
一、什么是端智能?
AI 技术现在已经覆盖到了互联网的方方面面,在云端的应用已经非常广泛和成熟。为了追随人工智能的浪潮,各大厂商也在不断加强移动设备的 AI 能力,主要体现在以下方面:
通过专门为 AI 能力定制的 Soc,提供更好的计算能力
轻量级推理引擎技术的成熟(例如:TensorFlow Lite),对算力有限的移动设备更加友好
模型压缩技术使得模型体积大大降低,使得其部署在移动设备上成为了可能
经过这几年的飞速发展,在终端部署 AI 能力渐渐步入了大众的视野,端智能的概念应运而生,旨在提供在终端设备上使用 AI 能力的完整框架。相比云端,端智能具备以下优势:
低延迟:节省了网络请求的延迟
安全性:更好的保护用户隐私数据
定制化:根据用户习惯进行本地训练,逐步迭代优化,真正做到用户定制
更丰富的特征:可获取更加丰富的用户特征,提高预测的准确率
节约云端资源:与云端推理结合,在终端进行预处理,从而降低对云端算力的压力
更丰富的使用场景:人脸识别、手势识别、翻译、兴趣预测、图像搜索等智能场景已被广泛使用,更多的应用场景也在不断涌现。
在端智能的应用方面,Google、Facebook、Apple 等巨头已经走在了前列。Google 提出了 Recommendation Android App 的概念,根据用户兴趣进行内容推荐。Apple 的 Face ID、Siri 推荐也都是端智能应用的代表。
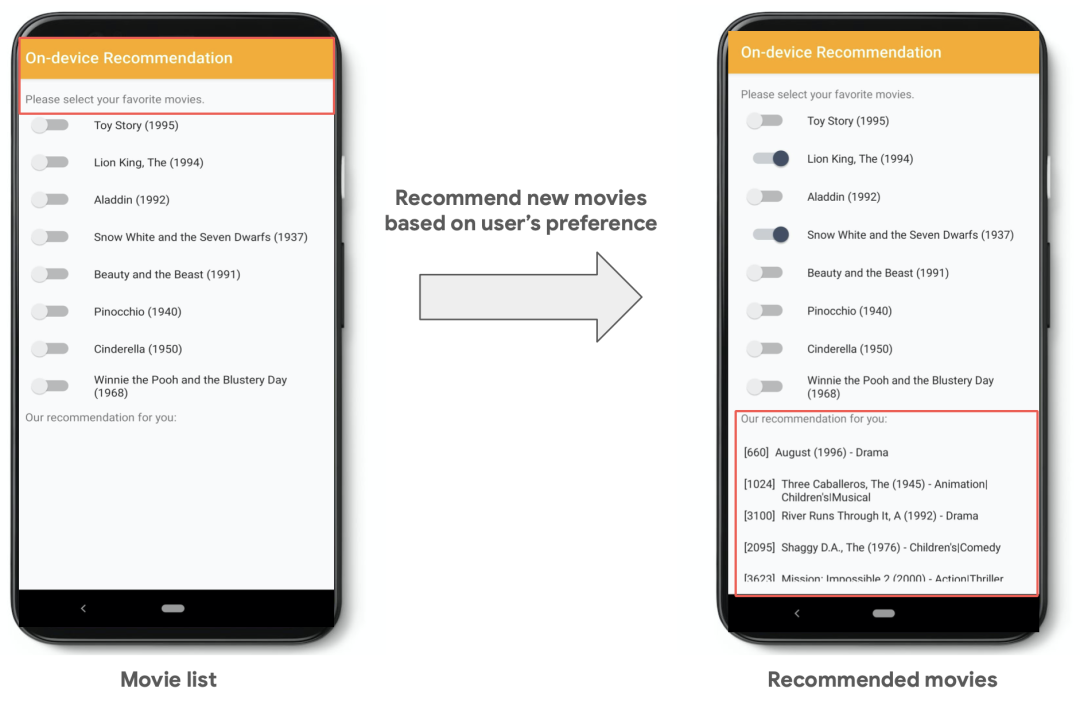
图 1-1 Recommendation Android App
在国内,阿里、腾讯等企业也先后进行了端智能的尝试。阿里在手淘中宝贝列表重排、智能刷新、跳失点预测、智能 Push、拍立淘(以图搜图)等多个场景实现了端智能的落地,并推出了 MNN 神经网络深度学习框架。腾讯则推出自研的 NCNN 框架,并在医疗、翻译、游戏、智能音箱等领域广泛应用端智能技术。
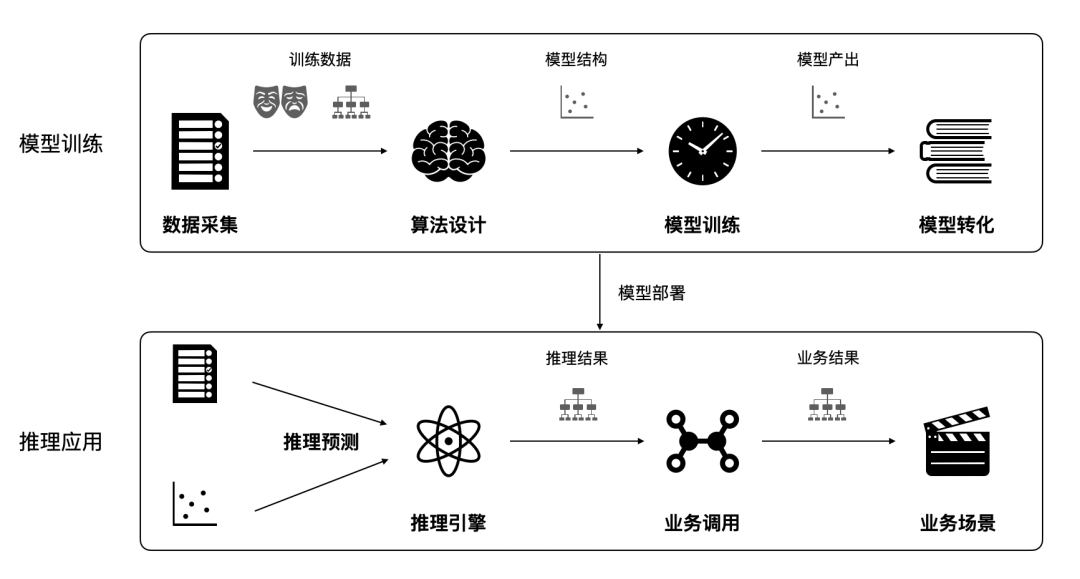
图 1-2 典型端智能开发流程示意图
一个典型的端智能开发流程如图 1-2 所示。首先在云端利用收集的数据进行算法设计和模型训练,并输出模型。此时的模型并不适用于移动设备,需通过模型转换和压缩转换为移动端推理引擎所支持的格式。最后通过云端配置,将算法和模型动态部署到目标设备上。在终端设备上,在合适的使用场景和时机触发推理流程,根据模型进行输入数据的整理并传递至推理引擎,获取并解析推理结果后进行相应的逻辑调整和反馈。
二、端智能面临的挑战
在移动设备部署端智能并非易事,现阶段的开发流程存在诸多的问题需要我们一一解决。
开发效率
按照典型的端智能开发流程,首先需要算法工程师在云端训练和输出模型,模型决定了数据的输入、输出格式。下一阶段,客户端工程师需进行端侧的开发来适配当前模型,包括输入数据的收集和整理、输出数据的解析等。开发完毕后,再交由测试工程师进行后续的质量保障。这期间需要多个角色的协同和沟通,整体开发链路冗长且低效。
灵活性
正如上面所提到的,一旦模型确定后,其输入输出就遵循固定的格式。如果模型想调整输入数据的策略,就一定要同时修改客户端逻辑。因此,线上验证与功能迭代的灵活性受到了极大的限制,无形中拉长了整个功能上线周期。此外,不同端智能应用场景(CV、推荐等)也存在着较大的需求差异,如何满足不同的业务场景需求也是需要解决的头部问题。
端上环境复杂性
构建一套完整的端智能运行环境并非易事,除了在云端进行模型的训练和下发,还需要在客户端进行数据的收集、存储、处理,硬件资源的评估与调度,推理引擎的选择,操作系统的兼容,推理任务的管理与调度等等。这些问题无形之中提高了端智能应用的门槛,如何能够屏蔽这些复杂的端上环境也是端智能目前面临重要挑战。
三、Pitaya 端智能一体化解决方案
为了解决上面的问题,Pitaya 与 MLX 团队进行了深度合作,共建了一套从端(云端)到端(终端)的全链路动态部署方案。MLX 是云端的模型训练开发平台,提供模型训练、转化、调试、发布、A/B 等能力。客户端 Pitaya SDK 则提供特征工程、推理引擎、算法包管理、任务管理、监控等端上能力。两者深度整合,覆盖了端智能流程的各个环节,大大降低端智能的应用门槛。
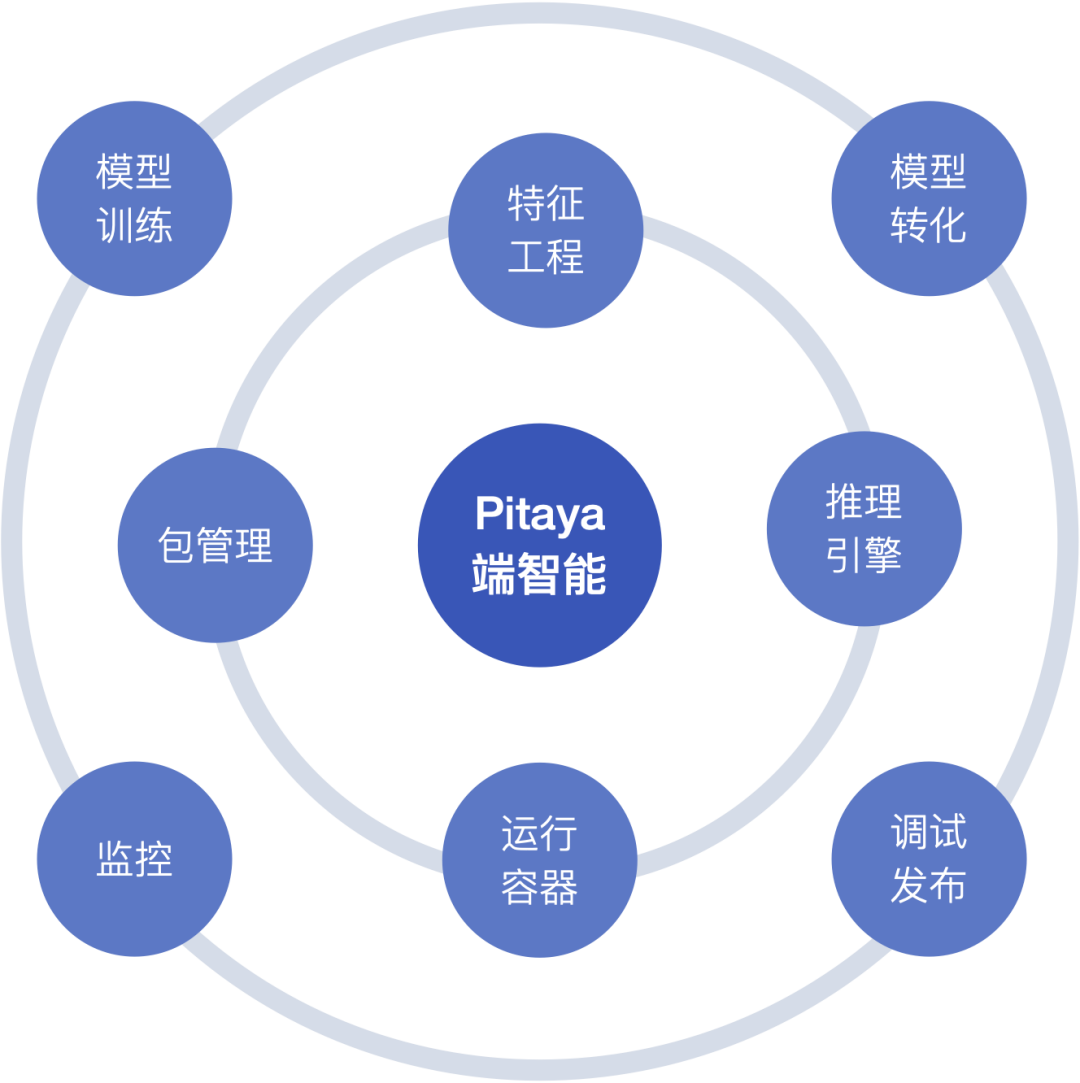
Pitaya-MLX 深度能力融合
1. MLX 平台
在介绍 Pitaya 前,先着重介绍一下 MLX 平台。在进行模型训练的过程中,我们会碰到很多的环境差异,比如不同的数据源的存储方结构、数据格式,不同的机器学习框架,以及不同操作系统环境和基础设施能力的搭建。MLX 平台就是为了解决上面的问题而诞生的。它提供了一个在云端实现模型训练、转换并将其最终产品化的服务平台,通过广泛接入了各类计算框架和服务平台,省去了复杂的环境搭建工作。
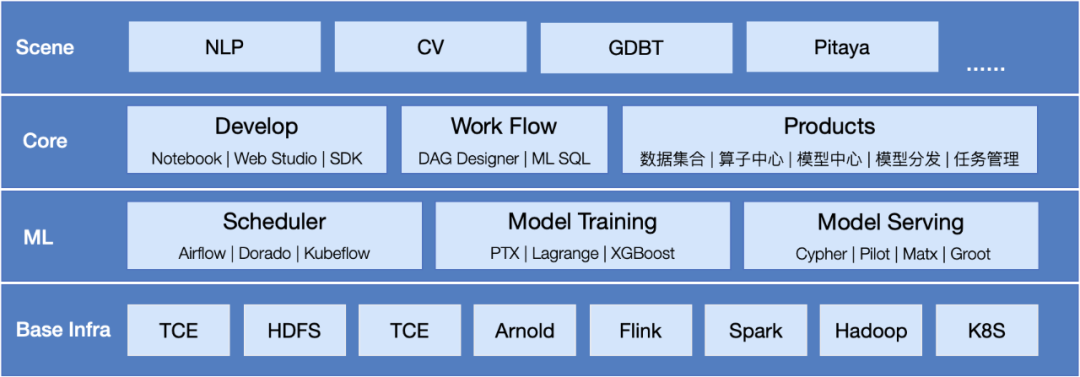
图 3-1-1 MLX 架构示意图
MLX 的架构如图 3-1-1 所示:
Base Infra:提供了诸多基础设施能力支撑上层功能。
ML:提供对各类机器学习框架的支持,主要分为 Scheduler、Model Training、Model Serving 三部分,是模型训练和转换的核心能力。
Core:开发人员直接接触的主要功能,在算法开发环节 MLX 提供 Notebook、Web Studio 等在线 IDE 编辑环境,支持 DAG Designer 的拖拽模式的工作流控制,更加简单易用。在模型产品化的流程中,覆盖了训练、任务管理、导出、发布等整个链路环节。
Scene:在以上基础能力的支撑下,MLX 平台上可以搭建不同的智能场景任务,例如:NLP、CV、GDBT,而 Pitaya 就是其中的新成员。
2. Pitaya
2.1 算法包
Pitaya 将自身的工作流与 MLX 平台特性进行了深度的整合,如下图所示。在传统的端智能开发流程中,云端仅负责模型的输出,能够动态部署下模型。而在 Pitaya 工作流中,“算法包”是一个完整资源的集合。“算法包”包括推理过程中使用到的模型,也包括算法逻辑及其依赖库信息,这些所有的内容被统一打包成为“算法包”。如果客户端同步了算法包内容,且具备算法包运行所需的各项能力,那么就可以在运行该算法包,实现一个完整的推理流程。
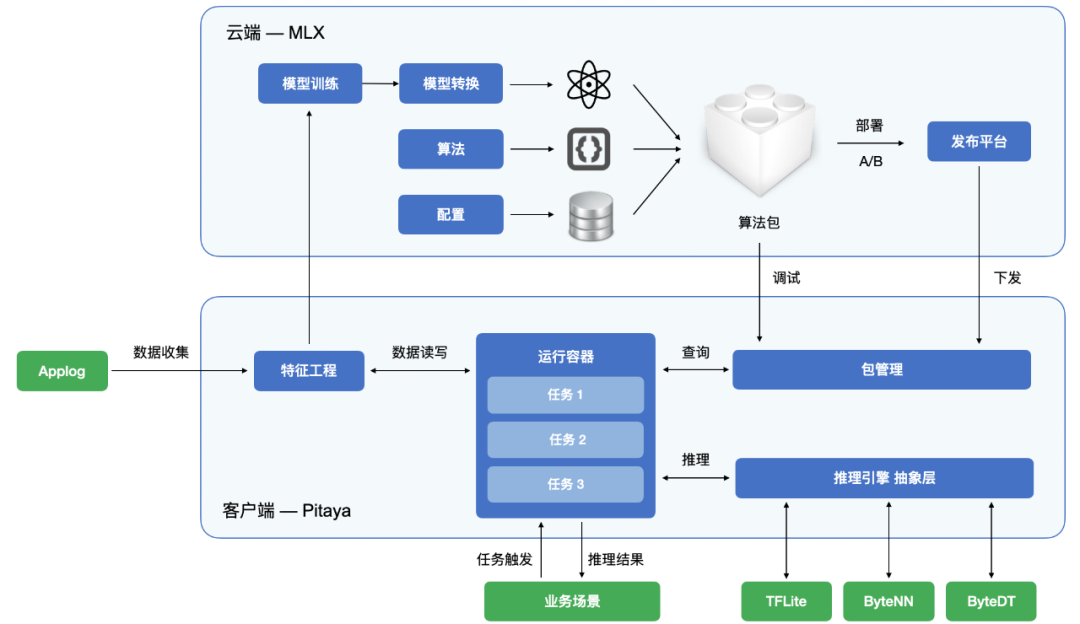
图 3-2-1 Pitaya 与 MLX 协同工作示意图
2.2 开发与调试
算法包的开发过程中,可以临时生成测试算法包。通过扫码将宿主 App 与 Pitaya-MLX 平台建立数据通道,推送测试算法包到客户端,通过真机运行和调试算法包,输出的日志信息也会在 MLX 的 IDE 环境展示,从而实现云端调试的完整体验。得益于 Pitaya 与 MLX 深度融合,算法工程师不再依赖客户端工程师进行任何开发,就可以独立完成算法在端上的运行与调试,极大的提升了算法开发的效率。
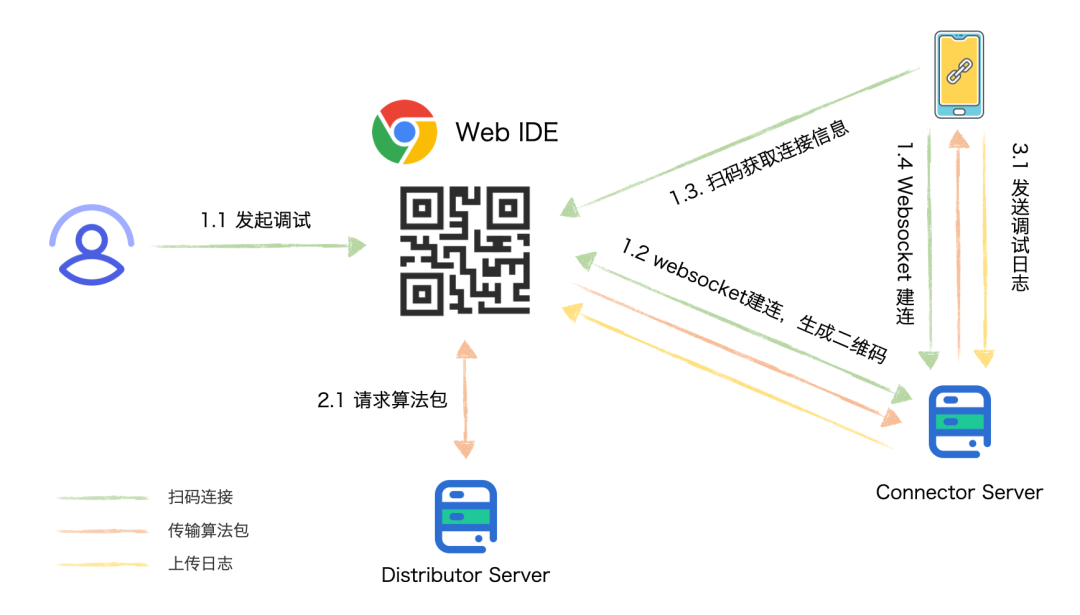
图 3-2-2 Pitaya-MLX 平台调试流程示意图
2.3 动态部署
当算法工程师完成算法包的调试后就可以将当前项目打包成一个算法包。每个业务场景都有一个当前 App 下的唯一 Business 标识,算法包与 Business 绑定。在 Pitaya-MLX 发布平台可针对某一 Business 业务,从 App、App 版本、OS 版本、渠道等多个维度对算法包的下发进行配置与管理。发布平台还与 A/B 平台实现了数据打通,可以实现无缝的线上实验对比,大大加快业务线上效果的验证。
除了上面提到的常规配置能力,Pitaya-MLX 发布平台还支持对当前设备机型进行性能打分,根据打分的结果来进行算法包的差异化下发。这种部署方式可以更加细粒度的对线上设备性能进行划分,针对高性能或支持某些 AI 加速的设备下发精度更高的模型,而针对性能较弱的设备为了追求更好的使用体验,则部署相对精简的模型。
2.4 特征工程
Pitaya 中一个核心能力就是“特征工程”。端上推理一般需要从原始数据生成输入到模型中的特征,再由模型推理得到结果。如果需要业务方自行收集和保存原始数据,其工作量是巨大的。特征工程的作用就是帮助业务方无侵入式的收集端上的用户特征数据,用于后续的推理预测。Pitaya 特征工程与 Applog SDK(事件统计 SDK)打通,支持在算法包中对推理过程中需要使用到的的 Applog Event 进行配置,当算法包在本地生效时,Pitaya 就可以根据算法包的配置收集数据。同时,Pitaya 也提供定制化的接口,用于关联用户行为上下文,例如:点击、曝光、滑动等。在算法包运行过程中,可以通过特征工程的能力获取用户的原始数据,通过数据的处理生成模型需要的输入数据。这种数据收集的方式较传统链路具备更好的动态性和灵活性,让业务方从繁重的数据处理工作中解放了出来。
此外,特征工程还支持上传指定的数据至 MLX 平台,用于云端的模型训练,形成一个完整的数据闭环,如图 3-2-1。
2.5 算法包的运行
当一个算法包同步到了终端设备后,触发算法包的运行可以有两种方式。
Applog Event 触发:通过算法包配置可以触发运行的 Applog Event,当有监控到有对应 Applog Event 事件时,则会间接触发该算法包的运行。该触发方式是提供给业务方一个通过 Applog Event 触发算法包执行的时机,可在算法包中进行特征数据的提取与预处理等操作。
主动触发:业务方在合适的场景和时机下主动调用 Pitaya 的接口(下图所示为 Objective-C 上的调用接口),可自定义输入数据和任务配置,在回调中获取推理结果。
- (void)runBusiness:(NSString *)business input:(PTYInput *_Nullable)input config:(PTYTaskConfig *_Nullable)config taskCallback:(PTYTaskCallback _Nullable)taskCallback;每触发一个算法包的运行实际上就相当于创建了一个任务(Task),Pitaya 内部的任务管理模块会对任务进行统一的接管与处理。算法包是在 Pitaya 的运行容器中执行的,该容器为每一个任务提供独立的运行环境,并通过 Pitaya 提供的接口来进行特征工程数据的存取和模型推理等。Pitaya 对推理流程和接口进行了高度的抽象,支持不同类型的推理引擎的集成(ByteNN、ByteDT、TFLite),最大程度上的满足了不同业务方的使用需求,降低项目迁移到 Pitaya 框架的成本。
2.6 任务监控
为了实现一键集成的使用体验,Pitaya 内部打造了一套对任务进行全面、细致的监控体系。监控内容涵盖以下几个方面:
指标监控:任务 PV/UV、成功/失败、算法包下载成功率/覆盖率
性能监控:内存、各个链路阶段耗时、初始化耗时
异常监控:任务卡死、失败原因、网络请求失败
Pitaya SDK 将以上指标进行了分类整理,依托于 Slardar 平台的数据展现能力,每个集成业务方都可以一键复制模板,在宿主 App 内建立完善的数据看板,真正做到开箱即用。
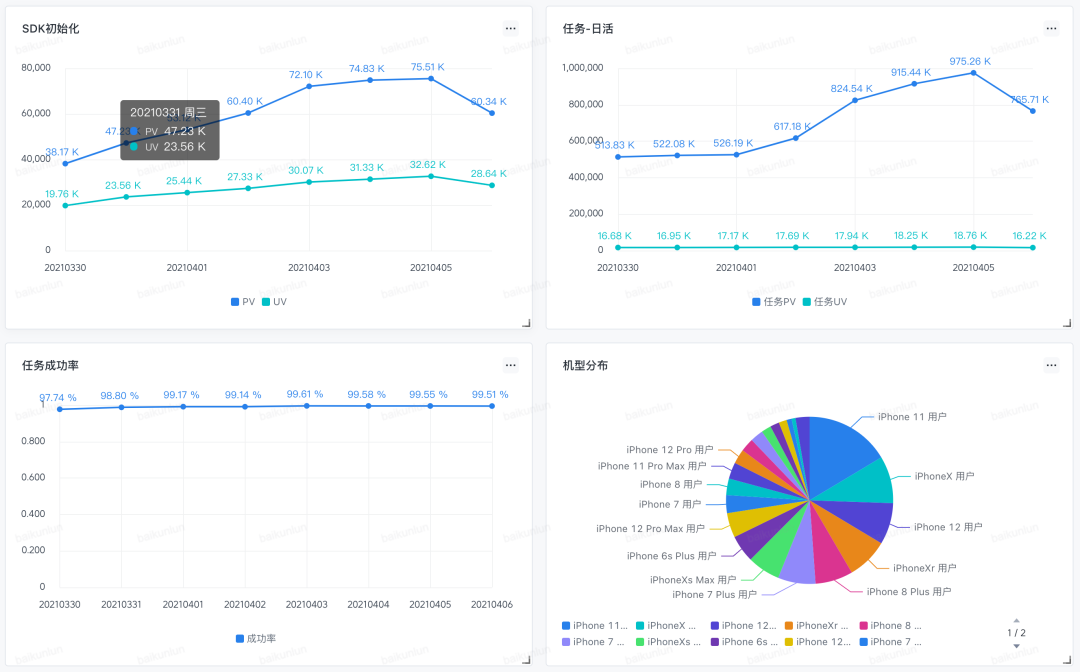
图 3-2-3 Pitaya 监控数据示意图
四、总结与展望
Pitaya 是专门为移动端打造的端智能一体化方案,与传统方案相比,具备以下优势:
降低了端智能使用成本,方便业务快速集成,拿到业务收益
完善的动态化能力,支持模型的快速迭代与效果验证
提升多方协作的效率,让算法工程师深入参与客户端场景中
算法、模型高度复用,可以快速推广已经验证的方案
目前,字节跳动内已经有抖音、头条、西瓜等众多产品线基于 Pitaya 开始了端智能的实践和探索,在此过程中我们也与业务方持续沟通,不断打磨产品和使用体验,并对未来 Pitaya 的发展方向进行如下规划:
特征工程:强化特征工程能力,充分利用端侧特有信息,结合云端数据,提供更加丰富和准确的数据。
模型自衍化:端智能的最大使用场景就是根据用户自身的行为特征进行不断的学习,从而更加符合使用者的习惯。为了达到这种效果,需要解决本地训练数据、模型本地训练的问题,以及建立一套对模型准确率评估和回退的管理机制。
通用 AI 能力建设:针对通用性的使用场景(网络状态预测等),Pitaya 可内置相关能力,快速推广至业务方。
本文转载自:字节跳动技术团队(ID:BytedanceTechBlog)




