编者按
“大牛 V 课堂”是 Geekbang 核心栏目,通过邀约专业领域内的互联网顶级大牛分享专业知识和见解,让你了解专业领域内含金量最高的知识。关注geekbang01 公众号,遇见下一位大牛。
本文根据微信资深工程师张文瑞在 ArchSummit 深圳 2015 大会的演讲整理而成,略有修改,感兴趣的读者可以关注 10 月份 QCon 上海 2015 大会的精彩内容。
今天下午跟大家分享的主题是如何实现“有把握”的春晚摇一摇系统。回忆一下春晚的活动,有什么样的活动形式呢?
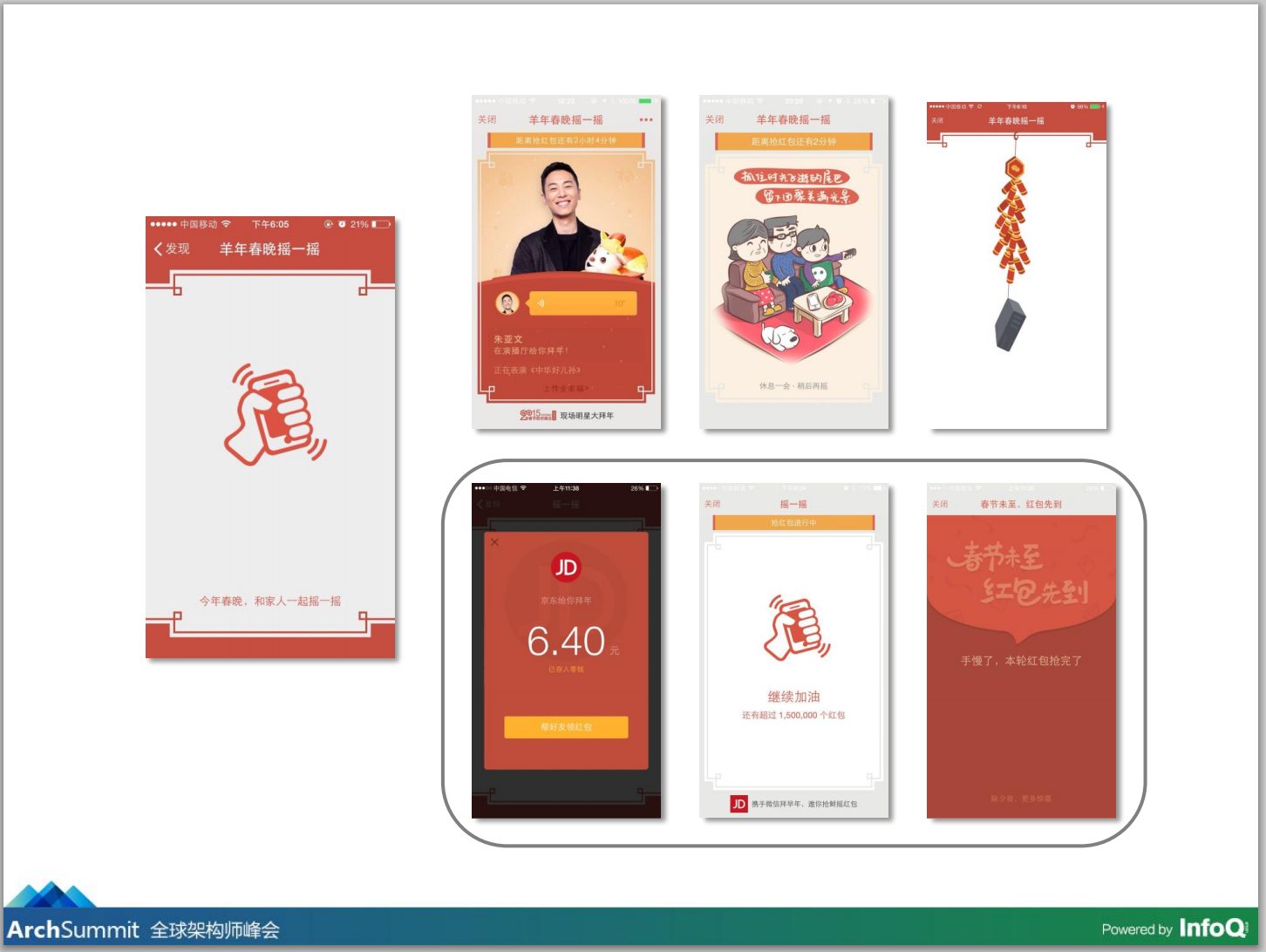
当时我们是直接复用客户端摇一摇入口,专门给春晚摇一摇定制了一个页面,可以摇出“现金拜年”、“红包”。底下的红包肯定是大家比较感兴趣的,也是今天下午重点介绍的内容。比较精彩的活动背后一定会有一个设计比较独到的系统。
V0.1 原型系统
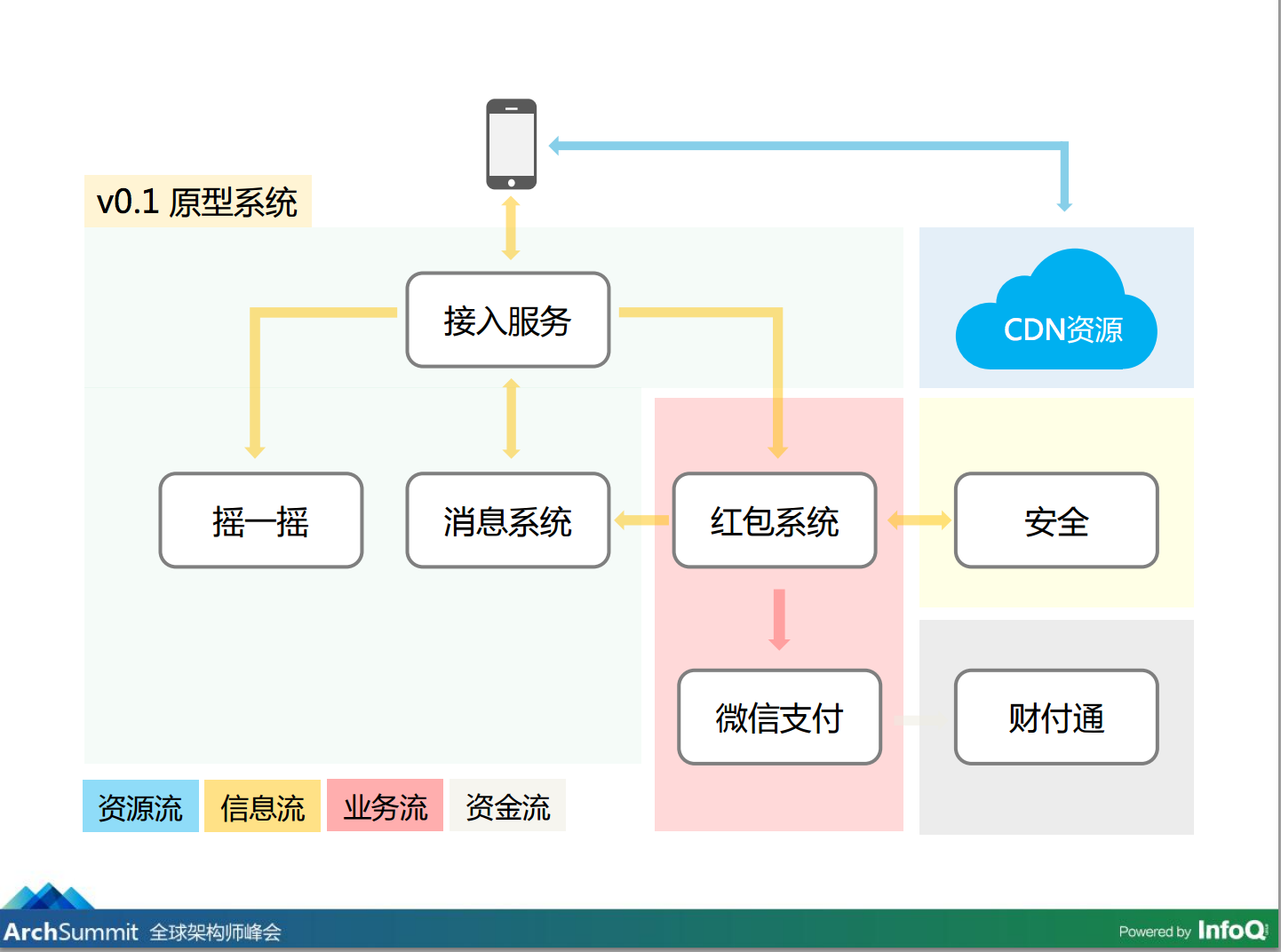
我们看一下这个系统,我们当时做了一个原型系统,比较简单,它已经实现了所有的功能,摇那个手机的时候会通过客户端发出一个请求,接入服务器,然后摇一摇服务,进行等级判断,判断以后把结果给到后端,可能摇到拜年或红包,假设摇到红包,上面有 LOGO 和背景图,客户端把这个 LOGO 和背景图拉回去,用户及时拆开红包,拆的请求会来到红包系统,红包系统进行处理之后会到支付系统,到财富通的转帐系统,最终用户拿到红包。拿到钱以后,只是其中一份,还有好几份是可以分享出去,我们称之为“分裂红包”,通过信息系统转发给好友或群里,好友跟群里的人可以再抢一轮。
整个过程归一下类,叫资源流、信息流、业务流、资金流,今天讲的主要是资源流跟信息流。
原始系统看起来比较简单,是不是修改一下直接拿到春晚上用就可以了?肯定不行的。到底它有什么样的问题呢,为什么我们不能用,在回答这个问题之前想请大家看一下我们面临的挑战。
1、我们面临怎样的挑战?
第一个挑战是比较容易想到的,用户请求量很大,当时预计 7 亿观众,微信用户也挺多的,当时预估一下当时峰值达到一千万每秒,通过图对比一下,左边是春运抢火车票,一秒钟请求的峰值是 12 万,第二个是微信系统,微信系统发消息有个小高峰,那时候峰值每秒钟是 33 万,比较高一点的是预估值一千万每秒,右边是春晚时达到的请求峰值是 1400 万每秒。
这个活动跟春晚是紧密互动的,有很多不确定因素,体现在几个方面。一个是在开发过程中,我们的活动怎么配合春晚,一直没有定下来,很可能持续到春晚开始前,显然我们的客户端跟我们的系统到那时候才发布出去,这时候我们的开发就会碰到比较多的问题了,这是第一个。
第二个,在春晚过程中,因为春晚是直播型节目,节目有可能会变,时长会变,顺序会变,活动过程跟春晚节目紧密衔接在一起,自己也是会有挑战的,这也是不确定的因素。再就是我们系统是定制的,专门为春晚定制,只能运行这么一次,这是挺大的挑战,运行一次的系统不能通过很长的时间,检查它其中有什么问题很难,发出去了以后那一次要么就成功了,要么就失败了。
第三个,因为春晚观众很多,全国人民都在看,高度关注,我们必须保证成功,万一搞砸了就搞砸在全国人民面前了。这么大型的活动在业界少见,缺少经验,没有参考的东西。还有就是我们需要做怎样的准备才能保证万无一失或者万有一失,保证绝大部分用的体验是 OK 的,有很多问题需要我们不断地摸索思考。原型系统不能再用的,再用可能就挂了。
2、原型系统存在哪些问题?
原型系统有哪些问题呢?第一个是在流量带宽上,大量的用户请求会产生大量的带宽,预估带宽峰值是 3000pb 每秒,假设我们资源是无限的能够满足带宽需求,也会碰到一个问题,用户摇到以后有一个等待下载的过程。第二个问题,在接入质量这一块,我们预估同时在线 3.5 亿左右,特别是在外网一旦产生波动的时候怎么保证用户体验不受损而系统正常运作。第三个挑战,请求量很大,1000 万每秒,如何转到摇一摇服务,摇一摇服务也面临一千万请求量,我们系统要同时面对两个一千万请求量,这不是靠机器的,大家都有分布式的经验,这么大请求量的时候任何一点波动都会带来问题,这是一个很大的挑战。
3、我们是如何解决这些问题的?
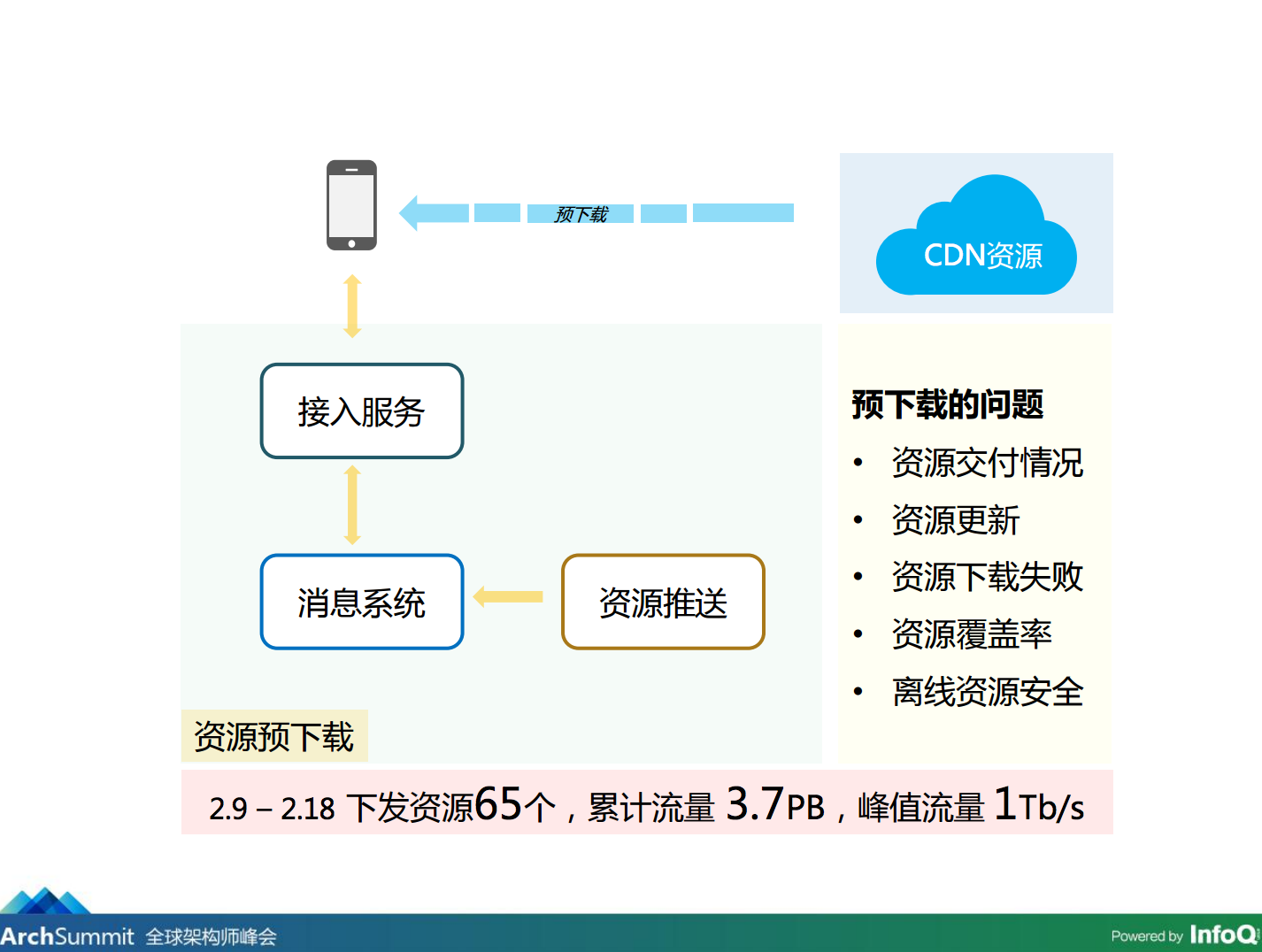
针对以上几点,我们详细看一下每一点我们是怎么做到的。我们首先看一下信心指数,把这个系统拿到春晚去跑有多少信心,这里的指数是 10,如果这个系统拿到春晚去用,而且还成功了,这个概率是 10%。当然我们的系统不能建立在运气的基础上,应该怎么做?第一个,在带宽这一块客户端可以摇到多种多样的结果,结果大部分都是静态资源,静态资源我们可以提前制作出来下发到客户端,在后台做了资源推送的服务,客户端拿到列表以后可以先行下载,客户端利用闲时把资源拉过去。碰到几个问题,资源交付情况的问题,需要增量的发下去;二是资源更新;三是资源下载失败,失败的话怎么办呢;四是资源覆盖率,依靠这个系统下载资源的用户,比如覆盖率只有 20%、30%,两个东西就没有意义了,覆盖率要达到 90% 左右;五是离线资源下载,万一有些人把里面的东西修改了,可能会产生意想不到的结果,怎么保证离线资源的安全。
这里有个数据,2 月 9 号到 2 月 18 号下发资源 65 个,累积流量 3.7PB,峰值流量 1Tb/s。通过这种方式解决了下载资源的问题。
再就是外网接入质量,在上海跟深圳两地建立了十八个接入集群,每个城市有三网的介入,总共部署了 638 台接入服务器,可以支持同时 14.6 亿的在线。
所有用户的请求都会进入到接入服务器,我们建立了 18 个接入集群,保证如果一个出现问题的时候用户可以通过其它的接入,但是在我们内部怎么把请求转给摇一摇服务,摇一摇处理完还要转到后端,怎么解决呢?解决这个问题代价非常大,需要很多资源,最终我们选择把摇一摇服务去掉,把一千万每秒的请求干掉了,把这个服务挪入到接入服务。除了处理摇一摇请求之外,所有微信收消息和发消息都需要中转,因为这个接入服务本身,摇一摇的逻辑,因为时间比较短,如果发消息也受影响就得不偿失了。
恰好有一个好处,我们的接入服务的架构是有利于我们解决这个问题的,在这个接入节点里分为几个部分,一个是负责网络 IO 的,提供长链接,用户可以通过长链接发消息,回头可以把请求中转到另外一个模块,就是接入到逻辑模块,平时提供转发这样的功能,现在可以把接入逻辑插入。这样做还不够,比方说现在做一点修改,还需要上线更新,摇一摇的活动形式没有怎么确定下来,中间还需要修改,但是上线这个模块也不大对,我们就把接入的逻辑这一块再做一次拆分,把逻辑比较固定、比较轻量可以在本地完成的东西,不需要做网络交互的东西放到了接入服务里。
另外一个涉及到网络交互的,需要经常变更的,处理起来也比较复杂的,做了个 Agent,通过这种方式基本上实现了让接入能够内置摇一摇的逻辑,而且接入服务本身的逻辑性不会受到太大的损伤。解决这个问题之后就解决了接入的稳定性问题,后面的问题是摇一摇怎么玩,摇一摇怎么玩是红包怎么玩,在红包过程中怎么保证红包是安全的呢,红包涉及到钱,钱是不能开玩笑的。第三个问题是怎样跟春晚保持互动,春晚现场直播,我们怎么跟现场直播挂钩衔接起来。
先看红包如何发放。
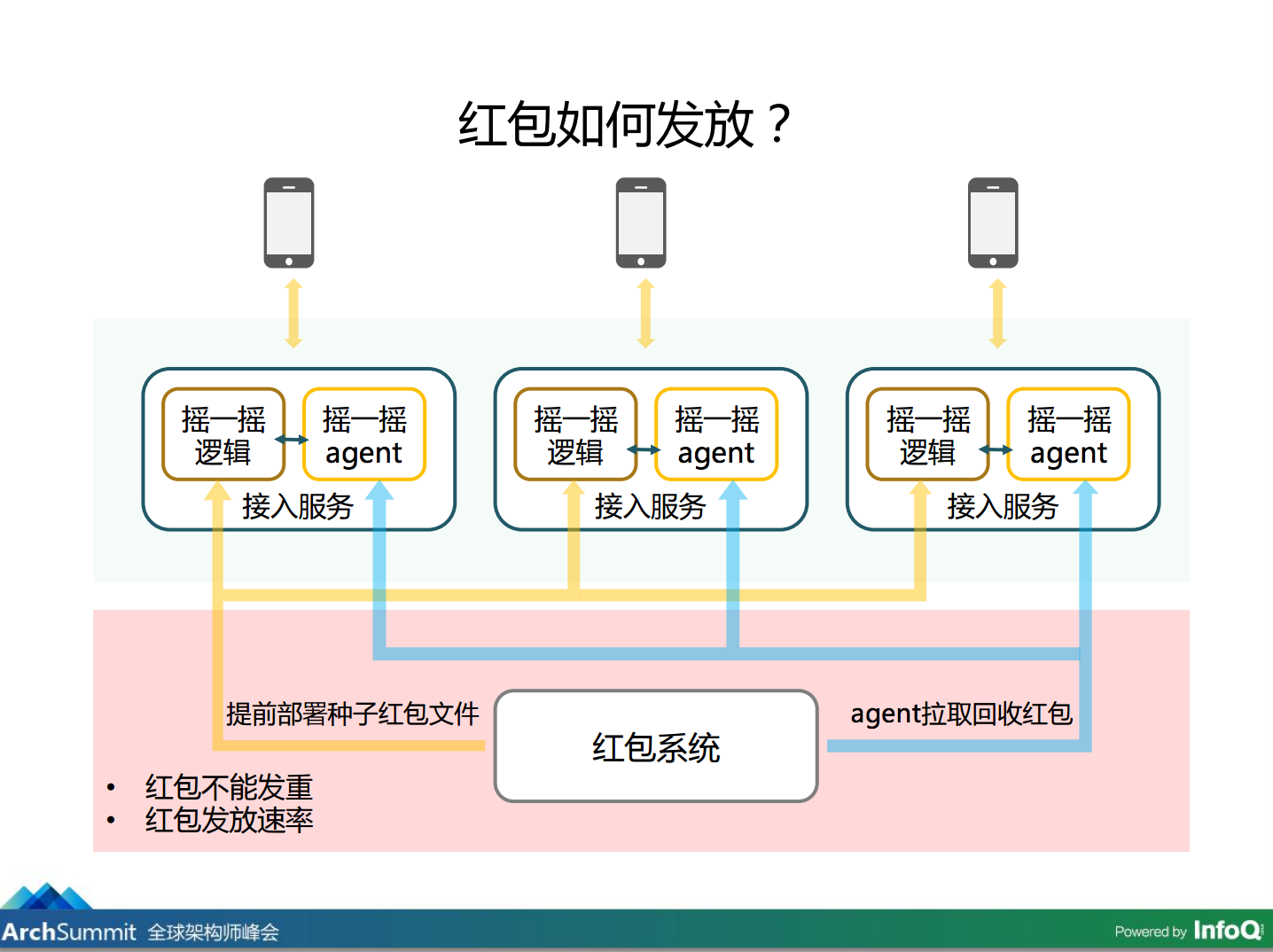
前面说道摇一摇请求,其实是在接入服务做的,红包也是在接入服务里发出去的,为了在发红包过程中不依赖这个系统,我们把红包的种子文件在红包系统里生成出来,切分,分到每个接入服务器里,每个接入服务器里都部署了专门的红包文件。一个红包不能发两次,红包的发放速率需要考虑,发放红包一定有用户拆,拆了还要再抢,我们需要精确控制,确保所有请求量都是在红包系统能够接受的范围内。在这个过程中还会有另外一个风险,用户摇到红包之后还可以有一些分裂红包分出去,他也可以不分享,不分享的也不会浪费,可以回收过来,会通过本地拉回去。这部分因为是比较少量的,问题不大,因为所有红包已经发出去了,只是补充的。这里我们就搞定了红包发放。
二是怎么样保证红包不被多领或恶意领取,每个客户领三个红包,这是要做限制的,但这是有代价的,就是存储的代价。
我们在我们的协议里后台服务接入的摇一摇文件里下发红包的时候写一个用户领取的情况,客户端发再次摇一摇请求的时候带上来,我们检查就行了,这是一个小技巧,这种方式解决用户最多只能领三个、企业只能领一个限制的问题。这个只能解决正版客户端的问题,恶意用户可能不用正版,绕过你的限制,这是有可能的。怎么办呢?一个办法是在 Agent 里面,通过检查本机的数据能够达到一个目的,摇一摇接入服务例有 638 台,如果迫到不同的机器,我们是长连,还可以短连,还可以连到另一台服务器,可以连到不同的地方去。还有一个问题是人海战术,有些人拿着几万、几十万的号抢,抢到都是你的,那怎么办呢?这个没有太好的办法,用大数据分析看用户的行为,你平时养号的吗,正常养号吗,都会登记出来。
怎样跟春晚现场保持互动?需要解决的问题有两个,一个是要迅速,不能拖太长时间,比如现在是刘德华唱歌,如果给出的明星摇一摇还是上一个节目不太合适,要求我们配置变更需要迅速,二是可靠。我们怎么做的呢?
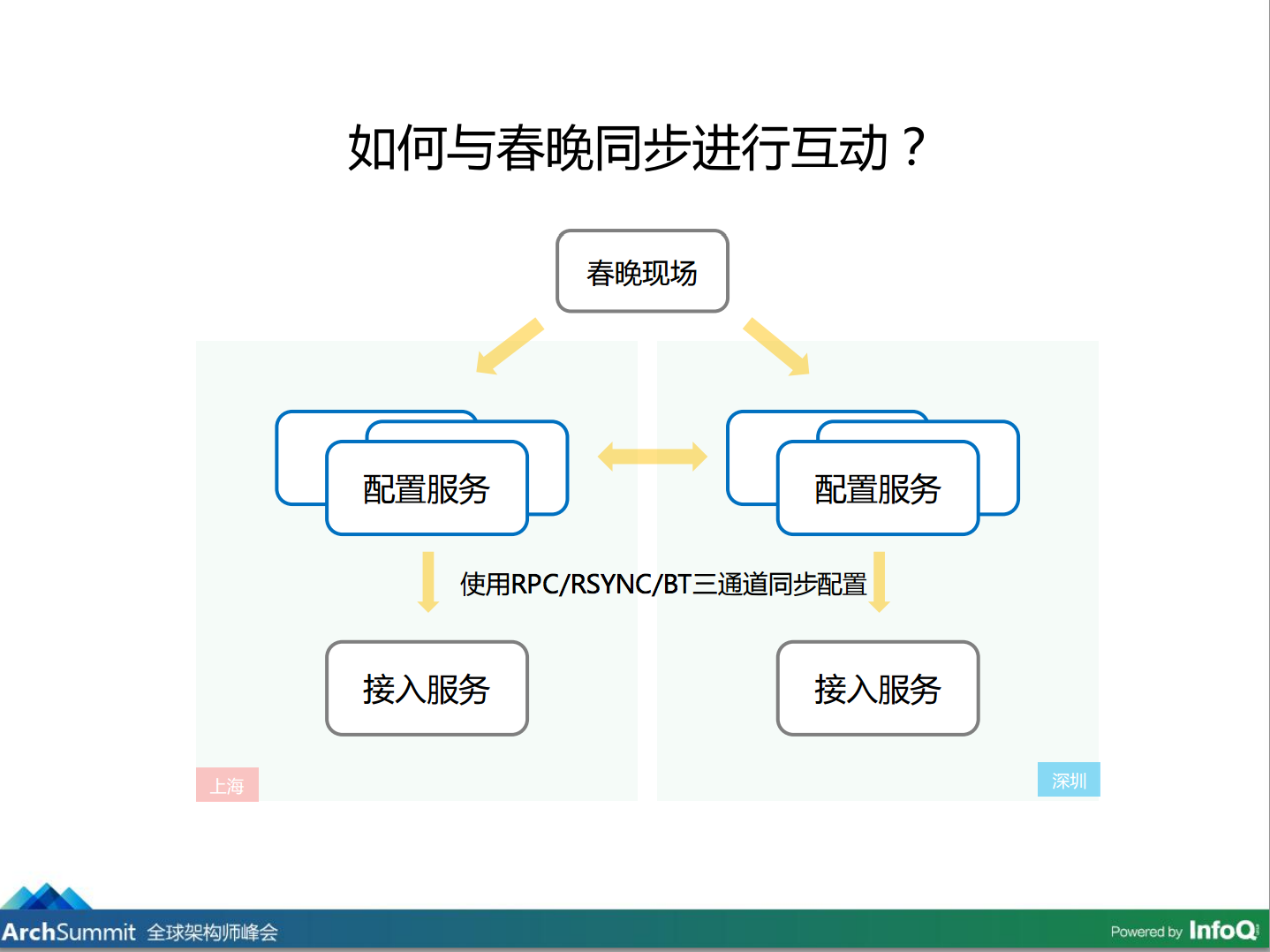
春晚现场我们是专门有同学过去的,在他们电脑装了系统,可以跟我们后台进行交互的,节目变了节切一下,变动的请求会发到后台,我们部署两套,一套在深圳、一套在上海,在这个配置里还准备了三步服务,哪一步都可以,同时还可以同步这个数据,这个数据还可以下发到所有的接入机器,会把它同步过去,不是用一种方式,而是用三种方式,通过这种方式可以迅速的在一千台服务器成功,是不是能够达到配置一定能够用?不一定,春晚现场是不可控的,万一指令没有发出怎么办?如果六个配置服务都挂了怎么办,从上一个节目切到下一个节目的时候发生这种问题不是太大,但是主持人在十点三十的时候如果摇红包一摇啥都没有,这就怒了,口播出不来也就挂了。
怎么做的呢?主持人肯定有口播,口播的时间点我们大致知道,虽然不知道精确的时间点,比如彩排的时候告诉我们一个时间,后来变了,我们大致知道时间范围,可以做倒计时的配置,比如十点半不管你有没有口播我们都要发红包了。如果节目延时太长了,你的红包十分钟发完了,之后摇不到,那也不行,这种情况下我们做了校正,在节目过程中我们不断校正倒计时的时间,设了一个策略,定了一个流程,半小时的时候要通知一下我这个时间,因为它是预估的,节目越到后面能定下来的时间范围越精确,提前告诉我们,我们就可以调整。那时候现场是在春晚的小会议室,在小会议室看不到现场什么情况,也是通过电视看,结果电视没信号了,就蒙了,校准就不知道现在怎么回事,进行到哪一步了,当时很着急,还好后来没事,后续的几个节目还是校正回来了,最终我们是精确的在那个时间点出现了抢红包。前面讲了怎么在系统解决流量的问题、请求量的问题,最重要的一点是我们预估是一千万每秒,但如果春晚现场出来的是两千万、三千万或四千万怎么办,是不是整个系统就挂掉了。
我们就是采用过载保护,过载保护中心点是两点,前端保护后端,后端拒绝前端。一个是在客户端埋入一个逻辑,每次摇变成一个请求,摇每十秒钟或五秒钟发送一个请求,这样可以大幅度降低服务器的压力,这只会发生到几个点,一个是服务访问不了、服务访问超时和服务限速。实时计算接入负载,看 CPU 的负载,在衔接点给这台服务器的用户返回一个东西,就是你要限速了,你使用哪一档的限速,通过这种方式,当时有四千万用户在摇我们也能扛得住。
V0.5 测试版
这是我们的 0.5 测试版,对这个我们的信心指数是 50,为什么只有 50% 的把握?
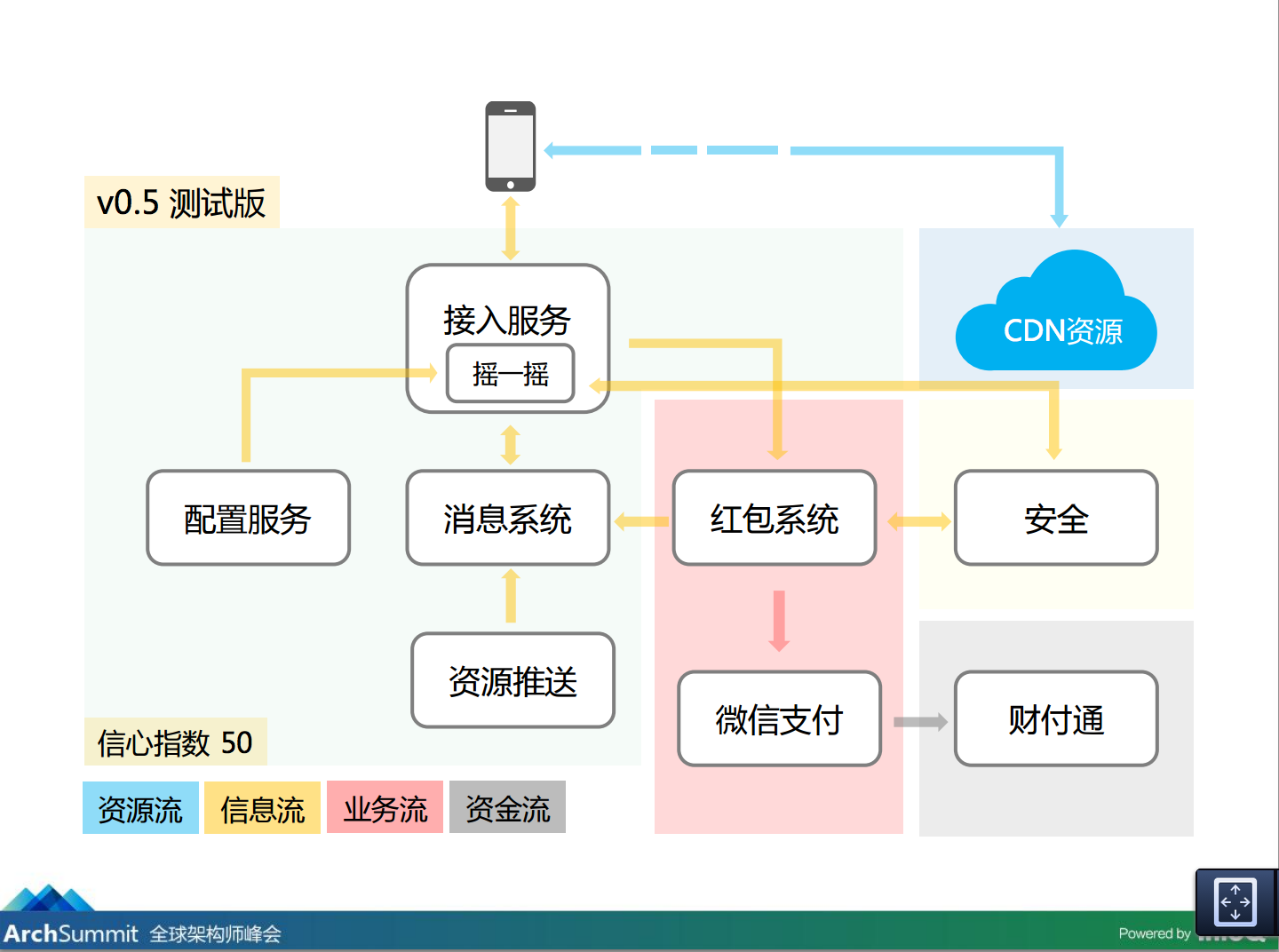
我们前面解决的问题都是解决用户能摇到红包,服务器还不会坏掉,但是对摇红包来说那是第一步,后面还有好几步,还要把红包拆出来,还要分享,分享完以后其它人可以抢,这个体验是要保证的,简单分析一下可以发现前面是本人操作,后面是好友操作,这里就存在一个契机,你可以做一些服务,一旦出现问题是可以利用的点,可以做延时。剩下的问题是保证本人操作比较好,后面出点问题可以延迟,有延迟表示有时间差处理那个东西。
1、核心体验是什么?
这里面我们需要确保成功,确保体验是完全 OK 的,确保成功的时候前面提到原型的系统里解决了摇到红包的问题,剩下的就是拆红包和分享红包。怎么样确保拆红包和分享红包的用户体验?
2、如何确保拆 / 分享红包的用户体验?
拆红包和分享红包可以做一下切割,可以切割成两个部分,一个是用户的操作,点了分享红包按纽,之后是转帐,对我们来说确保前面一点就可以了,核心体验设计的东西再次缩小范围,确保用户操作这一步能够成功。怎么确保呢?我们称之为“铁三角”的东西,拆 / 分享红包 = 用户操作 + 后台彰武逻辑。这是我们能做到的最高程度了。
3、还能做得更极致吗?
但我们还可以做的更好一点,前面这个用户看起来还是成功的,只是入帐入的稍微迟一点点,用户感觉不到。如果我们异步队列这里挂了,或者网络不可用了,概率比较低,我们有三个数据中心,挂掉一个问题不大,万一真的不能用呢,我们又做了一次异步,分两部分:一个是业务逻辑,校验这个红包是不是这个用户的,还有一个透传队列,把这个数据再丢到后边,其实可以相信本机的处理一般是可以成功的,只要做好性能测试基本上是靠谱的。在后面出现问题的时候我们用户的体验基本不受损,保证绝大多数用户的体验是 OK 的。
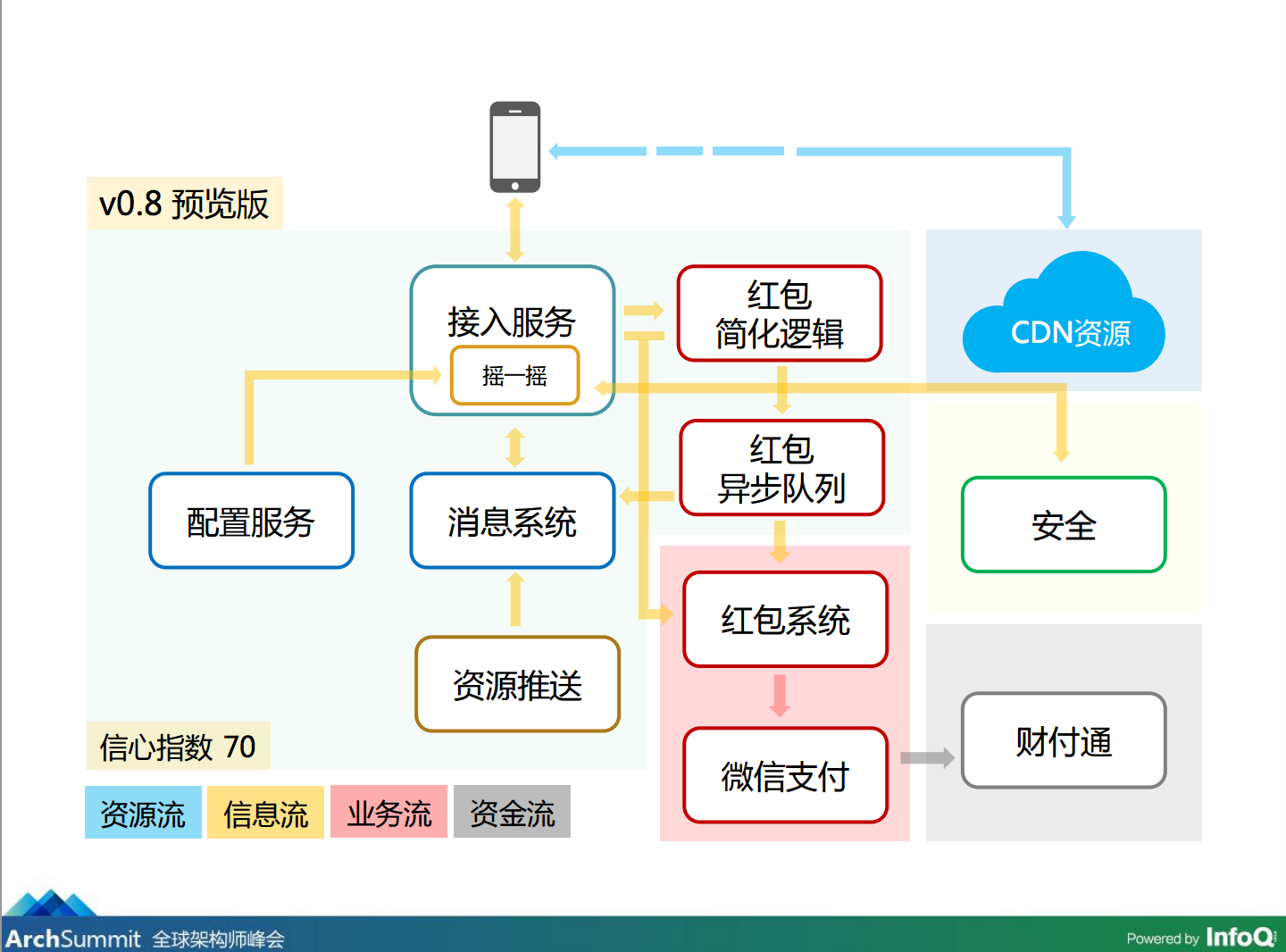
V0.8 预览版
我们又做了 0.8 的版本,预览版,信心指数 70,我们认为这个东西有七成把握是可以成功的。
大家知道设计并不等于实现,设计的再好实践有问题也很崩溃,要保证设计一是全程压测,二是专题 CODE REVIEW,三是内部演练,四是线上预热,五是复盘与调整。
复盘包括两部分,有问题的时候可以把异常问题看出来,二是很正常,跑的时候是不是跟想象的一样,需要对正常情况下的数据做预估的重新评估,看看是不是符合预期。两次预热,一次是摇了 3.1 亿次,峰值 5000 万一分钟,100 万每秒,跟我们估算的一千万每秒差很远,当时只是针对 iPhone 用户,放开一个小红点,你看到的时候可以抢,发放红包 5 万每秒,春晚当晚也是五万每秒。后面又发了一次,针对前面几个问题再做一次。
V1.0 正式版
做完这两次连接后面就迎接 2 月 18 号春晚的真正考验。这是 1.0 正式版,信心指数达到 80,我们认为 80% 是可以搞定的。
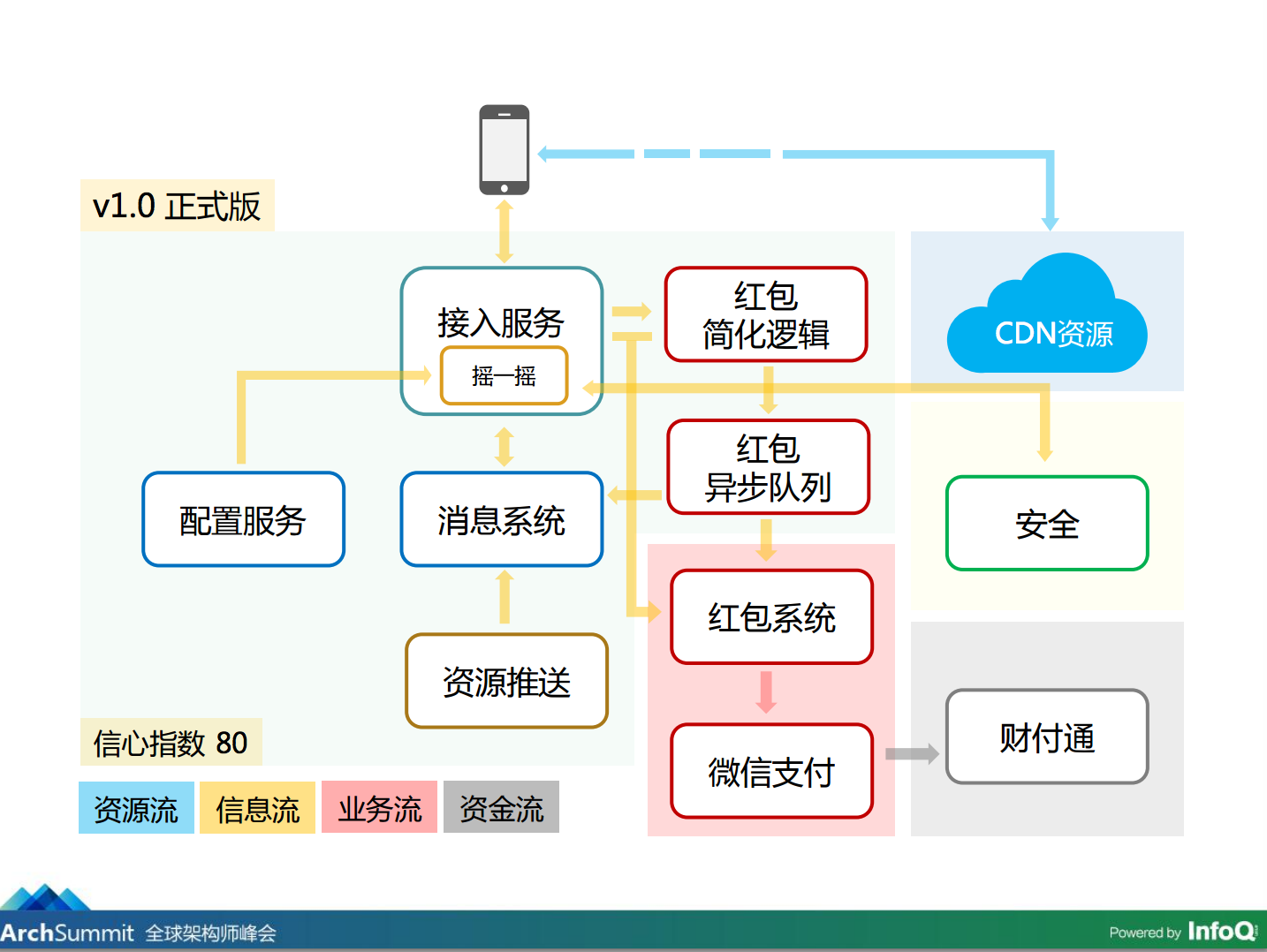
剩下 20% 在哪里?有 10% 是在现场,现场不可能一帆风顺,有可能现场摇的很 High,但后面到处灭火,10% 是在现场处置的时候有比较好的预案和方案能够解决,另外 10% 是人算不如天算,一个很小的点出现问题导致被放大所有用户受影响也是有可能的,我们很难控制了。要做出完美无缺的基本不太可能,剩下 10% 就是留运气。
2 月 18 号跑出来的结果是这样的,当时摇了 110 亿次,峰值是 8.1 亿每分钟,1400 万每秒。

我今天跟大家的分享到这里。谢谢大家。
作者的微信公众号“老崔瞎编”,关注 IT 趋势,承载前沿、深入、有温度的内容。感兴趣的读者可以搜索 ID:laocuixiabian,或者扫描下方二维码加关注。





