
采访嘉宾 | 李翔
编辑 | Tina
自去年年底 ChatGPT 掀起一轮 AIGC 热潮以来,国内外科技企业扎堆发布大模型,大佬也纷纷为自家大模型站台,甚至不惜掀起“口水战”。我们不可否认大模型优化了人类与机器交互方式,是效率的革命,然而作为开发者,我们更关心的是如何让大模型深入落地,在更多场景中把大模型的能力真正用起来。
现阶段这种实践经验尤为宝贵,但好在如何落地也是惟客数据的关注焦点,自 ChatGPT 出现后,惟客数据就开始了探索,并将之应用到了内部开发人员使用的场景,以及给已有产品赋能的场景中。应用新技术有哪些门道,我们为此采访了惟客数据 AI 算法专家李翔博士,他从模型选择、应用搭建、提示工程、实践效果等多方面进行了解答。
InfoQ:在大数据领域,目前 LLM 大语言模型能做哪些工作?LLM 和 GPT 之间的区别是什么?它们跟以前的 NLP 有哪些不同?
李翔:LLM 是大规模语言模型的统称,GPT 是其中的一种,两个都属于 NLP 领域,可以简单理解成为 NLP 包含 LLM、LLM 包含 GPT,当然 ChatGPT 这种又不是传统的 NLP,已经有一点 AGI 的雏形了,它涌现的能力主要体现在两块儿:一个是理解能力;一个是逻辑推理能力。比如通过理解人通过自然语言描述的需求,结合上下文信息去做合适的逻辑推理,生成人想要的内容,包括文案、代码等。
InfoQ:您们是什么时候开始决定将 GPT 这样的大模型融入业务?您们是如何选择模型的,基于什么原因,当前模型跟 ChatGPT 的区别主要是什么?
李翔:从去年 ChatGPT 一上线就开始关注了,当时的直接感觉就是“惊艳”,觉得所有的交互方式都可以也值得被重写,无论是提高软件的使用效率,还是降低人对软件产品的学习成本,可以在各种场景大幅度提高效率。
之前的大模型,无论是 OpenAI 的 GPT3,还是其他大厂的大模型,比如 Google 的 Palm(5400 亿参数),还有国内盘古或者悟道,都达不到 ChatGPT 的理解和推理能力,所以在那个时间点并没有其他的选择。之后有了 Google 的 Bard,百度的文心一言,还有 OpenAI 前团队的 Claude 这些跟随者。另外,还有一条开源的路线,比如基于 Meta 无意“泄露”的 LLaMA,衍生出了一系列的开源平替 Alpaca、BELLE 等。这些都会做为底层模型能力,接入到我们的 WakeMind 平台中来,我们还联合业界领先的千亿参数多模态预训练大模型厂商,通过知识蒸馏和动态量化,压缩出 100 亿参数量的 WakeMind 模型。不同的模型有各自的优劣,需要结合场景去挑选最合适的,比如在数据隐私极其敏感的场景,例如销售和客户的会话数据,就需要私有化部署的模型去提供对应的服务。
InfoQ:在这些场景中,该模型存在什么优势?是否存在对准确性和可靠性的担忧?
李翔:如上面所说,我们不会局限于某个单独的模型,而是通过 WakeMind 把这些模型都接入管理起来,作为底层的服务,提供给不同的场景和业务去用。
通常来说,一个新的技术出现时并不可靠,时灵时不灵,要将这样的技术转化成产品,需要足够的耐心和智慧,克服一个又一个困难,走完从 1 到 N 的漫长路程。
准确性决定了其服务的可靠性,和模型打交道也是一种学问,所以才会有 prompt engineer 这个说法,好的 prompt 可以回答的明显很准确,除此之外,还有其他的方式,比如大模型就有一个重要的参数“温度”,可以通过设置这个值去限定模型回答问题的发散程度,再比如 langChain 里的 prompt 模板里也明确了“必须基于给定的上下文去做理解和推理”,有很多的方法可以用来大幅度降低其回答跑偏的概率,这些都需要尝试,用实际落地的经验将这个准确率提高,为了把 prompt 和 langChain 管理起来,我们打造了 WakeMind,去把这些经验沉淀到我们的母舰平台上去。
InfoQ:您们是如何在工作环境中使用大模型的?在落地过程中,您们遇到的最大挑战是什么?
李翔:我们的应用分两个场景,一个是内部开发人员使用的场景,一个是给已有产品赋能的场景。最大的挑战就是,每次碰到一个新的场景,都需要不同的人去把模型的接入和 prompt 的调试的过程趟一遍,大量的重复劳动以及经验没法传承的浪费,所以我们就想把这些重复性的过程通过一个平台管理起来。基于 WakeMind 平台去使用,针对某个具体的应用场景,会建立一个新的项目进行管理,并在这个项目中新增对应的 prompt。新增的同时,可以在平台提供的 playground 中对 prompt 进行调试后保存。如果上下文的长度超过了模型对 token 数量的限制,就通过新增 langChain 的方式对提供的超长材料进行 embedding 映射,并建立对应向量检索的预处理。最后通过接口发布的方式把这个场景的服务开放出来,给到不同场景的人去用。
InfoQ:用于数据分析和商业智能的 AIGC,针对不同场景是否需要不同训练数据(以及使用数据进行模型微调的步骤)?怎么保证效果更好?
李翔:有些场景是需要结合具体情况去做微调的,但不是所有的场景都需要,因为像 ChatGPT 这类大模型,最强的就是其通用的理解和推理能力,对于垂类场景的问题,可以通过 langChain 的方式把相关的上下文内容和问题一起包装成一个合适的 prompt,就已经可以达到一个不错的效果,解决很多场景的问题了。但对于有些场景来说,如果对准确率有更高的要求,那就需要结合数据进行进一步的微调,但这个对微调的要求很高,因为让大模型收敛是一件非常有难度的事情,如果过程没有控制好,甚至会起到不增反降的效果。
InfoQ:该模型在客户支持、潜在客户生成和数据分析等方面的效果如何?
李翔:客户支持方面,直接的应用就是智能客服,可以大幅度降低生成智能客服的成本,不需要像传统方式对垂直场景进行训练建模调优的流程。
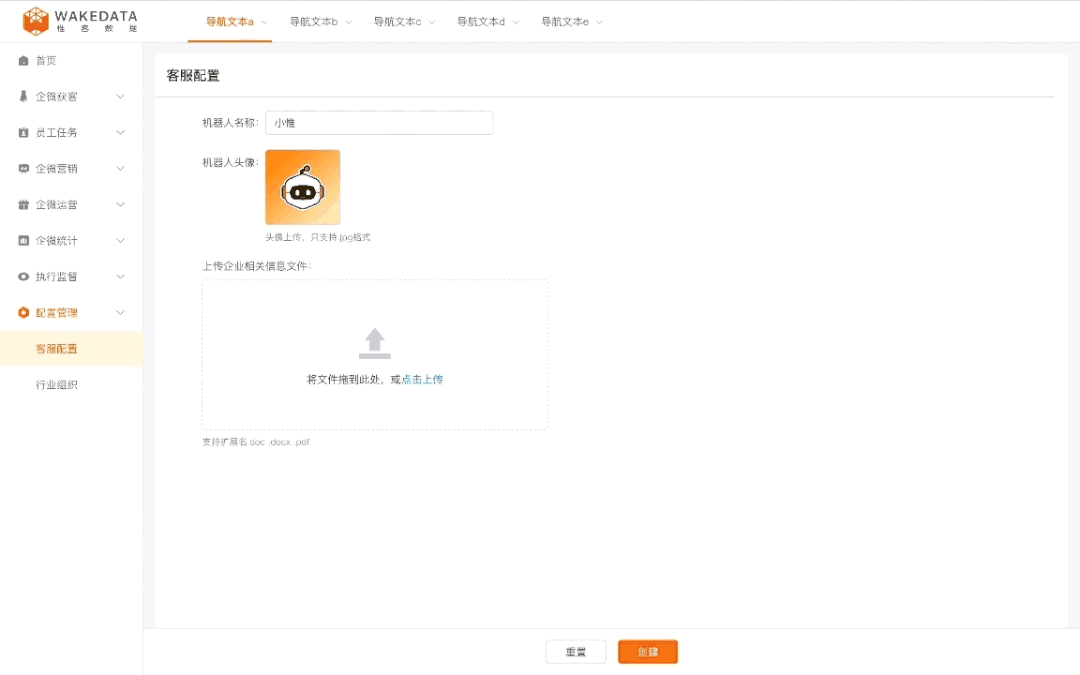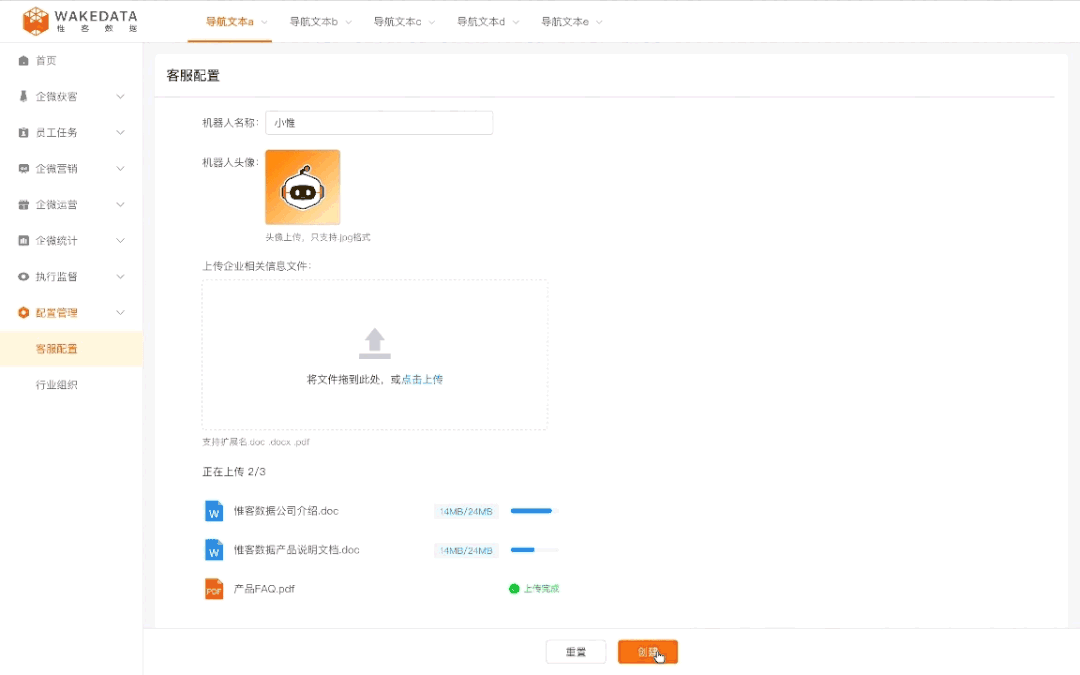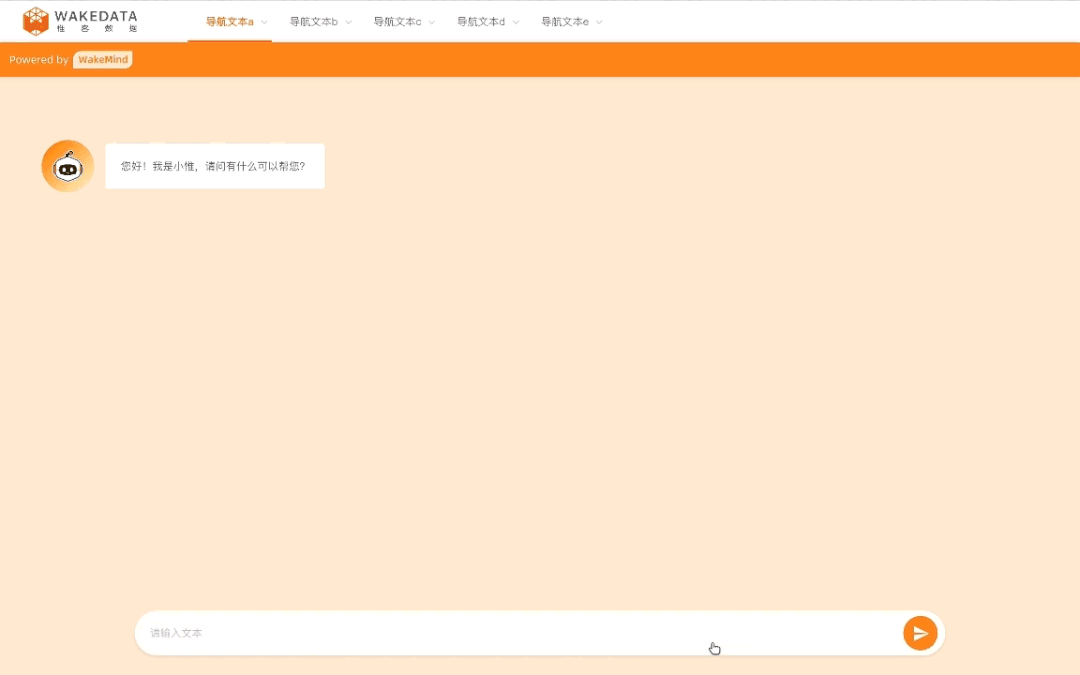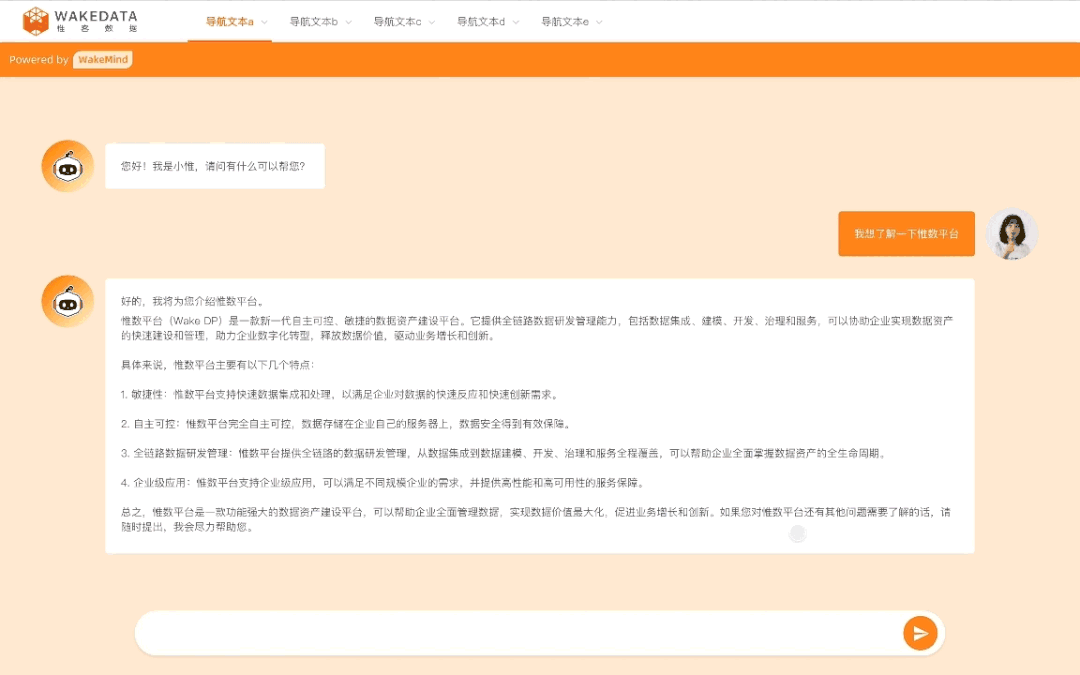
潜在客户分析和运营方面,也可以提高运营对人群的理解,从而提高运营投放的效率以及效果。
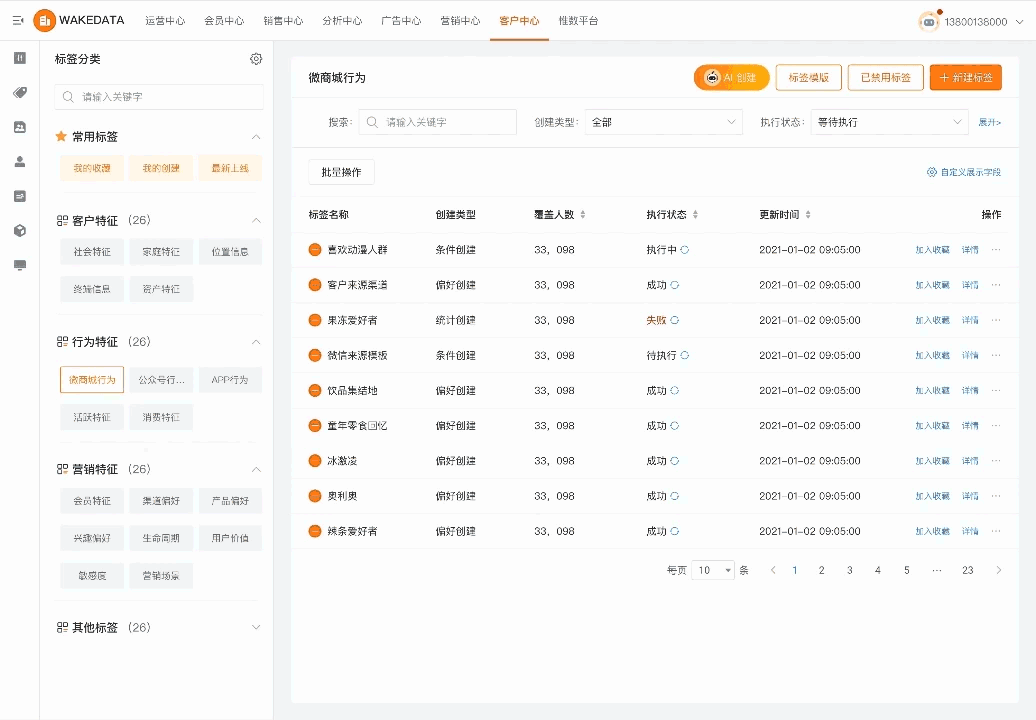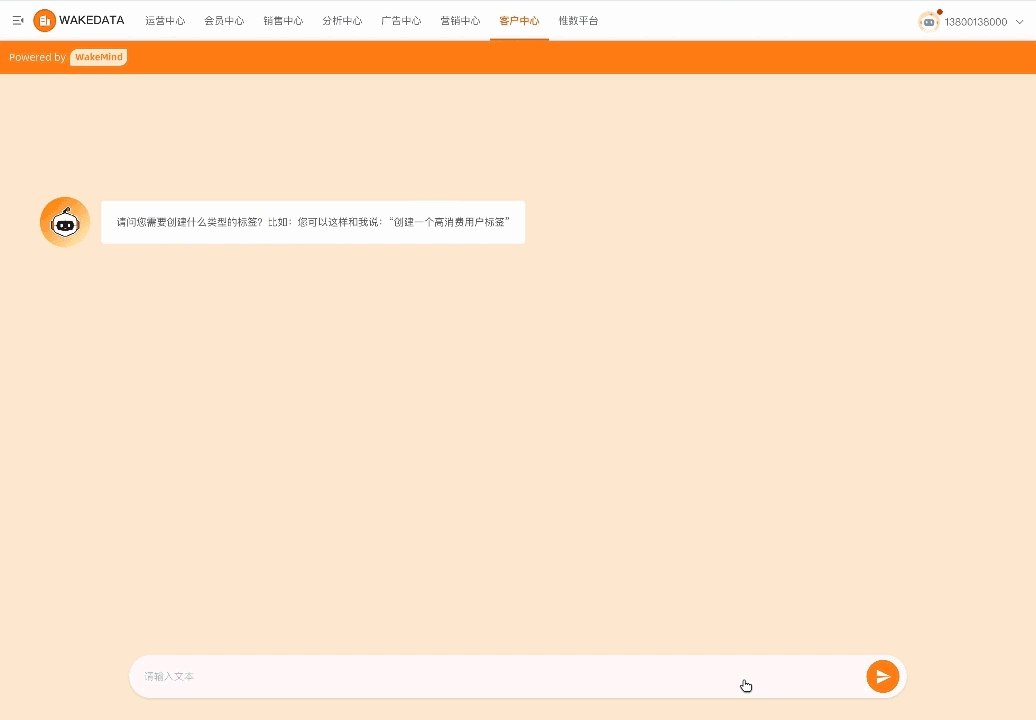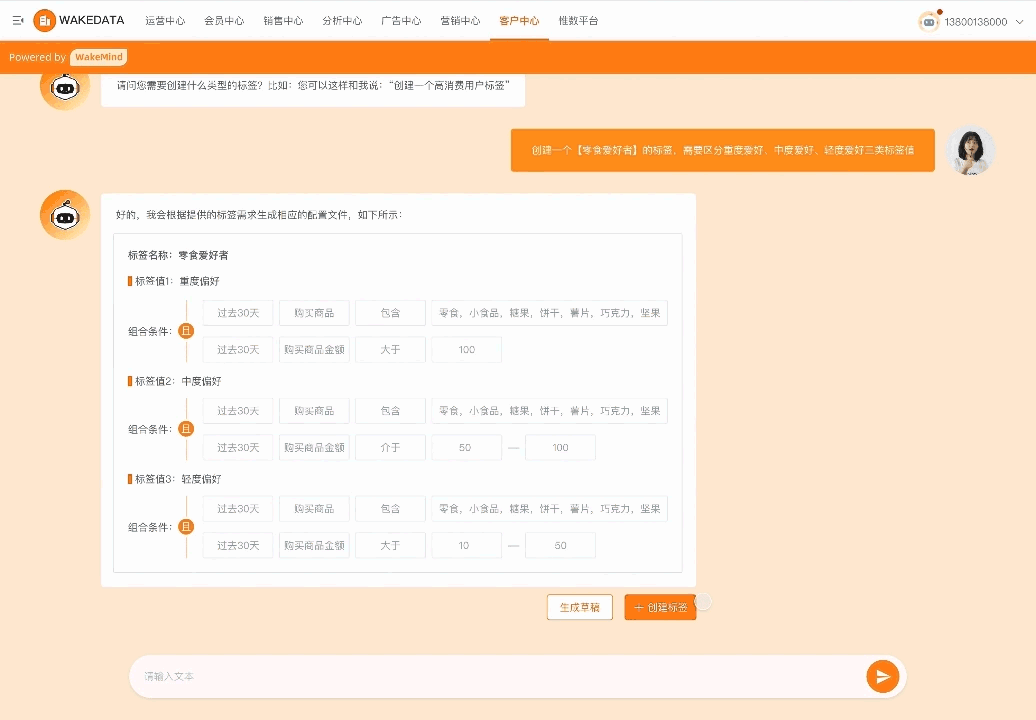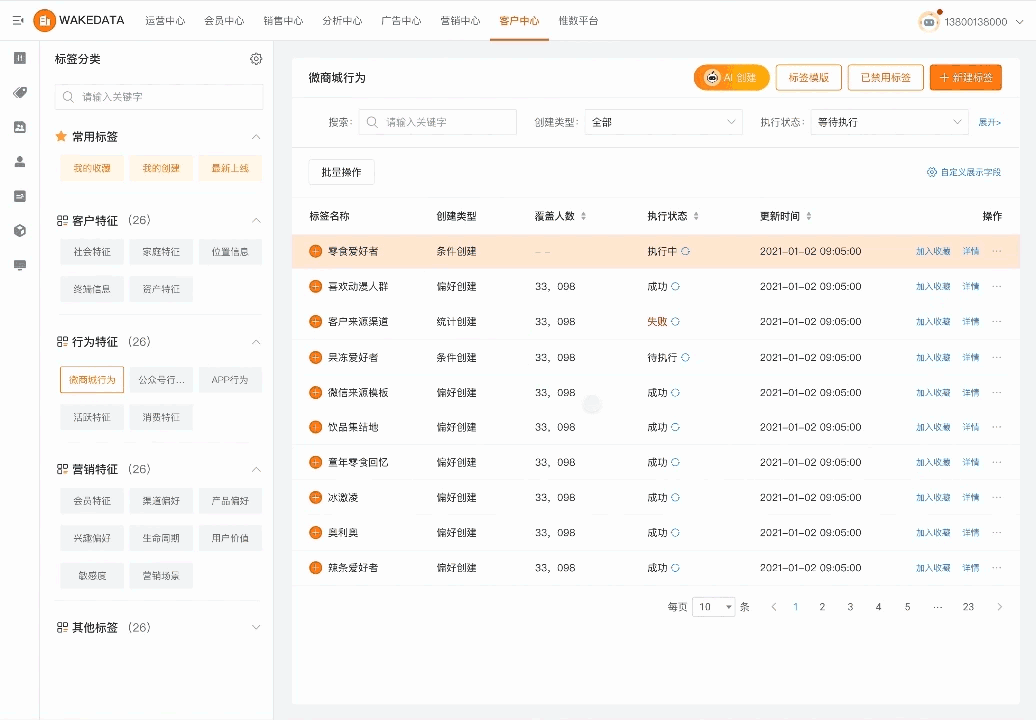
数据分析的价值点主要在两个,一个是可以提供一些新的分析角度和建议,毕竟人的想象力是有限的;另外一个就是提高分析过程的效率,比如通过 textToSQL 以及 SQL 优化等方式。
InfoQ:是否可以估算下使用 “GPT”模型的相关成本?对比成本,您们如何看待它的价值?
李翔:ChatGPT 刚出来时,还是比较贵的,但今年 2 月份通过他们的优化已经大幅度降低了使用成本,而且按 token 数量进行收费的方式也是比较合理的,这个价格是公开的。从目前各个场景对 token 数量的消耗来看,这个成本完全是可以商用的。另外,最近还有一些新的技术比如 GPTCache,通过重复使用的方式去降低这个消耗。
InfoQ:使用“GPT”模型能写出比数据分析师更好的 SQL 吗?
李翔:使用大模型能够生成高质量的 SQL 查询语句,但是否比分析师的 SQL 更好,这取决于具体情况。
大模型生成的 SQL 查询语句通常是准确的、高效的,并且可以处理大量的数据,因为大模型已经学习了大规模的数据,并从中发现了一些数据之间的关系和特征。而人类分析师则需要花费更多的时间和精力在 SQL 查询语句的编写上,同时也需要具备一定的 SQL 编程技能和经验;
大模型也可能存在一些误差和偏差,需要进行监督和调整才能达到最佳的效果。而人类分析师则具有更好的判断力和经验,能够处理一些特殊情况和异常情况,并且能够从数据中发现一些潜在的规律和趋势;
大模型在理解模糊或不清晰的需求方面可能存在困难。人类数据分析师可以通过与其他人沟通来澄清需求。
在实际应用中,我们可以结合二者的优势,发挥它们的作用,来实现更高效、更准确的数据分析。
InfoQ:您认为会对哪些岗位造成影响?AIGC 会让数据分析师失业吗?为什么?
李翔:从现在的应用效果来看,代码编写者、包括 ETL 这类型的工程师,也包括数据分析师,都可以通过大模型提高自己的工作效率,这些是已经可见的现象。而且随着使用的熟练度以及大模型本身的进化,这个效率会提高的越来越多,如果一个人就可以做以前要十个人才能做的事情,同时市场上又没有出现更多的需求,那之后大概率市场上对这些岗位的需求会逐渐下降。
InfoQ:有人认为 AIGC 对数据库 / 大数据产品的改进可能只占其所有功能 / 亮点的 1%,还有剩下的很多考量因素对于客户来说更加关键,您怎么看?
李翔:保持中立。像上面说的,大模型改变的是和产品的交互方式,提高了使用软件的效率。同时我们一直举例说现在是“iPhone 时刻”,iPhone 对手机操作体验的改变就是质变,其他产品会不会是质变呢?举个例子,假设所有的业务人员,都可以直接通过问询的方式和大数据产品进行直接沟通,通过简单交互就可以快速获得自己想看的数据,同时还能提供很多基于数据的推理和建议,让人对自己的业务有更深层次的、不同的理解,那会不会让业务做得更好呢?这种是不是也算一种质变呢?需要让时间来回答和证明。
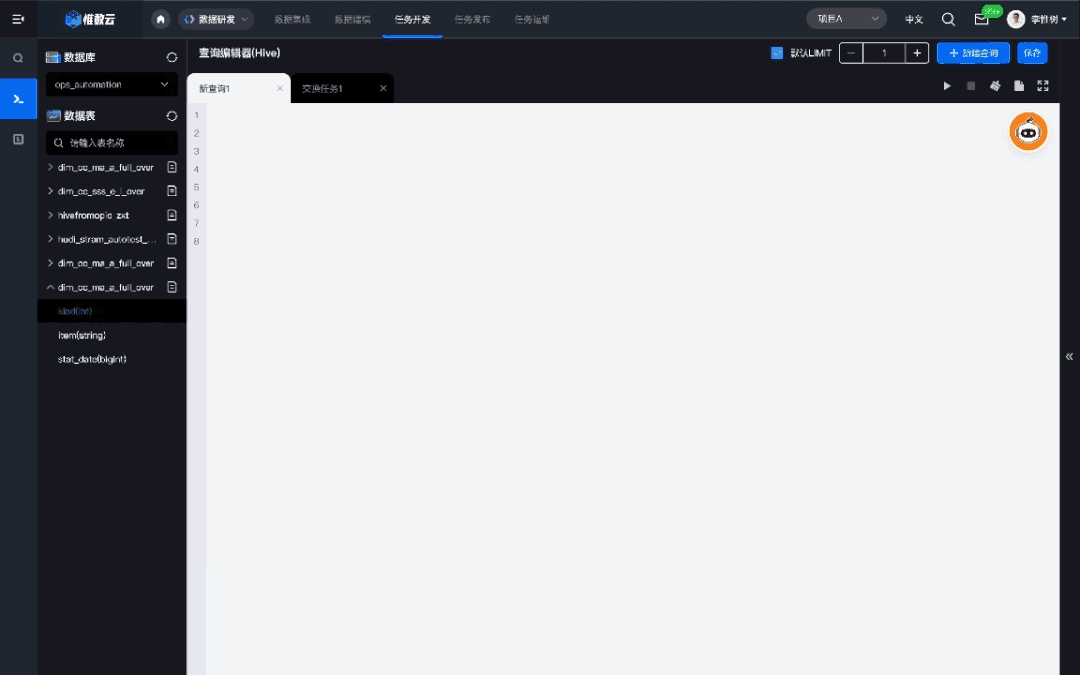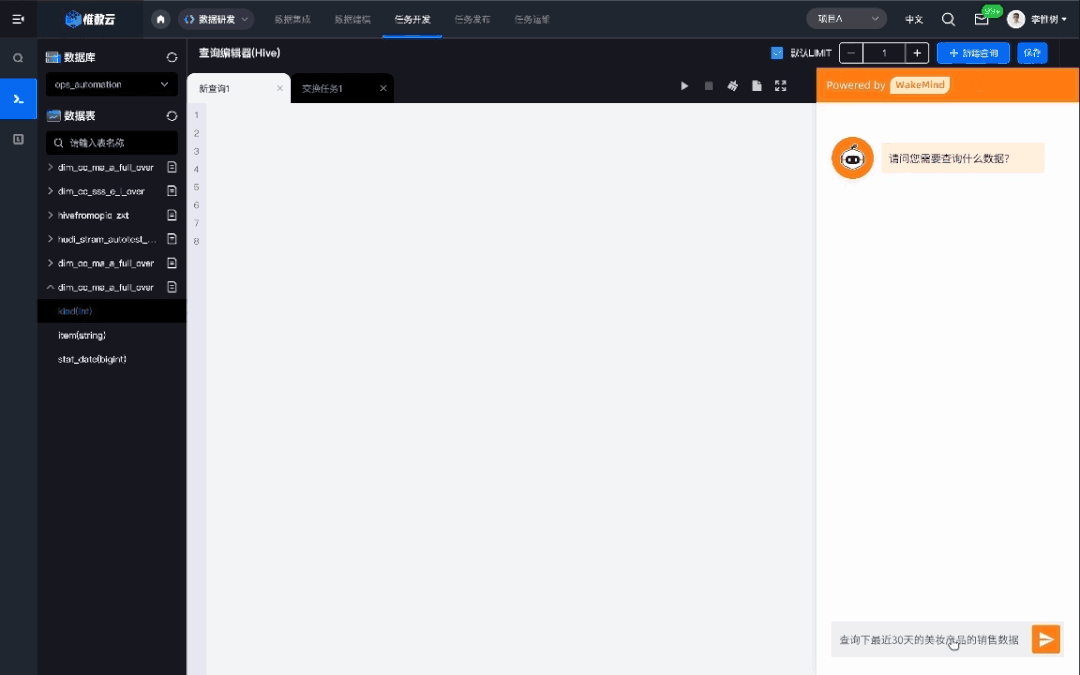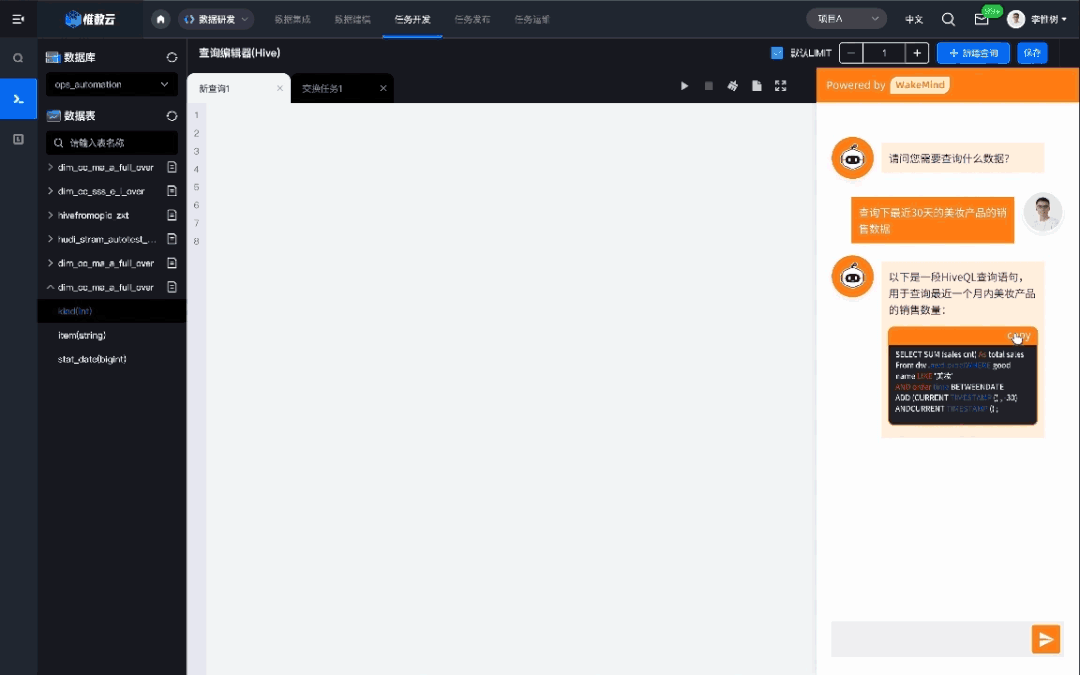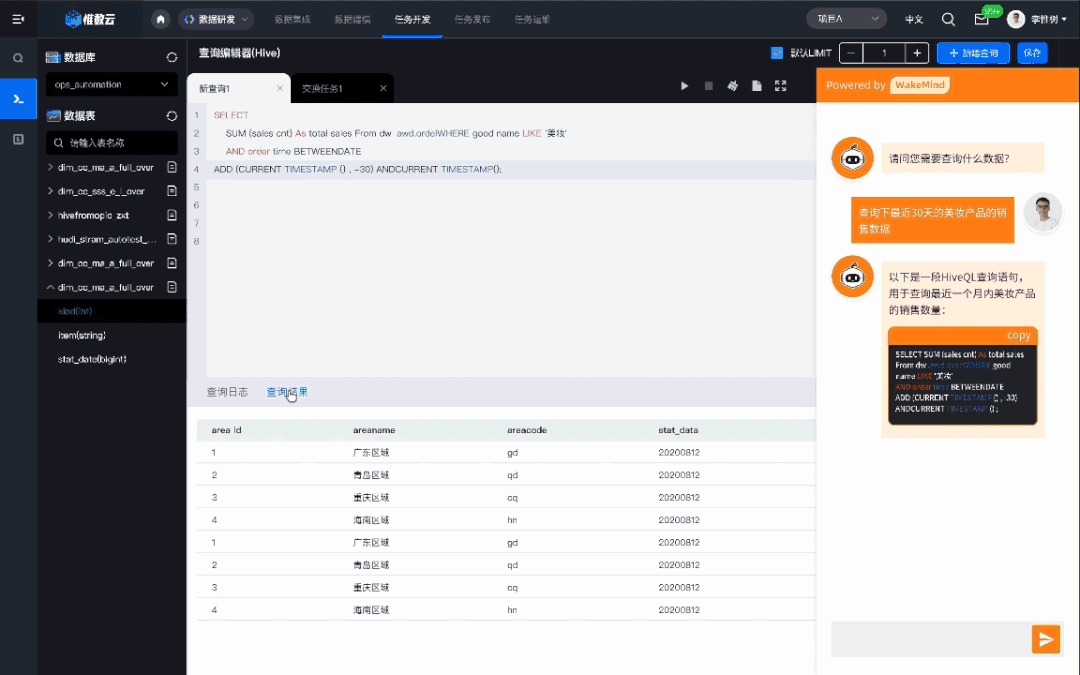
InfoQ:在辅助写代码方面,目前大家有两种看法,一个是认为写出来的不好用,另一个是觉得效果很好,那在您们内部使用过程中,是个什么情况?
李翔:在我们使用过程中,发现大模型非常擅长处理单个具体的场景,简单说就是不需要或没有太多的上下文信息,这种场景都能通过约束好 prompt 来完整地生成出来。但如果编码过程中包含了很长的上下文,比如有对负责需求的理解,以及和其他部门的沟通和协同,模块之间有很强的依赖关系之类的场景,从现在的体验来看,就处理的不是很好。
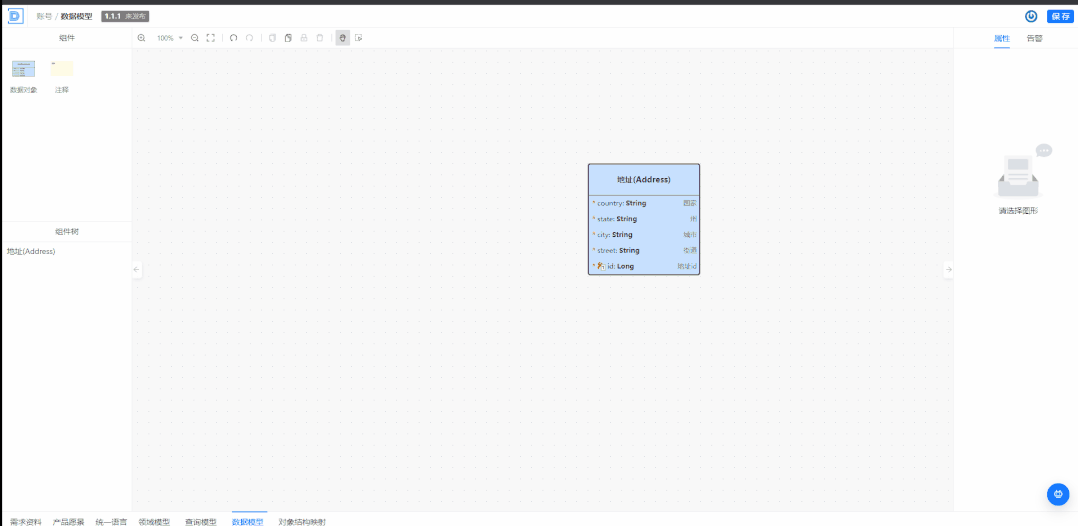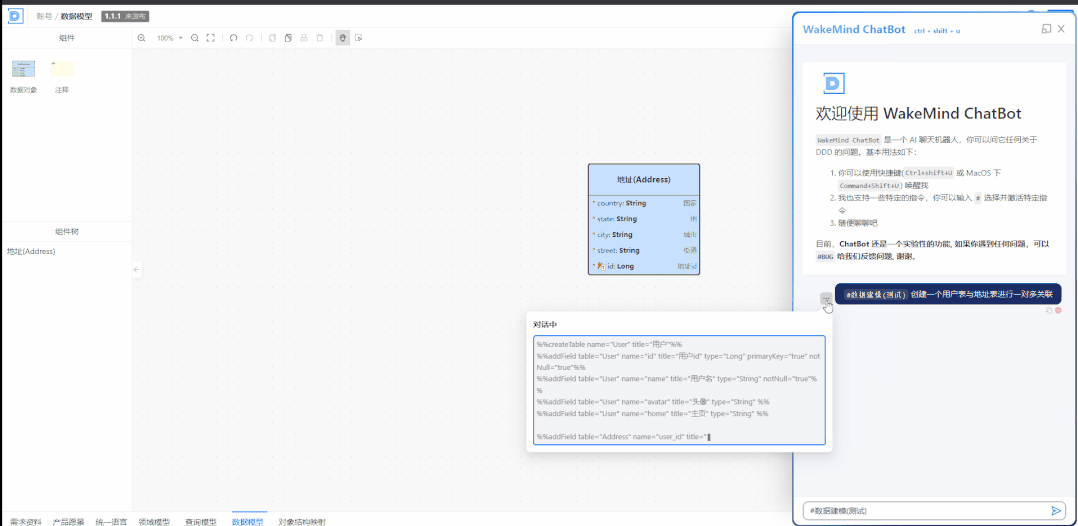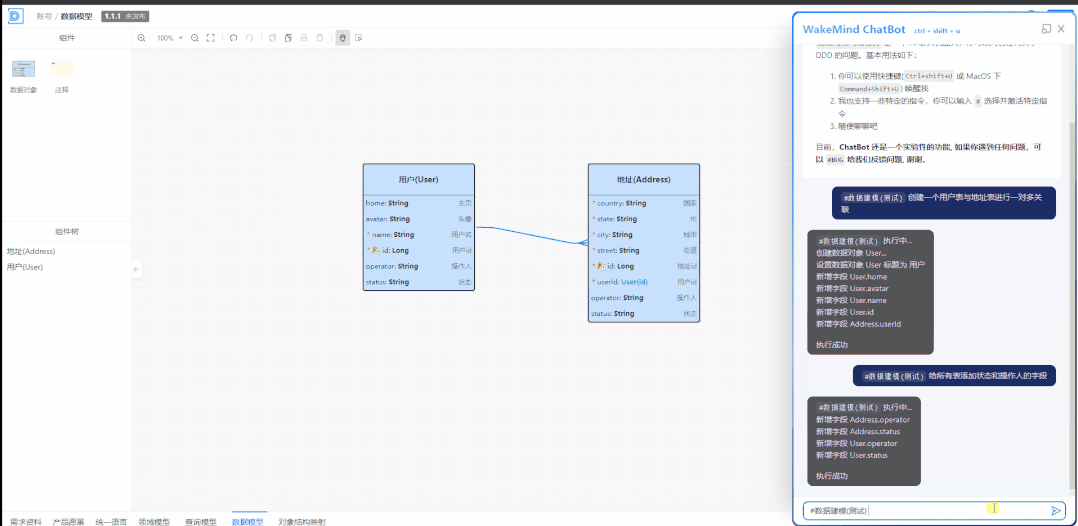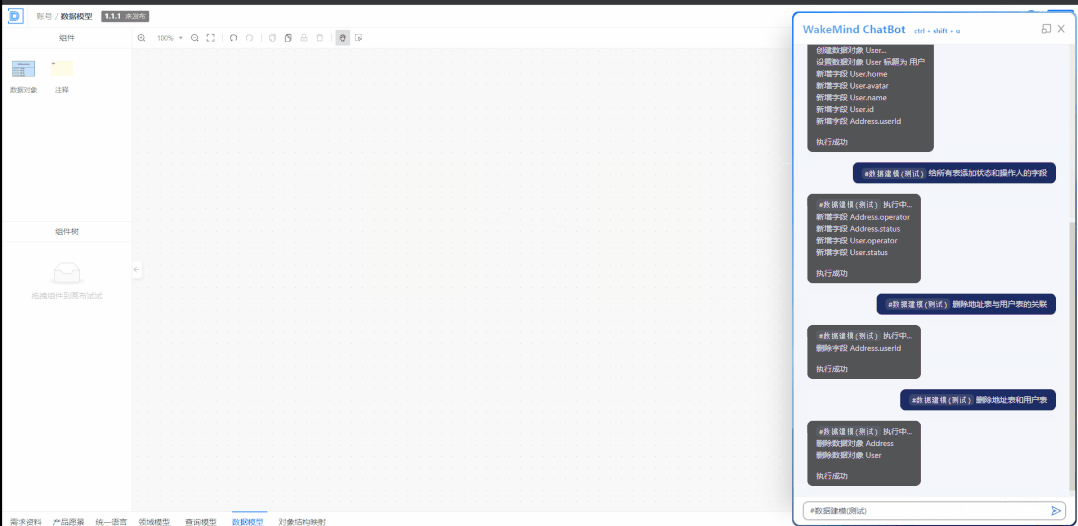
我们使用的核心逻辑是把需求文档转换成架构设计图,可视化的架构设计图转换成为 DSL,再通过 DSL 转换成为模板代码,开发人员在编码过程中通过大模型的辅助嵌入到已有的过程中:比如在开发过程中,做规则类代码生成、单元测试代码生成、开发代码优化、代码解释自动生成文档等,使编码效率与编码质量都得到了提升。
InfoQ:提示工程是否非常重要?您们积累了哪些经验或心得?
李翔:提示工程是非常重要的,prompt 描述的是否详细和贴切,决定了生成结果的质量。
在使用提示工程之前,应该了解大模型的限制和能力,以便于更好地指导大模型生成所需的结果;还可以尝试不同的提示和参数组合,从而获得更好的结果。例如,可以尝试不同的主题、关键字或参数来调整生成的文本;除此之外,还要学习和不同的模型打交道的方式,虽然各家大模型都有理解和逻辑推理的能力,但是由于训练数据和方式的不同,涌现的能力也会有较大差别,所以打交道的方式也会有很大的不同,需要摸索合适的方式,我们通过 WakeMind 的 prompt 管理平台,把这些经验都沉淀到了平台中,可见、可管理、可分享。
InfoQ:贵公司在辅助软件开发的方面还有哪些应用?效果如何?
李翔:在公司内部已发起自我生产力革命,从设计师、产品到程序员,全面运用大模型的工具,初步运用已实现人效达到 20% 的提升。更准确地讲,是开发过程的人效提升了 20%,也就是说,一个人有 20% 代码量是机器帮他完成的。在辅助软件开发方面,基于和大模型的结合提供了可视化的架构设计:包括构建数据模型,构建 SQL,构建领域模型图,构建流程图,识别并补充统一语言,通过需求文档总结需求并输出初步的架构设计等。
InfoQ:从行业发展角度来看,您认为“GPT”和生成式人工智能会催生出一波新的人工智能公司吗?
李翔:会,但不会很多。
对于前几次工业革命的技术爆发来说,不会让产业发生本质的变化,新的技术是用来做产业升级的,当前围绕各个产业的升级已经有了足够多的公司,新的技术会成为这些公司新的利器,做事情的细节会产生一些变化,但是做产业升级的大方向不会发生太多的变化,而且也不会再有很多新兴的公司去做应用和产业升级。从目前来看,新的公司更多是偏向底层做大模型的研发,这个门槛很高,所以不会很多。
采访嘉宾简介:
李翔,惟客数据 AI 算法专家。中山大学人工智能方向博士,珠海市产业青年优秀人才,师从中山大学印鉴教授,在人工智能领域有 11 年的研究与落地经验;熟悉资讯流推荐、画像预测标签、NLP、CV、语音识别等多个 AI 方向,并将对应落地成果发表在国际一流期刊以及申请多项发明技术专利。
今日好文推荐
ChatGPT写21个程序,16个有漏洞:离取代程序员还远着呢!
华为投入数千人实现自主可控ERP;SpaceX星舰爆炸了,马斯克:祝贺!谷歌合并两大人工智能部门,加速力战ChatGPT|Q资讯




