API 都实现了版本管理,但是 GraphQL 是一个无版本化的 API。因为它只会返回明确请求的数据,所以我们可以通过添加新的类型以及类型上的新字段来增加功能,避免带来破坏性的变更。
GraphQL 使用强类型系统,所有的类型都是使用 Graph SDL 以模式(schema)的方式进行定义的。它可以作为客户端和服务器的契约,避免请求 / 响应结构的混淆。
GraphLQ 支持内省(introspection),所以模式定义可以通过各种工具进行共享和下载,如 GraphiQL、GraphQL-playground 或 cli 工具。
GraphQL 实战
我们在 Classification Insight API 中使用了 GraphQL。Classification Insight 提供了用户的信息,并且能够帮助会议的参加者了解其他参会人员的头衔和角色。我们使用 Kotlin 和 graphql-java(GraphQL 的一个 Java 实现)实现该 API。
第一步:定义模式(如 schema.graphqls)。每个 GraphQL 服务会定义一组类型。GraphQL 模式中最基本的组件是对象类型,它代表了一种我们可以从服务中获取的对象。
在如下的模式中,我定义了一个名为“getClassificationInsightsByUser”的查询,在后面的内容中,我们可以通过发送如下的载荷到 API 来调用查询:{ getClassificationInsightsByUser(emailAddresses: [“test1@gmail.com”, “test2@gmail.com”]) { userId, title } }
schema.graphqls
# 描述我们能够获取什么内容的对象类型type ClassificationInsightByUser { organizationId: ID! userId: String! emailAddress: String! title: String!}# 定义所有查询的Query类型type Query { getClassificationInsightsByUser( emailAddresses: [String!]! ): [ClassificationInsightByUser]}schema { query: Query}第二步:实现 Datafetcher(也被称为解析器)来解析 getClassificationInsightsByUser 字段。简单来讲,解析器就是由开发人员提供的一个函数,用来解析模式中定义的每个字段并从配置的资源(如数据库、其他 API 或缓存等)中返回值。
在本例中,我们的 Query 类型提供了一个名为 getClassificationInsightsByUser 的字段,它接受 emailAddresses 参数。该字段的解析器函数很可能会访问一个数据库,并构造和返回 ClassificationInsightByUser 对象的一个列表。
// 假设我们已经定义了数据类// (如ClassificationInsightByUser)来存放数据// 编写自己的datafetcher类class ClassificationInsightByUserDataFetcher: DataFetcher<List<ClassificationInsightByUser>?> // 重载DataFetcher的get函数 override fun get(env: DataFetchingEnvironment): List<ClassificationInsightByUser>? { // 在提交的查询中获取参数 val emailAddresses = env.getArgument<List<String>> (EMAIL_ADDRESSES) // 编写逻辑从其他API或者通过调用控制器/服务从业务层获取数据 // 在这里,为了简单,返回静态数据 return EntityData.getClassificationInsightByUser(emailAddresses) }}第三步:初始化 GraphQLSchema 和 GraphQL Object(借助 graphql-java)来辅助执行查询。
// 借助工具函数,将所有模式文件加载为字符串String schema = getResourceFileAsString("schema.graphqls")// 根据模式文件创建typeRegistryval schemaParser = SchemaParser()val typeDefinitionRegistry = TypeDefinitionRegistry()typeDefinitionRegistry.merge(schemaParser.parse(schema))// 运行时装配,我们将自己的查询类型装配到解析器中val runtimeWiring = RuntimeWiring() .type("Query", builder -> builder.dataFetcher( "getClassificationInsightsByUser", ClassificationInsightByUserDataFetcher() ) ) .build();// 创建graphQL Schemaval schemaGenerator = SchemaGenerator();val graphQLSchema = schemaGenerator .makeExecutableSchema(typeDefinitionRegistry,runtimeWiring);// 创建graphQLval graphQL = GraphQL.newGraphQL(graphQLSchema).build();第四步:编写 servlet(MyAppServlet),处理传入的请求
override fun doPost(req: HttpServletRequest, resp: HttpServletResponse) { val jsonRequest = JSONObject(payloadString) val executionInput = ExecutionInput.newExecutionInput() .query(jsonRequest.getString("query")) .build() // 使用graphQL执行查询 // 它将会调用解析器来获取数据并且只返回请求的数据 val executionResult = graphQL.execute(executionInput) // 发送响应 resp.characterEncoding = "UTF-8" resp.writer.println(mapper.writeValueAsString(executionResult.toSpecification())) resp.writer.close() }第五步:在应用中,嵌入 Web 服务器(本例中使用的是 Jetty)。
// Serverval server = new Server();// HTTP连接器,在生产环境中要使用HTTPSval http = ServerConnector(server)http.host = "localhost"http.Port = 8080http.idleTimeout = 30000// 搭建handlerval servletContextHandler = ServletContextHandler()servletContextHandler.contextPath = "/"servletContextHandler.addServlet(ServletHolder(MyAppServlet()), "/api")server.handler = servletContextHandler// 启动jetty服务器以监听请求server.start()server.join()第六步:构建并启动应用,请使用 CI/CD 工具来创建、发布和部署 Docker 镜像到集群中。
确保 API 的安全性
在 Salesforce,安全性是首要任务。我们的 API 仅供注册用户访问,而且他们只能访问有权限的数据。在这方面,你可以探索 OAuth 2.0(JWT 授予类型和基于角色的访问控制)和开放策略代理(Open Policy Agent ,OPA)来满足访问控制的需求。
作为最佳实践,认证中间件应该放在 GraphQL 之前,并且要在业务逻辑层有唯一一个地方负责授权,避免在多个地方都要进行检查。除了认证和授权,在设计 API 时还应考虑速率限制、数据脱敏(data masking)和载荷扫描。
总 结
我们已经展示了如何构建一个可扩展、高效、安全的 API。在这个过程中,我们使用应用容器进行扩展,使用 GraphQL 和嵌入式 Jetty 确保高效和轻量级,并优先考虑了 API 的安全性。
今日好文推荐
“不搞职级、人人平等” 25 年后行不通了?Netflix 破天荒引入细分职级:气走老员工
英伟达回应“对中国断供部分高端 GPU”;月薪 3.6 万工程师日均写 7 行代码被开;12 年黑进 40 多家金融机构老板赚百万获刑 |Q 资讯




