
近日,清华大学与面壁智能团队提出了 Delta Compression(Delta 压缩)技术,它通过存储主干模型与任务专用模型之间的参数差值,显著降低了模型对显卡的存储需求。在此基础上,团队进一步结合低秩分解与低比特量化,提出混合精度压缩方法 Delta-CoMe。该方法在几乎不损失任务性能(如数学推理、代码生成和多模态任务)的前提下,大幅提升了模型推理效率,从而实现一块 80G A100 GPU 无损性能加载多达 50 个 7B 模型。
相比于传统的微调方法,Delta-CoMe 展现出了更高的效率和灵活性,该技术有效改善了不同应用场景对模型进行微调时的计算与存储开销难题,为终端设备带来了轻量化的大模型推理能力,同时为大模型在多任务、多租户、端侧场景的模型部署提供了全新的低成本、高效率解决方案。
下一步,或许我们正在迈向一个“模型共享”而非“模型堆叠”的时代,让每个参数都发挥最大效能,让每台设备都能加载无限可能。

➤ 论文链接:🔗 https://arxiv.org/abs/2406.08903
➤ GitHub 地址:🔗__https://github.com/thunlp/Delta-CoMe
Delta-CoMe 方法介绍
微调是增强预训练模型的重要手段,不同任务往往需要不同的微调方式。例如 Luo et al.[1] 提出 RLEIF 通过 Evove-instruction 来增强模型数学推理能力;Wei et al.[2] 利用 Code snnipet 合成高质量的指令数据来增加模型的代码能力。然而,这些方法通常依赖高质量数据,并需要精心设计的策略才能实现显著的效果。在一些场景中往往需要具有不同能力的 LLM 同时处理问题,例如多租户场景、多任务场景以及端侧场景等等。
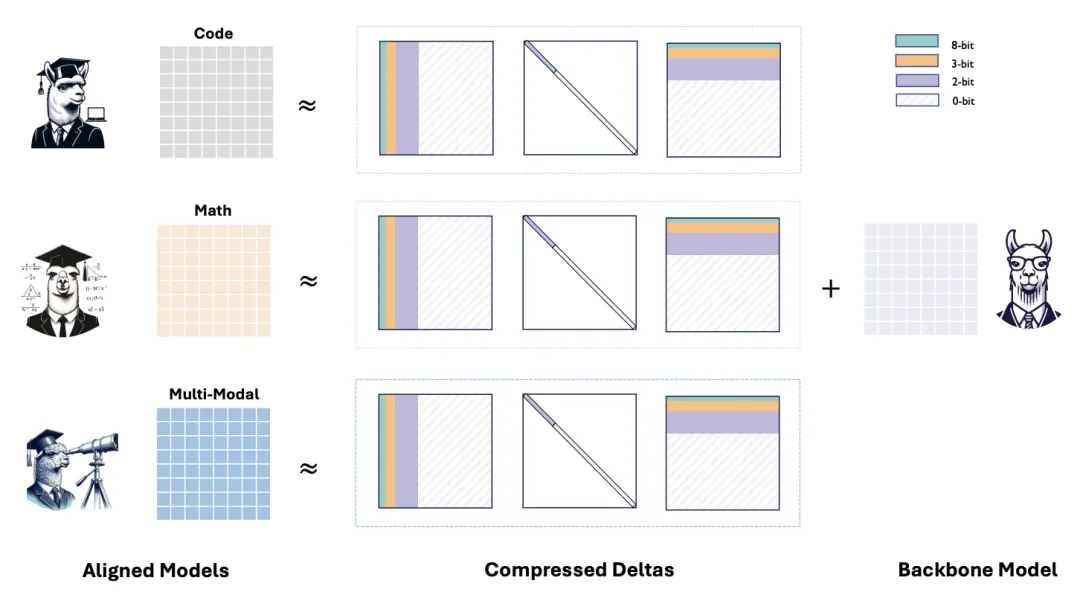
一种自然的解决方案是部署单个通用模型,以及多个具有专有能力的 Delta。以 Bitdelta[3] 为例,它通过将模型的 Delta 压缩到 1bit,有效保留了模型在日常对话场景中的基本功能。尽管压缩方法在存储和推理效率上表现出色,其在更复杂的任务(如数学推理和代码生成)上仍存在明显的能力瓶颈。针对这一挑战,清华 NLP 实验室联合北京大学和上海财经大学提出 Delta-CoMe。这一方法结合低秩和低比特量化技术,不仅显著提升了模型在复杂任务上的表现,还兼顾了压缩效率和实际应用需求,为模型的高效部署提供了一种新思路。
与前人的方法相比,Delta-CoMe 方法的优点在于:
结合低秩与低比特量化,利用了 Delta 低秩的特点,并发现低秩分解后的 Delta 是长尾分布的;之后采用混合精度量化进一步节省;
性能几乎无损,相比于 Bitdelta 等方法,在 math,code,Multi-modal 等复杂任务上,性能与原始模型表现基本接近;
推理速度提升,实现了 Triton kernel 对比 Pytorch 实现方式,带来近 3x 的推理速度提升;
超过 Delta-tuning 支持多精度 Backbone,Delta-CoMe 显著优于 Delta-tuning 并可以用在多种精度的 Backbone 上。
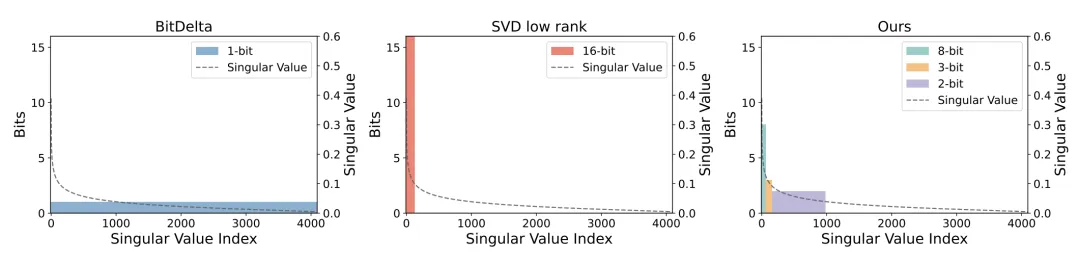
Delta-CoMe 首先采用 SVD 进行低秩分解,Delta 具有低秩性,秩降低到原来的 1/8 性能基本保持不变。经过低秩分解之后,我们发现奇异向量是长尾分布的,较大奇异向量对最终的结果贡献较大。一个自然的想法,我们可以根据奇异向量大小进行混合精度量化,将较大的奇异值对应的奇异向量用较高精度表示。
实验结果
多个开源模型和 Benchmark 的实验验证了该方法的有效性。

使用 Llama-2-7B 作为主干模型,在数学、代码、对话、多模态等多个任务中进行实验,Delta-CoMe 展现出平均几乎无损的性能。
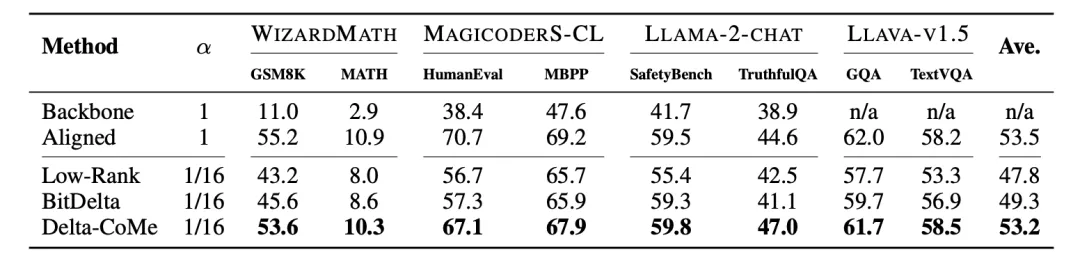
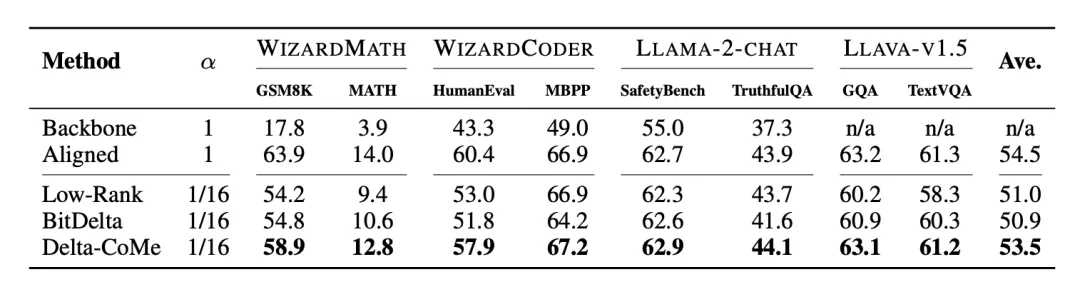
此外,实验还在 Mistral、Llama-3 等其它主干模型上进行验证。
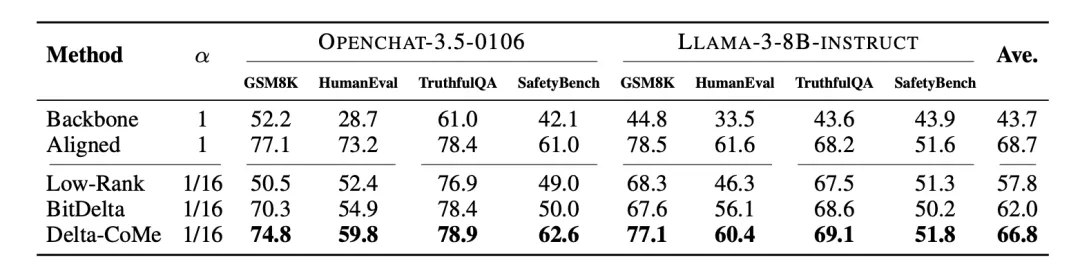
通过实现 Triton kernel,相比于 Pytorch 的实现方式,推理速度提升了约 3 倍。
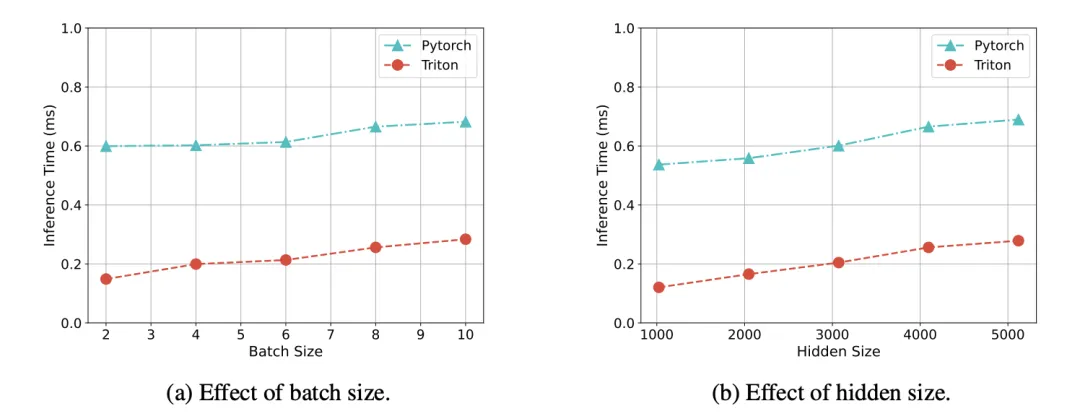
实验结果表明,使用一块 80G 的 A100 GPU 可以加载 50 个 7B 模型。
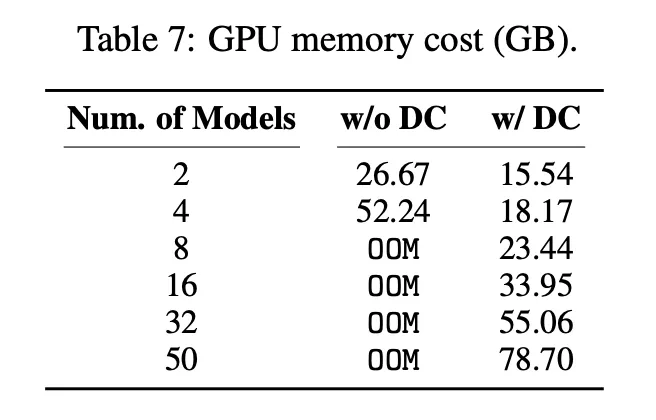
Delta-CoMe 对比 Delta-tuning 在相同的存储开销下,性能显著提升。
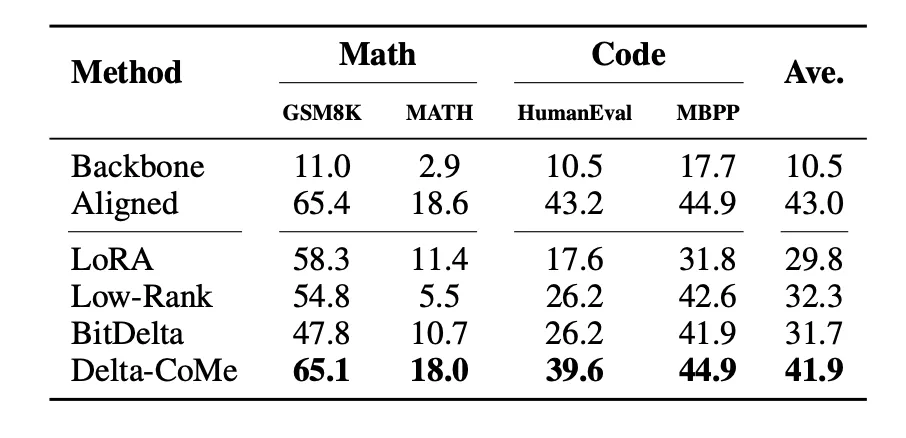
总结
Delta-CoMe 通过结合低秩分解和低比特量化,不仅实现了大幅度的存储压缩,还在复杂任务如数学推理、代码生成和多模态任务上维持了与原始模型相当的性能表现。相比于传统的微调方法,Delta-CoMe 展现出了更高的效率和灵活性,尤其在多租户和多任务场景中具有显著的应用价值。此外,借助 Triton kernel 的优化,推理速度得到了显著提升,使得部署大规模模型成为可能。未来,这一方法的潜力不仅在于进一步优化模型存储和推理速度,也有望在更广泛的实际应用中推动大语言模型的普及和高效运作。
参考文献
[1]Yu, L., Jiang, W., Shi, H., Jincheng, Y., Liu, Z., Zhang, Y., Kwok, J., Li, Z., Weller, A., and Liu, W.Metamath: Bootstrap your own mathematical questions for large language models. In The Twelfth International Conference on Learning Representations, 2023.
[2] Luo, Z., Xu, C., Zhao, P., Sun, Q., Geng, X., Hu, W., Tao, C., Ma, J., Lin, Q., and Jiang, D. Wizardcoder: Empowering code large language models with evol-instruct. arXiv preprint arXiv:2306.08568, 2023b
[3] Liu, J., Xiao, G., Li, K., Lee, J. D., Han, S., Dao, T., and Cai, T. Bitdelta: Your fine-tune may only be worth one bit. arXiv preprint arXiv:2402.10193, 2024b.




