
前言
下面是一段利用 Co-Pilot 辅助开发的小视频,这是 Apache SeaTunnel 开发者日常开发流程中的一小部分。如果你还没有用过 Co-Pilot、ChatGPT 或者私有化大模型帮助你辅助开发的话,未来的 5 年,你可能很快就要被行业所淘汰。因为这些善于使用 AIGC 辅助编程的人可以 10 倍于你的速度开发相应的代码,而你没有这个技能。我并不是危言耸听,读完此文,我相信你对 AIGC 研发提升研发效率会有全新的认知。
大模型颠覆传统初级程序员的培训和辅导过程,让技术和经验“平权”
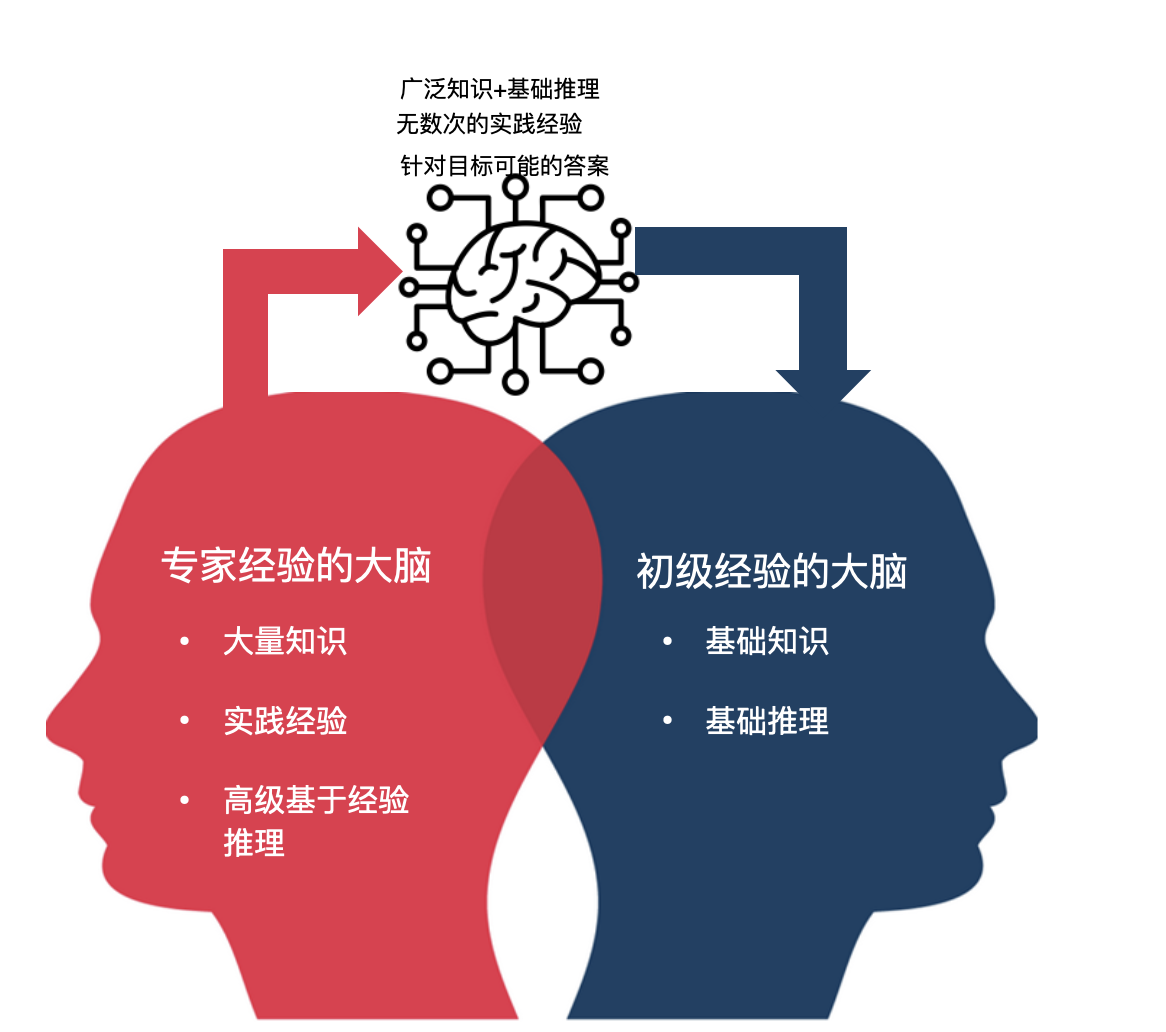
过去,初级程序员入职学习编程时,往往是师傅给一个任务需求,教大体的思路,然后在初级程序员写出代码工作当中培训和纠正,针对不同的命题告诉不同的方案,直到初级程序员把这些经验学会。
但大模型的到来把这个过程完全改变了。大模型自己具有广泛的知识,而且有一些基础的推理能力,它可以经历无数次的实践,学习公司里各种各样的代码和业务定义,它所遇到的场景要比师傅当年要遇到的场景多得多,同时它会根据开发者的需求和目标给出可能的答案。
这个过程就像我们多了一个无所不能的“师傅”,随叫随到还可以给你直接写出可能的代码,让你参考学习,让一个初级的程序员快速具有“师傅”写代码的能力。经过自己的学习和调整,就可以提交出一个远超你自己个人水平的代码,让别人 Review。
那么,我们有什么理由不使用大模型来提高自己的研发效率呢?
如何使用大模型辅助编程?
目前常见的工具有 ChatGPT、Co-Pilot、私有化大模型等等,在不同场景下要用不同的方法来编写程序:
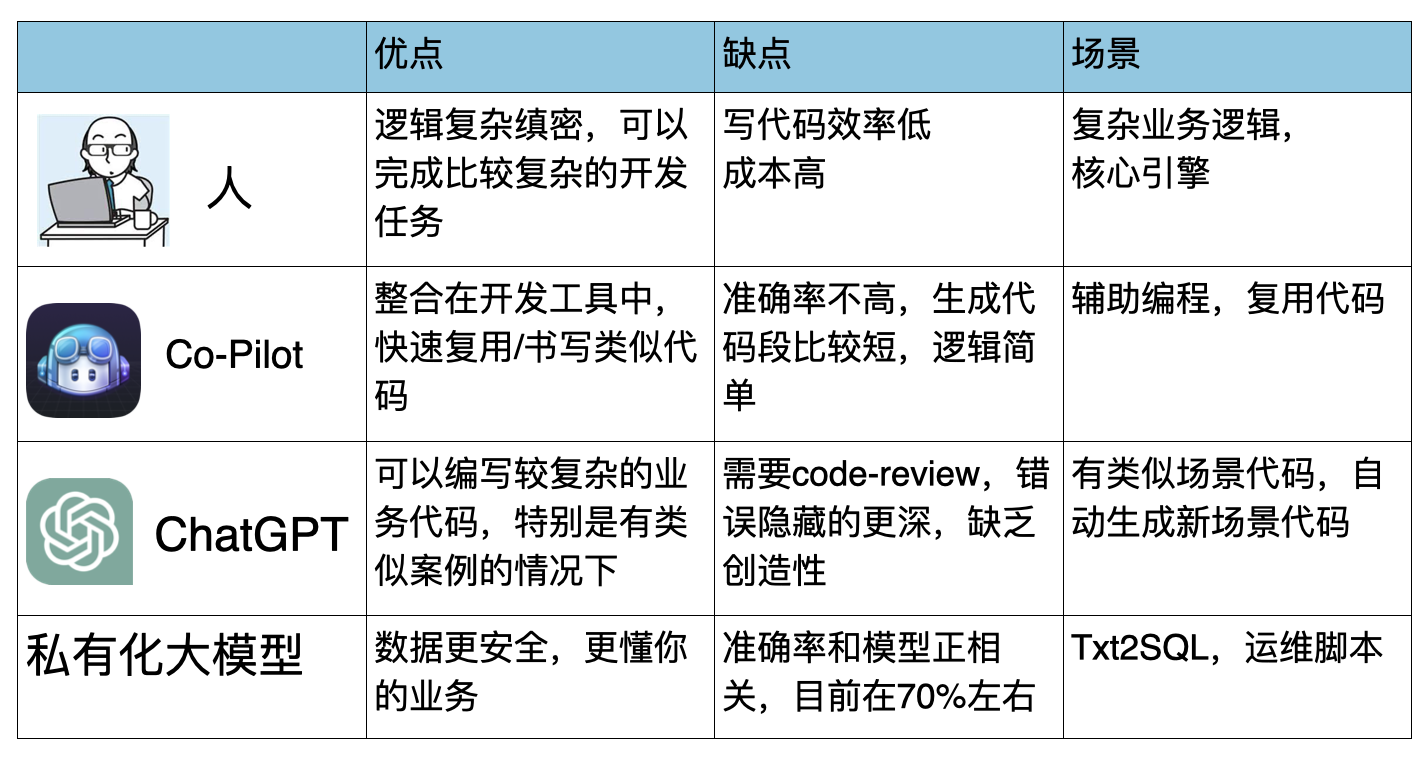
可以看到,人类其实最适合就是做比较有挑战和创新的架构类产品,或者是某个新业务场景的代码,如果中间有复用的部分或者类似的算法,可以使用 Co-Pilot 快速提升效率;ChatGPT 可以用于类似场景的代码来自动生成,稍微修改就可以使用;私有化大模型更适合对数据和代码安全有要求,而又需要大模型比较了解你的业务知识的场景,私有化大模型是需要 FineTune 的。
可能有人会说,私有化大模型普通公司玩不起的!其实这是一个误解,如果你要原生训练一个原生私有化大模型,估计中国能玩得起的公司不超过 5 个,而大多数公司不需要训练大模型,只需要根据开源大模型优化(Finetune)大模型就可以让大模型理解自己的业务了,而这个代价就是 1-2 张 3090/4090 的显卡就可以了,整个的实行过程可能也只需要 2~3 个小时的配置就可以(感兴趣的话可以参考下面这篇文章:《用一杯星巴克的钱,训练自己私有化的ChatGPT》,里面讲的利用是 Apache DolphinScheduler 和配置好的模板,拖拽就可以训练一个大模型的例子)。
使用私有化大模型可以直接实现以下功能:
软件众多功能中,直接找到你所需要的功能;
众多复杂的使用手册和规则,找到你所需要的功能和说明;
辅助编程,Txt2SQL,提高数据程序员的效率。
使用私有化大模型来辅助编程,真的距离我们一点都不遥远。如果你还不太相信 AIGC 自动化编程时代已经来临了,那么下面这个开源项目如何利用 AIGC 提高研发效率的例子,或许可以帮助你可能更好理解。
大模型自动化编程实例:Apache SeaTunel
Apache SeaTunnel 愿景是“连接万源,同步如飞”,也就是可以连接市面上所有的数据源(包括数据库、SaaS、中间件、BinLog),而且同步效率要做的最高。这对于任何一家公司都是不可能做到的事情,而面对几千上万的 SaaS 软件和不断变化的接口,甚至人类也无法做到这一点,那么 Apache SeaTunnel 核心项目团队是怎么在这个 AI 时代设计这样一款开源软件呢?总体如下图所示:
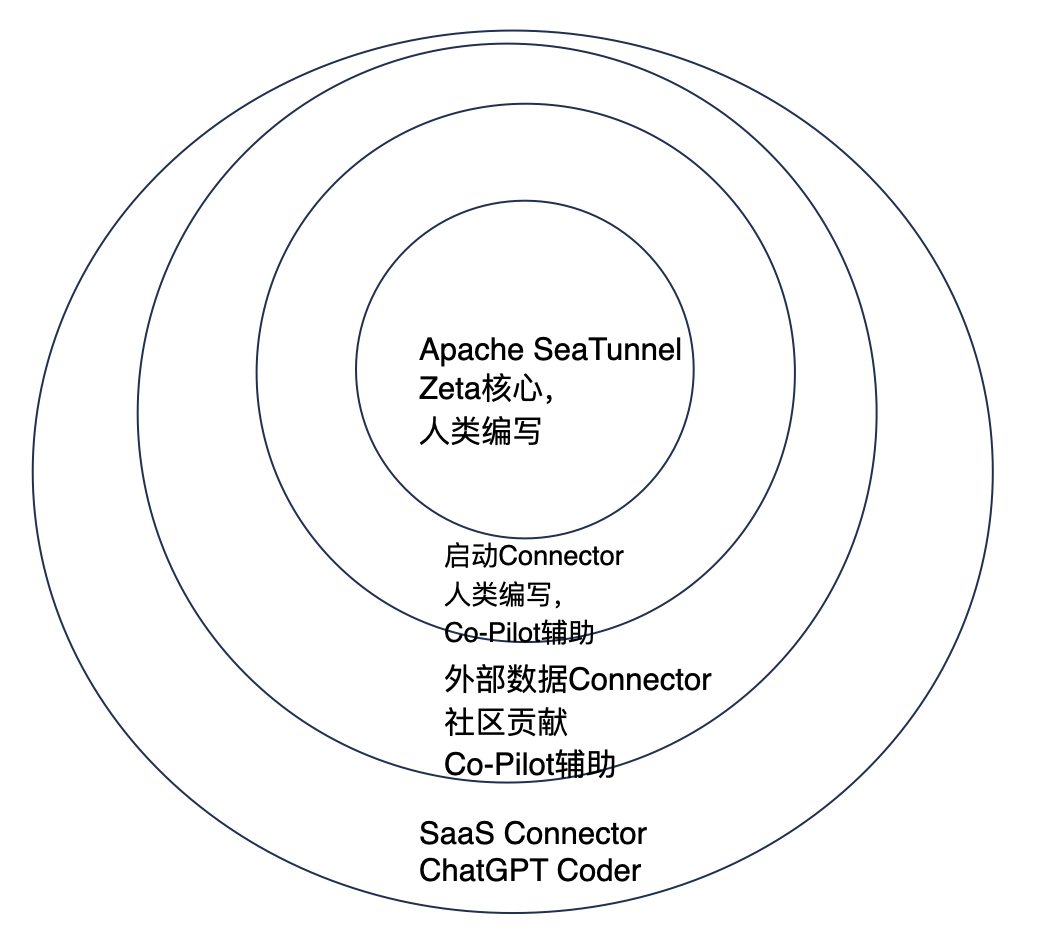
首先,计算核心引擎部分,属于专门为同步而生的计算引擎,它不同于 Flink、Spark,主要在同步复用内存、CPU、带宽和确保数据一致性上下功夫,所以大部分代码都没有可借鉴的,需要核心开发工程师直接编写、修正,以确保“同步如飞 ”。当然,因为是开源项目,核心引擎部分得到了众多大厂专家的修正和讨论,以确保时刻跟进全球最先进的技术。
其次,数据库的核心 Connector,例如 Iceberg Connector,这些接口实现比较复杂,除了保证代码正确之外还要保证数据传输效率很高,这时候直接使用大模型是无法达到我们所需要的效果的。因此主力还是人,但可以复用自己和云端过去常用的代码来做,这时候使用 Co-Pilot 就是最佳方案,主导者是人,而大模型可以作为辅助来帮你补充常规算法和复用的代码,如开头视频所示的样子。
面对浩如烟海的 SaaS 接口,例如 MarTech 领域的 SaaS 就超过 5000 个,靠人力对接接口是不可能的。SeaTunnel 核心团队就想了一个办法,根据多次尝试,把过去为人写的十几个接口进行抽象,不断和 ChatGPT 磨合,最终变成 2 个可以让 ChatGPT 理解并写出优雅代码的接口,然后利用 ChatGPT 可以读懂 SaaS 接口文档的特点,直接生成相关代码。这在 SeaTunnel 当中叫“AI Compatible”特性,兼容 AI。我理解这更是程序员和 AI 的一种“和解”,大家不要相互抢饭碗,程序员为 AI 做好准备,AI 来做程序员无法做到的事情。
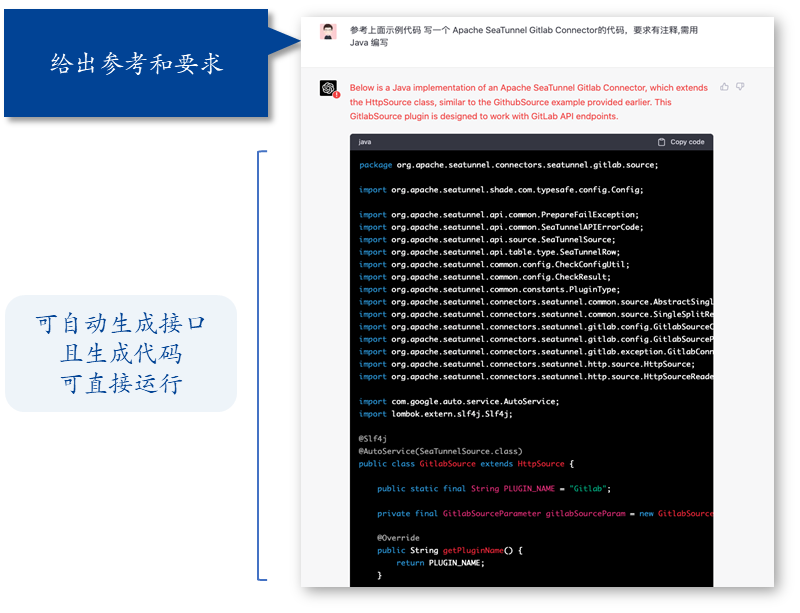
这个特性在 Apache SeaTunnel 2.3.1 里面已经发布了,当然作为众创的开源软件,该功能还有各种各样的缺陷有待提升。不过因为代码是完全开源的,我相信会有越来越多的爱好者把它打磨到更加自动化。比如,我已经听到有一个开发者要做一个 GPT Coder,监控 GitHub 上的 SaaS issue,自动化调用 ChatGPT,生成代码并提交 PR,让机器人和人类卷到极致。
大模型自动化编程存在的问题
虽然 ChatGPT、Co-Pilot 可以辅助编程,但它们也不是无敌的,目前大模型生成代码还有很多挑战:
准确率问题;
无法做 code review;
无法实现自动化测试;
无法担责。
大模型依然会出错,这在未来一段时间是常态,哪怕是 ChatGPT4,写出来的代码也就 90%的正确率,所以要尽量简化它写代码的过程,否则可能会写出来完全不对的代码。大模型快速生成代码之后,人类的 code review 会跟不上,因为机器是无法确定最终代码实现业务逻辑是不是对的;而大模型做 code review 的话,你会发现每次都给你煞有其事地提出来不同的改进点,但其实都是无关痛痒部分,无法确定最终的逻辑正确性。
同时,自动化测试案例和自动化测试也是当前大模型一个弱点,TestPilot 属于在学术圈比较活跃的内容,大家可以参考 Cornell 的《Large Language Models are Few-shot Testers: Exploring LLM-based General Bug Reproduction》和《Adaptive Test Generation Using a Large Language Model》都是一些比较有意思的文章,不过距离工程化使用都还有一定距离。
当然,自动化编程还有最后也是最难得一关——责任问题,就像自动化驾驶一样,哪怕是做到 L5,如果出问题到底是谁的责任。就像 WhaleOps 实现了 Txt2SQL 之后,很多用户问,为什么不直接把 SQL 执行出来变成最终的结果给我,这才是业务部门最终需要的东西。
我认为这是一个哲学问题,而不是一个技术问题了。不说现在 ChatGPT90%的准确率,假设将来大模型可以做到 99.9999%,你敢直接问一句话让它自动计算全公司的工资然后自动对接银行发工资么?如果出问题,你觉得是谁的问题呢?永远不能幻想用技术解决所有的业务问题,大模型也是如此。
未来展望
现在我们还处于大模型自动化编程的初期,很多小伙伴还在处于试用 Co-Pilot 和 ChatGPT 阶段,大多数程序员还没有用上私有化大模型来根据自己公司的业务提升编程效率,不过我认为未来的 3-5 年,自动化辅助编程一定会成为我们这一届开发者的标配工具:
国产基础大模型拉进 ChatGPT 距离,易用性提高;
开源大模型准确性、性能提升,更多的公司使用私有化大模型 ROI 提升;
大模型自动化门槛减低,除了 DolphinScheduler,更多的大模型训练平民化工具诞生;
技术管理者对于大模型自动化编程认知提升,技术管理流程适配大模型时代;
在当前经济周期下,降本提效利用大模型提高效率势在必行。
所以,未来几年,如果你在研发过程还是只会 CRUD,不会有效利用大模型将自己的经验和业务理解 X10 或者 X100 的话,那么不用等到 35 岁,你就会被会大模型编程的那批程序员所取代,他们 X10 之后,你就是那被淘汰的 9 个人。
当然,虽然有点危言耸听,但是编程提效当中的大模型趋势是势不可挡的,我也只是在大模型自动化编程这方面不断实践摸索的小学生,我相信会有很多的技术管理者和架构师加入到大模型自动化编程的浪潮中来,不断迭代和优化在开发领域当中人和大模型之间的关系。最终,让程序员、AI、技术研发流程更有效的为业务服务。
作者介绍
郭炜,人称“郭大侠”,Apache Foundation Member,Apache DolphinScheduler PMC,Apache IPMC Member,ClickHouse 中国开源社区发起人和首席布道师。中国软件行业协会智能应用服务分会副主任委员,TGO 北京董事会会长,全球中小企业创业联合会副会长,人民大学大数据商业分析研究中心客座研究员。郭大侠一直致力于让“数据能力平民化”的事业上,本人参与多个开源项目,促进多个开源社区在中国的落地以及中国开源项目在全球的发展,被评为 Apache Foundation Member 和 2021 年中国开源最佳人物之一。




