
背景
在 Netflix,我们大量使用 gRPC 来实现通信。当我们处理请求时,了解调用者对哪些字段感兴趣以及会忽略哪些字段通常是有益的。有些响应字段的计算成本可能会很高,有些字段可能需要对其他服务进行远程调用。远程调用从来都不是免费的;它们造成了额外的延迟,增加了出错的概率,并消耗了网络带宽。我们需要知道哪些字段不需要在响应中提供给调用者,从而避免进行不必要的计算并删除该调用方法。在 GraphQL 中,这可以通过使用字段选择器来实现。在 JSON:API 标准中,一个类似的技术被称为稀疏字段集(Sparse Fieldsets)。在设计 gRPC API 时,我们是如何实现类似功能的呢?我们在 Netflix Studio Engineering 中使用的解决方案是 protobuf FieldMask。
Protobuf FieldMask
Protocol Buffers,简称 protobuf,是一种数据序列化机制。默认情况下,gRPC 使用 protobuf 作为其 IDL(接口定义语言)和数据序列化协议。
FieldMask 是一条 protobuf 消息。关于如何在 RPC 请求中使用该消息,有许多实用程序和约定。FieldMask 消息包含一个名为 paths 的字段,用于指定字段是应该由读取操作返回或是应该被更新操作修改。
message FieldMask { // 字段掩码路径集 repeated string paths = 1; }示例:Netflix 工作室产品制作
我们假设有一个 Production 服务来管理工作室的内容制作(在电影和电视行业中,术语“制作”(production)指的是制作电影的过程,而不是运行软件的环境)。
// 包含制作相关的信息 message Production { string id = 1; string title = 2; ProductionFormat format = 3; repeated ProductionScript scripts = 4; ProductionSchedule schedule = 5; // ... 更多字段 } service ProductionService { // 根据ID返回制作产品 rpc GetProduction (GetProductionRequest) returns (GetProductionResponse); } message GetProductionRequest { string production_id = 1; } message GetProductionResponse { Production production = 1; }GetProduction 通过其唯一 ID 返回 Production 消息。该制作包含了多个字段,比如:标题、格式、日程排期、脚本(又称剧本)、预算、剧集等,但我们要保持这个示例的简单性,并在请求某个制作时将重点放在过滤日程排期和脚本上。
读取制作的详细信息
假设我们希望使用 GetProduction API 来获取特定作品的制作信息。虽然一个制作有很多字段,但其中一些字段是从其他服务返回的,例如来自 Schedule 服务的 schedule 或来自 Script 服务的 scripts 。
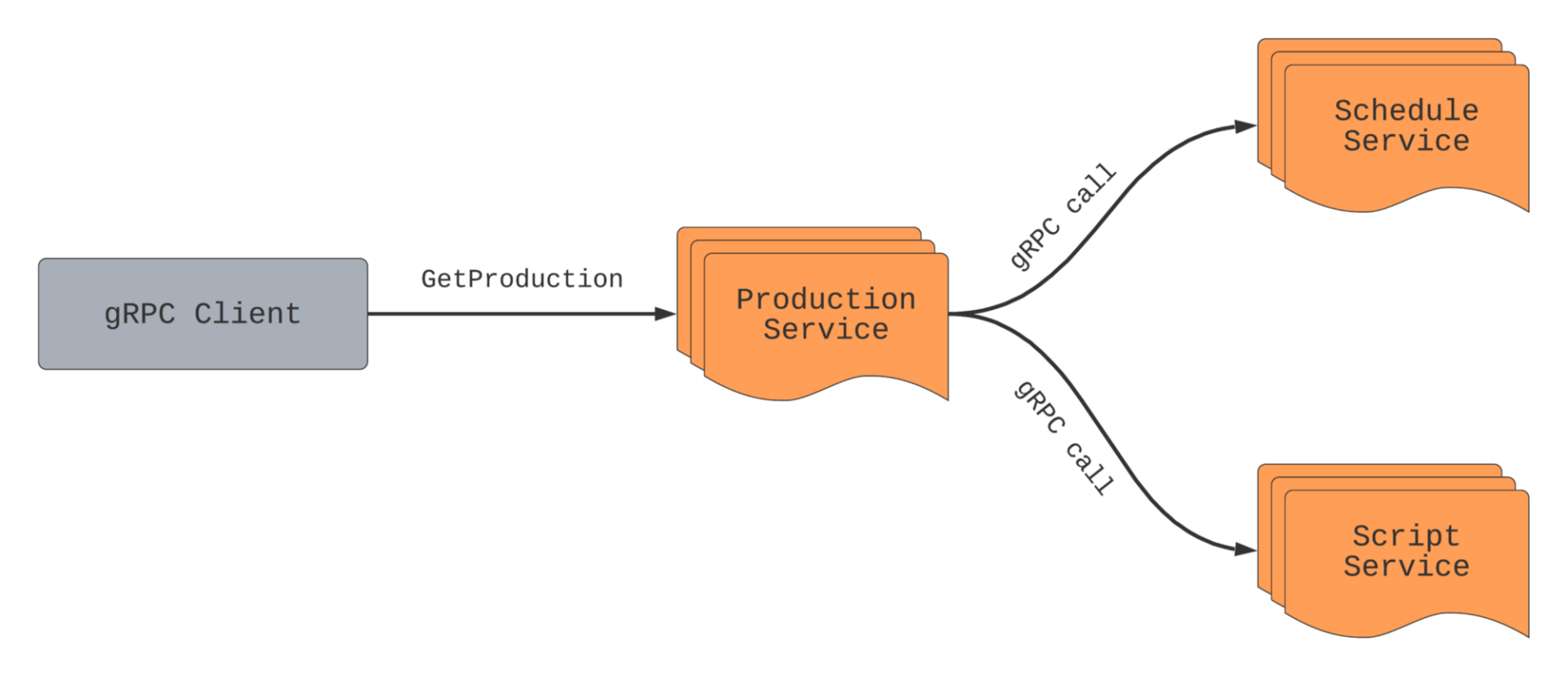
每次调用 GetProduction 时,Production 服务都会向 Schedule 和 Script 服务发出 RPC 调用,即使客户端需要忽略响应中的 schedule 和 scripts 字段。如上所述,远程调用不是免费的。如果服务知道哪些字段对调用者来说是重要的,那么它就可以做出明智的决策,决定是否需要进行昂贵的调用、启动资源密集型计算或调用数据库。在本例中,如果调用者只需要制作的标题和格式,那么 Production 服务可以避免对 Schedule 和 Script 服务的远程调用。
此外,请求大量字段可能会导致响应负载过大。对于某些应用程序来说,这可能会成为一个问题,比如,在网络带宽有限的移动设备上。在这些情况下,对于消费者来说,只请求他们需要的字段是一种很好的做法。
解决这些问题的一种简单方法是:添加额外的请求参数,例如 includeSchedule 和 and includeScripts :
// 不推荐使用包含一次性“include”字段的请求message GetProductionRequest { string production_id = 1; bool include_format = 2; bool include_schedule = 3; bool include_scripts = 4;}这种方法需要为每个开销较大的响应字段添加一个自定义 includeXXX 字段,但这不适用于嵌套字段。它还增加了请求的复杂性,最终会使维护和支持工作更具有挑战性。
将 FieldMask 添加到请求消息中
API 设计者可以在请求消息中添加 field_mask 字段,而不是创建一次性的“include”字段:
import "google/protobuf/field_mask.proto"; message GetProductionRequest { string production_id = 1; google.protobuf.FieldMask field_mask = 2; }消费者可以为他们希望在响应中接收的字段设置 paths。如果消费者只对制作的标题和格式感兴趣,他们可以设置一个 paths 字段中带有“title”和“format”的 FieldMask:
FieldMask fieldMask = FieldMask.newBuilder() .addPaths("title") .addPaths("format") .build(); GetProductionRequest request = GetProductionRequest.newBuilder() .setProductionId(LA_CASA_DE_PAPEL_PRODUCTION_ID) .setFieldMask(fieldMask) .build();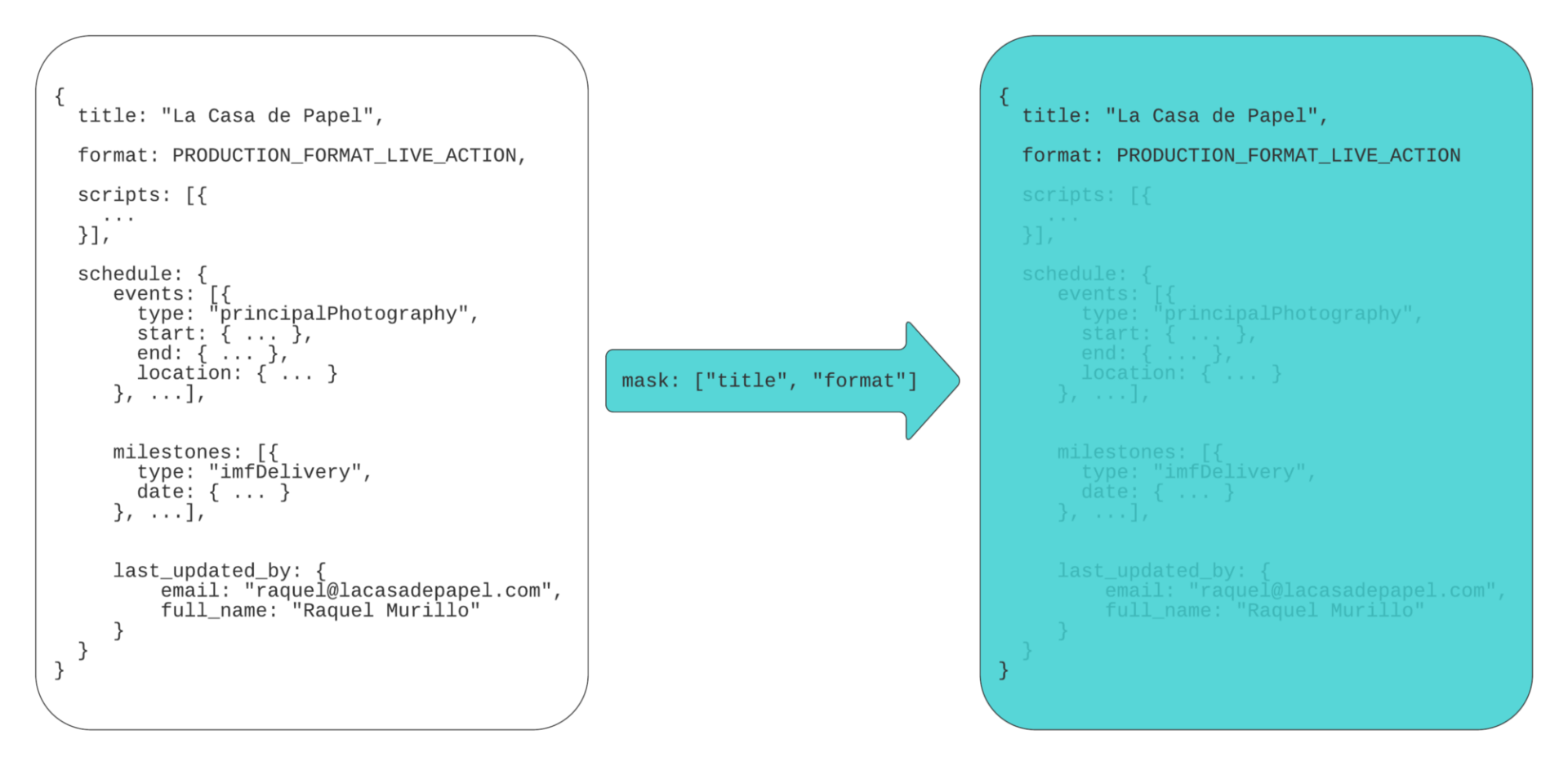
掩饰字段
请注意,尽管本文中的代码示例是用 Java 编写的,但所演示的概念也适用于 Protocol Buffers 所支持的其他任何语言。
如果消费者只需要上一个更新日程的人的标题和电子邮件,他们可以设置一个不同的字段掩码:
FieldMask fieldMask = FieldMask.newBuilder() .addPaths("title") .addPaths("schedule.last_updated_by.email") .build(); GetProductionRequest request = GetProductionRequest.newBuilder() .setProductionId(LA_CASA_DE_PAPEL_PRODUCTION_ID) .setFieldMask(fieldMask) .build();按照惯例,如果请求中不存在 FieldMask,则应该返回所有字段。
Protobuf 字段名称与字段编号
你可能已经注意到了,FieldMask 中的 paths 是使用字段名称指定的,而在网络连接上,编码的 Protocol Buffers 消息只包含了字段编号,而不包含字段名称。这(以及其他一些技术,如用于签名类型的 ZigZag 编码)能够使 protobuf 消息节省空间。
为了理解字段编号与字段名称之间的区别,让我们详细了解一下 protobuf 是如何编/解码消息的。
我们的 protobuf 消息定义(.proto 文件)包含了带有五个字段的制作消息。每个字段都有一个类型、名称和编号。
// 带有制作相关信息的消息 message Production { string id = 1; string title = 2; ProductionFormat format = 3; repeated ProductionScript scripts = 4; ProductionSchedule schedule = 5; }当 protobuf 编译器(protoc)编译这个消息定义时,它将使用你所选择的语言(在我们的示例中是 Java)创建代码。生成的代码包含了用于定义消息的类,以及消息和字段描述器。描述器包含了将消息编/解码为二进制格式所需的所有信息。例如,它们包含了字段编号、名称和类型。消息生成器使用描述器将消息转换为有线格式(Wire Format)。为了提高效率,二进制消息只包含了字段的数-值对,不包含字段名称。当使用者收到消息时,通过引用已编译的消息定义将字节流解码为对象(例如,Java 对象)。
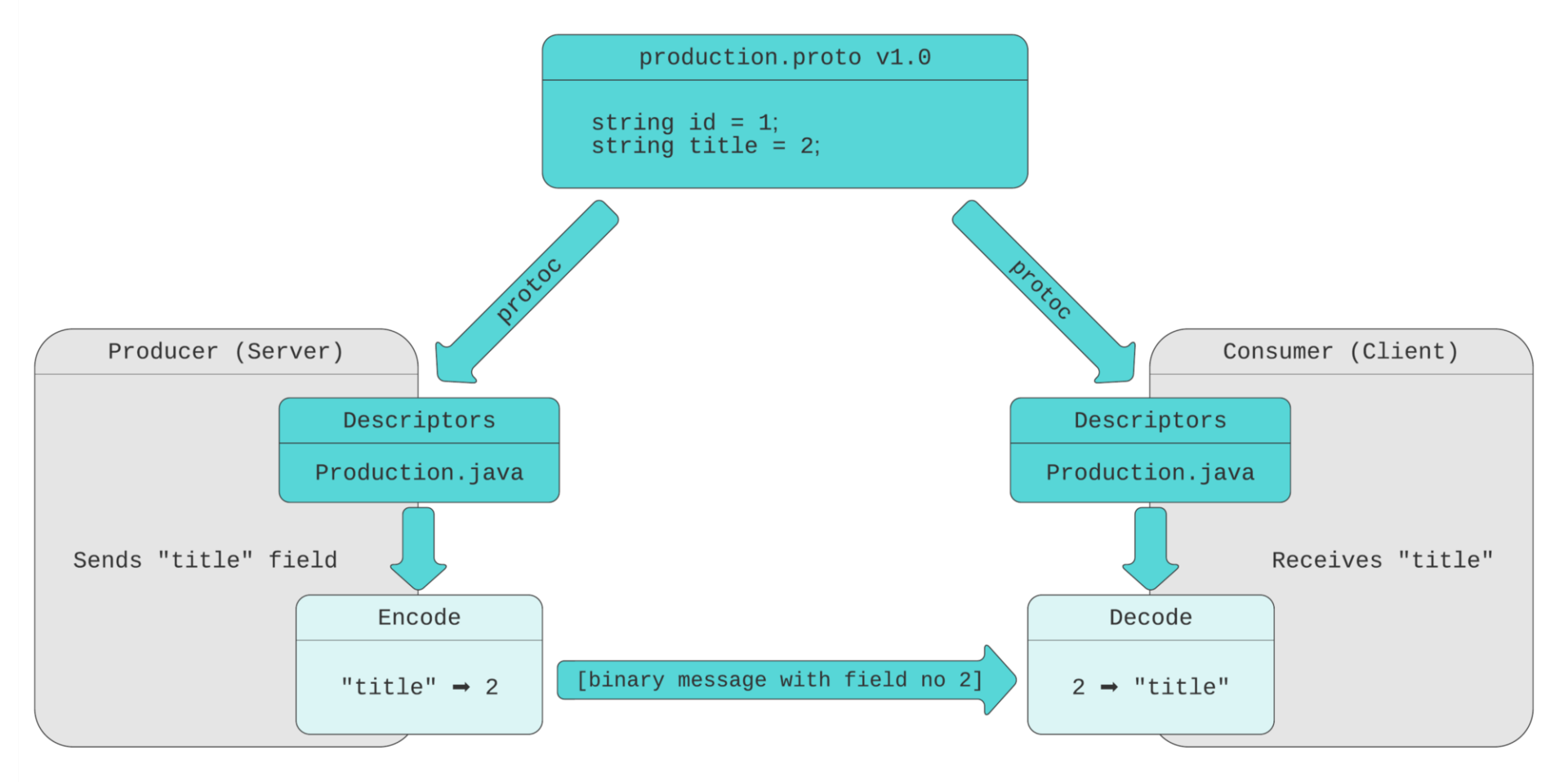
如上所述,FieldMask 列出的是字段名称,而不是编号。在 Netflix,我们使用的是字段编号,并使用 FieldMaskUtil.fromFieldNumbers()实用方法将它们转换为字段名称。该方法利用已编译的消息定义将字段编号转换为字段名称,并创建 FieldMask。
FieldMask fieldMask = FieldMaskUtil.fromFieldNumbers(Production.class, Production.TITLE_FIELD_NUMBER, Production.FORMAT_FIELD_NUMBER); GetProductionRequest request = GetProductionRequest.newBuilder() .setProductionId(LA_CASA_DE_PAPEL_PRODUCTION_ID) .setFieldMask(fieldMask) .build();但是,有一个很容易被忽略的限制:使用 FieldMask 会限制你重命名消息字段的能力。重命名消息字段通常被认为是一种安全的操作,因为如上所述,字段名称不是通过网络连接发送的,而是使用消费者端的字段编号派生的。而使用 FieldMask,字段名称需在消息的有效负载(在 paths 字段值中)中发送,并它变得重要了。
假设我们要将字段 title 重命名为 title_name ,并发布 2.0 版本的消息定义:
//2.0版本,title字段重命名为title_name string id = 1; string title_name = 2; // 这个字段以前是"title" ProductionFormat format = 3; repeated ProductionScript scripts = 4; ProductionSchedule schedule = 5; }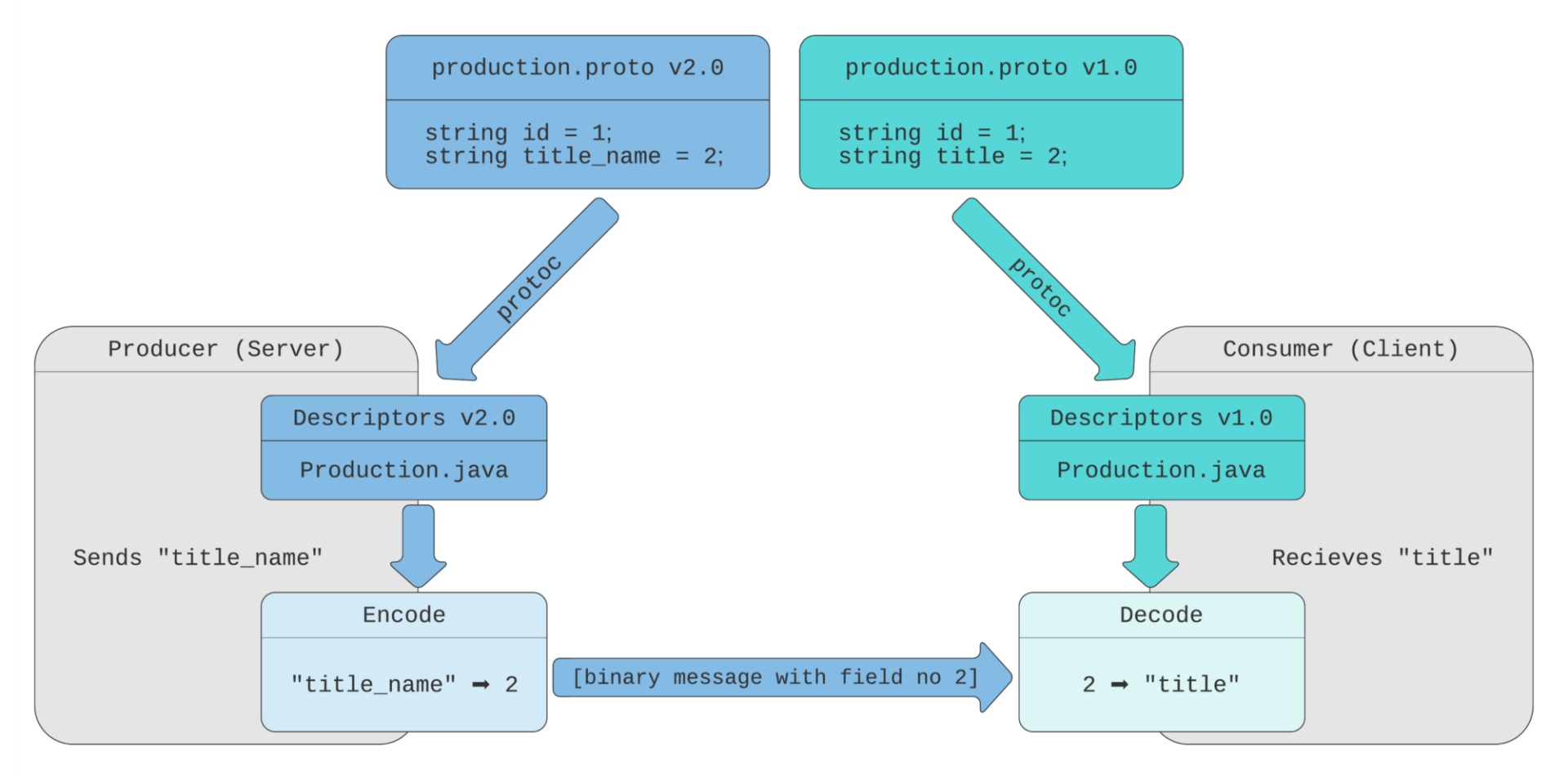
在这个图表中,生产者(服务器)使用了新的描述器,字段编号 2 被命名为 title_name 。通过网络发送的二进制消息包含了该字段编号及其值。消费者仍然使用原始的描述器,其中字段编号为 2 的名称是 title 。它仍然能够根据该字段编号对此消息进行解码。
如果消费者不使用 FieldMask 来请求字段,这种方法能够很好地工作。如果消费者使用 FieldMask 字段中的“title”path 来进行调用,生产者将无法找到该字段。生产者在其描述器中没有名为 title 的字段,因此它不知道消费者需要是编号为 2 的字段。
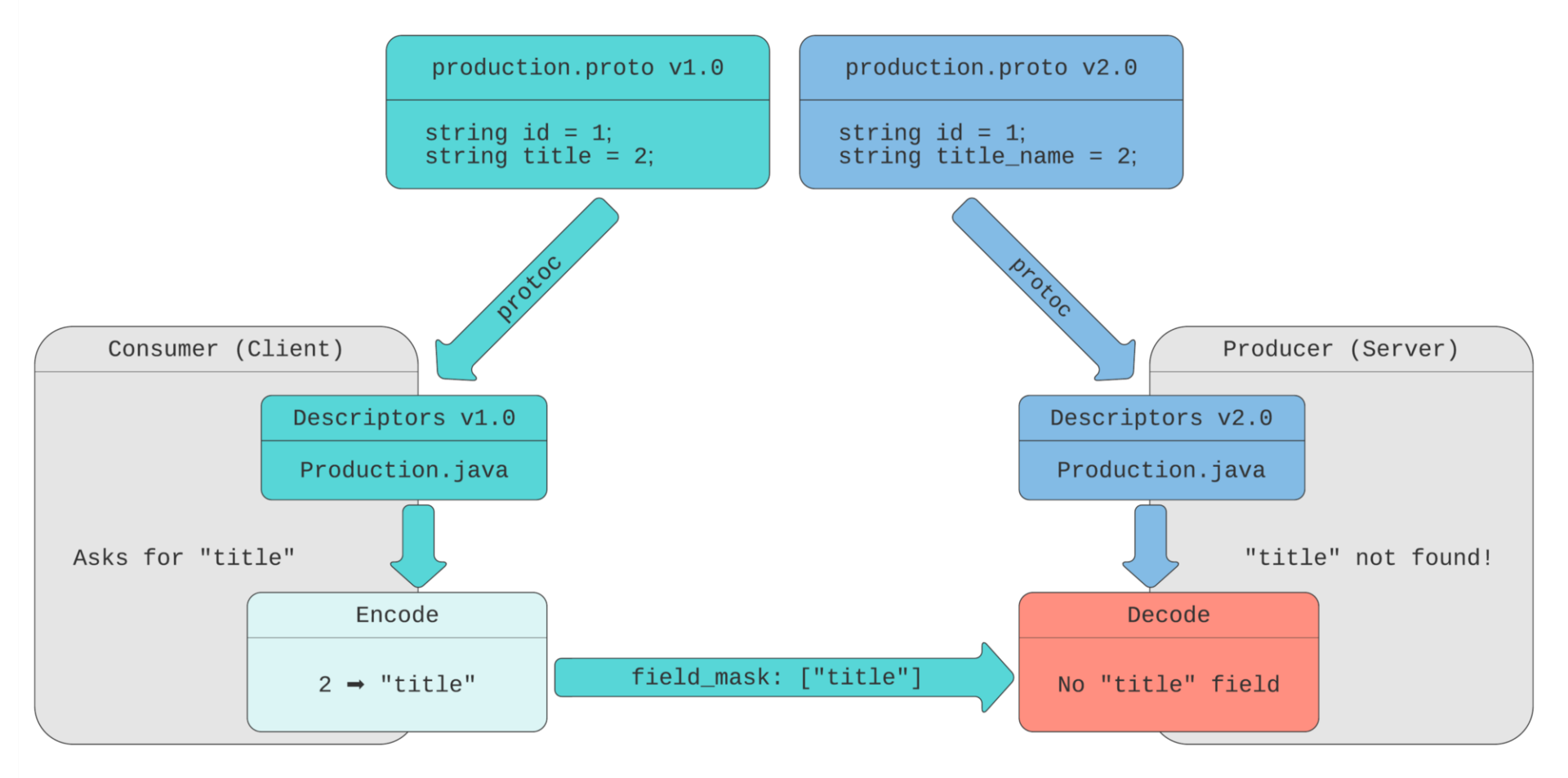
正如我们所看到的那样,如果某个字段被重命名了,后端应该能够同时支持新字段名和旧字段名,直到所有调用者都迁移到新字段名为止(向后兼容性问题)。
有多种方法可以解决这个限制:
使用 FieldMask 时,永远不要重命名字段。这是最简单的解决方案,但这并非总是可行;
要求后端支持所有的旧字段名称。 这解决了向后兼容性的问题,但需要在后端使用额外的代码来跟踪所有的历史字段名称;
弃用旧字段并创建新字段,而不是重命名。在我们的示例中,我们将创建一个字段编号为 6 的 title_name 字段。与前一个选项相比,该选项有一些优点:它允许生产者继续使用已生成的描述器,而不是自定义转换器;此外,弃用某个字段会使其在消费者侧更加突出。
message Production { string id = 1; string title = 2 [deprecated = true]; // use "title_name" field instead ProductionFormat format = 3; repeated ProductionScript scripts = 4; ProductionSchedule schedule = 5; string title_name = 6; }无论采用哪种解决方案,重要的是要记住 FieldMask 使字段名称成为了 API 契约中不可或缺的一个组成部分。
在生产者(服务器)端使用 FieldMask
在生产者(服务器)端,可以使用 FieldMaskUtil.merge()方法(第 8 行和第 9 行)从响应负载中删除不必要的字段:
@Override public void getProduction(GetProductionRequest request, StreamObserver<GetProductionResponse> response) { Production production = fetchProduction(request.getProductionId()); FieldMask fieldMask = request.getFieldMask(); Production.Builder productionWithMaskedFields = Production.newBuilder(); FieldMaskUtil.merge(fieldMask, production, productionWithMaskedFields); GetProductionResponse response = GetProductionResponse.newBuilder() .setProduction(productionWithMaskedFields).build(); responseObserver.onNext(response); responseObserver.onCompleted(); }如果服务器代码还需要知道请求了哪些字段,以避免进行外部调用、数据库查询或昂贵的计算,则可以从 FieldMask 路径字段获取该信息:
private static final String FIELD_SEPARATOR_REGEX = "\\."; private static final String MAX_FIELD_NESTING = 2; private static final String SCHEDULE_FIELD_NAME = // (1) Production.getDescriptor() .findFieldByNumber(Production.SCHEDULE_FIELD_NUMBER).getName(); @Override public void getProduction(GetProductionRequest request, StreamObserver<GetProductionResponse> response) { FieldMask canonicalFieldMask = FieldMaskUtil.normalize(request.getFieldMask()); // (2) boolean scheduleFieldRequested = // (3) canonicalFieldMask.getPathsList().stream() .map(path -> path.split(FIELD_SEPARATOR_REGEX, MAX_FIELD_NESTING)[0]) .anyMatch(SCHEDULE_FIELD_NAME::equals); if (scheduleFieldRequested) { ProductionSchedule schedule = makeExpensiveCallToScheduleService(request.getProductionId()); // (4) ... } ... }这段代码只有在请求 schedule 字段时,才会调用 makeExpensiveCallToScheduleServicemethod (第 21 行)。让我们来更详细地研究一下这个代码示例。
(1) SCHEDULE_FIELD_NAME 常量包含了字段名称。该代码示例使用消息类型描述器(Descriptor )和字段描述器(FieldDescriptor)按字段编号查找字段名称。protobuf 字段名称与字段编号之间的差异在上面的“Protobuf 字段名称与字段编号”部分已经描述过了。
(2)FieldMaskUtil.normalize()返回按字母顺序排序并去重了的 paths 字段(也称为规范形式)的 FieldMask。
(3)生成 scheduleFieldRequestedvalue 的表达式(第 14-17 行)接受 FieldMask paths 流,将其映射到顶层字段流中,如果顶层字段包含 SCHEDULE_FIELD_NAME 常量的值,则返回 true 。
(4)仅当 scheduleFieldRequested 为 true 时,才会检索 ProductionSchedule 。
如果最终要针对不同的消息和字段使用 FieldMask,请考虑创建可重用的实用工具助手方法。例如,基于 FieldMask 和 FieldDescriptor 返回所有顶层字段的方法、如果字段存在于 FieldMask 中则返回的方法,等等。
提供预构建的 FieldMask
某些访问模式可能比其他访问模式更常见。如果多个消费者对同一个字段子集感兴趣,API 生产者可以为最常用的字段组合提供带有 FieldMask 的客户端库。
public class ProductionFieldMasks { /** * 可以在{@link GetProductionRequest}中查询 * 制作的标题和格式 */ public static final FieldMask TITLE_AND_FORMAT_FIELD_MASK = FieldMaskUtil.fromFieldNumbers(Production.class, Production.TITLE_FIELD_NUMBER, Production.FORMAT_FIELD_NUMBER); /** * 可以在{@link GetProductionRequest}中查询 * 制作的标题和日程排期 */ public static final FieldMask TITLE_AND_SCHEDULE_FIELD_MASK = FieldMaskUtil.fromFieldNumbers(Production.class, Production.TITLE_FIELD_NUMBER, Production.SCHEDULE_FIELD_NUMBER); /** * 可以在{@link GetProductionRequest} 中查询 * 制作的标题和脚本 */ public static final FieldMask TITLE_AND_SCRIPTS_FIELD_MASK = FieldMaskUtil.fromFieldNumbers(Production.class, Production.TITLE_FIELD_NUMBER, Production.SCRIPTS_FIELD_NUMBER); }提供预构建的 FieldMask 简化了大多数常见场景的 API 使用,并使消费者能够灵活地为更具体的用例构建自己的字段掩码。
局限性
使用 FieldMask 可能会限制你重命名消息字段的能力(在 Protobuf 字段名称与字段编号部分中已经介绍过了)
重复字段只允许出现在 path 字符串的最后一个位置上。 这意味着你不能在列表消息中选择(屏蔽)单个子字段。在可预见的未来,这种情况可能会改变,因为最近获批的谷歌 API 改进提案 AIP-161 字段掩码包括了对重复字段的通配符支持。
结束语
Protobuf FieldMask 是一个简单但功能强大的概念。它有助于使 API 更健壮、服务实现更高效。
这篇博文介绍了 Netflix Studio Engineering 是如何以及为什么将其用于数据读取的 API。第 2 部分将介绍如何使用 FieldMask 来进行更新和删除操作。




