一. 配置的那些事儿
1.业务背景
作为大型复杂分布式系统,微博平台中存在大量的配置信息,这些配置信息定义了平台中的 RPC 服务和资源(memcached、redis、mysql 等)的地址,以及这些服务和资源的元数据信息。
在微博早期,配置信息散落在工程的代码中,这种方式简单方便,但是微博平台系统规模扩大和业务部署复杂度的提升带来了一些问题:
- 服务按照业务和重要程度部署在多个池子,不同池子的配置信息不同。
- 服务多机房部署,不同机房的配置信息也不同。
- 开发、测试以及上线部署的配置信息亦不同。
为了解决以上问题,微博平台对配置做了一次大规模调整,将代码和配置分离,配置按照机房、业务池以及环境拆分,并且存储在本地文件系统中约定的位置。分离之后,各业务池、各机房的配置更加灵活,也为配置向 config service 迁移提供了条件。
随着微博平台服务器规模的持续增长,RPC 服务和资源的故障和变更已经变为一种常态,在日常维护过程中,经常会遇到以下场景:
- 某一组 memcacheq 资源突然流量猛增,需要快速扩容
- 某一 redis 资源访问过载,需要立即降级调用它的服务
而现有的解决方案无法解决这些问题,我们迫切需要一个分布式环境下的持久配置系统,提供高效的配置注册获取和及时变更通知服务,于是 vintage(config service 在微博内部的代号)应运而生。
2.vintage
Vintage 是典型的基于 pub-sub 模型的通讯框架,在业界类似的系统很多,比如淘宝的 diamond 和软负载中心,zookeeper 在某些系统中(如 kafka)也扮演着类似的角色。
Vintage 将信息集中管理在云端,并且提供实时的变更通知。Vintage 主要应用于两种主要场景:配置管理和命名管理,配置管理主要维护静态配置数据(如服务超时时间、降级开关状态);命名管理主要维护 RPC 服务地址信息。两种场景看起来极为相似,但是也存在如下差别:
- 生命周期不同:命名服务需要管理服务的生命周期,实时探测服务的存活状态;配置服务主要管理静态的信息。
- 数据产生方式不同:命名服务数据来源于服务的注册;配置服务数据来源于 OP 手动添加。
- 数据精确度不同:命名服务数据可能会存在一定时间窗口内的误判(后面会提到);配置服务的数据会非常精确。
Vintage 在微博平台内部已经获得了很大的推广和使用,RPC service、cache service、分布式 trace 系统、queue service 都在一定程度上依赖 vintage,它的重要程度是不言而喻的。 那么如此重要的服务是如何设计的呢?
二.Vintage 设计和架构
1. 架构设计
Vintage 在设计之初就明确了以下的目标:
- 高可用:vintage 管理着服务的地址和元数据信息,其本身的高可用性决定着系统整体成败。
- 低延迟:微博平台中每次调用理论上都会与 vintage 有一次或者多次的交互,因此 vintage 访问延迟影响着系统整体的性能。
- 时效性:对于变更及时响应和通知
vintage 选择 redis 作为配置信息的落地存储,结构简单,无单点,具体如下图所示:
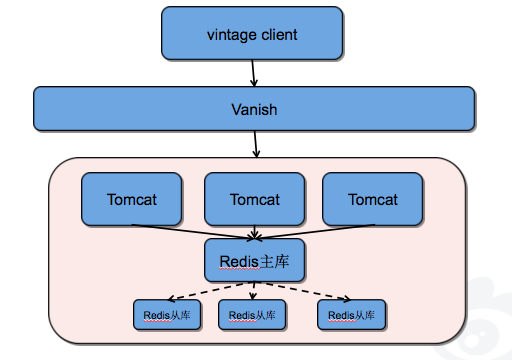
2. 容灾机制
vintage 以高可用性为设计根本,我们在容灾机制上投入了很大的精力。配置数据存储在 redis、服务端缓存、客户端 snapshot 文件中,在多种故障场景下,vintage 均能轻松应付:
- redis 主库 crash,可以迅速切换到从库,继续提供服务
- redis 主库和从库同时 crash,服务端的内存缓存可以保证 vintage 服务正常运行。
- vintage 服务端全部不可用,客户端本地 snapshot 文件也可以提供服务,只是变更通知功能将失效。
由此可知,只有在服务端 redis、tomcat 全部不可用,客户端的 snapshot 文件被删除或者损坏的情况下,客户端应用才会无法从 vintage 获取配置信息,导致服务不可用,这种场景出现的几率极低。
3.变更通知
vintage 相比于本地文件系统保存配置信息最大的优势就在于可以对配置变更的实时通知。实现变更通知最直观的做法就是客户端定期查询配置信息,但是这种方式存在很多问题。
首先,配置信息在 redis 中以 hash 格式存储,对信息的每次全量获取都是一次 hgetall 操作,这个操作会极大的增加 redis 负载,降低吞吐量。
其次,vintage 对应的客户端很多,其本身存储的数据量也很大,大量的全量获取会压满网卡。
vintage 的解决方案是这样的:
vintage 中除了存储配置信息以外还会存储信息的 MD5 码,同时配置信息和 MD5 码也会缓存在客户端。客户端应用发起的每次查询操作实际上只是查询客户端缓存中信息。而 vintage client 会定期的访问 server 获得最新的 MD5 码与本地缓存的 MD5 比对,如果发生变化才会从 server 获得最新的信息,并且缓存在客户端缓存和 snapshot 文件中。具体流程如下图所示:
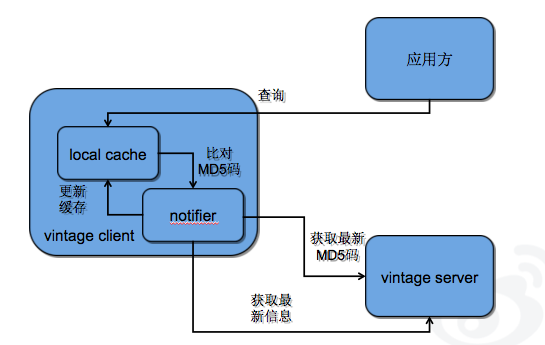
4.服务生命周期
之前提到,vintage 的命名管理功能主要维护的是 RPC 服务的地址信息,这些信息是有生命周期的,生命周期状态有三个:working、unreachable 和 removed,状态变更图如下:
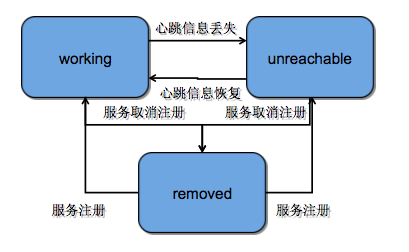
其中,服务生命周期中的 working 态和 unreachable 态的变化是通过 RPC server 和 config service 之间的心跳完成的,心跳时间戳也是存储在 redis 中。每台应用服务器中存在心跳接收器(heartbeat acceptor)异步写入心跳时间戳,同时存在一个心跳处理器(heartbeat processor)定期的检查心跳是否出现连续缺失。具体流程如下图所示:
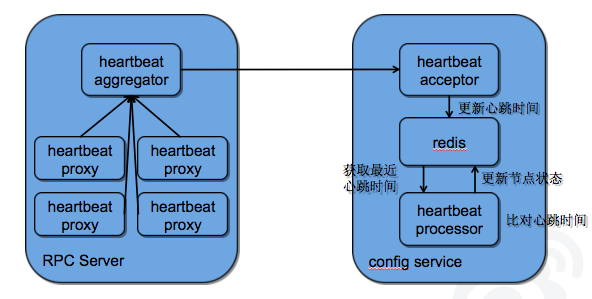
心跳服务对于命名服务来说至关重要,直接影响着服务的生命周期变化,在实际应用过程中,需要注意一下几点:
- heartbeat acceptor 和 heartbeat processor 所做操作均是异步的,需要实时的监控线程池中的任务堆积情况,以免任务堆积后导致 heartbeat 写入不实时造成服务状态误判。
- 微博平台使用的 RPC server 可以在单个实例内跑不同的服务,heartbeat aggregator 会把所有服务的心跳数据收集起来进行压缩传输,减少了带宽消耗。
- 优化 redis 连接池,避免 heartbeat acceptor 对 redis 的集中写入导致写入失败。
三. 遇到的问题
vintage 在设计上非常简单,代码量也不是很大,但是在实际使用中还是遇到各种各样的问题,以下针对几个典型问题和大家分享以下。
1.节点状态误判
vintage 接受来自所管理的 RPC 服务的心跳信息,并且根据配置的策略判断 RPC 服务是否存活。那么在不考虑心跳包在传输过程中被篡改的前提下(Byzantine Generals Problem),只会出现两种情况:
- vintage 正确判断 RPC 服务节点状态。
- RPC 服务节点存活,但是由于传输信道的不可靠导致 vintage 没有接收到心跳消息,从而导致 vintage 对于节点状态的误判(Two Generals Problem)。
如果第二种情况发生会产生非常严重的后果,极端情况下会 vintage 会摘除所有的 RPC 服务节点,导致服务整体不可用。负载中心类型的产品通常都会遇到这样的问题,vintage 是如何解决的呢?
首先,vintage 不会摘除心跳检测中标志死亡的节点,只是把它标记为不可达的状态(unreachable);而对于不可达节点的使用,vintage client 中提供多种策略,由应用方来选择是否使用以及如何使用不可达节点。
其次,vintage 会保护服务节点,控制心跳检测中标示不可达节点的数量,避免某一个服务集群的所有节点被标志为不可达。
2.变更“风暴”
之前提到引用方使用的信息实际上时存储在 vintage client 的本地缓存中,那么当应用方重启(如进行上线)或者信息发生变更时,vintage client 的本地缓存失效,大量的请求会穿透到 vintage server 以及 redis 中,造成系统瞬时负载和网卡流量的暴涨,我们称之为变更“风暴”。变更风暴对于 vintage 来说是致命的,因为应用方只有在此时会和 vintage server 交互,如果 vintage server crash,会造成对 vintage 强依赖的应用方永远无法启动。
我们的应对方案如下:
- vintage server 增加 hot local cache,降低风暴过程中大量的对于同一组配置信息的请求穿透到 redis 中。
- vintage client 增加本地文件的缓存,在应用系统启动时使用文件中存储的信息预热内存缓存。
- 压缩 vintage 中存储的信息,降低风暴对于网卡的压力。
四. 结束语
vintage 在微博系统架构层面发挥的作用是不言而喻的,它增强了微博架构的鲁棒性,使各个业务系统可以进行快速地变更、降级、切换流量,它是微博架构从稚嫩走向成熟的标示。
感谢崔康对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




