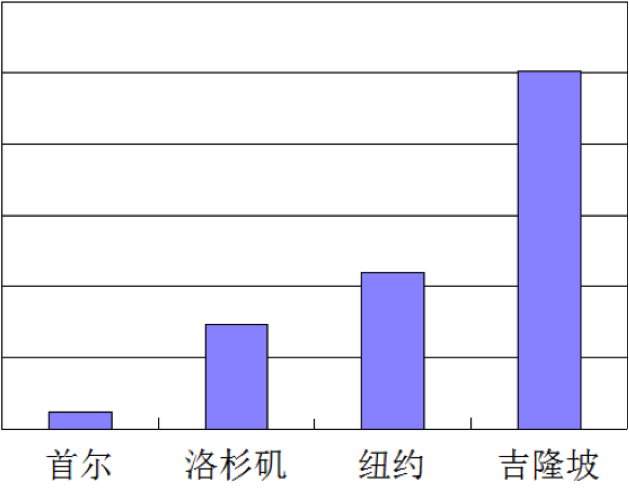
在国内网络环境下,单机房的可靠性无法满足大型互联网服务的要求,如机房掉电,光缆被挖的情况也发生过。微信就曾发生大面积故障,包括微信信息无法发出、无法刷新朋友圈、无法连接微信网页版,或接收到的图片无法打开等。同时,微信公众平台也出现了 503 报错,范围影响北京、上海、广东、浙江等近 20 个省市。故障的原因,微信团队指出是由于“市政道路施工导致通信光缆被挖断,影响了微信服务器的正常连接”。单机房除了单点风险之外,另外一个问题是不适应复杂的网络环境,下图是调研国外各地区用户访问微博的延迟情况,可以看到南方海外用户的访问延迟比较大。
为了解决上述问题,微博在 2010 年启动了多机房部署的架构升级。微博不同于静态内容,静态内容 CDN 基本上大的互联网公司都会做,已经非常成熟。动态内容 CDN 是业内的难点,国内很少有公司能够做到非常成熟的多机房动态内容发布的成熟方案。同时根据微博业务特点,又要求多机房方案能够支持海量规模、可扩展、高性能、低延迟、高可用,所以面临很多技术挑战。 微博的多机房架构 V1 版本,解决了海量动态数据的 CDN 同步问题。一般业界的数据同步架构可以归纳为三种:Master-Slave,Multi-Master,Paxos。考虑到微博的特点是海量数据,低延迟,弱一致性,所以 Paxos 并不适合微博,而 Multi-Master 在当时并没有成熟的产品,所以微博开始采用的是 Master-Slave 方案,如下图:
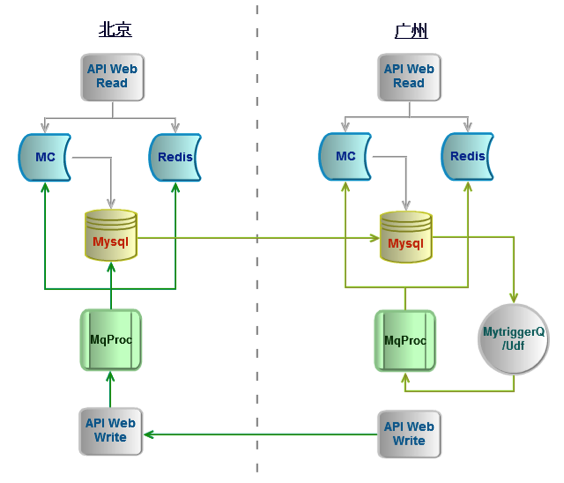
由于 Memcached 服务端是无状态的,分布式是在客户端实现,所以需要解决两个机房 Memcached 数据同步的问题。微博研发了 MytriggerQ,通过解析 Mysql 的 binlog,还原更新操作实现 Memcached 数据同步。
数据库方面 Mysql 自身的 Master-Slave 同步实现是比较成熟的。但是在微博的海量数据情况下,广州两从的结构就导致同步的数据量翻倍,导致带宽被大量占用。针对这个问题微博是通过 Relay 的方式来解决,即北京到广州仅需要同步一份数据,到广州后再由 Relay 服务器同步两份数据给从库。由于 Relay 服务器可以代理多个从库,所以在基本没有增加资源的情况下,我们把同步带宽降低了一倍。 而 Redis 的同步实现就不太成熟了,由于不支持断点续传,一旦网络抖动导致主从不一致后,导致大量的带宽被占用,甚至出现过专线 100% 被占用的情况,严重影响正常的机房间通信,同步恢复时间需要几个小时甚至几天。所以微博对 Redis 的同步机制进行了改造,利用 AOF 特性支持断点续传。改造后即使在专线中断的情况下,同步也可以在几秒钟内恢复正常。 V1 版本实现了微博多机房从无到有,V2 版本重点解决了多机房的可靠性和可扩展性。V2 版本实现了 Master-Master 架构,通过消息总线同步用户操作行为,而不再依赖底层存储系统的同步,每个机房都独立完成读写操作。
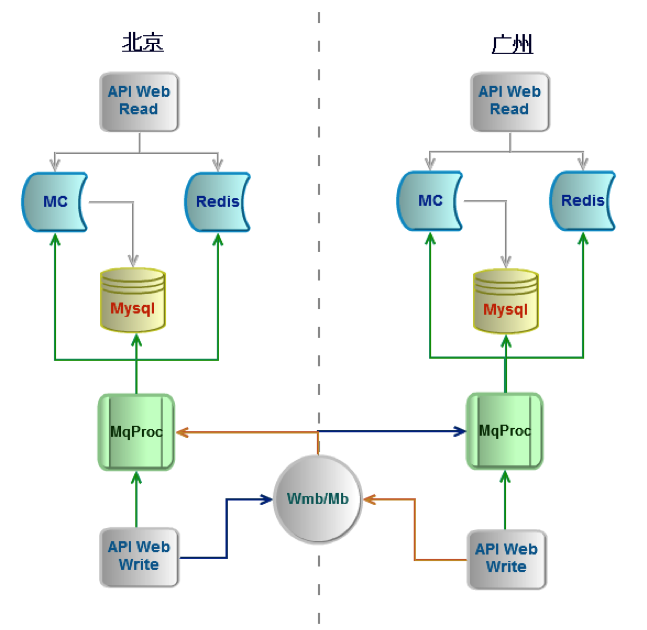
面对微博海量实时数据,业界通用的消息总线产品无法满足性能要求,所以我们自己基于 MemcacheQ 实现了一套消息总线 WMB,它与普通消息总线产品最大的差别是采用一写一读的方式实现消息同步。这种方式最大的好处是消除了并发锁消耗,单机性能可以发挥到极致,而吞吐量可以通过增加机器线性扩容。目前这套消息总线同步性能单机极限达到每秒 10 万消息同步性能。
可靠性方面,由于各机房仅通过消息总线进行同步,不依赖任何底层资源,所以各个机房都可以独立对外提供服务,任何一个机房出现问题都可以实现流量快速切换。可扩展性方面,增加一个机房仅需线性扩展消息总线即可完成,机房的部署结构与数据同步对业务完全透明。微博多机房已经实现从北京、广州两个机房的结构升级到广州亚太、北京电信、北京联通三个核心机房的部署结构。
Master-Master 架构非常依赖消息总线的一致性,而在网络延迟比较验证的多机房环境下,MemcacheQ 存在消息丢失的隐患,即而服务端完成消息读取,但在传输过程中超时,客户端无法再次获取这条消息。为了解决这个问题,我们在 WMB 的升级版 WeiBus 消息总线中实现了消息同步序号的功能,支持客户端在超时情况下,可重复获取消息。
但是随着微博业务的蓬勃发展,业务依赖关系越来越复杂,多机房部署成本压力越来越大,而且运维成本也不断攀升,下图是一个产品的服务依赖关系图。微博多机房 V3 版本实现了业务灵活多机房部署架构,支持业务自定义机房部署个数,及部署区域。
业务定制部署需要解决业务路由问题。在当前全国的网络环境下,南北网络专线延迟一般在 30 到 40 毫秒之间,而机房内延迟一般小于 1ms。业务路由需要支持尽可能路由到调用本地机房调用,对需要跨机房调用的请求进行打包以便减少网络延迟的影响。微博根据自身业务特点,实现了业务路由服务,支持将多个业务请求进行打包,将多个请求打包成一个请求,自动识别本地业务部署,把需要跨机房调用的请求一次性请求到对应机房,并将返回的结果打包后一并返回。并且支持自动识别业务部署结构变更,并对非核心业务异常自动隔离。
随着移动互联网的迅猛发展,3 个机房的部署结构不能完全解决用户访问速度问题,一种解决方案是让机房更加靠近用户。但是社交网络由于数据的网状访问,较难选择合适的切分维度,目前微博核心业务仍需要各机房同步全量数据,部署更多机房的成本压力比较大。QZone 的 SET 化和 Tumblr 的 Cell 化在解决社交网络拆分维度方面都值得参考,微博也在进行 Cell 化方面的尝试,相关信息也会在 @微博平台架构 微博帐号上与社区进行交流,希望感兴趣的同学积极与我们互动。 微博只是多机房之路上迈出了一小步,仍有很多难题有待攻克。希望对多机房系统,对微博的架构感兴趣的同学加入到我们微博的团队,共同打造一流的分布式系统。
感谢刘宇对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




