
一、了解图数据库
1、开胃菜:公司业务场景的难题

首先介绍字节跳动的一个产品——抖音,作为我们本次分享的开胃菜。大家都知道目前抖音的视频的推荐,是通过算法去做的,这当中肯定会有一些最核心的基础数据的存储,比如说用户之间的关注关系、视频点赞的这种关系,以及用户的相互之间的通讯录的关系,是基于这些关系的数据去做推荐算法的。
如何去存储这些数据呢?这本身是一个非常有挑战性的问题,所以基于用户的关系来做这个内容或者是用户的推荐,从算法的角度上来说,是一个核心指标提升很大的事情。
做推荐显然是会基于二度和多度的关系,基于 pattern 来做推荐的,pattern 本身是有很多种组合的,如何去基于这些组合去求解,这本身也是作为技术架构需要有这样的能力。
那么我们现在先假设一下原来的时限。比如说我要做二度关系,根据二度邻居的关注关系的结果做查询,那么以前的方法是首先要从线上 MySQL,把用户的关系 dump 到 hive 上,然后将多张的 hive 表做这样的一个 join,然后产出这样的二度关系,然后再将二度关系导入一个在线的 KV 系统,用于做推荐,然后上述的过程每天会去执行几次。
那可以想象在 6 亿+DAU 的抖音,它的整个数据量是非常大的,所以这样的一条条数据下来,它的时间成本和算力成本也是非常大的。
因此,通过算法推荐这个方式,得到的数据已经很旧了,可能是几天以前的数据,所以导致它推荐不实时,以及策略迭代的代价太大了,中间任何一个环节出问题,可能就会导致整个过程的失败。
第三个问题就是日活如此高的抖音,如何实现高并发,以及毫秒级的查询延时,是比较有挑战的一件事情。
下面,我们来看看图数据库的好处是什么?
2、图数据库与关系型数据库
我们需要做一个简单的分析,图数据库相比于传统的关系型数据库,它的区别是什么?
首先图非常很简单,由最基础的点、边以及属性所构成的,而关系型数据库当中,当我对基于一种关系或者说某种特定的条件去做查询的时候,通常的一个技术是多表的 join。
那图数据库对于同样的工作量,它的反应是通过这个图上的遍历(traversal)去实现的,操作更加高效。
因为图数据库本身是基于点和边所组成的,所以从固定的点去做 traversal,它的形成消息分发是一个更加细粒度的分发,所以相当于在一个大的分布式架构上,它会变得更细粒度,对内存的开销、网络的开销都会变得更小,这是背后的系统层面。
简单举一个例子:我如何去做一鸣的好友,然后我再去查询好友的公司有多少名员工?
在关系型数据库当中通常去需要有这样的一些 table,比如说公司的信息表、雇佣关系表、员工信息表等,用 MySQL 去查,可能就需要写成如下图这样的 SQL 语句。

而基于图数据库,我们用 gremlin 这样一种查询语言去实现,简单的一行就能把它非常直白地写完。
接下来我会简单介绍一下图数据库里面流行的语言,以及整个图数据库里面的体系。
3、图数据库业界对角度分类
从语言生态、架构设计、集群规模、场景上分图数据库:

二、适用场景介绍举例
1、ByteGraph 的发展历程和适用业务数据模型
接下来,给大家介绍一下字节跳动内部 ByteGraph 的发展历程:
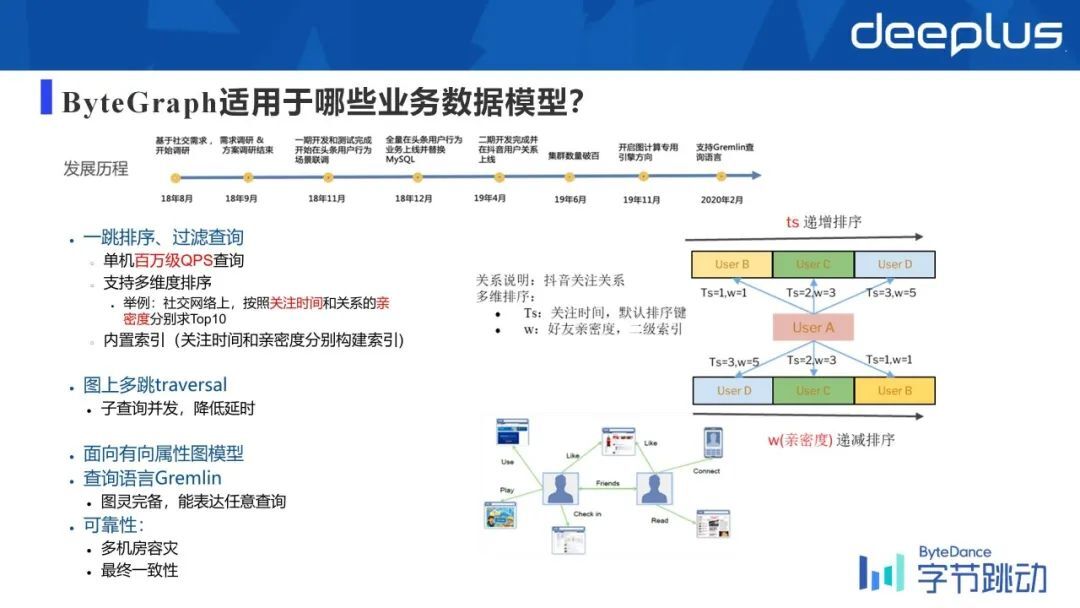
当前版本的 ByteGraph 在单机上是拥有百万级 QPS 的查询性能,并且同时支持了多维度的排序,比如说按照关注时间或者关系的亲密度,分别去做排序,也就是分别会基于时间和关系的亲密度去构建索引。
同时我们也支持会比较支持比较复杂的这种查询,比如说多跳的 traversal,如果我要基于某一个点做一跳进而做二跳、三跳……通常这样的查询所涉及到的点的数量是非常多的,所以通常中间的某些子查询是可以并发去做的,来降低延时。
查询语言上我们当前是基于 Gremlin 去做的,Gremlin 本身是一个图灵完备的语言,能表达任意的查询;作为一个公司百万级数据的这样的一个产品,可靠性是我们非常强调的,我们支持多机房容灾,然后也支持数据的最终一致性。
2、已上线业务场景分类
从业务上划分,目前我们支持了超过 500 多个业务集群,服务器规模已经达到上万台服务器。
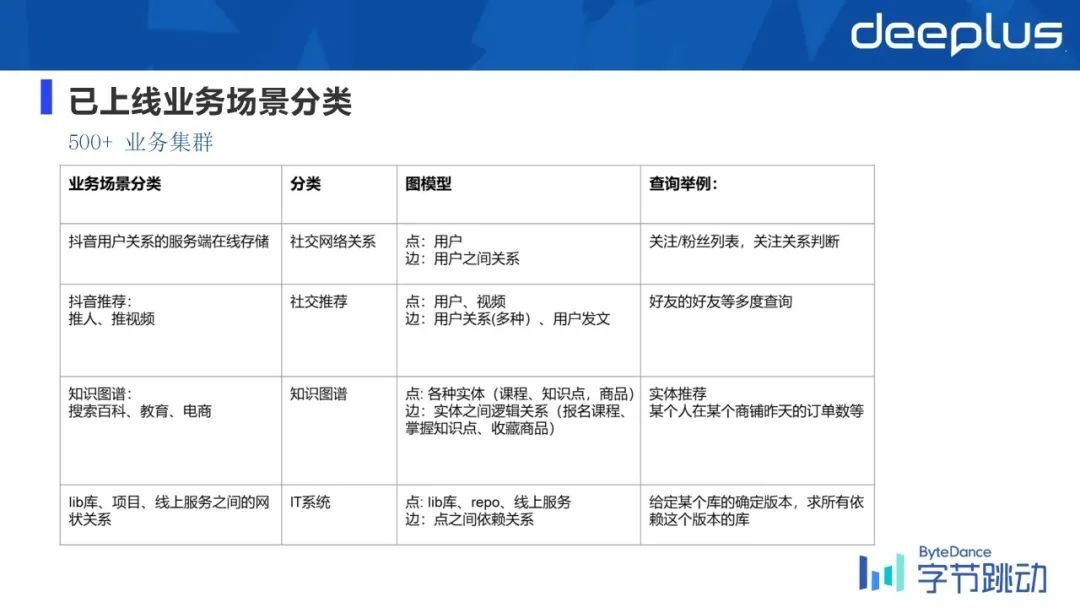
举一个例子:最开始的一个业务,抖音去存储用户关系的在线存储,比如说好友关系、粉丝列表等,也有基于这些基础数据去做推荐的,比如说抖音推荐、推人、推视频等,是基于好友的好友等多跳的查询去做挖掘关系,然后做关联规则分析等一些算法上的内容。
另外也有知识图谱领域,支持搜索百科、教育团队、电商团队等,然后去做个体的推荐。另外的,IT 系统上去用 graph 来抽象 rapo 的依赖关系,或者线上服务之间的网络状态等。
这里举个例子,比如说抖音电商把它建模成一张图,首先实体(点)和联系(边)具体可以分成如下:
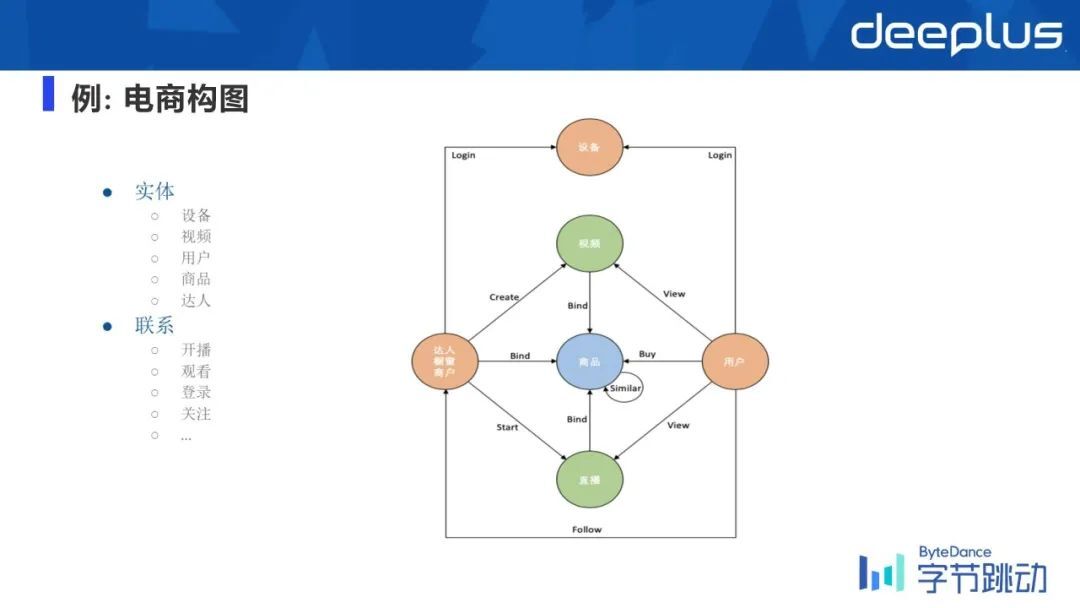
我们会基于不同的设备、商品、达人等构建出来非常大的一张构图,然后这张图上会做各种类型的推荐,或者是离线、在线的分析,甚至是在线的基于图神经网络的训练等,有各种各样的应用。
三、数据模型和查询语言
1、有向属图建模
ByteGraph 是基于有向属性图来建模的,有向属性图就是有点、边和属性来构成。点来表示的一些实体,然后通常 ByteGraph 内部是有一个二元组来唯一标志一个点,二元组通常有一个用户的 uid 和他的在具体的一个应用场景下,比如说抖音、火山、头条等应用,用不同的应用分类成不同的垂直的场景,用这样的一个二元组来唯一标记一个实体点,然后 type 标记的是一类点的集合。
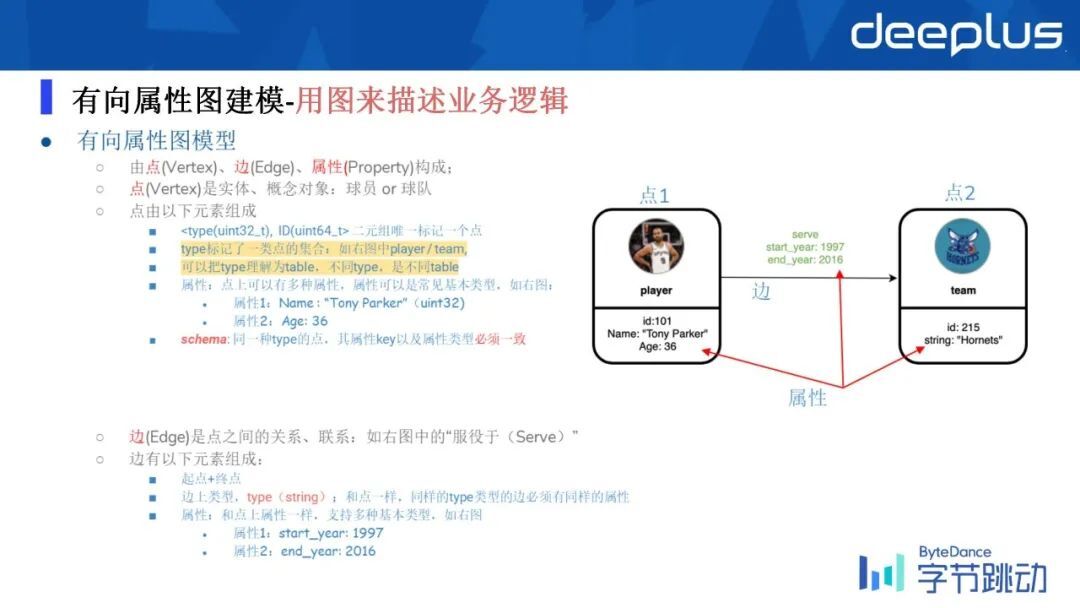
比如说一个运动员或者一个 team,他表达的是真实世界当中的一个实体,可以简单理解成把 table 理解成是关系数据当中一个 table,不同的 type 是不同的 table。
属性其实就是用来描述固定的一个实体,比如说姓名、性别、年龄等等,然后我们会规定同一种类型的 type 点(schema)必须是一致的。
同理,边也是有一个这样的实体,它是由点之间的关系就映射成了边,它通常由起点加终点,以及边上的边类型 type 来描述一个事件。然后同时也会有很多种属性,比如说它的起始时间、终止时间、发生的地点等,来描述这样的一个事件。
简单介绍完了一下 ByteGraph 的图建模,我们再简单介绍一下 ByteGraph 的使用查询语言。
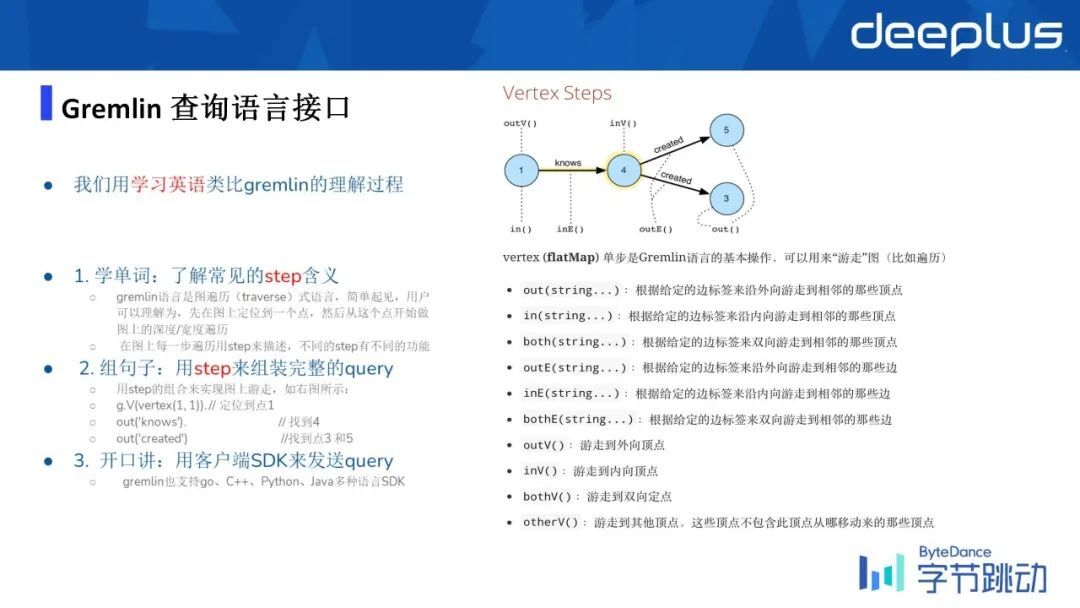
2、Gremlin 查询语言接口
Gremlin 语言我刚才说的是一种图灵完备的语言,它隶属于 Apache,是 Apache 的一个项目之一,它规定了 Gremlin 的一些不同算子所涉及到的查询语义,但是对具体实践是不会有一个硬性的限制的,所以这取决于不同的厂商对 Gremlin 的标准,完全依赖于每一个厂商自己的实现。
目前 ByteGraph 支持了 Gremlin 的一个子集,覆盖率到了 80%左右。数据模型就是有效属性图模型,Gremlin 相比于传统 RPC 接口更灵活、表达力更好。

从上述例子也可以看出,Gremlin 这个语言是非常接近于自然语言的。
简单总结一下,基于 Gremlin 的查询语言接口,用学英语来比喻的话,就分为:学单词、组句子、开口讲这三步。
再用另外一个非常具体的 UGC 场景来举例,基于 Gremlin 语言如何去表达不同类型的查询。
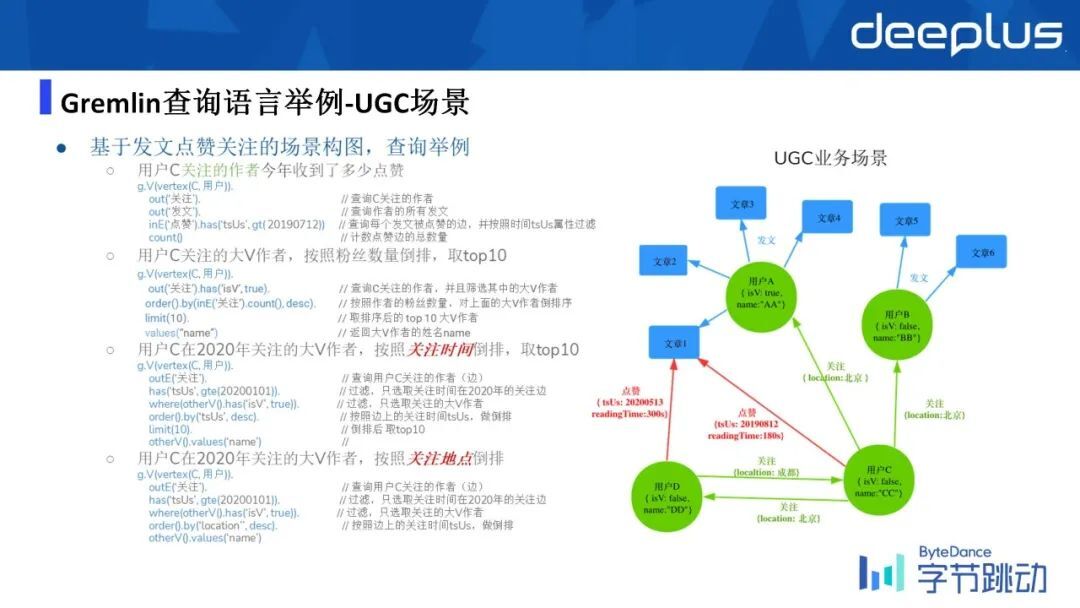
可以看到 Gremlin 这个查询的写法,相对来说比 SQL 还要简单一点且非常直白,比如说我要去限制关注的大 v 的一个条件,会写一个 where,where 里面会写 otherV,otherV 表示当前基于关注关系的这样的一条边,对应的 vertex 一定要限制是一个点,所以这样的一些条件限制可以写到 where 语句,然后我们会基于这个时间和 tsUs 然后去倒排,然后限制直取 Top10,最后 limit(10),然后我会把这些大 v 作者的名字给取出来,这个时候会再去拿到 otherV 然后去求它的一个 value,然后 value 的属性名是 name。
同时 ByteGraph 的特点是我们支持跨集群以及跨表的查询,下面还是以 UGC 场景举例。
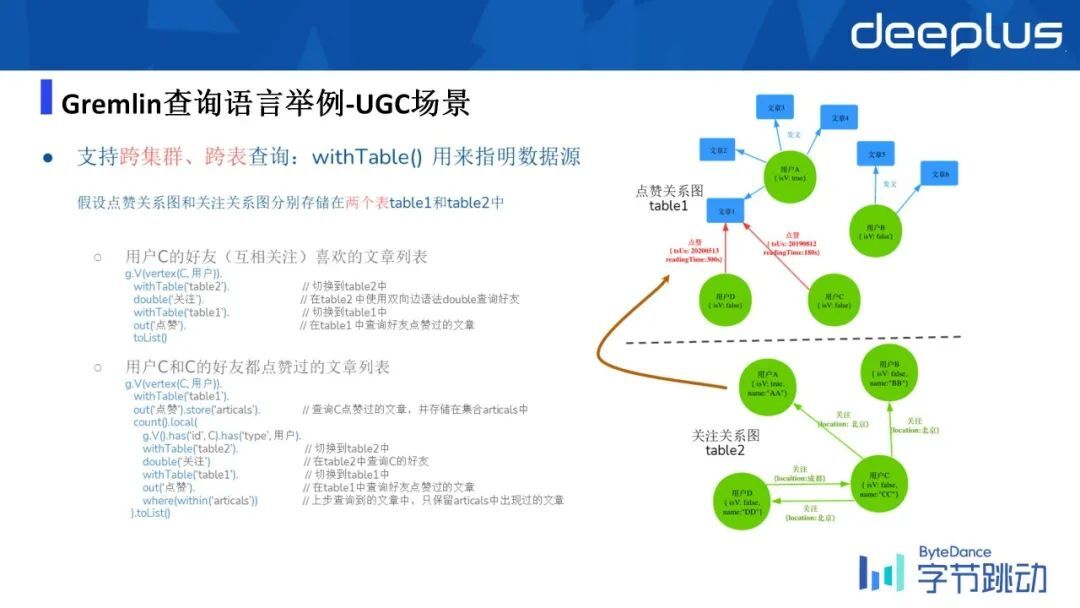
假设当前最上游的垂直业务当中,用户的关系是通过一张 table 来存储的,而点赞关系图通过另外一个 table 来存的。现在我想这个去查询,比如说用户 C 的好友(相互关注)所喜欢的文章的列表,则是我是基于用户 C 从 table2 开始去找,去找在 table1 当中文章的名字,这个时候我需要通过 with Tbale 语义去限制在 table2 中去找 vertex C,然后从具有了 double 关注的所有用户当中,切到 table1 把具有的点赞关系的文章数它给列出来。
所以 Gremlin 它也支持这样子的一些跨表查询的语义,来支撑跨表甚至是跨集群的查询。
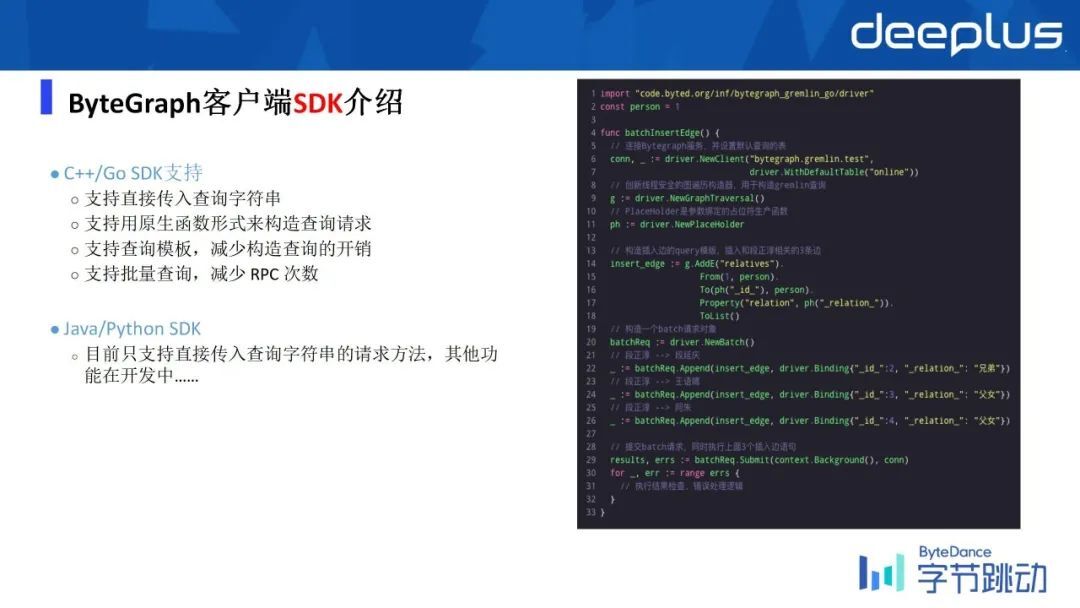
目前 ByteGraph 支持了 C++/go SDK,上右图是基于 Gremlin 的语言,如果要去做一个图查询的话,怎样基于 Java 或者是 C++、Python 这些 SDK 去写这样的一个基于 Gremlin 的查询的例子。
目前的话,4 种语言都支持 RPC 的接口,但是基于 Gremlin 是暂时只支持 C++和 go 的接口。
接下开会更深入的讲解一下 ByteGraph 的整体架构。
四、ByteGraph 架构与实现
1、ByteGraph 整体架构
整个系统可以分成三层:查询引擎层、存储引擎层,磁盘存储层。
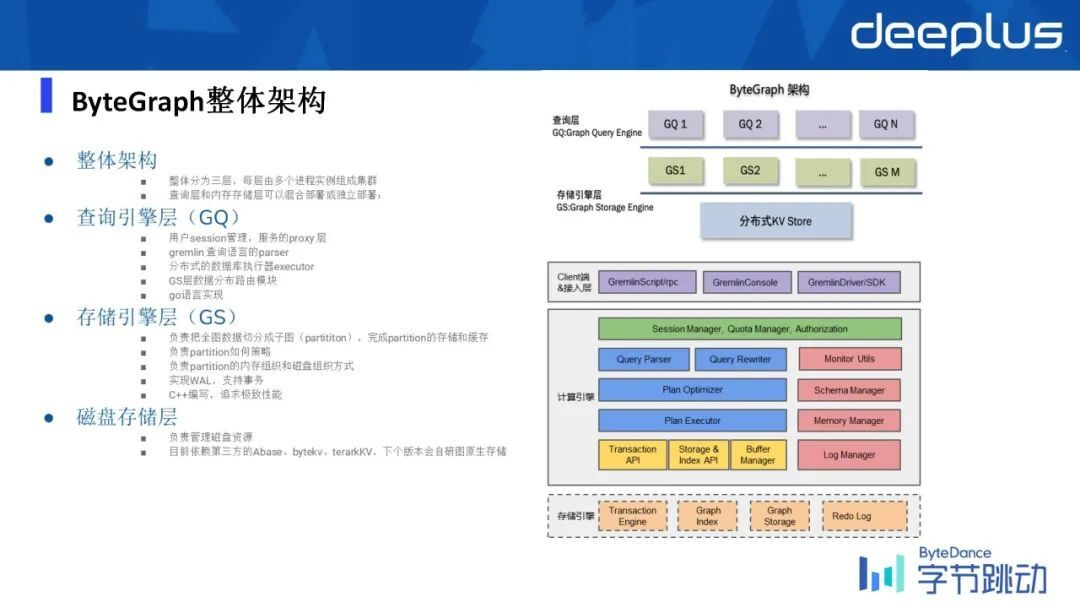
三层是相互独立的,每一层都可以水平扩容,比如说你查询的语言语义非常复杂,可能涉及到的 step 数比较多,所以它是一个计算比较重的这样的查询,但=内存存储开销可能会比较少一点,所以可以开更多的查询引擎层(GQ)的实例,开更少的存储引擎层(GS)实例。
整体上 ByteGraph 是基于了一个经典的计算存储分离的架构去做的,最底层是一个分布式 KV,分布式 KV 我们用的是公司内部的一个叫 Abase 的一个分布式 KV 系统,同时我们也支持其他的分布式 KV,比如说公司内部其实有一个 byte KV 这样的一个产品,它跟 Abase 区别是一个是一致性、一个重可靠性,所以整体上后端引擎是可以以热插拔的形式去做更替的。
查询引擎层
主要涉及到用户 session 管理、服务的 proxy,然后核心的一个功能是基于用户发过来的 Gremlin 请求,去做一个逻辑的逻辑查询计划的这样的一个生成。然后基于逻辑上的查询计划,生成一个物理的查询计划,然后通过执行器 executor 把对应的子查询给分发出去,它是由 go 来实现的,重高并发问题。
存储引擎层
这边主要涉及到数据的存储,因此我们会在这个模块当中会涉及到如何把数据做切片,然后分成一个 Graph partition(Graph shard),然后如何去把不同的 shard 内部所代表的子图,用一种特定的数据结构把它组织起来,同时这个数据结构要有相对来说比较良好且较低的读写放大能力,以及它能够在磁盘的组织形式上对磁盘比较友好,然后是顺序读写。
所以如何去实现这样的数据结构,也是我们 ByteGraph 比较一个核心的设计。为了保证数据不能丢失,在存储引擎层我们也支持了 WAL(Write-Ahead Log),同时我们也支持事务性,通过 1PC 的事务协议来支持的,事务性目前是当前是支持 Read Committed 的事务隔离级别,这一层是通过 C++写的。
磁盘存储层
当前是依赖于公司的第三方 permission store(KV store)去做的,下个版本会自研图原生存储。
2、ByteGraph 读写流程
然后我们简单分析一下,一个读写的 query 进来之后,它的路由机制怎样的呢?
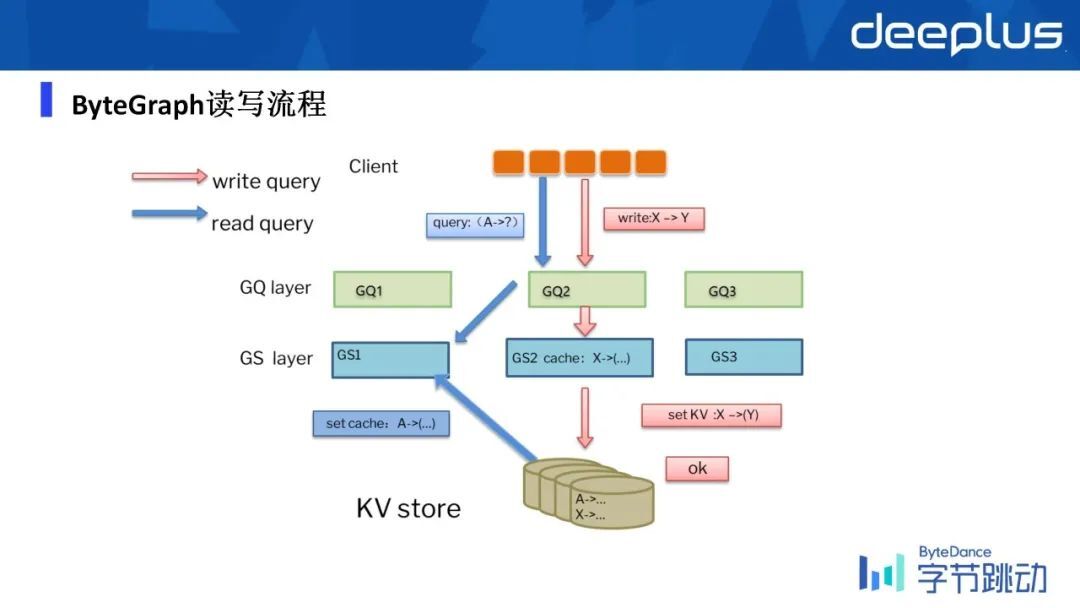
假设当前的 GQ 和 GS 层分别有不同的实例,一个写语句进来之后,它会基于当前写的 X 然后假设根据最简单的哈希规则,它会不会映射到 GQ2 的实例上,GQ 收到 read query 之后,会基于路由规则把它打到 GS2 上,然后 GS2 的 cache 层就会去找 X 存不存在。
如果不存在的话,会把当前 page 从存储的 KV store 里去把它给捞上来,然后把当前写过程给写进去,与此同时,我们会写入一条 WAL 这样的 log,把它固化到 KV store,防止数据更新的丢失。
如果是一个读的过程,就只是做查询,就相对来说更简单了,直接去基于一个 GQ 的实例去找应该在哪个 GS 的实例上,去找到 A 这样的 page,如果找不到就把它从磁盘捞上来,如果找得到就直接返回结果。
所以简单可以把 GS 层理解成缓存层,但同时我们也不是简单的一个缓存,因为在这一层上我们也支持数据的事务性,还有数据的防丢失的能力。
3、ByteGraph 实现
1)查询引擎
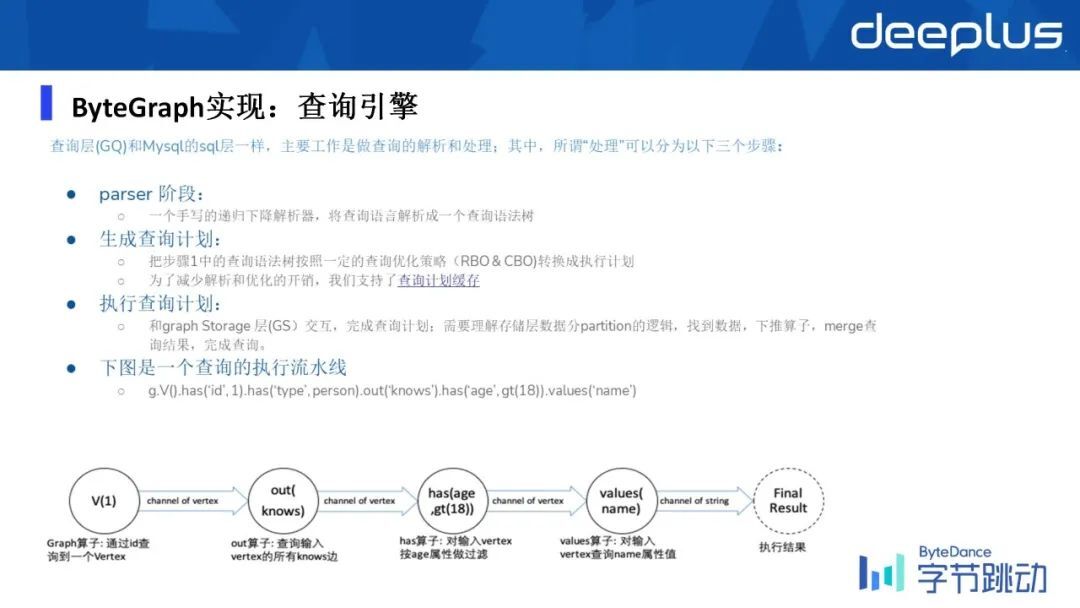
这里再简单提及一下 ByteGraph 的查询引擎,接下来我会依次对查询引擎、存储引擎做详细的分享。查询引擎这边首先第一个是要做 parser,把一个 string 打进来之后,把它解析成一个查询的语法数,基于一定的优化规则,如 RBO(rule based optimization)和 CBO(cost based optimization)去生成一个逻辑的查询计划。
通常 query 在垂直的业务上,所以 query 和 pattern 是比较相似的,所以我们为了防止查询计划多次的生成,所以一个查询计划基于一个模板的情况下,我们是有缓存的。
然后生成了查询计划之后,接下来的事情就是让 GQ 层与 GS 层之间交互,能并行的查询尽量并行去做,不能做的话就只能串行的去查询,基于这样的一个依赖关系去串行的完成这样的查询。
同时 GQ 层,需要去理解在存储层上的分片逻辑,找到对应的一个数据,它在具体在 GQ 层还是在 GS 层上。
同时,一个带索引的查询,它在存储层上已经建了索引之后,这个查询显然不应该把它放到查询上去做,它应该放到存储上去做。所以我们这里也涉及到一些算子下推的一些优化。
在查询优化器上分成两类:第一种是基于规则的优化器,第二个是基于代价的优化。
2)查询优化器
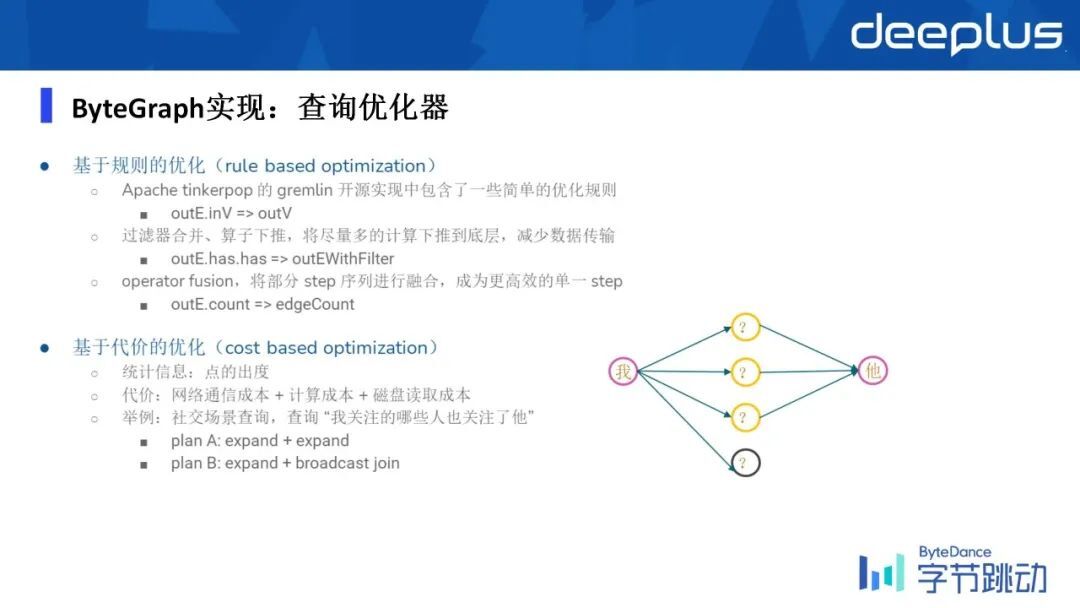
查询优化器分成两类:基于规则的优化和基于代价的优化。
在基于代价的优化中,可以用右图来表示。执行计划 A 非常显而易见的一个方式,就是做两票的 expand,我先找到他的一度邻居,然后依次让一度邻居去找到他的二度邻居,看有多少人当中是有他的。另外一个方式是找到了我的一跳领居之后,然后找到他的一跳入住邻居,然后依次去做一个 join,那显然二会比一开销很多。
所以我们在用户写出这样的一个 query 之后,我们的优化器能够找到相对 cost 最低的一个查询优化的逻辑执行计划。
3)图分区算法
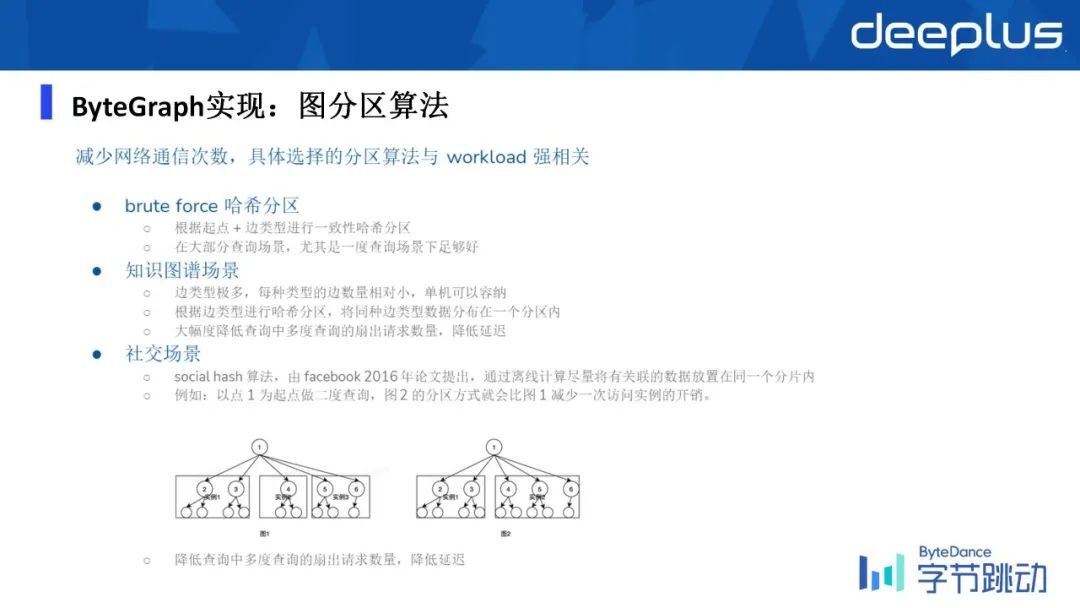
图分区的话,这一块 ByteGraph 支持了不同策略的图分区方式,比如说最简单的基于点的起点,和边的类型进行一致性哈希的分区方式,目前的话是在大部分场景上都是基于这样的分区的算法来做的。
ByteGraph 支持了不同策略的图分区方式,比如说最简单的基于点的起点,和边的类型进行一致性哈希的分区方式,目前的话是在大部分场景上都是基于这样的一个分区的算法来做的。
知识图谱的场景它的特点在于它的边类型是非常多的,所以删除之后映射到每一种类型的边的数量相对较少,小到单机是可以完全容纳这种类型的边的所有集合,所以就不要考虑点了,完全依据边的类型进行哈希分区。
这样的话在知识图谱这个场景下,它能大幅的降低查询中多度查询扇出的请求数量,也就是网络的开销,进而就可以降低了延时。
在社交场景当中,通常来说是一个点的度的分布,但是有一些点它的度特别大,有一些点它的度特别小,甚至没有人关注它。在这种情况下,我们是基于 Facebook16 年的一篇论文,去实现了一个这样的,一个 social hash 这样的一个算法,来保证我们做多跳邻居查询的时候,它的网络开销是比较小的。
所以这种情况下, ByteGraph 会优先让整个图导入之后去做一个离线的图分区算法,然后做完了之后再把对应的点和边,基于这个算法映射到不同的数据。
4)ByteGraph 存储引擎实现
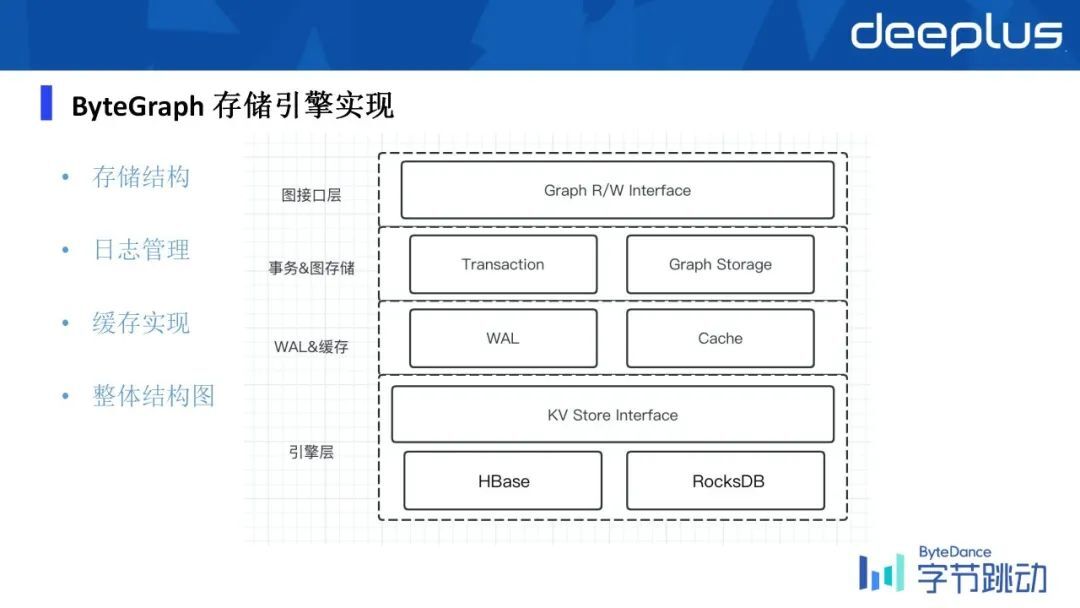
接下来再讲一下存储引擎的一些细节,整体上说存储引擎这边可以把整个系统组件划分成这样的几层。
最上层是一个跟图语有关的读写的接口,然后中间这一层是涉及到如何去支持数据的事务性,以及我们如何把一个数据映射成一个图原生的存储,它的数据 layout 是什么样子,我们在这一层把它给解决了,然后同时我们也支持 WAL,来保证数据的更新是能够持久化的,不会有任何数据的更新的丢失。
最下面一层就是基于 KV store 这样的接口,我们支持了不同类型的 KV store,比如说一些开源的 HBase、RocksDB 等。
① 存储结构(一)
简单讲一下如何机遇 KV 系统能够构建一个图结构?
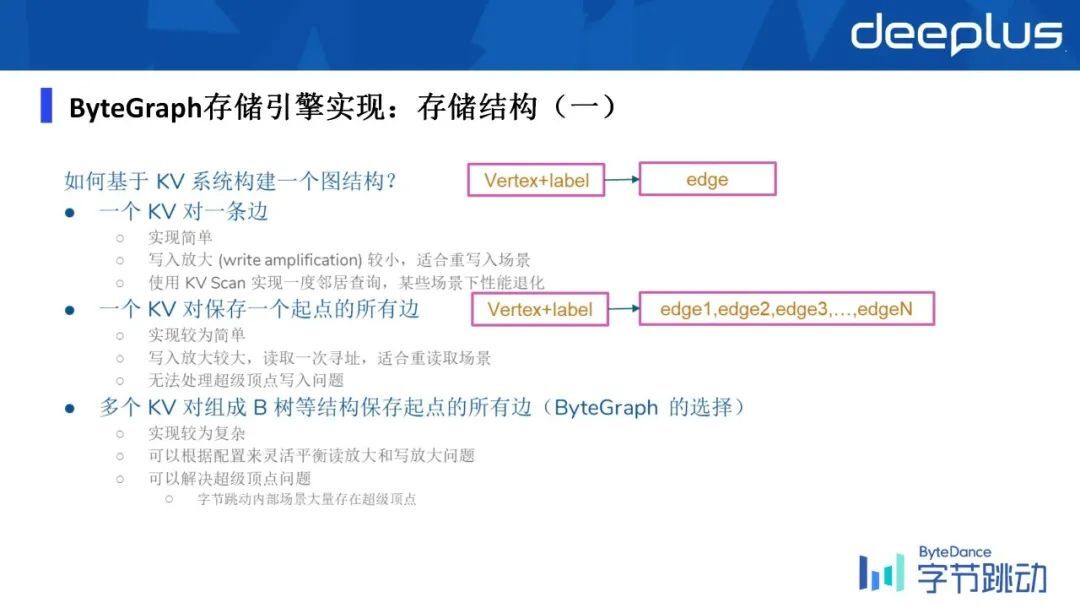
基于 KV 的一个建模,最简单且直观的方式就是一个 KV 对一条边,同时它的写放大也非常小。
所以写放大就是当你想更新一条数据,这个数据可能是有一个字节数,比如说 X,但是你实际上更新的这样一个数据块是 Y,如果 Y 远大于 X 的话,就是写放大是非常大的,当前这样建模它的写放大是非常小的,因为它的粒度很细,但是你可以想象它去做查询,做一跳领域的查询的时候,它的性能是退化的程度是非常大的,因为它涉及到大量的随机读写,它数据的局部性就没有了。
如果用一个 KV 去保存一个起点的所有边,显然这个数据的局部性就会好,但是它的写放大就会变得很大。比如说你改了当前对应的一个点上的一条边,其实整个 ege 历史都要被更改,这是我们设计上的一个权衡,需要做一个折中。
具体是怎么做的,我们用一个类似于 B 树的结构来建模 Graph,对某一个点来说,一个点同一个边 type 的所有的终点是一个存储单元,也就是说我们把一个起点 ID、起点 type 和边 type,基于它去 group by,具有相同值的所有边集合,我们会认为它是逻辑上属于一个分区的。
如果这个分区依然涉及到很多点怎么办呢?我们会把它作为一个二级的拆分,所以因此会涉及到 b 树的多层级。
假设一个点,它基于某一种关注关系,粉丝数是 1000 万,其实可以想象用一级的一个 page 去存肯定是不够的,我们会把它拆分成多 page。
② 存储结构(二)
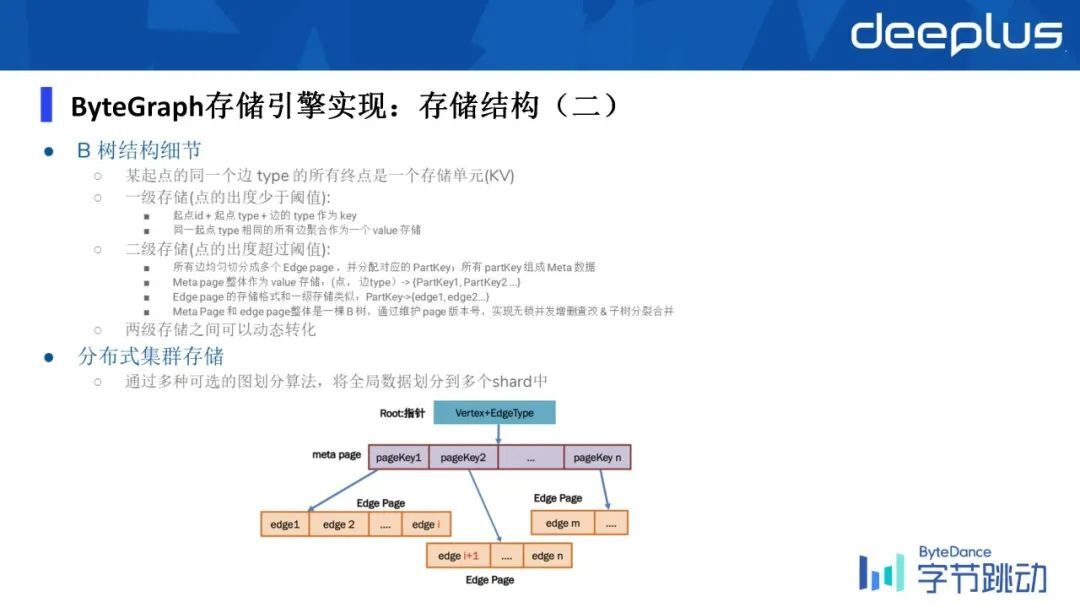
第一层的 page 就叫 Meta page,它其实只是去简单记录了一个映射,这 1000 万个邻居当中,我们基于每 2000 为一片,每一片我们把它称作为一个 Edge page ,每一个 Edge page 又存储了 2000 个 Edge,所以用这样一个多级拆分的这样的方式去降低了读写放大的问题,同时起到了一个非常平衡的设计。
总结下来就是单起点和某一种固定的边类型组成了一个 B 树,然后 B 树的每一个节点是一个 KV 队,然后这里涉及到完整性上的话,我们会限制每一个 B 树的写者只能是唯一的,以防止并发的写入导致 B 树逻辑上的破坏。
刚才说到写放大的问题,我们具体在当前 B 树的建模上,依然其实会存在写放大的问题。
③ 日志管理
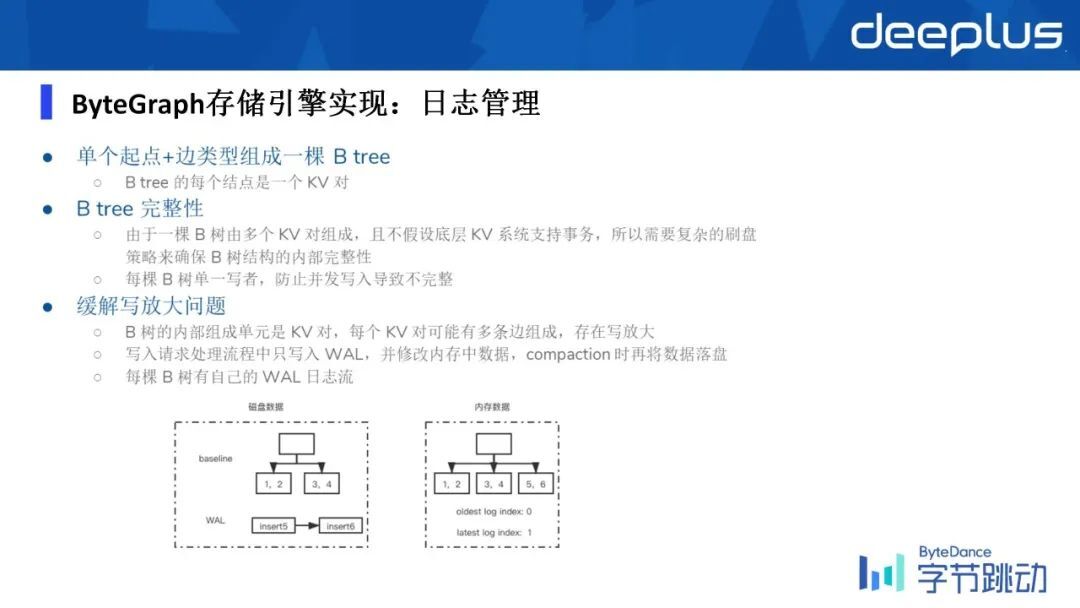
我们是如何进一步去优化写放大的?比如说一个写请求,过来了之后,我们其实是只会去写 WAL 的,当它在内存当中的某一个 B 树的 page,当一个写请求进来,它确实映射到 page 上的数据了,显然内存中的数据是需要被更改的,但是磁盘上的数据这个时候是不需要更改的。
这个时候,它会写一条相对来说尺寸比较小的 WAL,再把它固化到 KV store 里,只有当这个数据再次被从磁盘上捞到内存里的时候,我们会把原有的磁盘上的旧数据 apply 到新的 WAL,然后就生成了最新的数据,然后把它放到内存里,通过这样的方式来缓解写放大的问题。
然后同时如刚才所说,为了维持 B 树的完整性,每个必须是有且唯一的一个 WAL 日志流。
④ 缓存实现

关于缓存的话,我们去实现了自己的一个高性能的 LRU Cache。这个不难理解,作为一个数据库的话,你需要有一个相对来说比较泛化的能力,不同的垂直的应用场景,它所涉及到读写的比例以及读写的 QPS 也是不一样的。
所以我们 LRU Cache 是支持了不同的策略,基于不同的频率的读出,触发的阈值也不一样,比如说我们一台物理机的内存,比如说我用到了 60%,这个时候想再往上走可能就比较危险了,这个时候我就开始触发 LRU Cache 的能力,把不会经常用到 page,要下刷写到磁盘上。
当数据规模不变的时候、写请求的流量增大的情况下,缓存与存储分离的模式,它的一个优点就是可以快速的扩容,也就是把 GS 这一层单独的去加大请求的个数,来提高我的缓存的能力,但存储层的 QPS 的整个的容量是不变的。
下图是 ByteGraph 的存储层的全貌,单机的内存引擎就会长这个样子。
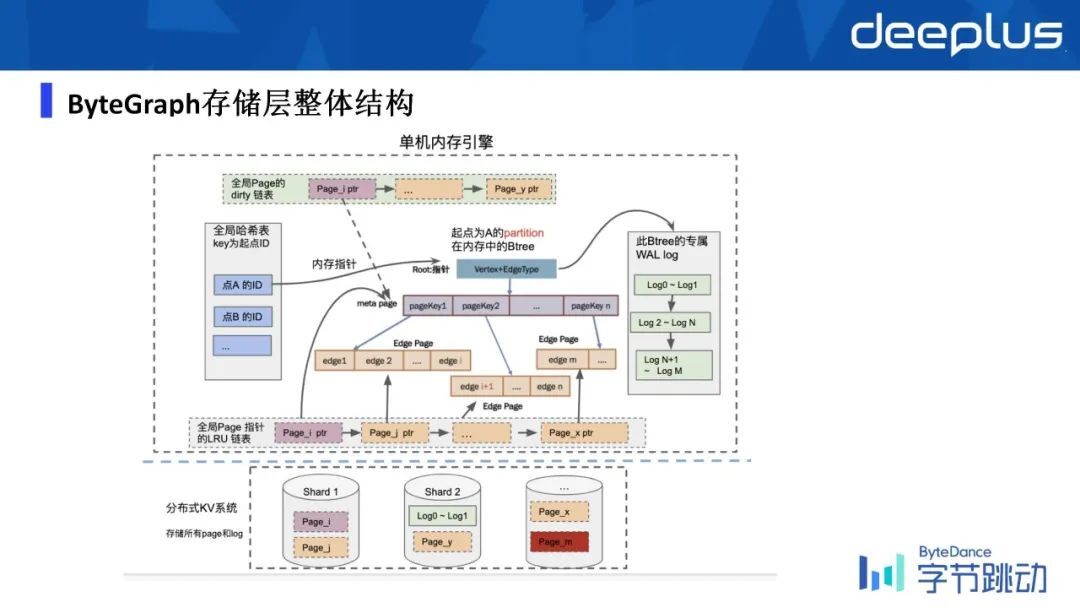
首先会把整个图数据模型成基于一个特定的点和它的边类型,会把它抽象成一个 B 树的数据架构。
如果随着读写流进来,特别是写流会把一些 page 更新掉它的数据,同时会写一个 WAL,这个时候 page 会变脏,所以我们会用一个 dirty page 的一个 link list 去记录脏数据,脏数据积累到一定程度后,我们要把脏数据下刷到磁盘上,然后同时我们会有维护 WAL 这样的一个 log 流,然后同时也会有这样的一个 LRU Cache 来保证一个我们的物理机的内存开销是在一个阈值之上的,有一个上界有一个下界。
五、关键问题分析
1、ByteGraph 关键问题之一:索引
索引我们目前是支持了全局索引和局部索引:

局部索引
对于给定的起点和边类型,然后对边上的属性构建索引,比如说我基于用户的年龄索引,显然基于默认的属性,比如说我们当前的默认属性是基于时间去索引,边就会基于时间去做排序,如果基于 Edge 去索引的话,那会基于 Edge 去做排序,这是两个不同的 B 树的组织方式。
全局索引
基于一个属性值,能查到当前在整个 Gragh 里面,具有特定属性值的所有点的 ID,这个是全局索引的定义。然后这里就涉及到数据一致性的问题了,它本身是有分布式事务的能力,所以我们通过分布式事务能力来维护了数据与索引之间的一致性。
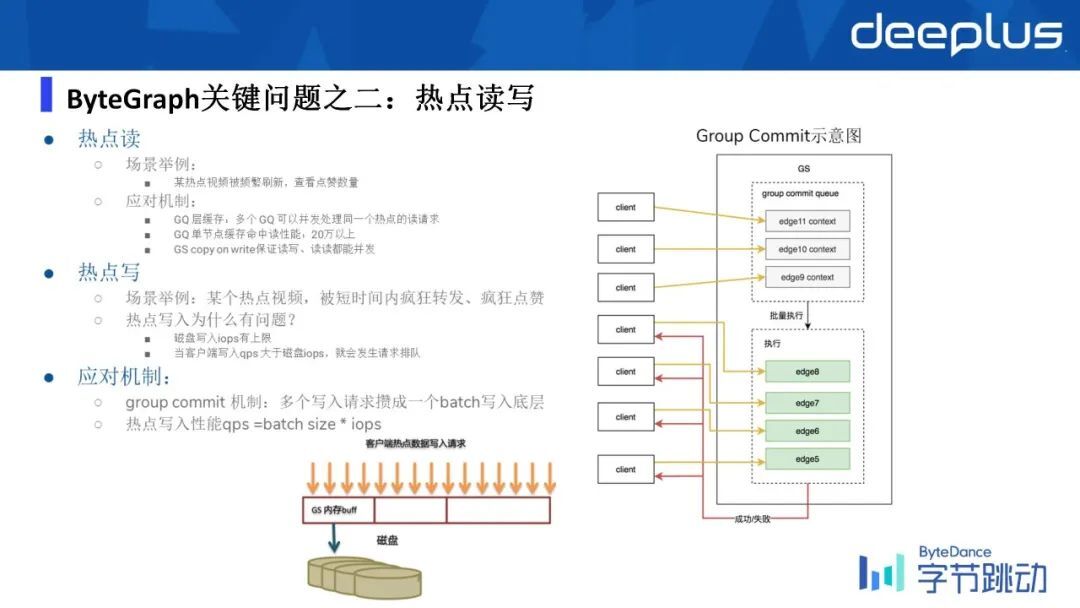
2、ByteGraph 关键问题之二:热点读写
举个例子:比如说一个大 v 正在直播的时候,可能有很多人进入了他的直播间,回到刚才那个例子,我们是通过一个图来去模拟用户与电商之间关系的,所以当有不同的用户进到这个商家的时候,其实你可以想象成在 Graph 里面会有很多边被写进来了,很多人进入一个特定的商家的时候,就会造成热点的写问题,同样读也是一样的。
3、ByteGraph 关键问题之三:离线在线数据流融合
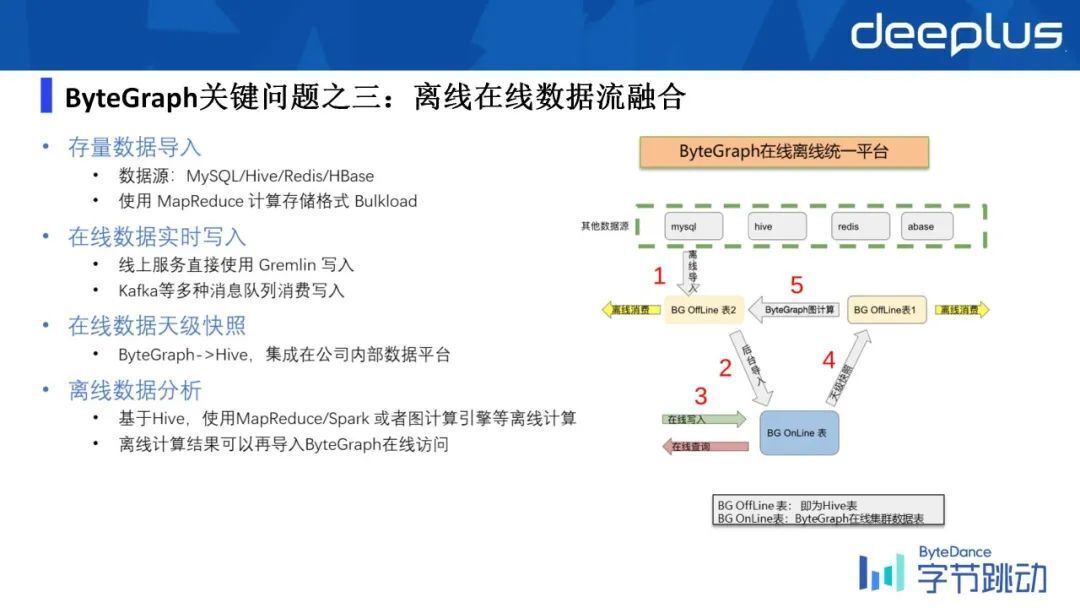
存量数据导入:ByteGraph 目前对存量的数据导入,比如它有不同的数据源存入 MySQL/Hive/Redis/Hbase 等,我们是通过这样的一个公司内部的平台 MapReduce 去 Bulkload 到我们的 ByteGraph 里了,这是存量的离线的数据导入。
在线数据实时写入:在线实时的写入是通过线上的服务调我们的 Gremlin 的 SDK,或者是 RPC 的 SDK 去写入,或者也可以通过 Kafka 等这种消息队列在线写入到 ByteGraph 里面。
在线数据天级快照:ByteGraph 也支持天级的数据快照,把一天的数据完整的放到 hive 里,然后用来给上游的业务同学做离线分析或离线训练等。
>>>>
Q&A
Q1:查询语言 Gremlin 和 GSQL 差别大吗?GSQL 会成为标准吗?
A1:据我所知,GSQL 目前确实有一种趋势会变成标准,原因是它跟 SQL 长得很像。但是我个人认为,我觉得 Gremlin 对用户更友好,是比较贴近于自然语言的,然后它是一个比较类 pipeline 的这样一种语言,所以天生就比较适合做查询计划的优化。
因为目前关系型数据库还是主流,所以大家 SQL 会熟悉一点,所以会轻易的从 SQL 转到 GSQL 上。至于 GSQL 会不会成为标准,不影响当前的一个事实是 Gremlin,已经被很多大厂基于查询语言,去做了一个这样的不同的数据库产品出来。
Q2:支持 HA 吗?
A2:当前暂时是不支持的。
Q3:请问支持一些基本的图计算操作吗?比如计算三角形个数 triangle counting/listing。
A3:目前是不支持的,我们有另外的一套系统去支持它。
Q4:貌似 DGraph 更简单,问下,什么原因不选择 DGraph?
A4:字节有自己特定的场景,我们不仅有国内的数据,还有国外的数据,数据量特别大,每秒钟要支持的 QPS 也特别高,所以目前开源的数据库都不能满足我们公司内部的需求。
Q5:请问老师我们对超级节点的查询有处理吗?
A5:这个是有的,我们用 B 树来 model 这个图,假设设定阈值为 2000,超出 2000 就会分裂成两个 page,以此类推。像我们抖音上人民日报的粉丝数有 1 亿+,相当于一个超级节点,在 ByteGraph 的维护下,目前性能上都没有任何问题。
Q6:图数据库也分为类似的 OLTP 和 OLAP 吗?还是主要应用于 OLTP 的场景?
A6:目前 OLTP 和 OLAP 都是各有侧重的。
嘉宾介绍:
陈宏智博士,目前在字节跳动基础架构组担任高级研发工程师角色,博士毕业于香港中文大学计算机科学与工程系,本科毕业于华中科技大学计算机学院,在计算机系统及数据库领域发表顶会论文及期刊(e.g:EuroSys/ SoCC/SIGMOD/KDD/TPDS 等)十余篇,研究方向为分布式系统、分布式计算、大规模图存储/计算/训练系统;港府博士奖学金获得者,微软研究院“明日之星”荣誉获得者。
本文转载自:dbaplus 社群(ID:dbaplus)
原文链接:字节跳动万亿级图数据库的应用与挑战




