
LinkedIn将Couchbase作为集中式缓存层,用于伸缩会员资料读取操作,以应对日益增长的、超出现有数据库集群处理能力的流量。新方案实现了超过 99%的命中率,将尾延迟降低了 60%以上,将年度成本降低了 10%。
多年来,LinkedIn 直接从其Espresso文档平台提供会员资料。Espresso 平台建立在MySQL之上,并使用Avro进行序列化,还包含了Apache Helix和Databus(LinkedIn 的变更捕获系统)组件。Espresso 路由器处理资料读取请求,将读/写请求定向到正确的存储节点,并使用堆外缓存(OHC)进行热键缓存。
/filters:no_upscale()/news/2023/07/linkedin-member-profile-caching/en/resources/1linkedin-espresso-1688241494720.jpeg)
图片来源:https://engineering.linkedin.com/blog/2023/upscaling-profile-datastore-while-reducing-costs
随着存储请求量每年翻倍,峰值超过每秒 480 万次,为会员资料提供服务的 Espresso 集群已经达到了伸缩性的极限。团队决定引入一个基于Couchbase的缓存层,而不是重构 Espresso 平台的核心组件,因为超过 99%的请求都是读取操作。
LinkedIn 软件工程师Estella Pham和Guanlin Lu解释了团队为什么选择 Couchbase 作为缓存:
在 LinkedIn,我们已经将 Couchbase 用作各种应用程序的分布式键值缓存。它被选中是因为它比 memcached 更强大,包括用于保存服务器重启之间持久化的数据,在集群中的个体节点发生故障时所有文档仍然可用的复制功能,以及可以在不停机的情况下添加或删除节点的动态可伸缩性。
新的缓存层结合了 OCH 和 Couchbase,并被集成到了 Espresso 中,不需要客户端做出修改。其设计重点是 Couchbase 的故障弹性、缓存数据可用性和数据分歧预防。Espresso 路由器会在发生暂时性故障时重试请求,并监控 Couchbase 健康状况以避免将请求发送到不健康的桶。会员资料数据被复制了三次,如果首领副本不可用,路由器会将其转移到其中的一个跟随者副本。
所有的会员资料数据都缓存在每一个数据中心里,由Apache Samza作业根据 Espresso 捕获的写操作进行实时的更新,以及根据数据库快照进行定期的更新。所有的缓存更新都使用了Couchbase Compare-And-Swap(CAS)来检测并发更新,并在必要时重试更新。
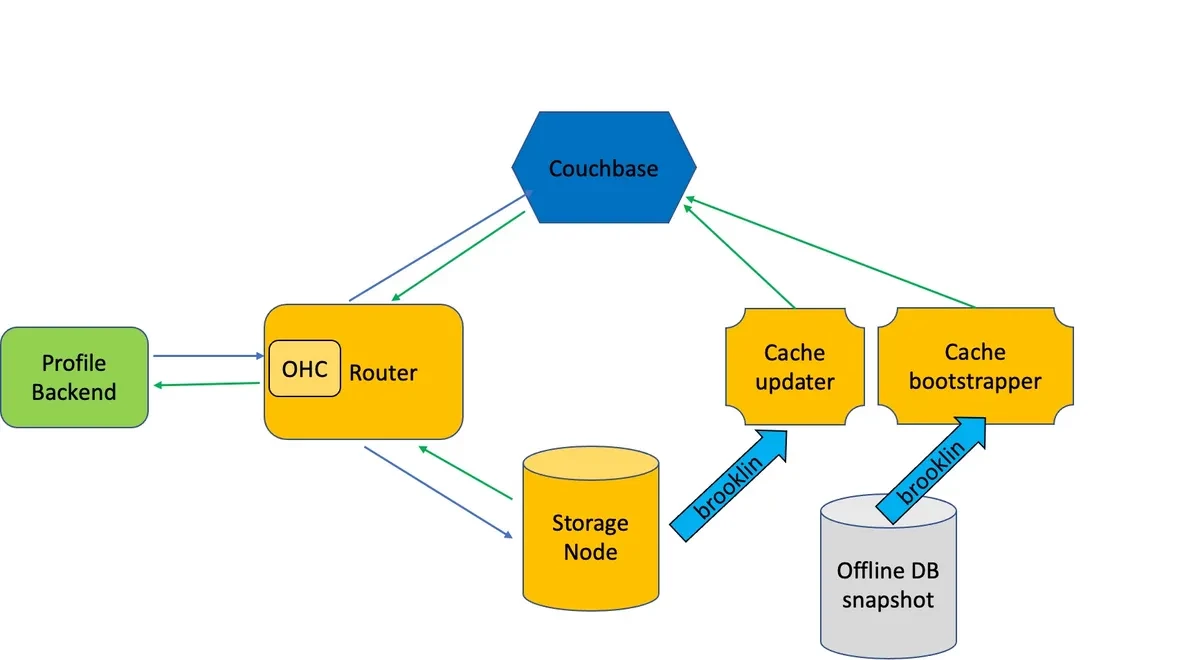
图片资料:https://engineering.linkedin.com/blog/2023/upscaling-profile-datastore-while-reducing-costs
经过调整之后,Profile Backend 服务将负责处理一些原先由 Espresso 处理的操作。它会动态评估请求字段并返回保存在缓存中的完整资料数据的子集。它还会处理 Avro 模式转换,并在必要时从注册表获取模式版本。
LinkedIn 的团队进行了进一步的性能优化,简化了 Avro/二进制格式的数据读取,并在反序列化性能方面实现了约 30%的改进。因为引入了新的混合缓存方案,Espresso 的节点数减少了 90%。考虑到运行 Couchebase 集群、缓存更新作业所需的新基础设施和运行后端服务新增的计算资源,为会员资料请求提供服务的总成本每年下降了 10%。
原文链接:
https://www.infoq.com/news/2023/07/linkedin-member-profile-caching/
相关阅读:




