
导读:虚拟网络中存在部分黑产用户,这部分用户通过违法犯罪等不正当的方式去谋取利益。作为恶意内容生产的源头,管控相关黑产用户可以保障各业务健康平稳运行。当前工业界与学术界的许多组织通常采用树形模型、社区划分等方式挖掘黑产用户,但树形模型、社区划分的方式存在一定短板,为了更好地挖掘黑产用户,我们通过图表征学习与聚类相结合的方式进行挖掘。本文将为大家介绍图算法在网络黑产挖掘中的思考与应用,主要介绍:
图算法设计的背景及目标
图算法 GraphSAGE 落地及优化
孤立点 &异质性
总结思考
图算法设计的背景及目标
1. 图算法设计的背景
在虚拟网络中存在部分的黑产用户,这部分用户通过违法犯罪等不正当的方式去谋取利益,比如招嫖、色情宣传、赌博宣传的行为,更有甚者,如毒品、枪支贩卖等严重的犯罪行为。当前工业界与学术界的许多组织推出了基于图像文字等内容方面的 API 以及解决方案。而本次主题则是介绍基于账号层面上的解决方法,为什么需要在账号层面对网络黑产的账号进行挖掘呢?

原因主要有三:
① 恶意账号是网络黑产的源头,在账号层面对网络黑产的账号进行挖掘可以对黑产的源头进行精准地打击;
② 账号行为对抗门槛高,用户的行为习惯以及关系网络是很难在短期内作出改变的,而针对单一的黑产内容可以通过多种方式避免被现有的算法所感知,虽然黑产用户可能不懂算法,但其可以通过“接地气”的方式来干扰算法模型,譬如在图片上进行简单的涂抹,在敏感处打上马赛克,在图片处加上黑框,通过简单的对抗手段会对基于黑产内容的算法产生较大的影响;
③ 可以防范于未然,通过账号层面的关联提前圈定可疑账号,在其进行违法犯罪行为之前对账号进行相应的处理以及管控。
具体通过什么方式挖掘黑产账号?
首先,简单介绍下在推荐场景中应用。比如广告推荐,通常上,广告商会给予平台方用户的用户标签,用户存在用户标签之后,平台方则会将相关类别的用户找出,然后将广告推送给对应的用户;另一种方式是广告方提供种子包给平台方,平台方会找到相似的用户,然后将广告推送给相关的用户,常见的应用场景有 Facebook look like、Google similar audiences。
在黑产场景中与推荐场景中的应用类似,主要分为两个任务场景:
① 找出目标恶意类别用户。比如需要找出散播招嫖信息的用户,则给定该类用户招嫖的标签,类似于一个用户定性的问题;
② 黑产种子用户扩散,即利用历史的黑产用户进行用户扩散以及用户召回,可以通过染色扩散以及相似用户检索等方式完成。
针对恶意用户定性的传统方法,通常采用树形模型,比如说 XGboost、GBDT 等。这类算法短板显而易见,其缺乏对用户之间的关联进行考虑;另外一种用户召回方式为用户社区划分(相似用户召回),其中比较常用的社区划分算法有 FastUnfolding、Copra 等。这类算法的缺陷也相当明显,其由于原本社区规模小,所以最终召回的人数也少。且会存在多个种子用户在同一个社区的情况,难以召回大量可疑用户。
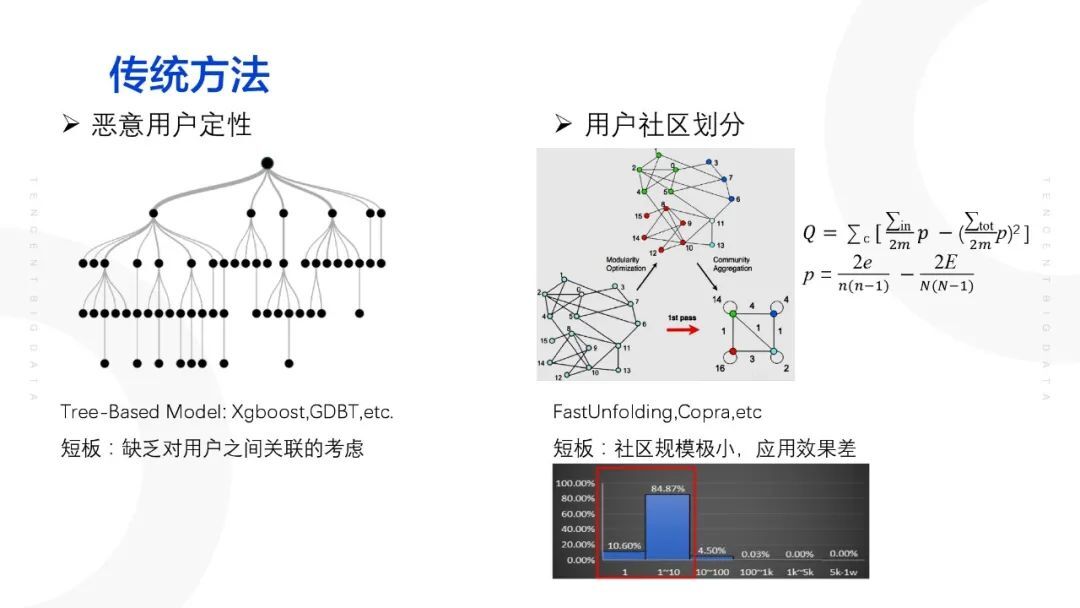
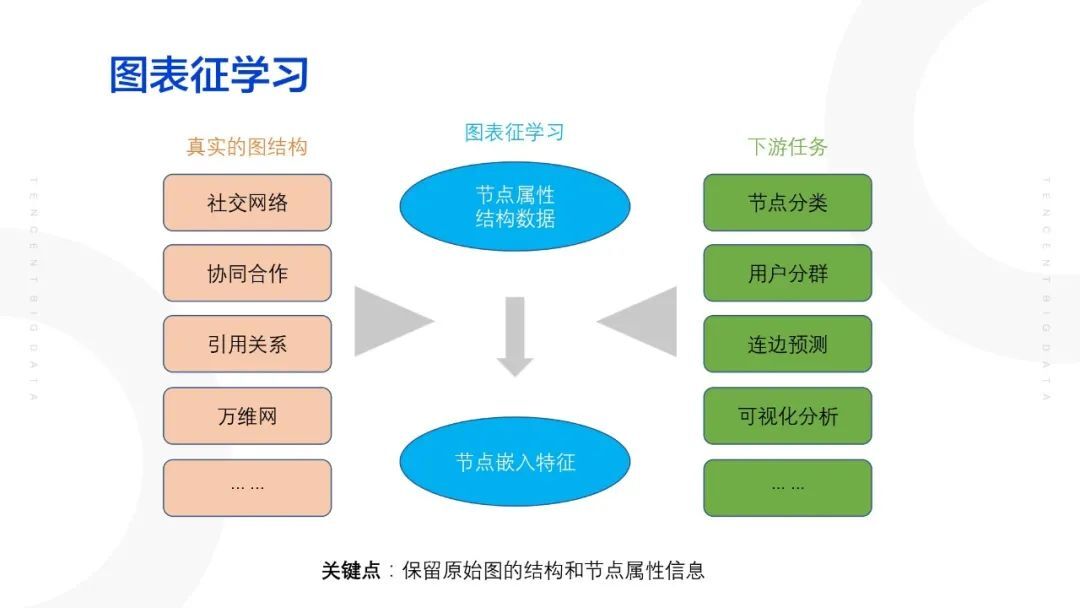
因此,通过图表征学习与聚类相结合的方式进行召回。通过图表征学习将图结构的节点属性以及结构特征映射到一个节点低维空间,由此产生一个节点特征,然后再去进行下游的任务,如用户定性即节点分类等。其中,图表征学习的关键点在于在进行低维的映射当中需要保留原始图的结构和节点属性信息。
2. 图算法设计的目标
① 算法的覆盖率和精准度;
② 用户分群规模合理,保证分群的可用性;
③ 支持增量特征,下游任务易用性。
由于业务场景更多为动态网络,当新增节点时,如果模型支持增量特征,则不需要重复训练模型,可以极大的减少开发的流程,节省机器学习的资源,缩短任务完成的时间。
图算法 GraphSAGE 落地及优化
1. GraphSAGE 核心思想
GraphSAGE 核心思想主要为两点:邻居抽样;特征聚合。
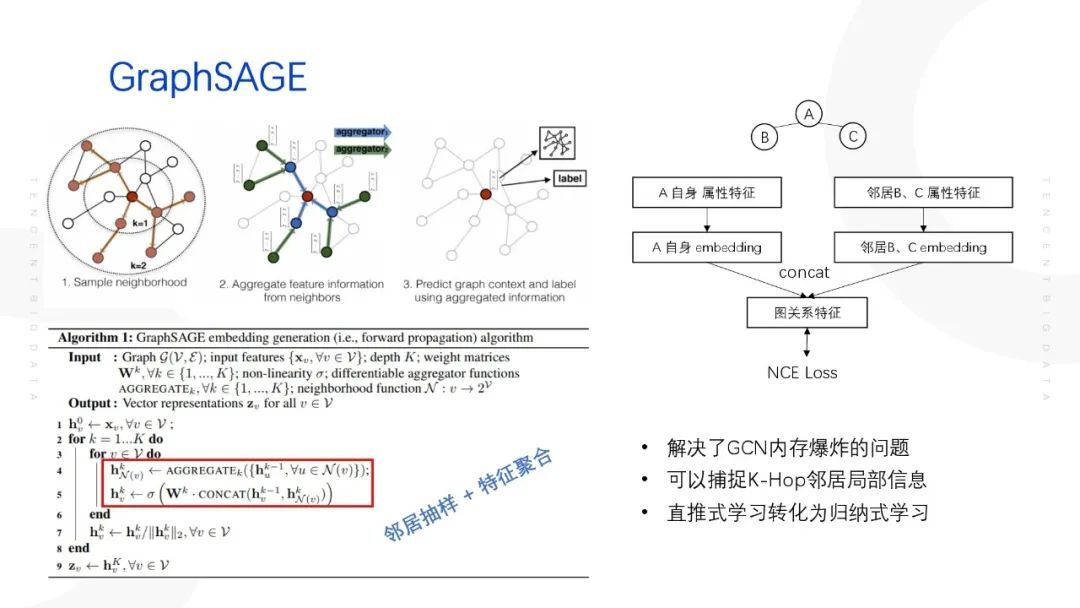
GraphSAGE 的聚合过程实际是节点自身的属性特征和其抽样的邻居节点特征分别做一次线性变换,然后将两者 concat 在一起,再进行一次线性变换得到目标节点的 embedding 特征。最后利用得到的目标节点的 embedding 特征进行下游的任务,训练的方式的可以采用无监督的方式,如 NCE Loss。
2. GraphSAGE 的优点
GraphSAGE 通过邻居抽样的方式解决了 GCN 内存爆炸的问题,同时可以将直推式学习转化为归纳式学习,避免了节点的 embedding 特征每一次都需要重新训练的情况,支持了增量特征。为什么通过邻居随机抽样就可以使得直推式的模型变为支持增量特征的归纳式模型呢?在原始的 GraphSAGE 模型(直推式模型)当中,节点标签皆仅对应一种局部结构、一种 embedding 特征。在 GraphSAGE 引入邻居随机抽样之后,节点标签则变为对应多种局部结构、多种 embedding 特征,这样可以防止模型在训练过程过拟合,增强模型的泛化能力,则可以支持增量特征。
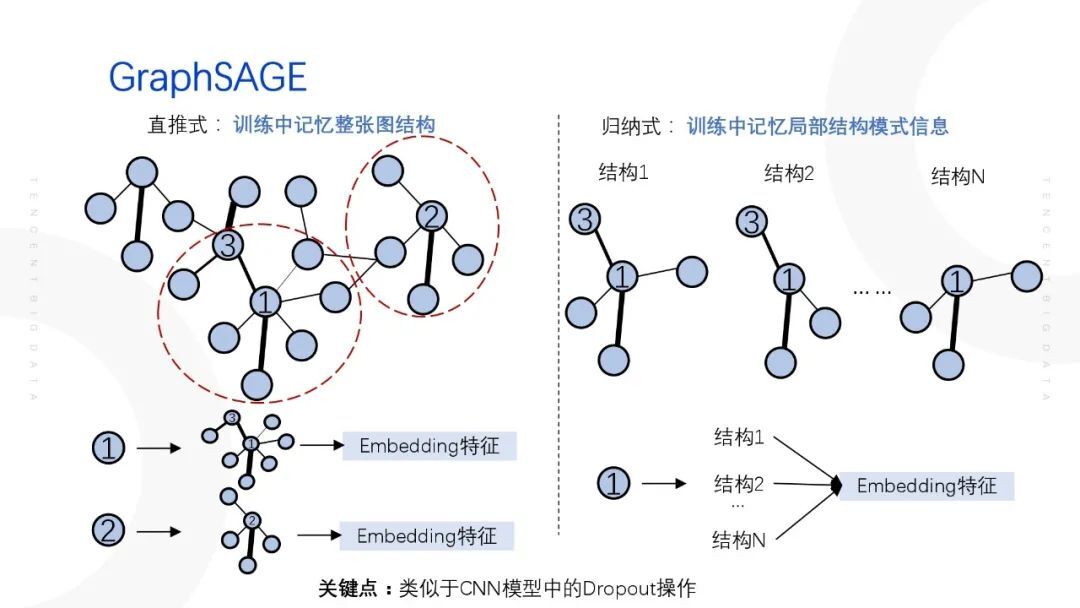
3. GraphSAGE 的缺点
① 原 GraphSAGE 无法处理加权图,仅能够邻居节点等权聚合;
② 抽样引入随机过程,推理过程中同一节点 embedding 特征不稳定;
③ 抽样数目限制会导致部分局部信息丢失;
④ GCN 网络层太多容易引起训练中过度平滑问题。
4. GraphSAGE 的优化
为解决上述 GraphSAGE 存在的缺点,对 GraphSAGE 进行优化。
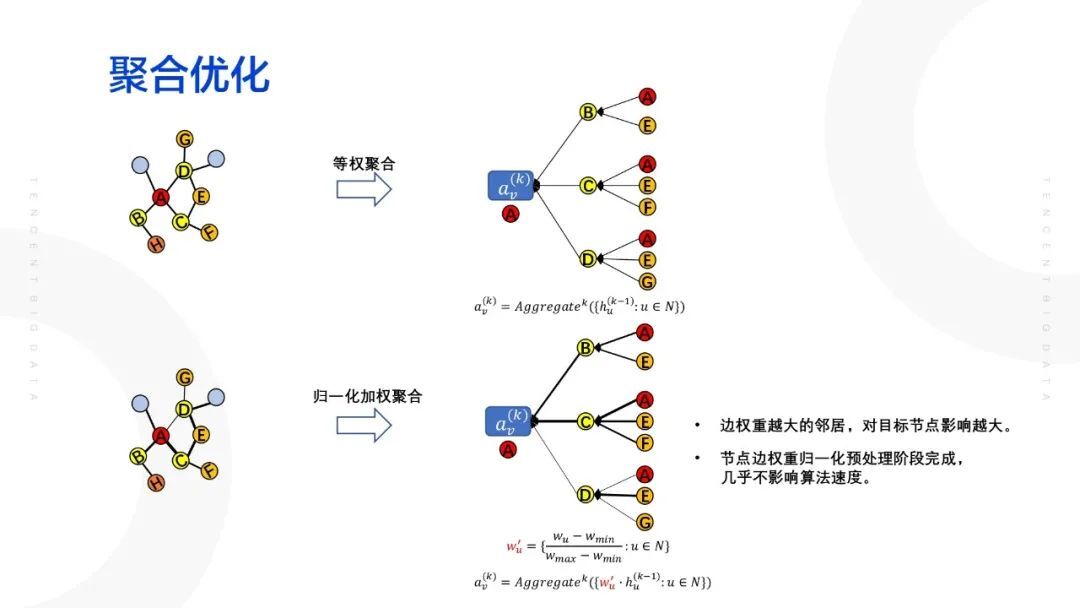
① 聚合优化
解决等权聚合的问题。相对于直接将邻居节点进行聚合,将边权重进行归一化之后,点的邻居节点的特征进行点燃,最后再进行特征融合。这样做的好处主要有两点:边权重越大的邻居,对目标节点影响越大;节点边权重归一化在预处理阶段完成,几再与目标节乎不影响算法速度。
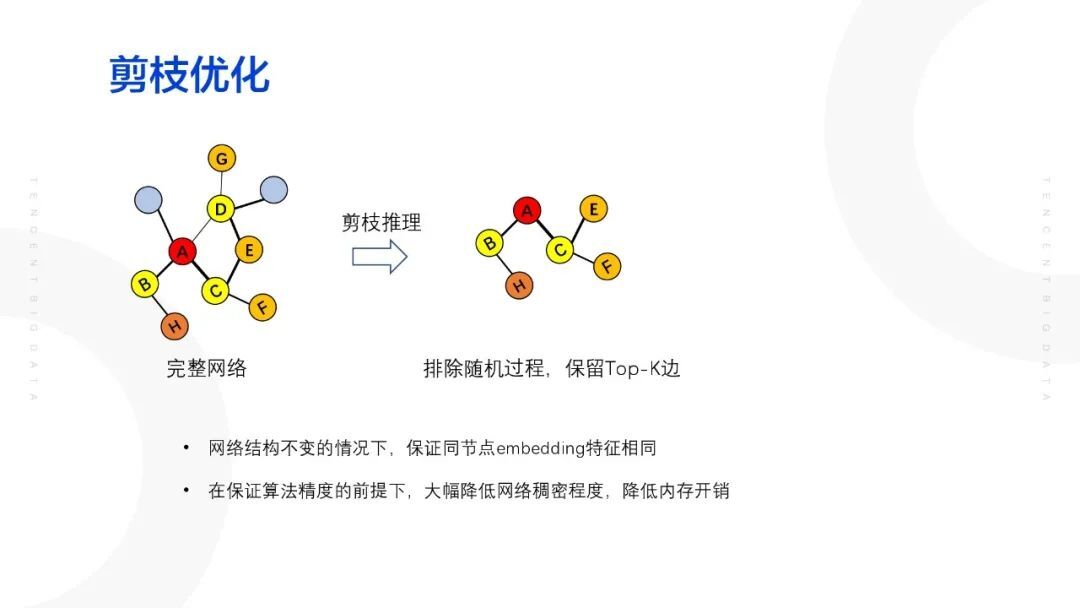
② 剪枝优化
解决 embedding 特征不稳定的问题。在训练的过程希望通过引入随机过程防止模型出现过拟合的现象,但是在模型的推理过程式是想要去掉这样一个随机过程。直接对原始网络进行剪枝操作,仅保留每个节点权重最大的 K 条边,在模型进行推理的时候,会将目标节点所有的 K 个邻居节点的特征都聚合到目标节点上,聚合方式同样为加权的方式。这样做的好处主要有两个点:在网络结构不变的情况下,保证同节点 embedding 特征相同;在保证算法精度的前提下,大幅度降低图的稠密程度,降低内存开销。
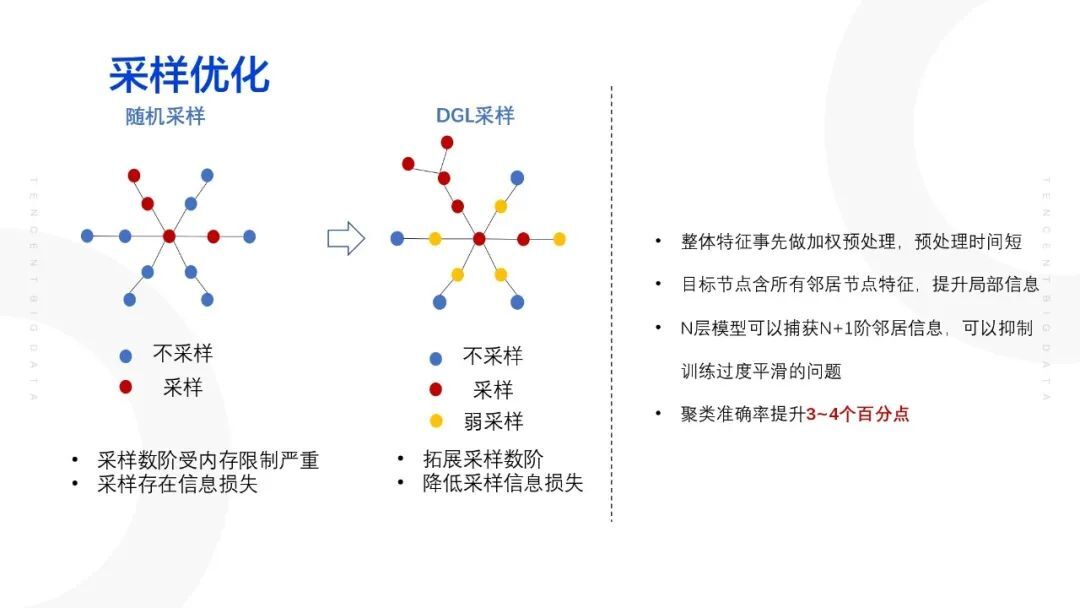
③ 采样优化
解决局部信息丢失以及训练过平滑的问题。主要通过 DGL 的抽样方式代替原有的抽样方式,具体的做法为:提前将每一个节点的属性特征与它所有的邻居节点的属性特征的均值进行 concat,这样可以使得每一个节点初始状态下已经包含了周围一些邻居节点的一些信息,通过这种方式,在采样相同节点的前提下,可以获得更多的局部信息。一般情况下,GCN 模型采用两层网络模型,当增加至第三层的时候则将存在内存爆炸的问题;当增加至第四层时,则将出现过平滑的问题,将导致特征分布去重,这样则导致节点没有区分性。而采用 DGL 采样,通过采样两层 GCN 模型而实际上采样了三层,而且不会出现过平滑问题。
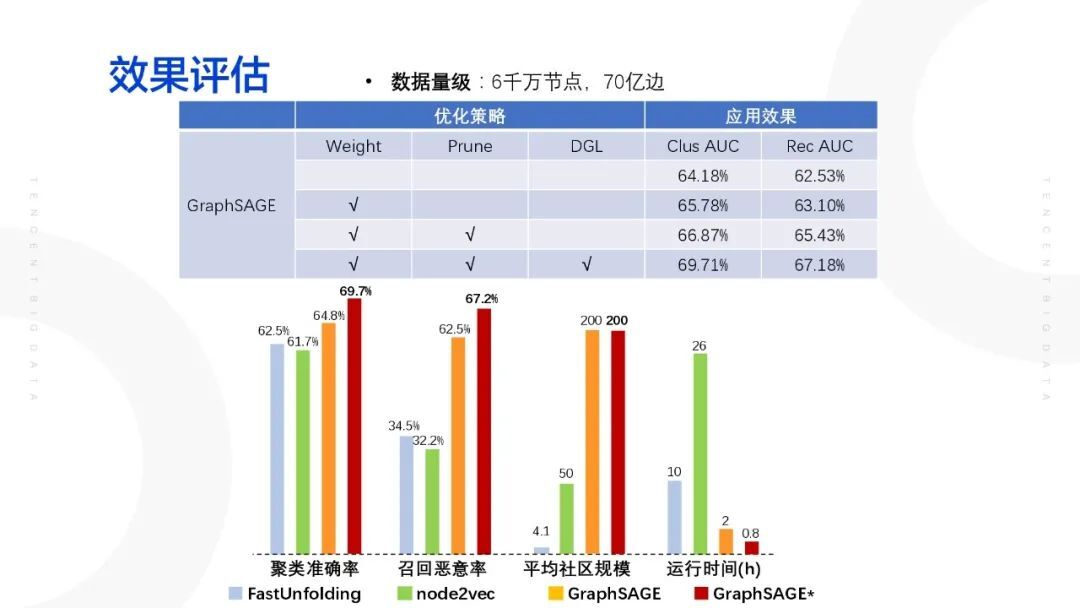
5. 效果评估
效果评估的指标主要有两个:聚类(社区)准确率;召回恶意率。相对于原有的 fastunfolding 以及 node2vec 从聚类准确率、召回恶意率、平均社区规模、运行时间作一个横向对比:
孤立点 &异质性
1. 黑产挖掘场景中的孤立点的解决思路
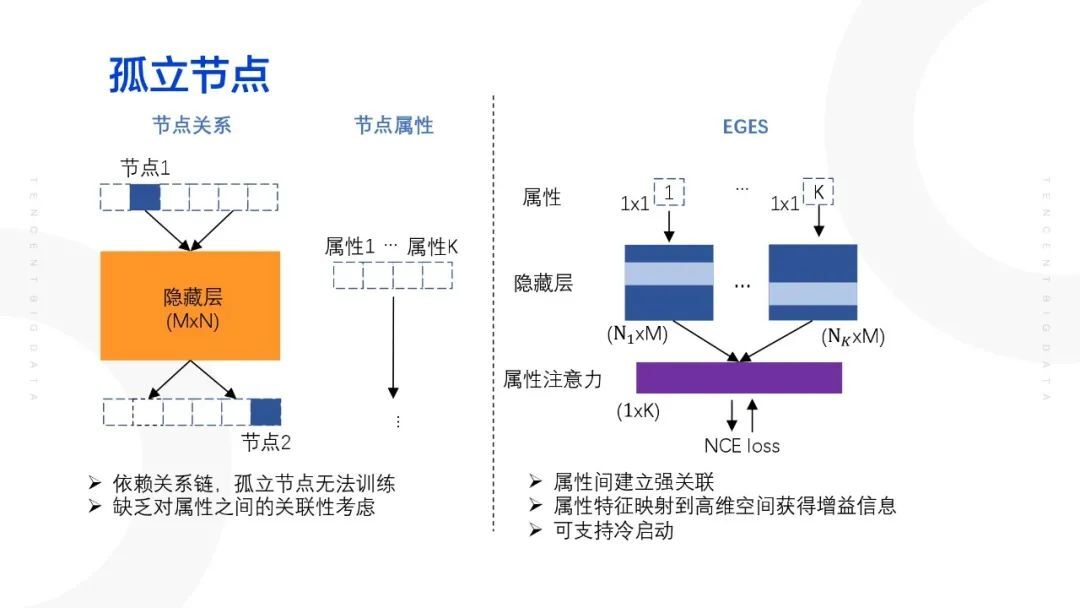
黑产用户在被处理后,通常会快速地申请新的账号或使用备用账号,因为在对黑产的挖掘过程中就不可避免地会出现孤立点,类似在推荐算法中的冷启动问题。以 node2vec 算法为例,算法通常会通过游走去构造训练的节点段,那么如果孤立节点没有连边的话,节点是无法出现在训练集当中。为了解决该问题,引入一个解决推荐系统冷启动的算法——EGES,将每一个节点的属性特征映射到一个 embedding 特征,然后将每一个属性的 embedding 特征置于注意力层进行处理,比如将 N 个随机特征通过注意力加权,可以获得最终的一个节点层面的 embedding 特征,新增的节点将不再依赖于关系网络以及用户的一些交互行为,新增的节点可以通过自身的属性特征就直接获得我们的 embedding 特征,不需要考虑用户关系从而解决孤立点的问题。
在具体落地过程中,提出了 GraphSAGE-EGES 算法,实际上是综合了两种算法的优势,GraphSAGE 的节点本身的初始特征将其替换成了 EGES 增强之后的属性特征,通过此类方式,最终的算法框架如下图所示:
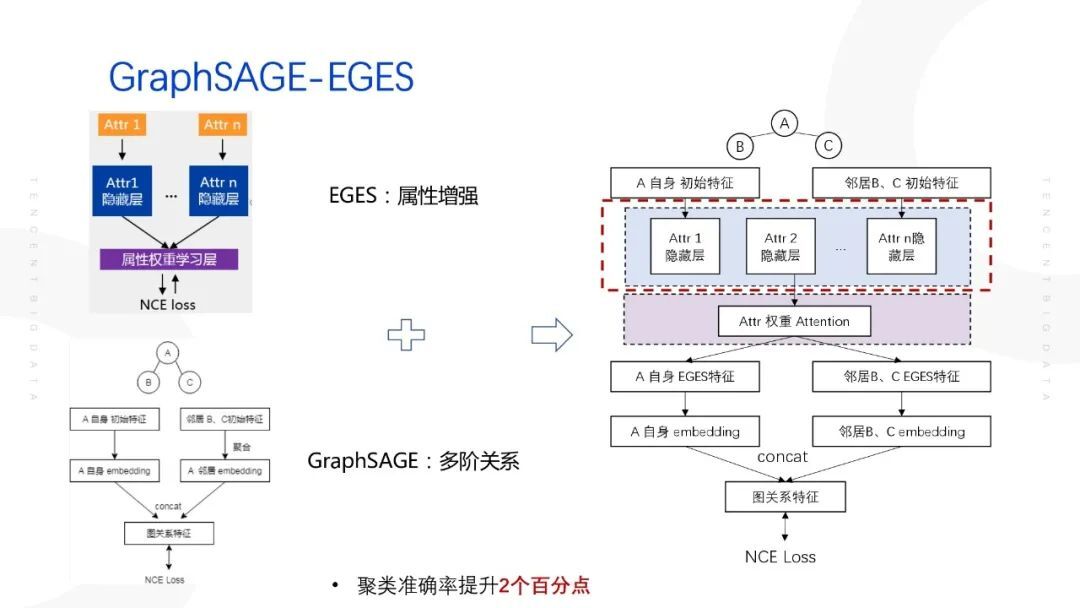
此类算法可以提升聚类准确率 2 个百分点。
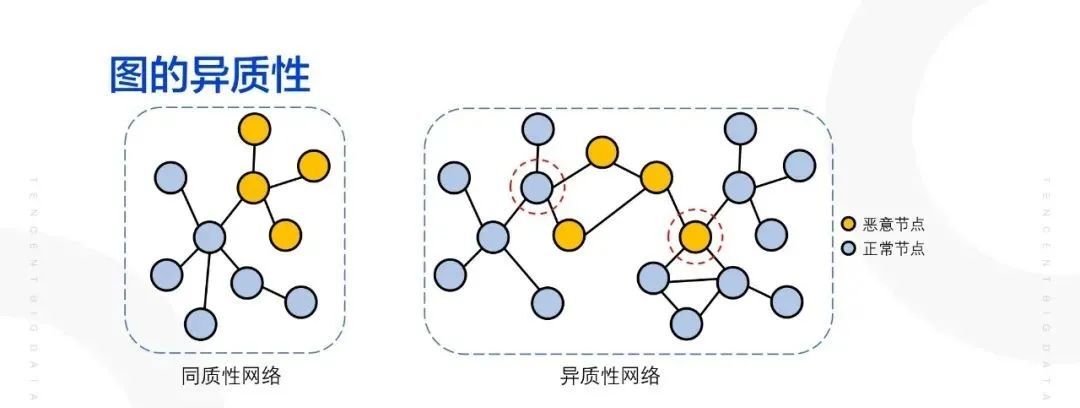
2. 黑产网络中异质性的解决思路
在正常的网络结构当中,一个用户的一阶邻居基本上都是同一类的用户,比如说在学术引用当中,一篇数据挖掘的论文,引用其的论文也多是与数据挖掘相关的。这一类的网络称之为同质性网络。但在黑产的关系网络当中,图的异质性就非常高了,黑产用户不仅仅与黑产用户相关,其也可以与正常用户建立关系,这种特殊的网络结构就会存在一些弊端,以下图异质性网络为例,圈住的正常节点的一阶邻居节点一半为恶意账号,算法进行预测、聚类时,该节点很多概率会被判定为恶意账号。圈住的恶意节点的一阶邻居 3 个皆为正常账号,算法进行预测、聚类时,该节点则大概率被判定为正常节点,导致算法的精度下降。
为了解决上述问题,需要去考虑网络的结构是否合理。为了构建合理的网络结构,需要将恶意账号与正常账号之间存在的联系剔除掉,并将恶意账号之间的联系进行一定的增强。
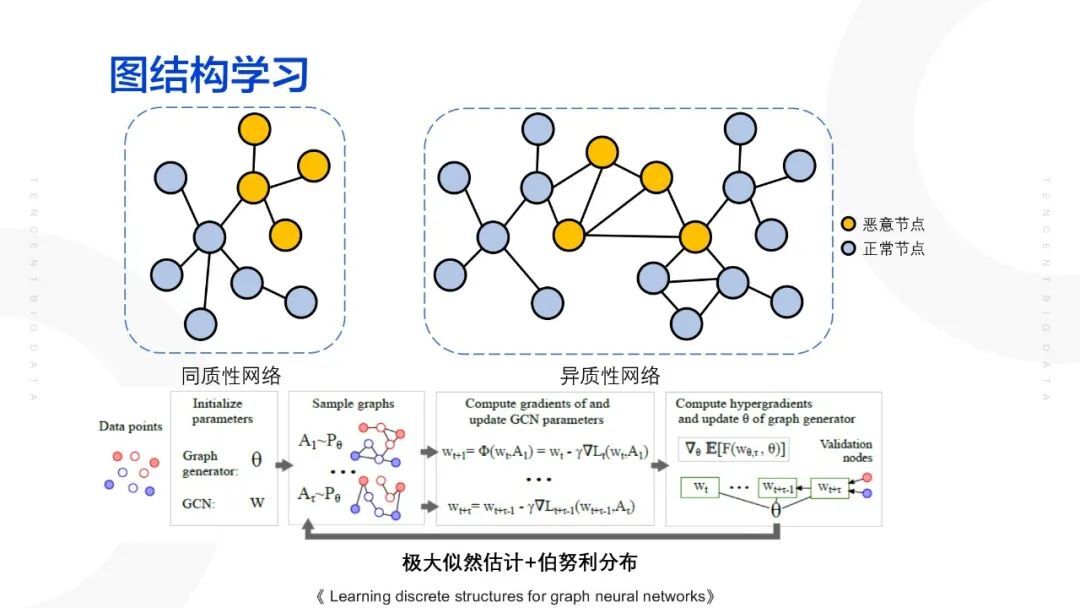
当网络结构合理时,算法进行预测、聚类时会更加准确,因此引入图结构学习的概念,尝试用 LDS 算法解决这类问题。
LDS 算法的思想:在训练 GCN 模型的参数的同时对网络的结构进行调整,在最初的时候给予一个网络结构(邻接矩阵),先固定 GCN 的模型,然后训练邻接矩阵,通过几轮迭代之后再固定邻接矩阵,再训练 GCN 模型,通过几轮迭代之后,可以得出一个合理的网络结构。总的来说,这个算法实际上就是一个极大似然估计以及伯努利分布的问题。在 LDS 算法学习邻接矩阵的时候实际就是学习两个点的邻边是否应该存在,实际上为一个 0-1 分布。最终通过网络结构以及节点的标签去预估在当前数据标签的情况下,更应该得到什么样的一个网络结构,以上即为该算法的核心思想。
实际上,在许多业务场景当中会存在许多不合理的图结构,甚者在某些业务场景中不存在关系信息,这样的话,在最初达不到完整网络的情况时,通常会使用 KNN 的方式对网络进行初始化,然后再去学习一个更加合理的网络结构,最终达到一个更好节点预测、聚类的目的。
总结思考
下面分享几点在算法落地以及算法选择中的一些工作总结与思考:
① 针对图算法这块,特征工程和图的构建方式是非常重要的。如果图的结构不合理的话,即使算法模型再强大、特征工程处理得再好,算法训练出的结果也不是最终理想的效果;
② 多数业务场景的区分度是不一样的,不存在一个普适的算法可以解决所有业务场景存在的问题,如上述的 FastUnfolding、node2vec 在某些特定的业务场景下效果可以比 GraphSAGE 的效果更好,所以在面临具体问题的时候,需要结合场景作算法选择以及优化;
③ 在工业界落地的算法通常比较直接、明了,这样的算法往往效果更好。
嘉宾介绍:
Harry,腾讯高级研究员。
本文转载自:DataFunTalk(ID:datafuntalk)
原文链接:图算法在网络黑产挖掘中的思考




