
苹果公司六位勇于挑战主流思潮的 AI 研究人员 Iman Mirzadeh、Keivan Alizadeh、Hooman Shahrokhi、Oncel Tuzel、Samy Bengio 和 Mehrdad Farajtabar,近日发表了一篇关于LLM的精彩论文。其中有一段很关键:
我们在语言模型中没有发现任何形式推理的东西……它们的行为更适合用复杂的模式匹配来解释……事实上,这种模式匹配非常脆弱,改个名称就可能改变结果的约 10%!
他们得出的结论在人工智能社区引起轩然大波,很多人对论文本身提出了很大的质疑。
论文地址:https://arxiv.org/pdf/2410.05229
苹果的研究人员对一系列领先语言模型,包括来自 OpenAI、Meta 和其他知名厂商的模型进行研究测试,以确定这些模型处理数学推理任务的能力。结果表明,问题措辞的细微变化都会导致模型性能出现重大差异,从而削弱模型在需要逻辑一致性场景中的可靠性。
苹果研究人员提醒大家注意语言模型中一个长期存在的问题:它们依赖模式匹配,而不是真正的逻辑推理。在几项测试中,研究人员证明,在问题中添加不相关的信息(不应影响数学结果的细节)会导致模型得出的答案大相径庭。
论文中以一个简单的数学题为例,问一个人在一共收集了多少只猕猴桃。当引入一些与猕猴桃数量无关的细节时,OpenAI 的 o1 和 Meta 的 Llama 等模型会错误地调整最终总数,尽管这些额外信息与问题结果无关:

这个例子来自 GSM-NoOp 数据集:我们在问题中添加了一些看似相关但实则与推理和结论都无关的陈述。然而,大多数模型都未能忽视这些陈述,而是盲目地将它们转换成了实际的运算,最终导致错误。
这种推理的脆弱性促使研究人员得出结论,即这些模型没有使用真正的逻辑来解决问题,而是依赖于训练过程中学习到的复杂模式识别。他们发现,“简单地改变名称就可以改变结果”,这对需要在现实世界中进行一致、准确推理的人工智能应用的未来来说是一个令人不安的潜在信号。
根据研究,所有测试的模型,包括较小的开源版本(如 Llama)到专有模型(如 OpenAI 的 GPT-4o),输入数据产生看似无关紧要的变化时,性能都会显著下降。苹果研究人员建议,人工智能可能需要将神经网络与传统的基于符号的推理(称为神经符号人工智能)相结合,以获得更准确的决策和解决问题的能力。
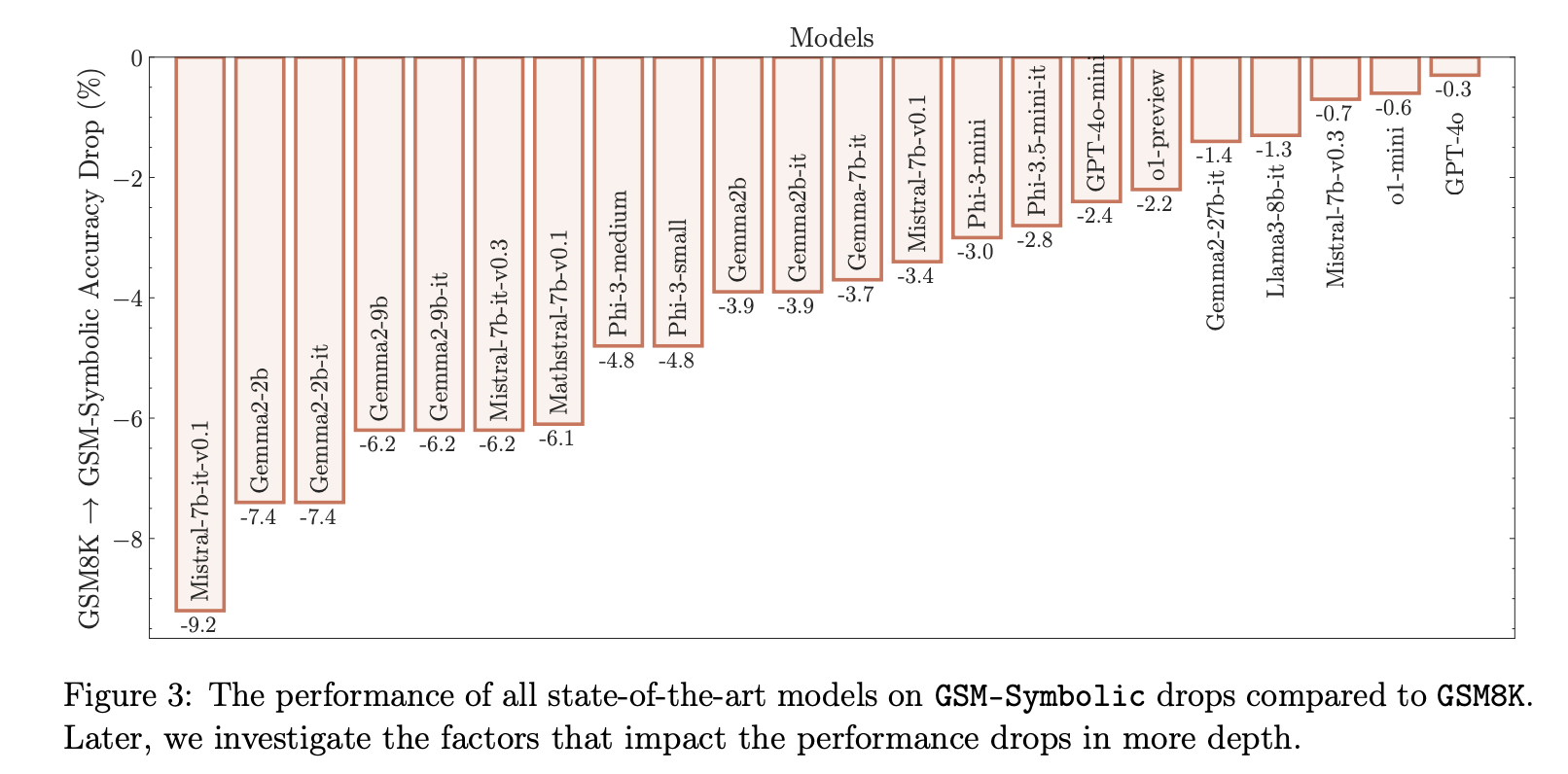
“总体而言,我们在语言模型中没有发现形式推理的证据,包括 Llama、Phi、Gemma 和 Mistral 等开源模型以及领先的闭源模型,包括最近的 OpenAI GPT -4o 和 o1 系列。”论文作者 Mehrdad Farajtabar 在 x 上总结道。
但重要的一点是,这篇论文借此推出了自己改进的新基准测试 GSM-Symbolic,使用符号模板生成多样化的问题,借此控制评估过程,因此被部分网友理解为“带货论文”。
“结论似乎有些道理,但论文本身一团糟”
“你们都想知道为什么苹果在人工智能/机器学习方面落后这么多?道貌岸然的家伙们基本上摧毁了工程团队,这篇论文就是这种做法的结果。”有网友气愤地表示。
首先 ,网友对该论文的 o1 测试的结论提出质疑:根据结果,测试模型之一的 o1 更加稳健,仅下降了 15%,而其他模型则下降了 25-40%,这也与他们的论点相矛盾并削弱了他们的论点。“适当的做法可能是更彻底地重新审视主题和论文,但他们决定继续发布并将其作为附录添加进去。”
“为了捍卫苹果的论文,他们无疑是在 o1 发布之前写的。”有网友指出,“o1 是在一个月前发布的,比论文早了大约两周。你们认为他们在两周内就写完了这篇论文吗?”
其次,有人质疑苹果整篇论文的逻辑性和目的:
这篇由苹果研究科学家( 其中包括前 DeepMind 员工)发表的“论文”被其他持强烈怀疑态度的人转发,这篇论文就做了一件事:制定了另一个大模型目前并不擅长的任意基准。就是这样,它没有做任何其他事情。
那么他们是这样报告结果的吗?当然不是。他们从一个大问题开始:LLM 真的能推理吗?人们可能会认为,在一篇表面上是由受过学术机构训练的有思想的成年人撰写的论文中提出这样的问题,作者可能会继续说他们所说的“真正的推理”是什么意思。
但人们想错了。相反,他们什么也没说,然后立即开始定义他们用来欺骗聊天机器人的任意系统。他们再也没有触及“推理”的概念。事实上,这篇论文甚至没有引用任何其他文献来阐明“真正的逻辑推理”或“真正的数学推理”的含义,尽管这些术语在开头几句中模糊地被提到过。
当然,直到结论部分,在经过几页艰苦的计算后,我们才被告知,我们刚刚见证的是对大语言模型“推理能力”的调查。
抱歉,一篇论文如何证明一个它没有理解、没有提及、甚至没有定义的概念?难道我们要想象,在这个聊天机器人“陷阱”里,藏着对自我反思能力的测试?
老实说,尽管我态度讽刺、充满敌意,但他们制定的新标准还是相当不错的。然而,包装实在令人不快和反感,如此可预测的平庸,甚至没有丝毫迹象表明其有任何意愿去探究他们假装要回答的实际问题,以至于我无法享受它。
还有网友表达了自己对人工智能论文质量的担忧,“近年来与人工智能相关的研究论文存在很大的质量问题。大多数时候,它的专业性远不及我阅读其他主题(图形编程、神经科学)的论文或 LLM 炒作之前的 ML 论文时所感受到的专业性。”
当然,也有网友认可这篇论文有一定的价值:“这篇论文确实有意义,因为它的动机是探索模型的可靠性,而其中的一些因素在生产中确实很重要。但论文里的推理联系似乎有些牵强,它并不完全是我们期望的,甚至可能是我们不想要的。它可能仍然值得作为一种限制因素进行探索和识别,但也确实是被夸大了。我认为它也缺乏与人类对比的基线,如果模型目前的表现比人类更好,那么忽视任何形式的逻辑推理都是很奇怪的。一些模型,比如 GPT-4o,似乎也没有受到测试的不利影响。”“也许他们有点夸大其词,但我不认为他们是最严重的违规者。这更像是哗众取宠,所有人都借此来证明他们对机器学习的哲学或意识形态观点。”
“结论似乎有些道理,但论文本身一团糟。”有网友总结。还有人表示,“苹果公司只是因为没有优秀的大模型而生气。”
“这个结论之前就有了”
Geometric Intelligence 创始人兼首席执行官 Gary Marcus 也就这篇论文发表了一些看法。Marcus 还是一位著名的美国认知科学家和人工智能 (AI) 研究员,在认知心理学、神经科学和人工智能领域做出了重大贡献。他提出,这种因为存在干扰信息而推理失败的例子并不新鲜。早在 2017 年,斯坦福大学的 Robin Jia Percy Liang 就做过类似的研究,结果也差不多:

以这样的 LLM 模型为基础,你根本无法构建可靠的代理,改变一两个无关紧要的单词或添加一些无关紧要的信息就会产生不一样的答案。
大模型无法进行足够抽象的形式推理的另一个表现是,问题越大,模型性能往往越差。以下是 Subbarao Kambhapati 团队最近对 GPT o1做的分析:
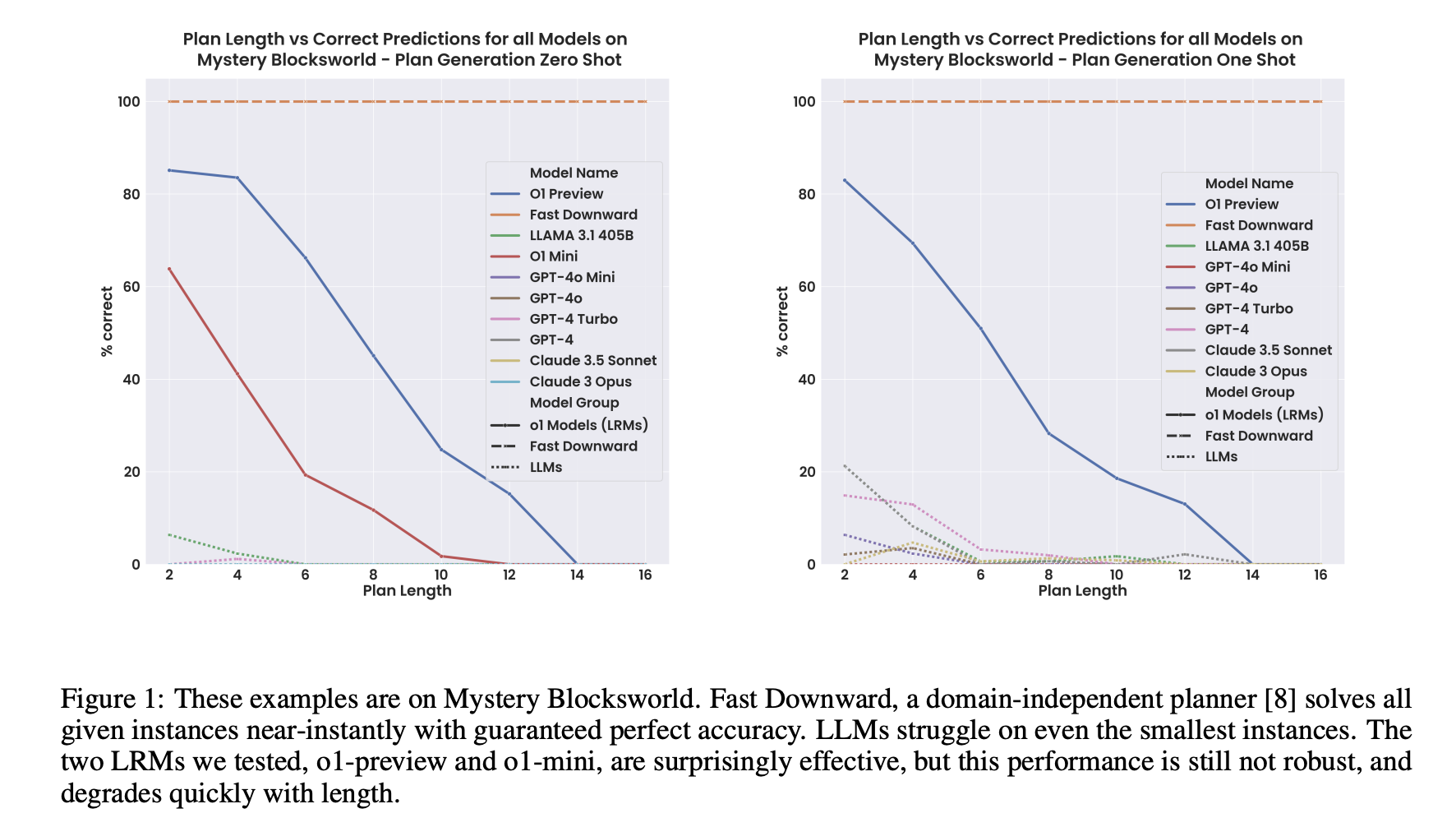
这些例子基于 Mystery Blocksworld 数据集。Fast Downward 是一个领域无关的规划器,它能近乎实时地处理所有给定的实例,并保证准确无误。我们测试的两个 LRM(o1-preview 和 o1-mini),其效果令人惊讶,但性能还不稳定,会随着长度的增加而迅速下降。
对于小问题,LRM 的性能还可以,但当问题变大时,其性能迅速下降。
我们在整数运算中看到了同样的情况。无论是旧模型还是新模型,我们多次观察到了性能随乘法运算问题变大而迅速下降的情况。
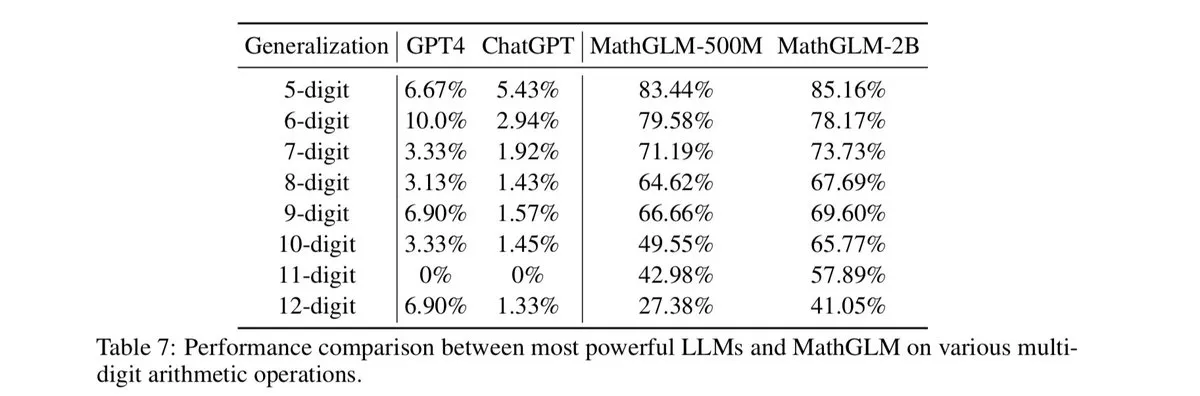
最强大的 LLM 与 MathGLM 在多位数运算方面的性能对比
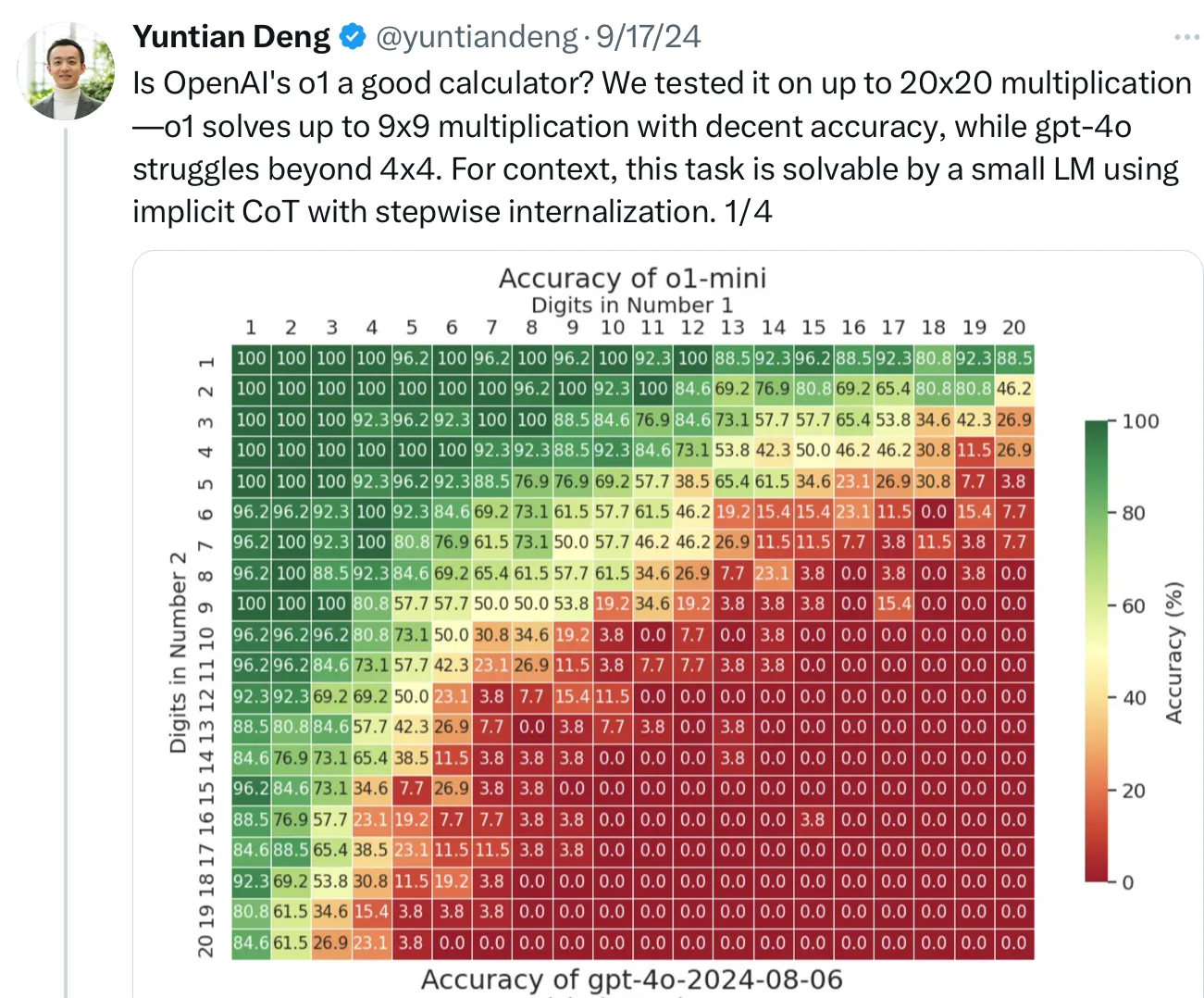
甚至 o1 也面临着这样的问题:
形式推理失败的另外一个例子是不遵守国际象棋的规则:
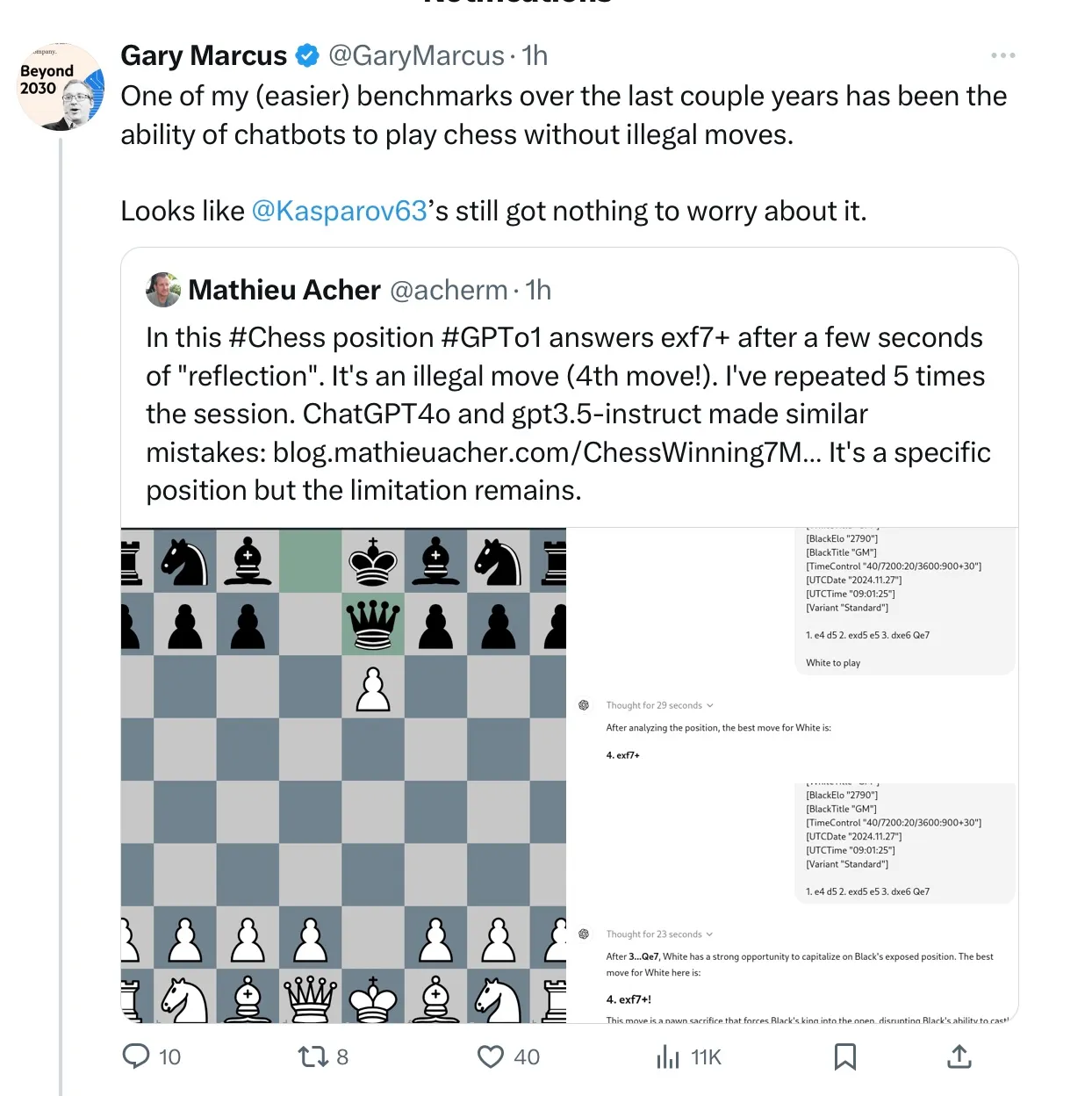
马斯克设想的自动驾驶出租车可能也有类似的问题:可能在大多数常见的情况下,它们都能够安全地行驶,但在某些情况下,它们也可能难以进行足够抽象的推理。不过,我们不太可能获得这方面的系统数据,因为该公司并未披露其所做的工作或结果。
LLM 爱好者的应急之策一直是忽略个别错误。我们在这里看到的模型,包括苹果的最新研究中的、以及最近其他关于数学和规划的研究中(与之前的许多研究相吻合)的,甚至在国际象棋的坊间数据中,都因为过于宽泛和系统化而无法解决这个问题。
“标准神经网络架构无法进行可靠的推断和形式推理,这是我自己1998年和2001年工作的核心主题,也是我 2012 年挑战深度学习、2019 年挑战 LLM 的一个主题。” Marcus 说道。
Marcus 坚信,目前的结果是可靠的。“在‘很快就能实现’的承诺过了四分之一世纪之后,我不想再看你们比划了,你们得让我相信,与大模型兼容的解决方案已经触手可及。”
Marcus 还表示,“我在 2001 年出版的 The Algebraic Mind 一书中提出的观点依然有效:符号操作必须是其中的一部分。在符号操作中,知识被真正地抽象为变量和对这些变量的运算,就像我们在代数和传统计算机编程中看到的那样。神经符号人工智能将这种机制与神经网络相结合——很可能是继续发展的必要条件。”
参考链接:
https://x.com/notadampaul/status/1845014638288859355
https://x.com/notadampaul/status/1845014638288859355
https://garymarcus.substack.com/p/llms-dont-do-formal-reasoning-and




